Command Palette
Search for a command to run...
Verankierung von Welt-Simulationsmodellen in einer realen Metropole
Verankierung von Welt-Simulationsmodellen in einer realen Metropole
Zusammenfassung
Was wäre, wenn ein Weltmodell eine Simulation nicht einer imaginierten Umgebung, sondern einer tatsächlich existierenden Stadt rendern könnte? Bisherige generative Weltmodelle synthetisieren visuell plausible, jedoch künstliche Umgebungen durch die Generierung aller Inhalte aus dem Nichts. Wir stellen das Seoul World Model (SWM) vor, ein stadtmaßstabsgerechtes Weltmodell, das auf der realen Stadt Seoul basiert. SWM verankert die autoregressive Videogenerierung durch retrieval-augmentierte Konditionierung auf nahegelegene Street-View-Bilder. Dieses Design bringt jedoch mehrere Herausforderungen mit sich, darunter zeitliche Fehlausrichtungen zwischen den retriaverten Referenzen und der dynamischen Zielszene, eine begrenzte Trajektorienvielfalt sowie eine Datenknappheit infolge von Fahrzeugaufnahmen in großen zeitlichen Abständen. Diese Herausforderungen adressieren wir durch Cross-Temporal Pairing, einen großskaligen synthetischen Datensatz, der diverse Kameratrajektorien ermöglicht, sowie durch eine View-Interpolation-Pipeline, die aus spärlichen Street-View-Bildern kohärente Trainingsvideos synthetisiert. Zusätzlich führen wir einen Virtual Lookahead Sink ein, um die Generierung über lange Horizonte zu stabilisieren, indem jeder Chunk kontinuierlich an ein retriavertes Bild an einem zukünftigen Standort neu verankert wird. Wir evaluieren SWM gegenüber aktuellen Video-Weltmodellen in drei Städten: Seoul, Busan und Ann Arbor. SWM übertrifft bestehende Methoden bei der Generierung von räumlich getreuen, zeitlich konsistenten, langfristigen Videos, die in tatsächlichen städtischen Umgebungen verankert sind und Trajektorien von Hunderten von Metern abdecken, während es gleichzeitig diverse Kamerabewegungen und scenario-Variationen auf Basis von Text-Prompts unterstützt.
One-sentence Summary
Researchers from KAIST AI, NAVER AI Lab, and SNU AIIS introduce Seoul World Model, a city-scale simulation system that grounds video generation in real urban environments by retrieving street-view images. Unlike prior models that imagine artificial worlds, this approach uses cross-temporal pairing and a Virtual Lookahead Sink to ensure spatial fidelity and long-horizon stability for applications like urban planning and autonomous driving.
Key Contributions
- The paper introduces Seoul World Model, a city-scale world simulation system that anchors autoregressive video generation to real urban environments by retrieving and conditioning on nearby street-view images based on geographic coordinates and camera actions.
- To overcome data sparsity and trajectory limitations, the work presents a large-scale synthetic dataset with diverse camera paths and a view interpolation pipeline that synthesizes coherent training videos from sparse street-view captures using an intermittent freeze-frame strategy.
- A Virtual Lookahead Sink is proposed to stabilize long-horizon generation by continuously re-grounding each video chunk to a retrieved image at a future location, which experimental results show enables spatially faithful and temporally consistent videos over trajectories reaching hundreds of meters.
Introduction
World simulation models currently generate dynamic environments by imagining all content beyond an initial frame, which limits their utility for applications requiring strict fidelity to real-world locations like urban planning or autonomous driving testing. Existing approaches struggle to ground generation in specific physical cities because they lack mechanisms to anchor predictions to actual geometry, while traditional 3D reconstruction systems remain static and unable to simulate dynamic scenarios. The authors introduce the Seoul World Model, which grounds autoregressive video generation in a real metropolis by retrieving nearby street-view images to condition the output. To overcome challenges such as temporal misalignment between static references and dynamic scenes, sparse data coverage, and long-horizon drift, they employ cross-temporal pairing, a large-scale synthetic dataset with diverse trajectories, and a Virtual Lookahead Sink that continuously re-anchors generation to future locations.
Dataset
Dataset Composition and Sources
The authors construct the Street-View Motion (SWM) dataset by aligning street-view references with target video sequences to ground generation in real-world geometry. The data originates from three primary sources:
- Real Street-View Data: 1.2 million panoramic images captured across major urban areas of Seoul, sourced from NAVER Map.
- Synthetic Urban Data: 12.7K videos rendered using the CARLA simulator across six urban maps.
- Public Driving Dataset: A supplementary publicly available driving video dataset used to increase scenario diversity.
Key Details for Each Subset
- Real Street-View Subset:
- Size: 1.2M raw panoramas reduced to 440K images for training after processing.
- Metadata: Includes GPS coordinates and timestamps; license plates and pedestrians are blurred for privacy.
- Coverage: Spans approximately 44.8 km east-west and 31.0 km north-south within the Seoul Metropolitan Area.
- Synthetic Subset:
- Size: 12.7K videos covering 431,500 square meters.
- Trajectory Types: Includes pedestrian paths (sidewalks/crossings), vehicle paths (highways/turns), and free-camera navigation.
- References: 4K street-view positions rendered with eight directional views each, totaling 32K reference frames.
- Stylized Augmentation: 10K additional videos generated by applying style transfers (e.g., weather changes, day-to-night) to the interpolated street-view data.
Data Usage and Training Strategy
- Cross-Temporal Pairing: The authors enforce a strict rule where reference images and target sequences are captured at different timestamps. This prevents the model from learning transient objects like specific cars or pedestrians, forcing it to rely on persistent spatial structures.
- Training Splits: The 440K processed real images and the full synthetic set are used to train the video generation model.
- Text Prompts: Videos are captioned using Qwen2.5-VL-72B to generate long and short descriptions of scenery and events. These are combined with predefined camera action tags (e.g., "straight," "left turn") derived from pose sequences.
- Mixture: The training mixture combines real-world data, synthetic data, and stylized augmentations to balance geometric fidelity with diverse camera paths and environmental conditions.
Processing and Construction Details
- View Interpolation: To bridge the gap between sparse panoramic captures (5–20m intervals) and continuous video requirements, the authors use a pretrained latent video model to synthesize smooth T-frame videos from N sparse keyframes.
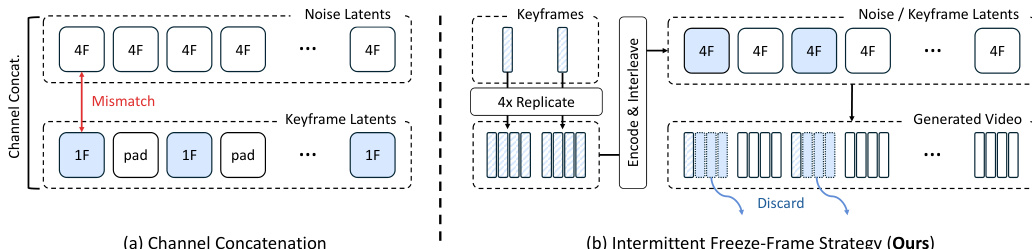
- Intermittent Freeze-Frame Strategy: To ensure compatibility with the 3D VAE's 4-frame temporal compression, keyframes are repeated four times during encoding. At inference, these repeated frames are discarded to recover the intended smooth video.
- Geometric Alignment: Depth maps and 6-DoF camera poses are estimated using Depth Anything V3. These are aligned to real-world metric scales using GPS metadata to ensure global coordinate consistency across the database.
- Retrieval Pipeline: For inference, the system performs a two-stage retrieval: nearest-neighbor search identifies candidate locations, followed by depth-based reprojection filtering to select references that provide sufficient pixel coverage for the target view.
Method
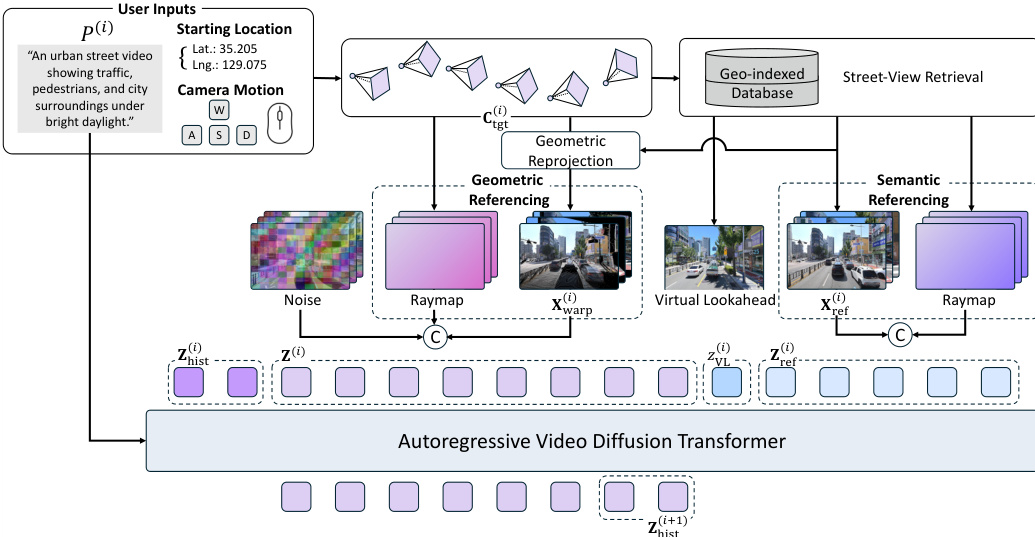
The proposed Street-View World Model (SWM) generates videos grounded in real cities using a retrieval-augmented autoregressive framework. The system builds upon a pretrained Diffusion Transformer (DiT) that operates in a latent space compressed from pixel-space frames via a 3D VAE. Generation proceeds autoregressively in chunks, where each chunk conditions on a text prompt, a target camera trajectory, and noisy latents. To ensure temporal continuity, subsequent chunks condition on history latents from the tail of the preceding chunk's output.
Refer to the framework diagram for the overall architecture. User inputs, including a starting location and camera motion, drive a geo-indexed database retrieval process. This retrieves relevant street-view images which serve dual purposes: acting as a Virtual Lookahead Sink for long-horizon stability and providing conditioning for geometric and semantic referencing to ground the generation in real-world geometry and appearance.
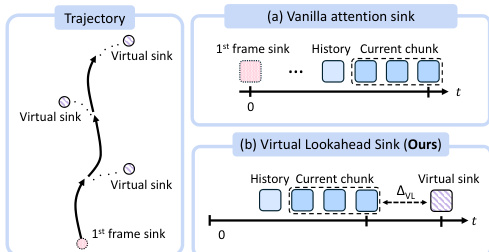
To mitigate error accumulation inherent in autoregressive generation over city-scale distances, the authors introduce a Virtual Lookahead Sink. As shown in the figure below, standard attention sinks typically anchor to the initial frame, which becomes increasingly irrelevant as the camera moves away. In contrast, the proposed method dynamically retrieves the nearest street-view image to the target trajectory's endpoint for each chunk. This image is treated as a virtual future destination and placed with a sufficient temporal gap from the current generation chunk. By providing a clean, error-free anchor ahead of the current frame, the model has a stable target to converge toward, ensuring the grounding remains relevant to the region being generated.
The model employs two complementary conditioning pathways to utilize the retrieved references. Geometric referencing reprojects a reference image into the target viewpoint via depth-based forward splatting, providing dense spatial layout cues. This warped video is encoded and channel-wise concatenated with the noisy target latent. Semantic referencing preserves appearance detail by injecting the original references into the transformer's latent sequence. Each reference is encoded into a single latent and concatenated with the target latents along the temporal axis. To handle dynamic objects that may differ between the reference and the generated scene, the authors leverage a cross-temporal pairing strategy, encouraging the model to focus on persistent scene structure rather than transient content.
For training data generation involving keyframes, the authors utilize an Intermittent Freeze-Frame strategy. Refer to the comparison diagram which contrasts this with standard channel concatenation. The channel concatenation baseline suffers from weak keyframe adherence because isolated keyframes do not form valid groups for the 3D VAE's temporal compression. The proposed strategy ensures each keyframe forms a complete 4-frame group matching the VAE's temporal stride by repeating the keyframe 4 consecutive times. During inference, the input keyframe is encoded into a single clean latent, which replaces the corresponding position in the noisy input latent at every diffusion step, ensuring exact keyframe conditioning.
Experiment
- Real-world grounded world simulation benchmarks validate that the model generates high-fidelity, dynamic videos consistent with actual urban layouts and target camera trajectories, outperforming existing world models that suffer from drift and structural collapse over long horizons.
- Ablation studies confirm that cross-temporal data pairing is essential for handling dynamic objects, while combining geometric and semantic referencing strategies ensures both structural alignment and visual fidelity.
- The Virtual Lookahead Sink design is critical for maintaining stability during extended generation, significantly reducing error accumulation and preserving scene coherence compared to conventional attention sink methods.
- Comparisons with static scene generators demonstrate that explicit modeling of scene dynamics is necessary to produce temporally coherent videos from real-world references, as static models fail to synthesize plausible motion.