Command Palette
Search for a command to run...
Alignment macht Sprachmodelle normativ, nicht deskriptiv.
Alignment macht Sprachmodelle normativ, nicht deskriptiv.
Eilam Shapira Moshe Tennenholtz Roi Reichart
Zusammenfassung
Das post-training Alignment optimiert Sprachmodelle so, dass sie menschliche Präferenzsignale abbilden; dieses Ziel ist jedoch nicht äquivalent zur Modellierung beobachteten menschlichen Verhaltens. Wir vergleichen 120 Paare aus Basis- und alignierten Modellen anhand von mehr als 10.000 realen menschlichen Entscheidungen in mehrstufigen strategischen Spielen – darunter Verhandlungen, Überzeugungsversuche, Aushandlungsprozesse und wiederholte Matrixspiele. In diesen Szenarien übertreffen Basismodelle ihre alignierten Gegenstücke bei der Vorhersage menschlicher Entscheidungen um fast das Zehnfache; dieses Ergebnis erweist sich als robust über verschiedene Modellfamilien, Prompt-Formulierungen und Spielkonfigurationen hinweg. In Settings, in denen menschliches Verhalten eher normativen Vorhersagen folgt, kehrt sich dieses Muster jedoch um: Alignierte Modelle dominieren bei einmaligen Lehrbuchspielen über alle 12 getesteten Typen hinweg sowie bei nicht-strategischen Lotterieentscheidungen – und selbst innerhalb der mehrstufigen Spiele bereits in der ersten Runde, bevor sich eine Interaktionsgeschichte entwickelt. Dieses Muster der Randbedingungen deutet darauf hin, dass Alignment einen normativen Bias induziert: Es verbessert die Vorhersagegenauigkeit, wenn menschliches Verhalten relativ gut durch normative Lösungen erfasst wird, verschlechtert sie jedoch in mehrstufigen strategischen Settings, in denen das Verhalten durch deskriptive Dynamiken wie Reziprozität, Vergeltung und historisch abhängige Anpassung geprägt ist. Diese Ergebnisse offenbaren einen grundlegenden Zielkonflikt zwischen der Optimierung von Modellen für den menschlichen Einsatz und ihrer Verwendung als Stellvertreter für menschliches Verhalten.
One-sentence Summary
Researchers from Technion reveal that post-training alignment introduces a normative bias, causing aligned models to fail at predicting human behavior in multi-round strategic games where base models excel by a 10:1 margin, while aligned versions succeed only in one-shot or non-strategic scenarios.
Key Contributions
- The paper introduces a systematic comparison of 120 base-aligned model pairs across more than 10,000 real human decisions in four multi-round strategic game families, revealing that base models outperform aligned counterparts by a nearly 10:1 margin in predicting human choices.
- This work presents a deterministic token probability extraction method that bypasses text generation to directly measure how well a model's internal distribution matches human decision distributions, enabling a fair comparison between base and aligned variants on identical inputs.
- Results demonstrate that alignment induces a normative bias that improves prediction accuracy in one-shot textbook games and non-strategic lottery choices but significantly degrades performance in multi-round strategic settings where human behavior is driven by reciprocity and history-dependent adaptation.
Introduction
Researchers increasingly use aligned Large Language Models as behavioral proxies to simulate human opinions and predict experimental outcomes, yet this practice assumes alignment preserves behavioral fidelity. Prior studies indicate that alignment techniques like RLHF and instruction tuning often collapse opinion diversity, introduce cognitive biases, and degrade reasoning capabilities, but these findings have largely been limited to static judgments rather than dynamic strategic interactions. The authors address this gap by conducting the first systematic comparison of base versus aligned models across 120 model pairs in four game families, demonstrating that alignment makes models normative rather than descriptive and significantly reduces their ability to predict the full range of human strategic behavior.
Dataset
-
Dataset Composition and Sources The authors evaluate models across four strategic game families and two boundary condition datasets. The primary strategic data comes from the GLEE benchmark (Shapira et al., 2024b) and Akata et al. (2025), while the boundary tests utilize procedurally generated matrix games from Zhu et al. (2025) and binary lottery choices from Marantz and Plonsky (2025).
-
Key Details for Each Subset
- Bargaining: Based on the Rubinstein model, this subset includes 1,788 human decisions where players alternate offers with optional free-text messages and face discount factors framed as inflation.
- Persuasion: A repeated cheap talk game over 20 rounds containing 3,180 human decisions where buyers decide to purchase based on seller messages, featuring both long-living and myopic buyer variants.
- Negotiation: A bilateral price negotiation with 1,182 human decisions involving ternary choices to accept, reject, or take an outside option with a third party.
- Repeated Matrix Games: Includes 3,900 decisions (1,950 per game) from 195 participants playing 10 rounds of Prisoner's Dilemma and Battle of the Sexes against pre-computed GPT-4 strategies.
- One-shot Matrix Games: A procedurally generated set of 2,416 games spanning 12 topologies with approximately 93,000 aggregated human decisions, reduced to 71 valid pairs after filtering.
- Binary Lottery Choices: Comprises 1,001 non-strategic problems where participants choose between gambles, resulting in 90 valid pairs after filtering.
-
Data Usage and Processing The authors use these datasets to generate over 2.4 million total predictions across 120 same-provider base-aligned model pairs. For the GLEE games, human participants interacted with LLM opponents via a web interface without knowing the opponent's nature, ensuring decisions were uncontaminated by bias. The repeated matrix games are formatted as multi-turn prompts that include the payoff matrix and round history. The one-shot matrix games use a counterbalanced format to control for position bias, while lottery choices are presented as verbal descriptions.
-
Filtering and Metadata Construction The study excludes model pairs where the base and aligned checkpoints are identical or where the aligned model lacks a chat template. For the boundary condition datasets, the authors apply strict filtering to retain only valid same-provider pairs, resulting in 71 pairs for the one-shot matrix games and 90 pairs for the lottery choices. The evaluation covers 10,050 human decisions per model to ensure statistical robustness across the different game structures.
Method
The authors frame human decision prediction as a token probability extraction task. For each human decision point within a game, they construct a prompt consisting of a system message that describes the game rules and the participant's role. This is followed by the dialogue history up to the specific decision point. The model then performs a single forward pass to extract the log-probabilities assigned to each decision token from the next-token distribution at the final position. For example, in bargaining scenarios, the tokens might be "accept" versus "reject".
They normalize the extracted probabilities to obtain a predicted decision distribution. The formula for the probability of acceptance is defined as:
paccept=∑dp(d)p(yes)where d ranges over all decision tokens for a given family. This includes two tokens for bargaining, persuasion, and matrix games, while negotiation adds a third token for the outside option. The resulting paccept value falls within the range [0,1] and captures the model's relative preference for the affirmative action. This normalization removes the influence of non-decision tokens.
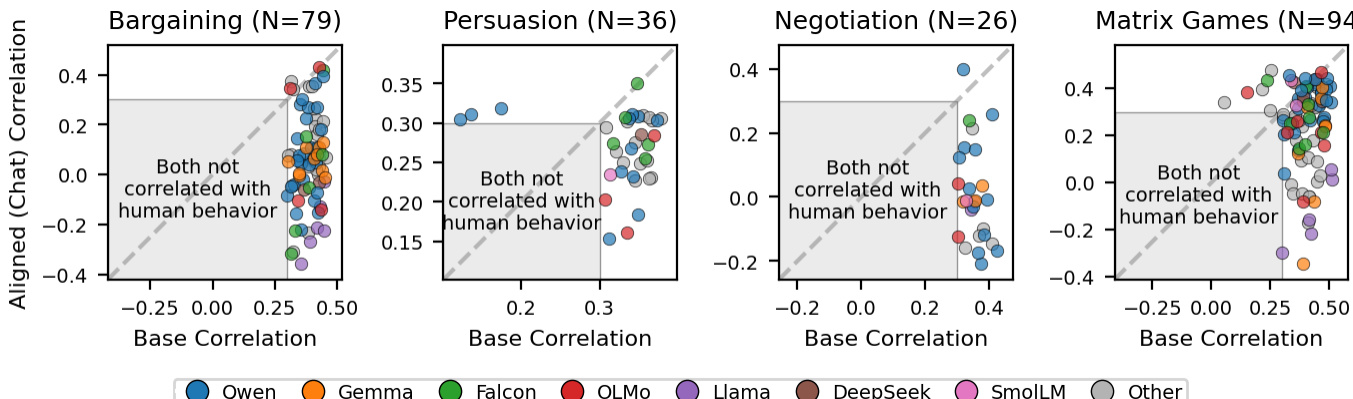
This method requires no text generation and no sampling. It is a deterministic extraction of the model's internal probability distribution over decision tokens. The approach is applicable to both base and aligned models without requiring different decoding strategies. However, the normalization is robust only when decision tokens receive substantial probability mass. When the model distributes mass primarily to non-decision tokens, the normalized probabilities become unreliable. To address this, the authors apply two pair-level filters per game family. The first is a mass filter that excludes pairs where either model assigns less than 80% average probability mass to decision tokens. The second is a minimum correlation filter that excludes pairs where both models correlate below 0.3 with human decisions. These filters are applied independently per family to ensure the base advantage remains robust across threshold choices.
Experiment
- Multi-round strategic games (bargaining, persuasion, negotiation, repeated matrix games) validate that base models significantly outperform aligned models in predicting actual human behavior, as alignment introduces a normative bias that suppresses descriptive dynamics like reciprocity and retaliation.
- One-shot textbook games and non-strategic lottery choices validate that aligned models excel in settings where human behavior aligns with normative predictions, demonstrating that alignment improves accuracy when interaction history is absent.
- Round-by-round analysis within multi-round games confirms that aligned models perform better in the initial round before history accumulates, but lose predictive advantage as interaction history develops and strategic dynamics emerge.
- Robustness tests across model families, prompt formats, and game parameters validate that the performance gap is driven by model weights and alignment effects rather than prompt formatting or specific game configurations.
- The overall conclusion establishes a fundamental trade-off where alignment optimizes models for human use and normative ideals but degrades their utility as proxies for describing complex, history-dependent human behavior.