HyperAI
Command Palette
Search for a command to run...
الأوراق البحثية
أوراق بحثية متطورة في مجال الذكاء الاصطناعي يتم تحديثها يوميًا لمساعدتك على مواكبة أحدث اتجاهات الذكاء الاصطناعي

Parrot: تقييم متانة الإقناع والموافقة لصدق المخرجات — معيار مرجعي لمتانة التملق لدى LLMs
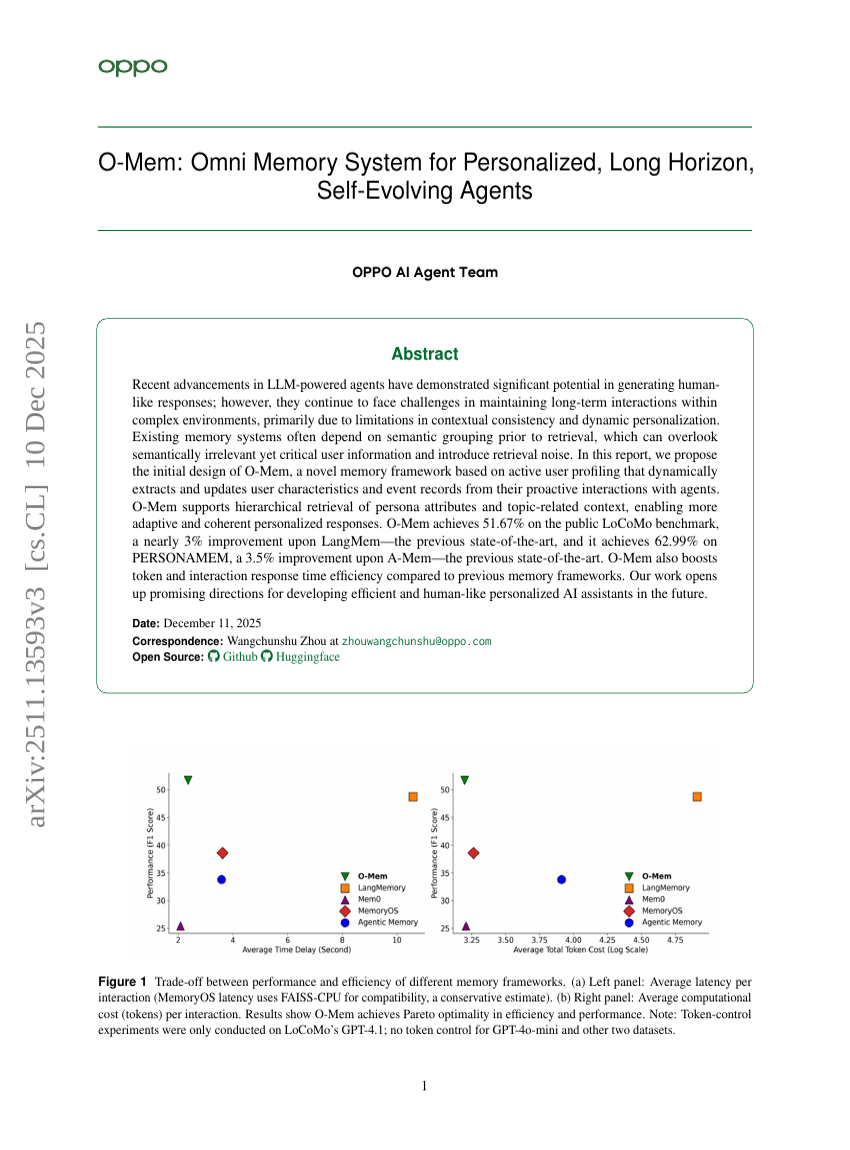
O-Mem: نظام ذاكرة شامل لوكلاء ذويية التطور الذاتي على المدى الطويل والشخصي

















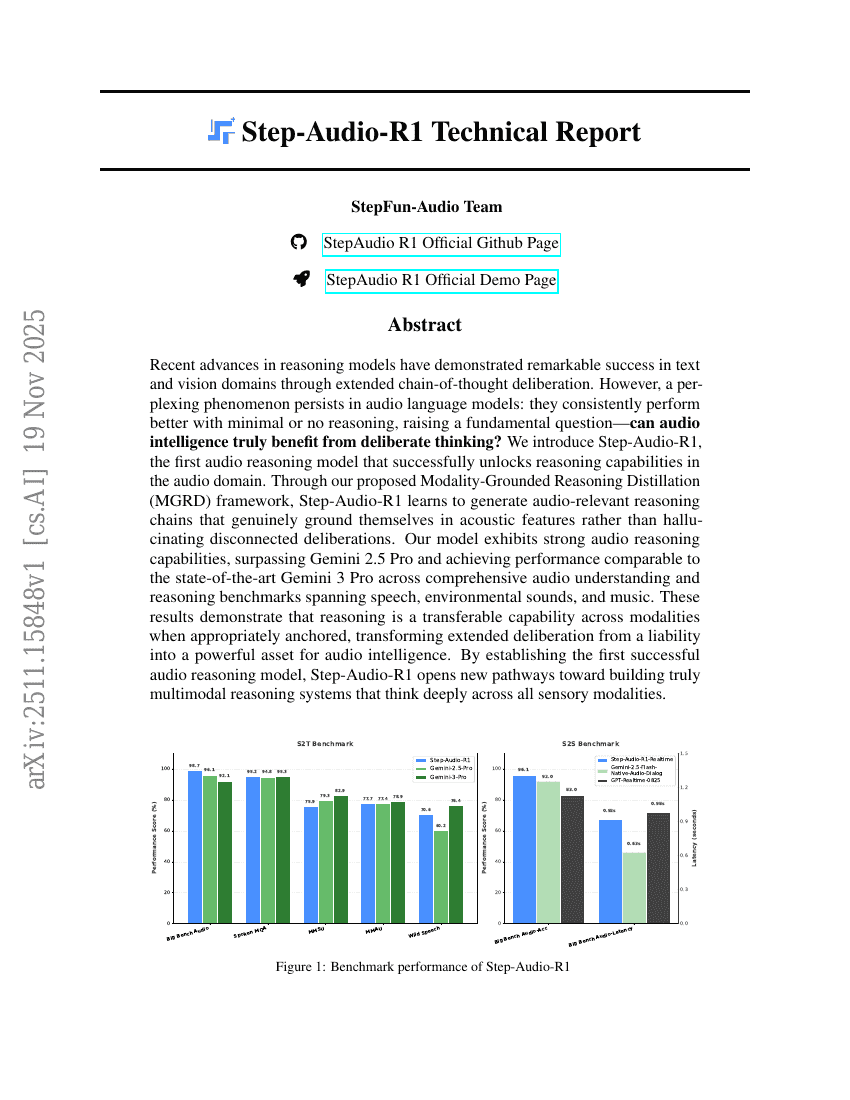
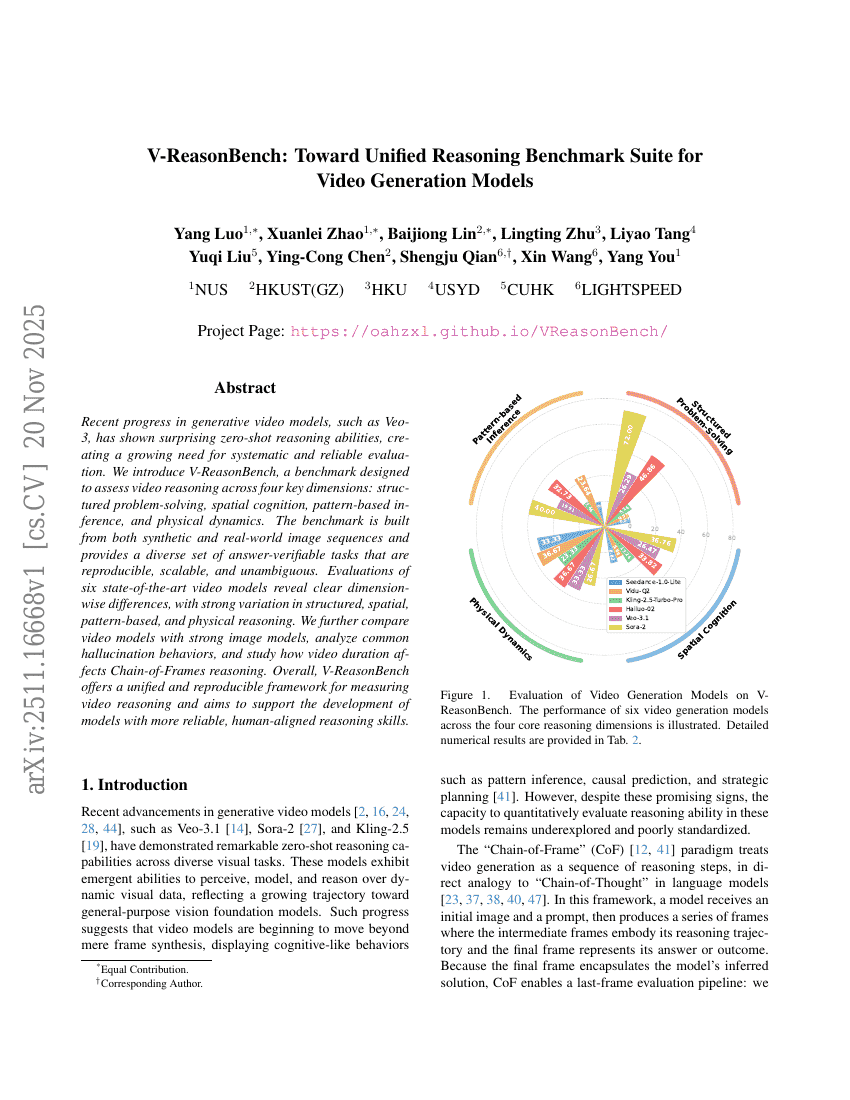



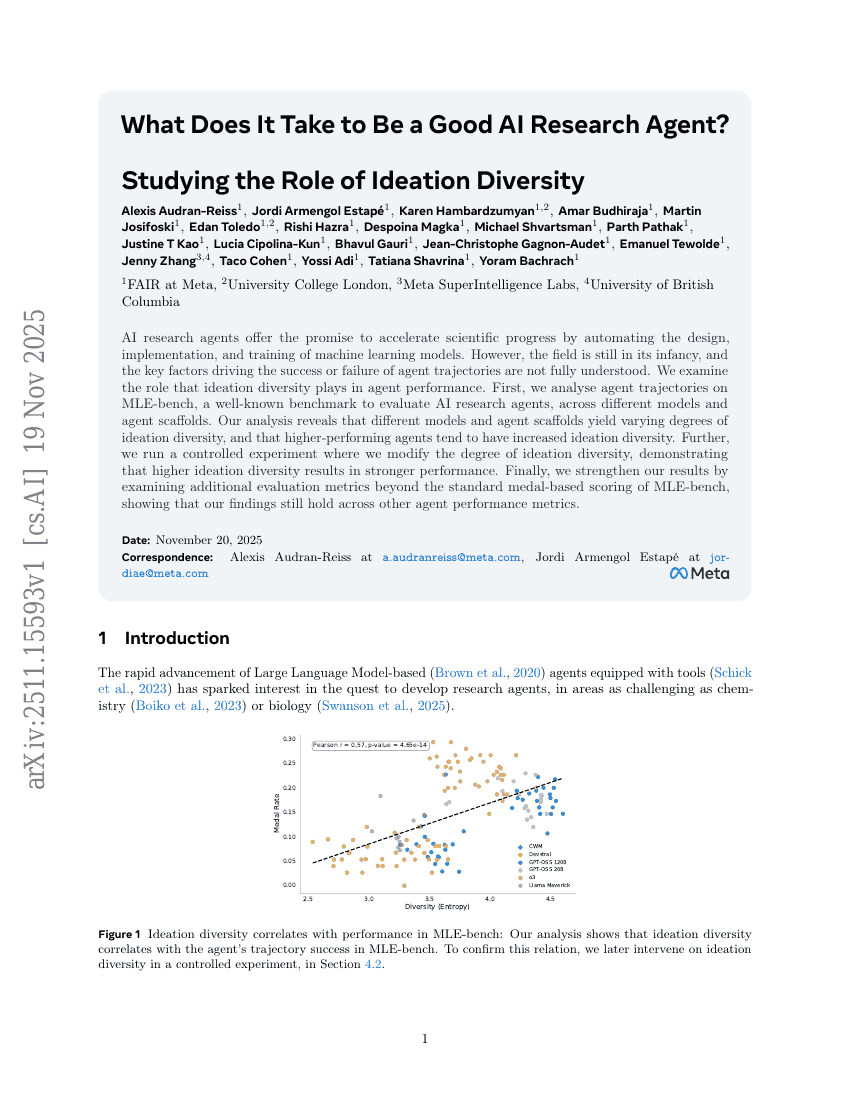





Parrot: تقييم متانة الإقناع والموافقة لصدق المخرجات — معيار مرجعي لمتانة التملق لدى LLMs
O-Mem: نظام ذاكرة شامل لوكلاء ذويية التطور الذاتي على المدى الطويل والشخصي
كشف البُعد الجوهري للنصوص: من الملخص الأكاديمي إلى القصة الإبداعية
SAM 3: تجزئة أي شيء باستخدام المفاهيم
GeoVista: الاستدلال البصري القائم على Agent والمُعزز بالويب لتحديد الموقع الجغرافي
OpenMMReasoner: دفع حدود الاستدلال متعدد الوسائط باستخدام وصفة مفتوحة وعامة
HiPO: تحسين السياسة الهجيني للتفكير الديناميكي في النماذج اللغوية الكبيرة
SERES: إعادة بناء عصبي يراعي المعنى من مناظر متباعدة
SDAR: منهج متماسك يعتمد على الانتشار-الانحدار التلقائي لتوليد التسلسلات القابلة للتوسع
MultiPL-MoE: توسيع النماذج اللغوية الكبيرة متعددة البرمجة واللغة من خلال مزيج الهجين من الخبراء
CapRL: تحفيز القدرات المكثفة في التسمية الصورية من خلال التعلم المعزز
توليد لغة فائق السرعة عبر انحراف التمايز المتقطع التعليمي
DisCO: تعزيز النماذج الكبيرة للاستدلال من خلال التحسين المقيّد التمييزي
QSVR: تقريب منخفض الرتبة فعّال لضغط أوزان الاستعلام-القيمة-الرقم المُسجَّل الموحَّد في نماذج الرؤية واللغة من الدقة المنخفضة
التعلم المتداخل: الوهم المتأصل في هياكل التعلم العميق
SAM 3D: 3Dify أي شيء في الصور
إجابة بالفيديو: التنبؤ بإنشاء الحدث الفيديو التالي باستخدام Joint-GRPO
الإطار الأول هو المكان المثالي للتخصيص المحتوى المرئي
توسيع الذكاء المكاني باستخدام النماذج الأساسية متعددة الوسائط
تقرير فني حول Step-Audio-R1
V-ReasonBench: نحو مجموعة معايير موحدة لتقييم الاستدلال النموذجية لتنبؤ الفيديو
أولمو 3
تجارب تسريع العلم المبكرة مع GPT-5
نحو تقييم موضوعي ومنهجي للتحيز في الذكاء الاصطناعي للتصوير الطبي
ما الذي يتطلبه أن تكون وكيل بحث ذكاء اصطناعي جيد؟ دراسة دور تنوع التفكير الإبداعي
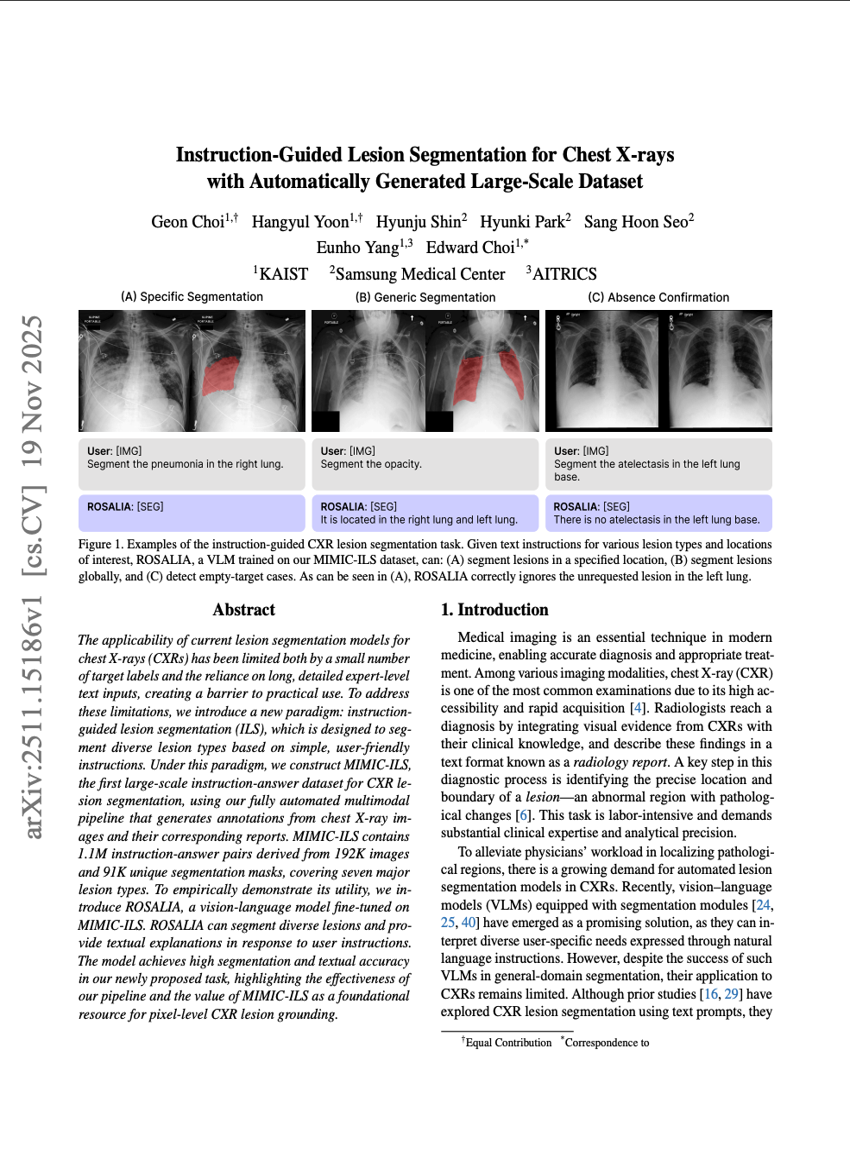
التشخيص التوجيهي للتشوهات في صور الأشعة الصدرية باستخدام مجموعة بيانات ضخمة مُولَّدة تلقائيًا
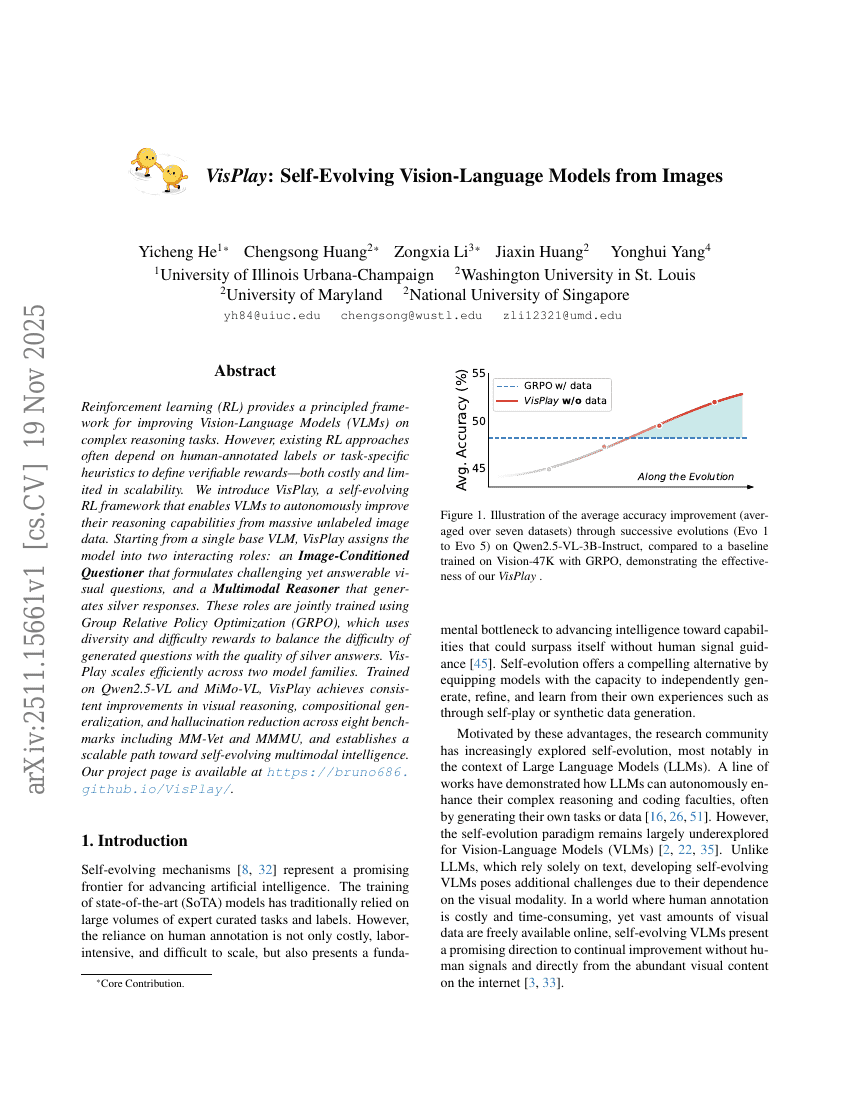
VisPlay: نماذج لغة-رؤية متعددة التطور الذاتي من الصور
الاستنتاج من خلال الفيديو: أول تقييم لقدرات الاستنتاج النموذجية للفيديوهات من خلال مهام حل المتاهات
VIDEOP2R: فهم الفيديو من الإدراك إلى الاستدلال
كاندينسكي 5.0: عائلة من النماذج الأساسية لإنشاء الصور والفيديوهات
JAM-2: التصميم الكامل الحسابي للجسوم المضادة شبه الأدوية ب معدلات نجاح عالية
PathMind: إطار استرجاع-تصنيف-استنتاج للاستدلال في الرسوم المعرفية باستخدام نماذج اللغة الكبيرة
كشف البُعد الجوهري للنصوص: من الملخص الأكاديمي إلى القصة الإبداعية
SAM 3: تجزئة أي شيء باستخدام المفاهيم
GeoVista: الاستدلال البصري القائم على Agent والمُعزز بالويب لتحديد الموقع الجغرافي
OpenMMReasoner: دفع حدود الاستدلال متعدد الوسائط باستخدام وصفة مفتوحة وعامة
HiPO: تحسين السياسة الهجيني للتفكير الديناميكي في النماذج اللغوية الكبيرة
SERES: إعادة بناء عصبي يراعي المعنى من مناظر متباعدة
SDAR: منهج متماسك يعتمد على الانتشار-الانحدار التلقائي لتوليد التسلسلات القابلة للتوسع
MultiPL-MoE: توسيع النماذج اللغوية الكبيرة متعددة البرمجة واللغة من خلال مزيج الهجين من الخبراء
CapRL: تحفيز القدرات المكثفة في التسمية الصورية من خلال التعلم المعزز
توليد لغة فائق السرعة عبر انحراف التمايز المتقطع التعليمي
DisCO: تعزيز النماذج الكبيرة للاستدلال من خلال التحسين المقيّد التمييزي
QSVR: تقريب منخفض الرتبة فعّال لضغط أوزان الاستعلام-القيمة-الرقم المُسجَّل الموحَّد في نماذج الرؤية واللغة من الدقة المنخفضة
التعلم المتداخل: الوهم المتأصل في هياكل التعلم العميق
SAM 3D: 3Dify أي شيء في الصور
إجابة بالفيديو: التنبؤ بإنشاء الحدث الفيديو التالي باستخدام Joint-GRPO
الإطار الأول هو المكان المثالي للتخصيص المحتوى المرئي
توسيع الذكاء المكاني باستخدام النماذج الأساسية متعددة الوسائط
تقرير فني حول Step-Audio-R1
V-ReasonBench: نحو مجموعة معايير موحدة لتقييم الاستدلال النموذجية لتنبؤ الفيديو
أولمو 3
تجارب تسريع العلم المبكرة مع GPT-5
نحو تقييم موضوعي ومنهجي للتحيز في الذكاء الاصطناعي للتصوير الطبي
ما الذي يتطلبه أن تكون وكيل بحث ذكاء اصطناعي جيد؟ دراسة دور تنوع التفكير الإبداعي
التشخيص التوجيهي للتشوهات في صور الأشعة الصدرية باستخدام مجموعة بيانات ضخمة مُولَّدة تلقائيًا
VisPlay: نماذج لغة-رؤية متعددة التطور الذاتي من الصور
الاستنتاج من خلال الفيديو: أول تقييم لقدرات الاستنتاج النموذجية للفيديوهات من خلال مهام حل المتاهات
VIDEOP2R: فهم الفيديو من الإدراك إلى الاستدلال
كاندينسكي 5.0: عائلة من النماذج الأساسية لإنشاء الصور والفيديوهات
JAM-2: التصميم الكامل الحسابي للجسوم المضادة شبه الأدوية ب معدلات نجاح عالية
PathMind: إطار استرجاع-تصنيف-استنتاج للاستدلال في الرسوم المعرفية باستخدام نماذج اللغة الكبيرة