Command Palette
Search for a command to run...
كل شيء في مكانه: تقييم الذكاء المكاني للنماذج النصية إلى الصورية
كل شيء في مكانه: تقييم الذكاء المكاني للنماذج النصية إلى الصورية
Zengbin Wang Xuecai Hu Yong Wang Feng Xiong Man Zhang Xiangxiang Chu
الملخص
أحرزت نماذج التوليد من النص إلى الصورة (T2I) تقدماً ملحوظاً في إنتاج صور عالية الدقة، لكنها غالبًا ما تفشل في التعامل مع العلاقات المكانية المعقدة، مثل الإدراك المكاني أو الاستدلال أو التفاعل. تُهمل هذه الجوانب الحيوية في المعايير الحالية إلى حد كبير بسبب تصميم المطالبات القصيرة أو المحدودة بالمعلومات. في هذه الورقة، نقدم SpatialGenEval، وهو معيار جديد مصمم لتقييم ذكاء المكانية في نماذج T2I بشكل منهجي، ويشمل جوانب رئيسية اثنتين: (1) يتضمن SpatialGenEval 1,230 مطالبة طويلة وغنية بالمعلومات عبر 25 مشهداً واقعياً. تدمج كل مطالبة 10 مجالات فرعية مكانية، مع أزواج مكونة من سؤال واجابة متعددة الخيارات (10 أزواج)، تشمل مناطق مثل موقع الكائنات والتركيب المكاني، والاختفاء، والسببية. أظهر تقييمنا الواسع لـ 21 نموذجاً من أحدث النماذج أن الاستدلال المكاني من الرتبة العليا لا يزال يمثل عقبة رئيسية. (2) ولإثبات أن فائدة تصميمنا الغني بالمعلومات لا تقتصر على التقييم البسيط، أنشأنا أيضًا مجموعة بيانات SpatialT2I. وتضم هذه المجموعة 15,400 زوجاً من النصوص والصور، مع إعادة صياغة المطالبات لضمان الاتساق البصري مع الحفاظ على كثافة المعلومات. أظهرت نتائج التدريب الدقيق على النماذج الأساسية الحالية (مثل Stable Diffusion-XL و Uniworld-V1 و OmniGen2) تحسناً متسقاً في الأداء (+4.2%، +5.7%، +4.4%)، مع تحسّن في الواقعية في العلاقات المكانية، مما يبرز نموذجاً مركزاً على البيانات لتحقيق الذكاء المكاني في نماذج T2I.
One-sentence Summary
Researchers from AMAP, Alibaba Group, and Beijing University of Posts and Telecommunications propose SpatialGenEval, a benchmark with 1,230 dense prompts to evaluate spatial reasoning in T2I models, and SpatialT2I, a training dataset that boosts performance on models like Stable Diffusion-XL by up to 5.7% through information-rich prompt redesign.
Key Contributions
- We introduce SpatialGenEval, a new benchmark featuring 1,230 long, information-dense prompts across 25 real-world scenes, each integrated with 10 spatial sub-domains and paired with 10 multi-choice questions to systematically evaluate spatial perception, reasoning, and interaction in T2I models.
- Our evaluation of 23 state-of-the-art models exposes a consistent and significant bottleneck in higher-order spatial reasoning, revealing that current T2I systems struggle with complex spatial relationships despite excelling at basic object generation.
- We construct the SpatialT2I dataset of 15,400 text-image pairs with rewritten prompts preserving information density, and show that fine-tuning foundation models like Stable Diffusion-XL, Uniworld-V1, and OmniGen2 on this data yields measurable gains (4.2%–5.7%) in spatial accuracy and realism.
Introduction
The authors leverage the growing capabilities of text-to-image models to tackle a critical gap: their inability to handle complex spatial relationships like object positioning, occlusion, and causal interactions. While current benchmarks focus on short prompts and basic object-attribute matching, they fail to evaluate higher-order spatial reasoning, leaving a blind spot in model evaluation. To address this, the authors introduce SpatialGenEval—a benchmark with 1,230 long, information-dense prompts across 25 real-world scenes, each paired with 10 multi-choice questions covering 10 spatial sub-domains. Their evaluation of 23 models reveals a universal bottleneck in spatial reasoning. Beyond assessment, they build SpatialT2I, a fine-tuning dataset of 15,400 text-image pairs, which boosts performance across models like Stable Diffusion-XL and OmniGen2 by up to 5.7%, demonstrating that data-centric training can directly improve spatial intelligence.
Dataset

The authors use a carefully constructed dataset pipeline to evaluate and enhance spatial intelligence in text-to-image (T2I) models. Here’s a breakdown:
-
Dataset Composition & Sources
The core benchmark, SpatialGenEval, is built from 25 real-world scenes across 5 categories: Outdoor (32.5%), Nature (28.5%), Indoor (16.3%), Human (12.2%), and Design (10.6%). These scenes are selected for diversity and real-world relevance, covering environments from airports to underwater landscapes. -
Key Subset Details
- Prompt Generation: 1,230 high-quality, information-dense prompts (avg. 60 words) are generated using Gemini 2.5 Pro, each embedding all 10 spatial sub-domains. Human experts refine them for fluency, logic, and lexical simplicity (e.g., replacing “vermilion” with “bright red”).
- QA Generation: For each prompt, 10 multiple-choice questions are auto-generated (1 per spatial sub-domain), with 3 distractors. Human annotators ensure no answer leakage (e.g., revising “What is the layout of leaves arranged in a circle?” to “What is the layout of the leaves in the image?”) and add a “None” option for uncertain cases.
- SpatialT2I (SFT Dataset): A separate 15,400 image-text pairs dataset built from 14 top T2I models. Prompts are rewritten via GPT-4o to better match generated images. “Design” scenes (130 prompts) are excluded due to low image quality.
-
Model Training & Data Use
SpatialT2I is used to fine-tune UniWorld-V1, OmniGen2, and Stable Diffusion-XL. The authors test data quality via ablation: three subsets (Unipic-v2, Bagel, Qwen-Image) show performance gains proportional to their original scores. Scaling experiments confirm that adding higher-quality subsets improves model spatial reasoning. -
Processing & Metadata
- All prompts and QAs undergo human-in-the-loop refinement by 5 experts over 168 person-hours, guided by detailed annotation rules.
- QA pairs are validated by Qwen2.5-VL for consistency.
- For SpatialT2I, prompts are rewritten using GPT-4o to align with image content, preserving spatial intelligence while correcting misalignments.
- Metadata includes scene type, prompt, questions, ground-truth answers, image path, and model predictions — all structured for reproducibility.
The pipeline combines MLLM automation with human curation to ensure high-quality, spatially rich data for both evaluation and model training.
Method
The authors leverage a hierarchical framework to define and evaluate spatial intelligence in the Spatial-GenEval benchmark, structured across four primary domains: Spatial Foundation, Spatial Perception, Spatial Reasoning, and Spatial Interaction. Each domain is further decomposed into specific sub-dimensions that progressively assess the model’s ability to generate and interpret spatially coherent scenes. The evaluation pipeline begins with the selection of a real-world scene and the integration of all 10 spatial sub-domains, as illustrated in the framework diagram. 
In the first stage, a large language model (LLM) synthesizes an information-dense prompt that incorporates all 10 spatial constraints. This prompt is designed to be semantically rich and explicitly integrates the required sub-domains, such as object attributes, spatial positions, and causal interactions. The generated prompt is then used to drive text-to-image (T2I) model generation. The resulting image is subsequently evaluated against a set of 10 corresponding omni-dimensional question-answer pairs, which are designed to probe the model’s understanding of the spatial relationships encoded in the prompt. The evaluation process involves comparing the model’s output against ground-truth answers to identify discrepancies, which are then used to refine the prompt for improved spatial accuracy.
The framework includes a meta-instruction phase for prompt generation, where the task description specifies that each prompt must involve all 10 spatial sub-domains and be approximately 60 words in length. This ensures that the generated prompts are comprehensive and cover a wide range of spatial reasoning tasks. The output format requires the prompts to be structured in valid JSON, with each entry containing a scene and its corresponding generated prompt. This structured approach ensures consistency and facilitates the systematic evaluation of spatial intelligence across diverse scenarios.
In the second stage, the focus shifts to generating question-answer pairs based on the text-to-image prompt. The meta-instruction for this stage emphasizes the creation of 10 multiple-choice questions, each targeting one of the 10 spatial sub-domains. The questions must be derived directly from the prompt and avoid introducing irrelevant or mythical information. The output format for this stage is also JSON-based, with each entry containing the scene, prompt, question type, and the corresponding answers. This ensures that the evaluation is both systematic and aligned with the original prompt.
Finally, the framework includes a meta-instruction for prompt rewriting, where the goal is to improve the spatial intelligence of the generated prompts. The process involves analyzing the input JSON, which includes the scene, prompt, question type, and ground-truth answers. The task is to deconstruct the scene and synthesize a rewritten prompt that accurately reflects the final state of the scene, incorporating all confirmed facts from the perceptual, reasoning, and interactive details. The rewritten prompt must be a single, clear paragraph that is suitable for downstream text-to-image generation. This iterative refinement process ensures that the prompts are not only accurate but also optimized for generating spatially coherent images.
Experiment
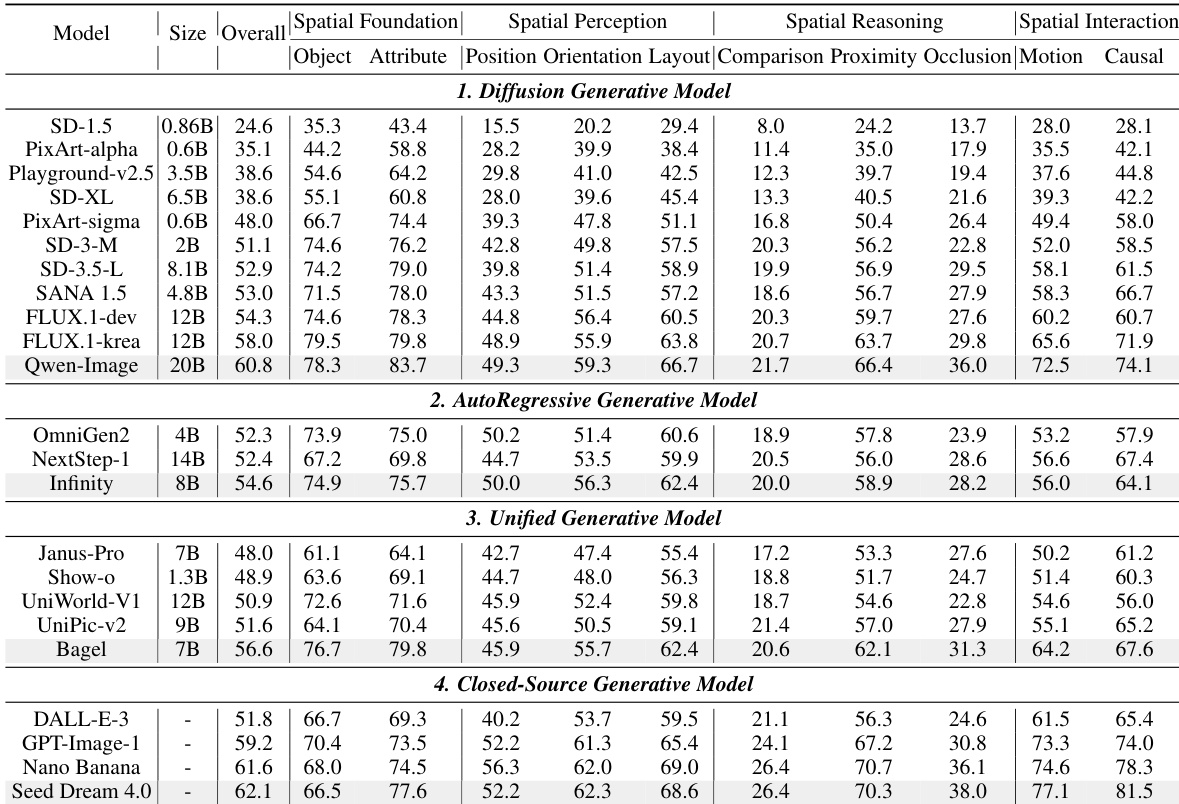
- Evaluated 23 text-to-image models (open/closed-source) on SpatialGenEval using Qwen2.5-VL-72B as judge; top performer: Seed Dream 4.0 (62.7%), closely followed by open-source Qwen-Image (60.6%).
- Spatial reasoning (e.g., comparison, occlusion) is the core bottleneck, with scores often below 30%, near random chance (20%).
- Models with stronger text encoders (e.g., LLM-based) outperform CLIP-only models; e.g., Qwen-Image (60.6%) > SD-1.5 (28.5%).
- Unified models (e.g., Bagel, 7B, 57.0%) achieve competitive results vs. larger diffusion models (e.g., FLUX.1-krea, 12B, 58.5%), showing architectural efficiency.
- Prompt rewriting via Gemini 2.5 Pro improves scores (e.g., +4.5% in Comparison for OmniGen2), especially for explicit spatial relations, but not for implicit reasoning like occlusion.
- Evaluation is robust: GPT-4o and Qwen2.5-VL-72B produce consistent rankings; human alignment study confirms MLLM evaluators are effective (balanced accuracy ~80%).
- SpatialGenEval correlates strongly with other benchmarks, validating its reliability as a generative capability indicator.
The authors use a multi-benchmark comparison to evaluate the performance of five popular text-to-image models across various spatial intelligence tasks. Results show that Qwen-Image achieves the highest score on the proposed SpatialGenEval benchmark (60.60), outperforming other models including Janus-Pro, SD-3.5-L, Flux.1-dev, and Bagel, with its ranking consistent across multiple benchmarks.

The authors use a comprehensive benchmark to evaluate 23 text-to-image models across four categories, with results showing that while open-source models are closing the gap with closed-source ones, spatial reasoning remains a significant weakness. Results show that models perform well on basic spatial tasks like object and attribute generation but struggle with complex reasoning, particularly in comparison and occlusion, where scores often fall below 30%, indicating a core limitation in binding semantic properties to structural scene logic.
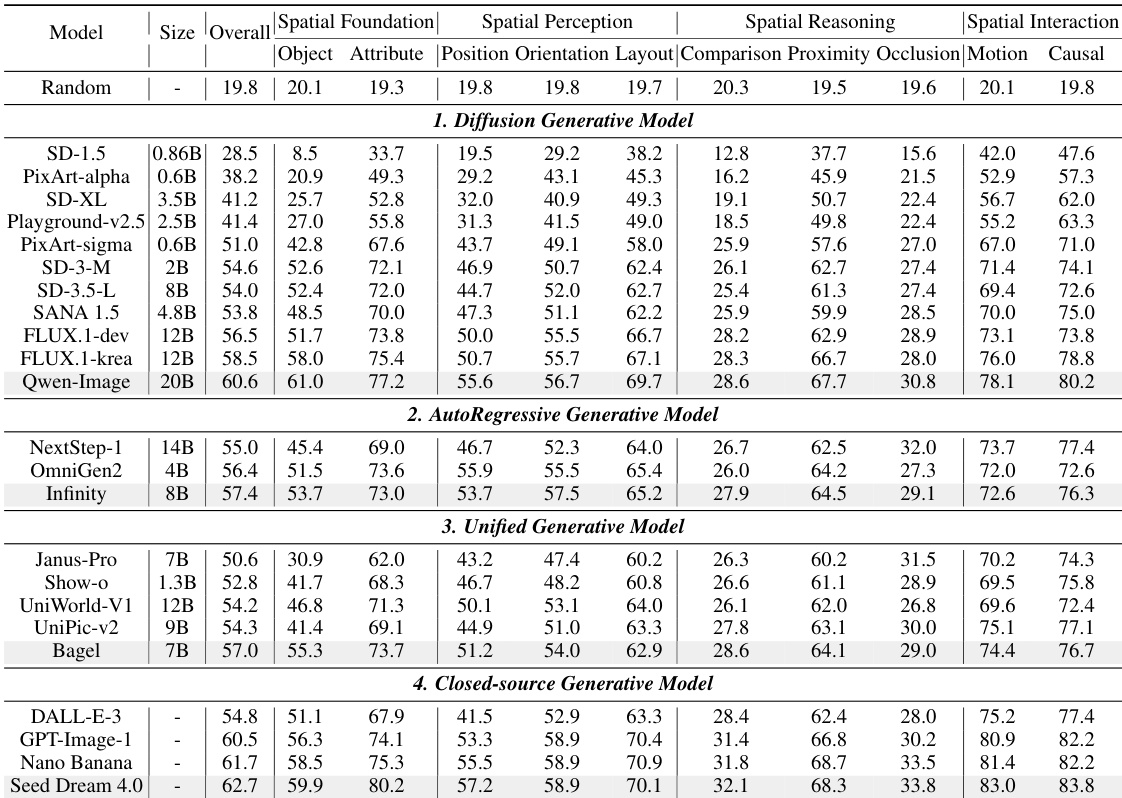
The authors use Qwen-Image to evaluate its performance on the SpatialGenEval benchmark, showing that it achieves a high overall score of 60.6% by excelling in spatial foundation and perception tasks, but still struggles with spatial reasoning and interaction, where its scores are significantly lower. Results show that while Qwen-Image outperforms random selection and no-image input across all sub-domains, its performance on spatial reasoning (42.4%) and spatial interaction (79.2%) indicates persistent weaknesses in complex spatial reasoning and interaction tasks.

The authors use a multi-round voting mechanism to evaluate text-to-image models on the SpatialGenEval benchmark, assessing their performance across four spatial dimensions. Results show that while models perform well on basic spatial foundation tasks, their accuracy drops significantly on complex reasoning subtasks like comparison and occlusion, indicating a core weakness in relational understanding.
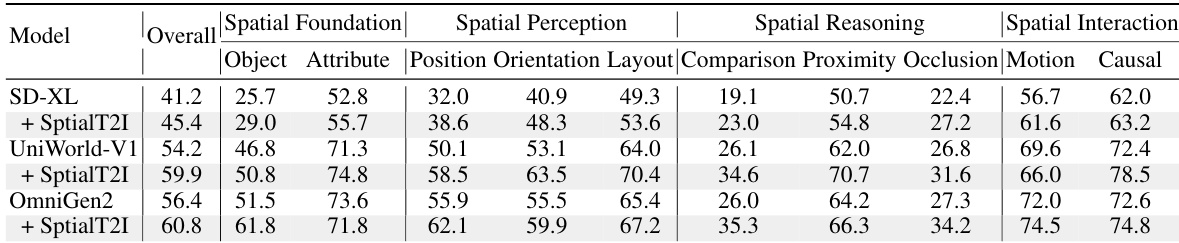
The authors use a comprehensive benchmark to evaluate 23 text-to-image models across four categories, with results showing that while open-source models are closing the gap with closed-source ones, spatial reasoning remains a significant weakness. Results show that models perform well on basic spatial tasks like object and attribute generation but struggle with complex reasoning, particularly in comparison and occlusion, where scores often fall below 30%.