Command Palette
Search for a command to run...
كيمي كي2.5: ذكاء عقلي بصري
كيمي كي2.5: ذكاء عقلي بصري
الملخص
نقدّم نموذج Kimi K2.5، نموذجًا مفتوح المصدر متعدد الوسائط يعتمد على الذكاء الوظيفي العام، صُمّم لتعزيز الذكاء الوظيفي العام. يركّز K2.5 على التحسين المشترك بين النص والرؤية، بحيث تُعزّز الوسائط المتناظرة بعضها البعض. ويشمل ذلك سلسلة من التقنيات مثل التدريب المسبق المشترك بين النص والرؤية، وتدريب التصحيح بدون رؤية (zero-vision SFT)، والتدريب المعزّز المشترك بين النص والرؤية. مستندًا إلى هذه الأساس المتعدد الوسائط، يقدّم K2.5 إطار عمل "سرب الوكيل" (Agent Swarm)، وهو إطار تنظيمي متعدد الوكالات ذاتية التوجيه، قادر على تفكيك المهام المعقدة ديناميكيًا إلى مسائل فرعية متنوعة وتنفيذها بالتوازي. أظهرت التقييمات الواسعة أن Kimi K2.5 يحقق نتائج رائدة على مستوى الحالة الحالية (SOTA) في مجالات متعددة تشمل البرمجة، والرؤية، والاستدلال، والمهام الوظيفية. كما يقلّل إطار "سرب الوكيل" من زمن التأخير (latency) بنسبة تصل إلى 4.5 مرة مقارنةً بالأساليب التقليدية التي تعتمد على وكيل واحد. ونُعلن عن إتاحة نقطة التحقق (checkpoint) للنموذج Kimi K2.5 بعد التدريب الإضافي، وذلك لتسهيل الأبحاث المستقبلية والتطبيقات الواقعية في مجال الذكاء الوظيفي.
One-sentence Summary
The Kimi Team introduces Kimi K2.5, an open-source multimodal agentic model that jointly optimizes text and vision via novel training techniques and Agent Swarm—a parallel orchestration framework that boosts efficiency up to 4.5× while achieving SOTA across coding, vision, reasoning, and agentic tasks.
Key Contributions
- Kimi K2.5 introduces joint text-vision optimization through early fusion pre-training, zero-vision SFT, and cross-modal RL, enabling bidirectional enhancement between modalities and achieving state-of-the-art performance on reasoning, coding, and vision benchmarks.
- The model features Agent Swarm, a parallel agent orchestration framework that dynamically decomposes tasks into concurrent sub-problems, reducing inference latency by up to 4.5× while improving task-level F1 scores over sequential baselines.
- Built on MoonViT-3D with native-resolution encoding and 3D ViT compression for video, K2.5 supports variable-resolution inputs and long video processing, and its open-sourced checkpoints aim to accelerate research toward general agentic intelligence.
Introduction
The authors leverage joint text-vision pre-training and reinforcement learning to build Kimi K2.5, an open-source multimodal agentic model that improves cross-modal reasoning and task execution. Prior models often treat vision and language separately, limiting their ability to handle complex, real-world agentic tasks that require both modalities to work in concert. Kimi K2.5 introduces Agent Swarm, a framework that dynamically splits tasks into parallel sub-agents, reducing latency up to 4.5x while boosting performance on coding, vision, and reasoning benchmarks. By open-sourcing the model, the team enables broader research into scalable, general-purpose agentic intelligence.
Dataset
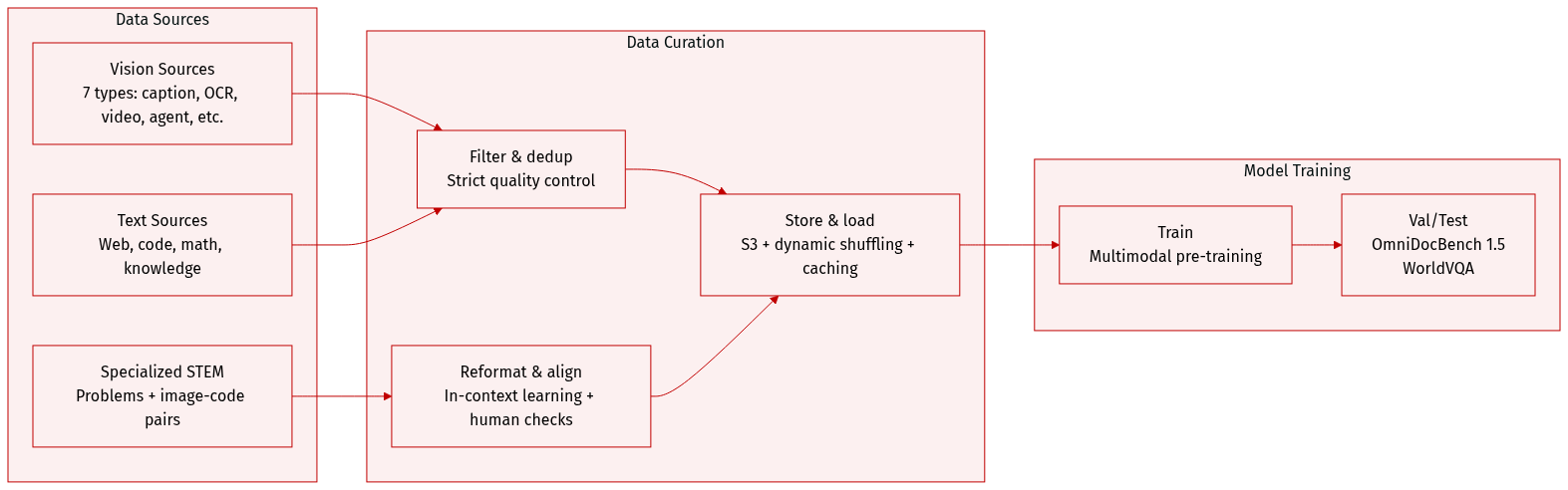
-
The authors use a multimodal pre-training corpus split into seven vision data categories: caption, interleaving, OCR, knowledge, perception, video, and agent data. Caption data ensures modality alignment with minimal synthetic content to reduce hallucination. Interleaving data from books and web pages supports multi-image and long-context learning. OCR data covers multilingual, dense, and multi-page documents. Knowledge data uses layout-parsed academic materials to build visual reasoning.
-
For STEM reasoning, they curate a specialized problem-solving corpus via targeted retrieval and web crawling. Raw materials without explicit questions are reformulated into structured academic problems (K-12 to university level) using in-context learning. Image-code pairs—spanning HTML, React, SVG—align abstract code with rendered visuals to bridge visual and code modalities.
-
Agent and temporal understanding data includes GUI screenshots and action trajectories across desktop, mobile, and web, with human-annotated demos. Video data enables hour-long comprehension and fine-grained spatio-temporal perception. Grounding data adds bounding boxes, point references, and a new contour-level segmentation task for pixel-level perception.
-
All vision data undergoes strict filtering, deduplication, and quality control to ensure diversity and effectiveness.
-
The text corpus spans four domains: Web Text, Code, Mathematics, and Knowledge. Code data is upweighted and expanded to include repository-level code, issues, reviews, commits, and code-related documents from PDFs and webtext to improve cross-file reasoning and agentic coding tasks like patch generation and unit testing.
-
For supervised fine-tuning, the authors synthesize high-quality responses using K2, K2 Thinking, and proprietary expert models. Domain-specific pipelines combine human annotation with prompt engineering and multi-stage verification to produce instruction-tuning data with diverse prompts and reasoning trajectories, training the model for interactive reasoning and tool-calling.
-
Data is stored in S3-compatible object storage. The loading infrastructure supports dynamic shuffling, blending, tokenization, and sequence packing; enables stochastic augmentation while preserving spatial metadata; ensures deterministic training via seed management; and scales efficiently via tiered caching. A unified platform manages data registration, visualization, stats, cross-cloud sync, and lifecycle governance.
-
Evaluation includes OmniDocBench 1.5 (using normalized Levenshtein distance) and WorldVQA (for fine-grained visual and geographic knowledge).
Method
The authors leverage a unified multimodal architecture for Kimi K2.5, built upon the Kimi K2 MoE transformer backbone, to enable agentic intelligence across text and vision modalities. The core framework integrates a native-resolution 3D vision encoder (MoonViT-3D), an MLP projector, and the language model, allowing seamless joint optimization of visual and textual representations. During pre-training, the model processes approximately 15 trillion mixed vision-text tokens, with early fusion of visual tokens at a constant ratio throughout training to enhance cross-modal alignment. Architecturally, MoonViT-3D employs a shared embedding space for images and videos: consecutive frames are grouped into spatiotemporal volumes, flattened into 1D sequences, and processed through a shared encoder with temporal pooling to achieve 4× compression, enabling longer video comprehension within fixed context windows.
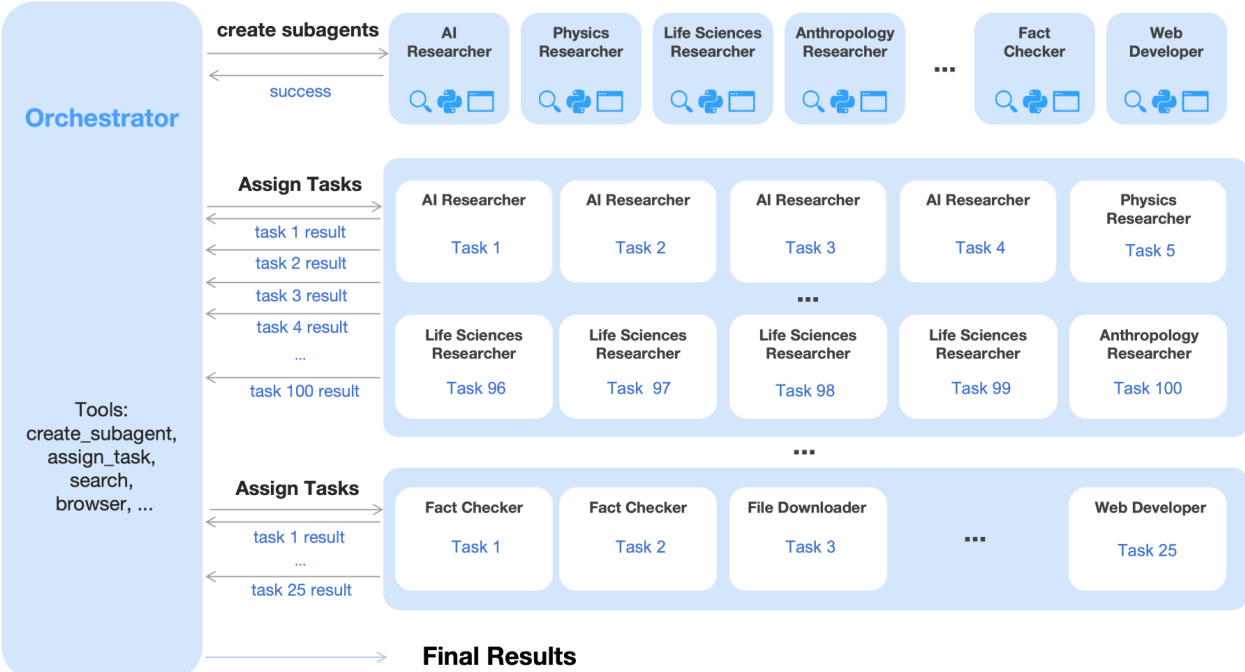
Refer to the framework diagram, which illustrates the agent orchestration mechanism. The system introduces Agent Swarm, a dynamic parallel execution framework where a trainable orchestrator creates and delegates tasks to frozen sub-agents. This decoupled architecture avoids end-to-end co-optimization, mitigating credit assignment ambiguity and training instability. The orchestrator learns to decompose complex tasks into parallelizable subtasks, such as assigning domain-specific researchers or fact-checkers, and schedules their execution based on environmental feedback. The training objective is guided by a composite PARL reward that balances subagent instantiation, task completion, and overall performance, with auxiliary terms to prevent serial collapse and spurious parallelism. Critical steps—defined as the sum of main agent steps plus the maximum subagent steps per stage—are used as a resource constraint to incentivize latency-minimizing parallelization.
The post-training pipeline begins with zero-vision SFT, where text-only supervised fine-tuning activates visual reasoning capabilities by proxying image manipulations through programmatic operations in IPython. This approach avoids the generalization degradation observed with human-designed visual trajectories. Following this, joint multimodal RL is applied across domains organized by ability rather than modality—knowledge, reasoning, coding, agentic—using a unified Generative Reward Model (GRM) that evaluates heterogeneous traces without modality barriers. Outcome-based visual RL targets grounding, chart understanding, and STEM tasks, improving not only visual performance but also textual benchmarks like MMLU-Pro and GPQA-Diamond, demonstrating bidirectional cross-modal enhancement.
The reinforcement learning algorithm employs a token-level clipped policy objective to stabilize training in long-horizon, multi-step tool-use scenarios. The reward function combines rule-based outcome signals, budget-control incentives, and GRMs that evaluate nuanced user experience criteria. To reconcile reasoning quality with computational efficiency, the authors introduce Toggle, a training heuristic that alternates between budget-constrained and unconstrained phases, dynamically adjusting optimization based on problem difficulty and model accuracy. This enables the model to generate more concise reasoning while preserving scalability to higher compute budgets.
Training infrastructure is optimized via the Decoupled Encoder Process (DEP), which separates vision encoder computation from the main transformer backbone. DEP executes vision forward passes across all GPUs to balance load, discards intermediate activations to reduce memory, and recomputes them during backward pass, achieving 90% multimodal training efficiency relative to text-only training. The unified agentic RL environment supports asynchronous, coroutine-based task execution with pluggable components for toolsets, judges, and prompt diversification, enabling scalable orchestration of up to 100,000 concurrent agent tasks.
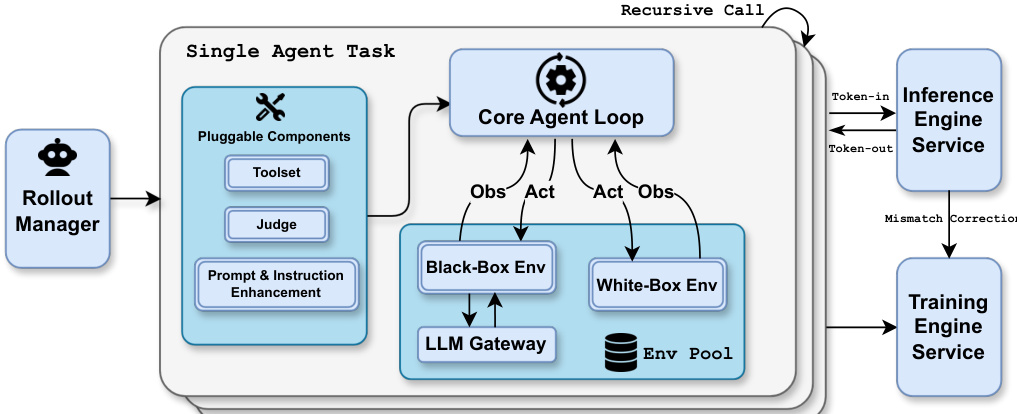
As shown in the figure below, the system demonstrates its capability on large-scale multimodal tasks, such as analyzing 32 video parts totaling 24 hours and 40GB of gameplay footage. The orchestrator spawns sub-agents to process individual videos in parallel, extracting frames, identifying key events, and aggregating results into a comprehensive HTML showcase. This workflow exemplifies the system’s ability to handle massive, heterogeneous workloads through dynamic parallel decomposition while maintaining coherent long-context understanding.

Experiment
- Early fusion with moderate vision ratios during pre-training yields better multimodal performance than late, vision-heavy strategies, challenging conventional approaches and supporting native multimodal training.
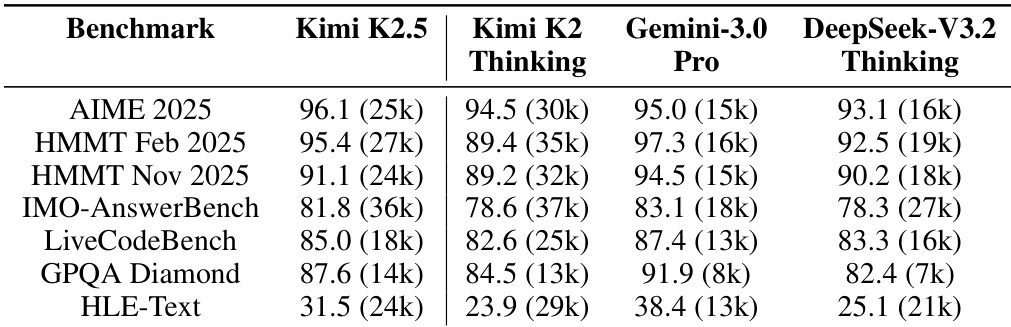
- Kimi K2.5 achieves state-of-the-art or competitive performance across diverse domains including reasoning, coding, agentic search, vision, video understanding, and computer use, often outperforming leading proprietary models.
- Agent Swarm architecture significantly boosts performance on complex agentic tasks by enabling parallel subagent execution, dynamic scheduling, and proactive context management, improving both accuracy and speed.
- The system demonstrates robust real-world capabilities through efficient handling of long-context, multi-step, and tool-intensive tasks, with strong results on benchmarks requiring synthesis, retrieval, and autonomous execution.
- Performance gains from Agent Swarm are most pronounced in high-complexity, scalable scenarios, validating that architectural parallelism translates into qualitative capability improvements beyond mere efficiency.
The authors use an agent swarm framework to dynamically orchestrate multiple specialized subagents, achieving substantial performance gains over single-agent configurations on complex agentic tasks. Results show that this approach not only improves accuracy—particularly on benchmarks requiring broad exploration or parallel decomposition—but also reduces execution time by 3x to 4.5x through parallelization. The swarm architecture enables proactive context management by isolating subtask contexts, preserving reasoning integrity while scaling effective context length.

The authors find that early integration of vision tokens at a lower ratio yields stronger overall multimodal performance compared to mid- or late-stage injection with higher vision ratios, even under a fixed token budget. Results show that early fusion preserves text capabilities better and leads to more stable training dynamics, supporting a native multimodal pre-training approach. This strategy enables more balanced co-optimization of vision and language representations from the outset.

Results show Kimi K2.5 achieves competitive or leading performance across reasoning, coding, agentic, vision, video, and computer-use benchmarks, often matching or exceeding top proprietary models like Claude Opus 4.5 and GPT-5.2 under comparable evaluation settings. The model demonstrates particular strength in complex agentic tasks and long-context reasoning, with its Agent Swarm framework delivering significant gains in both accuracy and efficiency through parallel subagent orchestration. Its native multimodal pre-training strategy, which integrates vision early at moderate ratios, supports robust cross-modal performance without sacrificing linguistic competence.
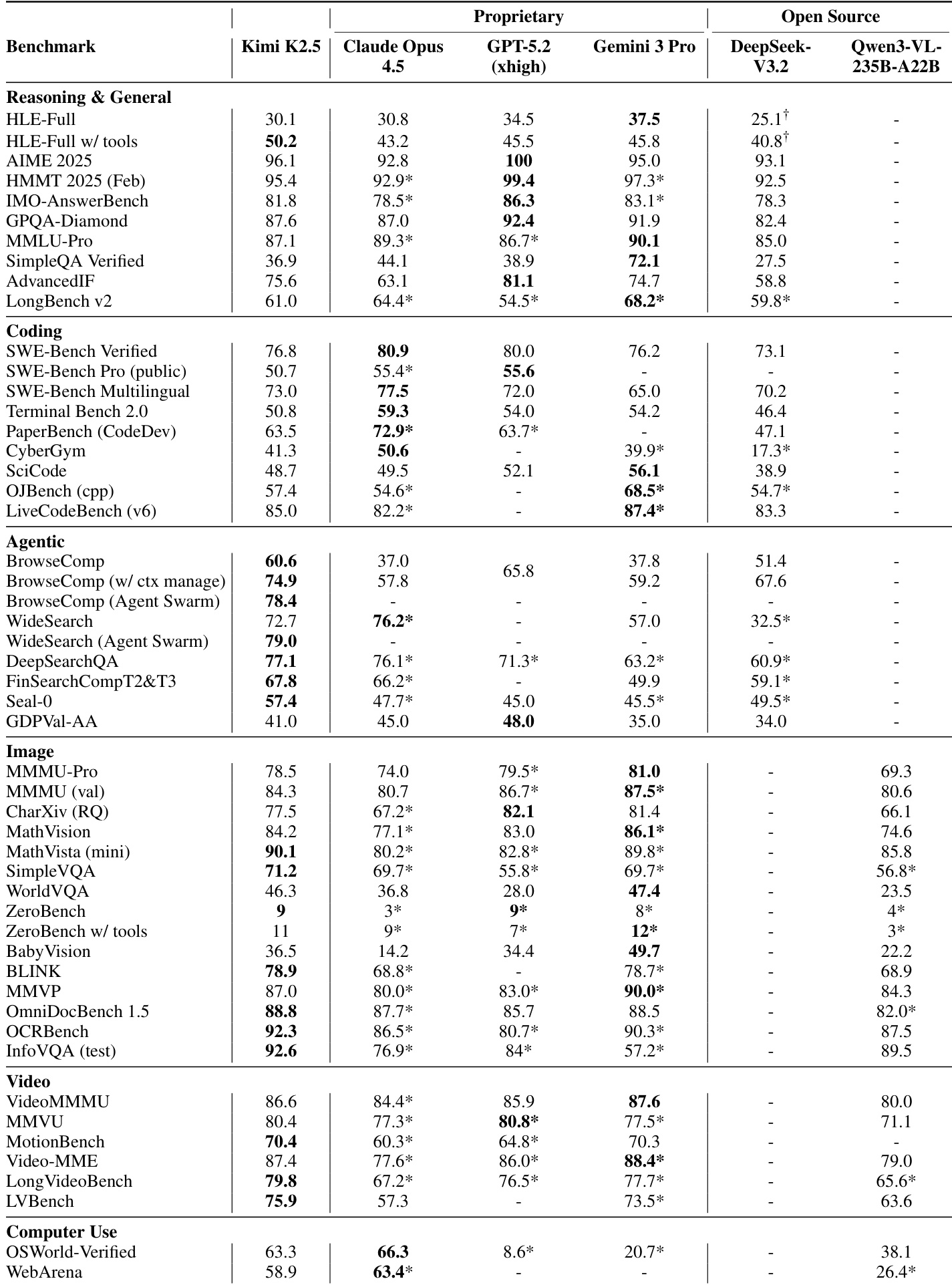
The authors use a fixed token budget to compare multimodal pre-training strategies and find that early fusion with a lower vision ratio outperforms late-stage, vision-heavy training, suggesting balanced co-optimization of modalities from the start yields more robust representations. Results show Kimi K2.5 achieves competitive or superior performance across reasoning, coding, agentic, and multimodal benchmarks, often matching or exceeding proprietary models despite using moderate vision integration and efficient context management. The agent swarm framework further boosts performance and reduces execution time by enabling parallel, context-sharded subagent execution without sacrificing reasoning integrity.
The authors use a vision reinforcement learning phase to enhance multimodal capabilities after initial pre-training. Results show consistent improvements across multiple benchmarks, including MMLU-Pro, GPQA-Diamond, and LongBench v2, indicating that targeted vision-based fine-tuning effectively boosts performance on both reasoning and long-context tasks. This suggests that post-pre-training vision alignment contributes meaningfully to broader multimodal competence.
