Command Palette
Search for a command to run...
Idea2Story: نموذج آلي لتحويل المفاهيم البحثية إلى سرديات علمية كاملة
Idea2Story: نموذج آلي لتحويل المفاهيم البحثية إلى سرديات علمية كاملة
الملخص
أحرزت الاكتشافات العلمية المستقلة باستخدام وكلاء تعتمد على نماذج اللغة الكبيرة (LLM) تقدماً كبيراً في الآونة الأخيرة، مُظهِرة القدرة على أتمتة سير العمل البحثي من البداية إلى النهاية. ومع ذلك، تعتمد الأنظمة الحالية بشكل كبير على نماذج تنفيذ متمحورة حول الوقت الفعلي، حيث تُكرر قراءة وملخصات وتأملات واسعة النطاق في الأدبيات العلمية المتاحة عبر الإنترنت. إن هذه الاستراتيجية الحسابية في الوقت الفعلي تُسبب تكاليف حسابية عالية، وتعاني من قيود نافذة السياق، وغالباً ما تؤدي إلى استنتاجات هشة ووهمية. نقترح "Idea2Story"، إطار عمل مُوجه بالحساب المسبق للاكتشاف العلمي المستقل، يحوّل فهم الأدبيات من التفكير المباشر عبر الإنترنت إلى بناء معرفي مسبق. يجمع "Idea2Story" باستمرار الأوراق العلمية المُراجعة من قبل الزمل مع تعليقات المراجعين، ويستخرج الوحدات المنهجية الأساسية، ويشكل أنماط بحث قابلة لإعادة الاستخدام، وينظمها في رسم معرفي منهجي منظم. في الوقت الفعلي، يتم مطابقة نوايا البحث غير المحددة بدقة مع النماذج البحثية المثبتة، مما يمكّن من استرجاع واستخدام أنماط بحث عالية الجودة بكفاءة، بدلًا من التوليد المفتوح والتجريب والخطأ. من خلال تأسيس تخطيط البحث وتنفيذه على رسم معرفي مُبنى مسبقًا، يخفف "Idea2Story" من عائق نافذة السياق في نماذج اللغة الكبيرة، ويقلل بشكل كبير من التفكير المتكرر في الوقت الفعلي على الأدبيات. أجرينا تحليلات نوعية ودراسات تجريبية أولية تُظهر أن "Idea2Story" قادر على إنتاج أنماط بحث متماسكة ومنهجية وابتكارية، ويمكنه أيضًا إنجاز عدة عروض بحثية عالية الجودة في بيئة متكاملة من البداية إلى النهاية. تشير هذه النتائج إلى أن بناء المعرفة المسبق يُعد أساسًا عمليًا وقابلًا للتوسع للاكتشاف العلمي المستقل الموثوق.
One-sentence Summary
The AgentAlpha team proposes Idea2Story, a pre-computation framework that builds a methodological knowledge graph from peer-reviewed papers to ground vague research ideas into structured, reusable patterns—reducing LLM context limits and hallucination while enabling efficient, novel scientific discovery without runtime literature reprocessing.
Key Contributions
- Idea2Story introduces a pre-computation-driven framework that constructs a structured methodological knowledge graph from peer-reviewed papers and reviews, replacing inefficient runtime literature processing with offline knowledge curation to improve scalability and reduce hallucination.
- The system grounds user research intents by retrieving and composing validated research patterns from the knowledge graph, enabling efficient, context-aware planning that circumvents LLM context window limits and avoids open-ended trial-and-error generation.
- Preliminary empirical studies show Idea2Story generates coherent, novel, and methodologically grounded research demonstrations end-to-end, validating the practical feasibility of offline knowledge construction for autonomous scientific discovery.
Introduction
The authors leverage large language models to automate scientific discovery but address key inefficiencies in existing systems that rely on real-time, context-heavy literature processing. Prior approaches suffer from high computational costs, context window limits, and brittle reasoning due to repeated online summarization and trial-and-error exploration. Idea2Story introduces a pre-computation framework that builds a structured knowledge graph offline by extracting and organizing methodological units from peer-reviewed papers and their reviews. At runtime, it maps vague research intents to validated research patterns from this graph, enabling faster, more reliable, and more coherent scientific planning without reinventing known methods. This shift reduces hallucination risk and computational load while grounding research in empirically supported paradigms.
Dataset

-
The authors construct a paper pool from ~13,000 accepted machine learning papers (5,000 from NeurIPS, 8,000 from ICLR) published within the most recent three-year window, retaining full text (title, abstract, body) and associated review artifacts (comments, ratings, confidence scores, meta-reviews).
-
Each paper undergoes anonymization to remove author/reviewer identifiers (names, affiliations, emails) and safety filtering to eliminate toxic or abusive content, yielding a de-identified corpus that preserves technical and evaluative signals while minimizing privacy and safety risks.
-
The dataset is used to train Idea2Story, which leverages the paper-review pairs to learn how research contributions are framed and evaluated, supporting retrieval and composition of reusable methodological patterns rather than domain-specific content.
-
The knowledge graph built from this data reveals a hub-and-spoke structure: high-frequency domains act as hubs connecting many papers, while methodological patterns often bridge multiple domains—enabling abstraction-aware retrieval and synthesis beyond paper-level similarity.
Method
The framework of Idea2Story operates through a two-stage paradigm that decouples offline knowledge construction from online research generation, enabling the system to transform informal user ideas into structured, academically grounded research directions. The overall architecture is divided into an offline phase for building a persistent methodological knowledge base and an online phase for grounding user inputs and generating refined research patterns.
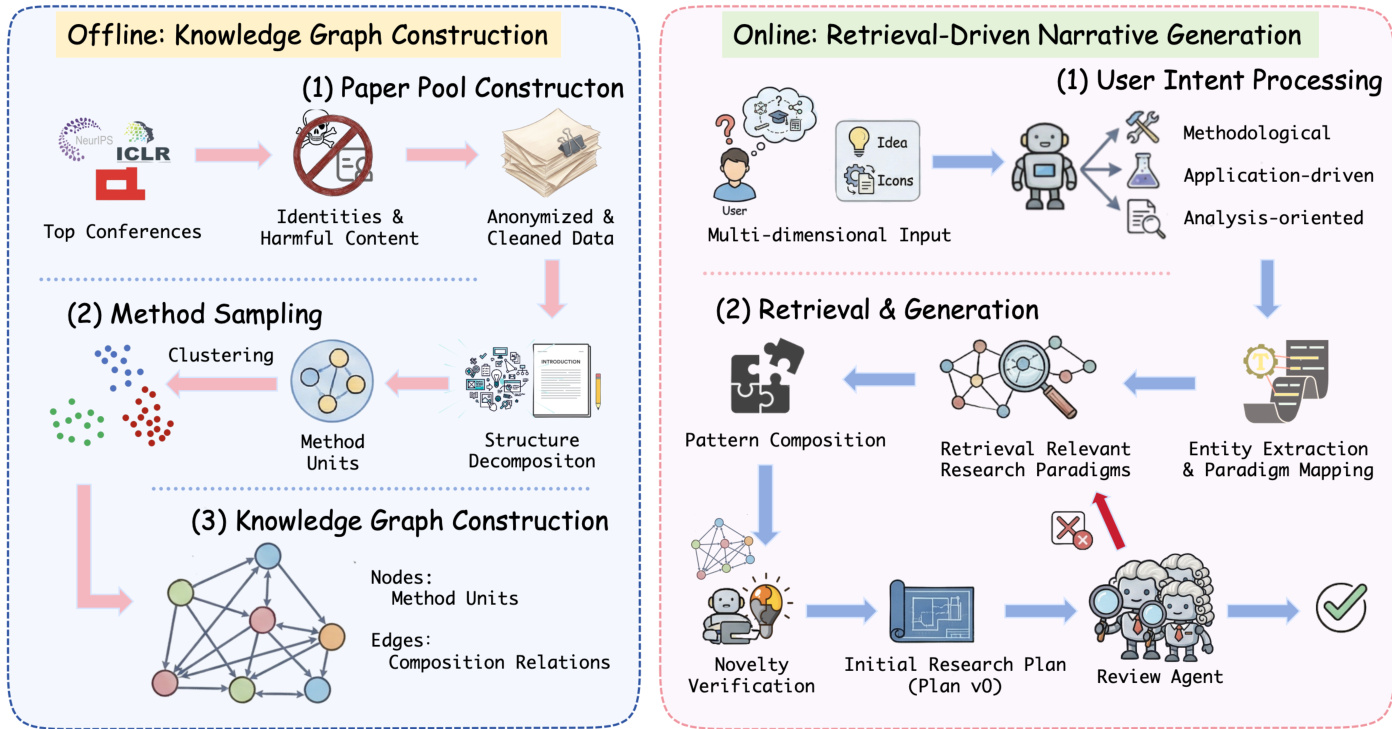
In the offline stage, the system begins by constructing a curated paper pool from top-tier peer-reviewed conferences, filtering out identities and harmful content to ensure privacy and safety. This anonymized and cleaned dataset undergoes method unit extraction, where each paper is deconstructed into its core methodological contributions. The extraction process leverages the structured layout of academic papers, analyzing the introduction, method, and experiments sections to isolate reusable method units that capture essential technical ideas while excluding implementation-specific details such as hyperparameter tuning or dataset selection. Each method unit is normalized into structured attributes, including atomic meta-methods and composition-level patterns, and represented as a vector embedding derived from its associated units. These embeddings are then projected into a lower-dimensional space using UMAP, followed by density-based clustering with DBSCAN to identify coherent research patterns that represent recurring methodological structures across the literature.
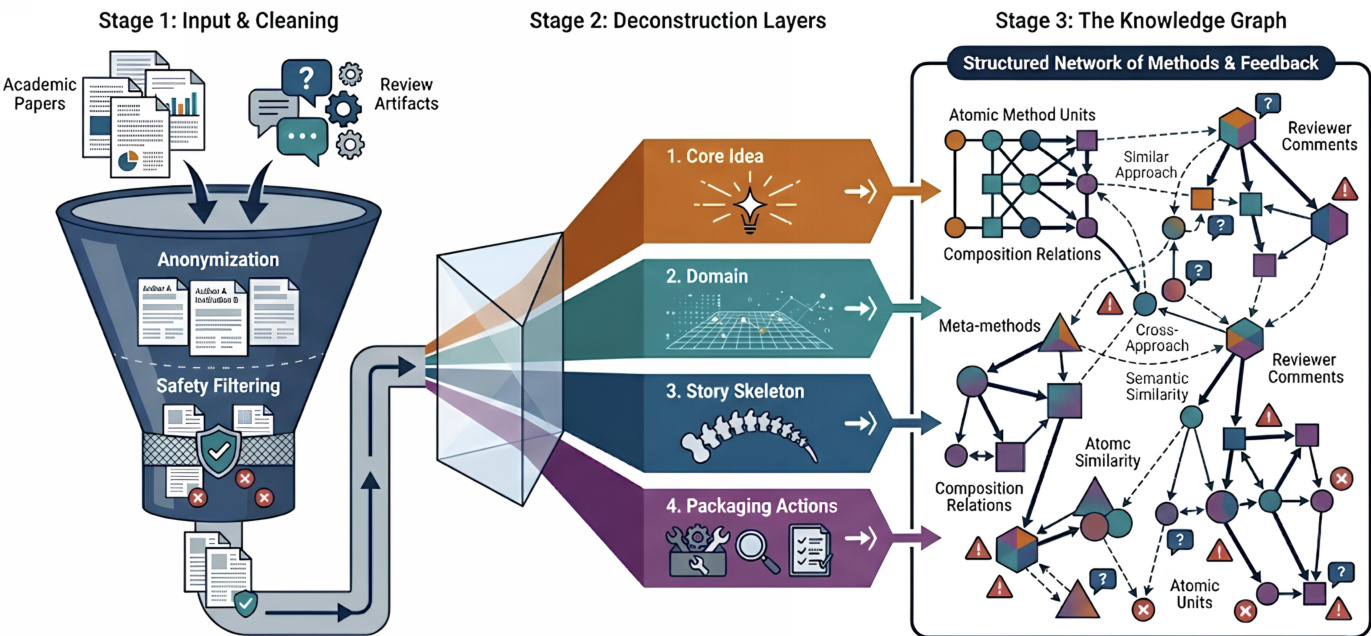
The extracted method units and research patterns are organized into a structured knowledge graph, which serves as a persistent methodological memory. This graph is defined as a directed graph G=(V,E), where nodes represent canonicalized method units or meta-methods, and edges encode composition relations between method units observed in prior work. Canonicalization groups semantically similar units into shared abstractions, reducing surface-level variation while preserving core methodological intent. The graph explicitly captures both reusable methodological elements and empirically observed compatibility, enabling the system to reason about methods at a higher level of abstraction than individual papers.
In the online stage, given a user-provided research idea, the system treats method discovery as a graph-based retrieval and composition problem over the knowledge graph. The process begins with user intent processing, where the input is interpreted as a multi-dimensional query that can be methodological, application-driven, or analysis-oriented. The system then performs retrieval and generation by identifying relevant research patterns through a multi-view retrieval formulation. This approach aggregates complementary signals from idea-level, domain-level, and paper-level retrieval views, each contributing a relevance score based on semantic similarity to the input query. The final ranking of research patterns is determined by a weighted sum of these view-specific scores, producing a ranked list of candidate patterns.
Following retrieval, the system initiates a review-guided refinement loop. A large language model acts as a reviewer, evaluating the retrieved research patterns on criteria such as technical soundness, novelty, and conceptual coherence. Based on the feedback, the system iteratively revises the pattern by recombining compatible method units or adjusting the problem formulation. This generate–review–revise loop continues until the pattern meets the reviewer's criteria for novelty, coherence, and feasibility, or until no further improvement is observed. The output is a refined research pattern that serves as a structured blueprint for downstream planning and paper generation.
Experiment
- Evaluated Idea2Story on 13K ICLR and NeurIPS papers to assess its ability to extract reusable methodological structures and generate coherent research patterns from ambiguous inputs.
- Analyzed extracted method units to confirm they represent meaningful, reusable abstractions.
- Conducted qualitative case studies using three real user ideas, comparing Idea2Story (powered by GLM-4.7) against a direct LLM baseline that lacks explicit pattern modeling.
- Found that Idea2Story reframes vague intent into dynamic, structurally grounded research blueprints, emphasizing generative refinement and evolving representations.
- Direct LLM outputs remained abstract, relied on conventional formulations, and lacked concrete methodological grounding.
- Independent evaluation by Gemini 3 Pro consistently favored Idea2Story for novelty, methodological substance, and overall research quality.