Command Palette
Search for a command to run...
アルケミスト:メタ勾配データ選択によるテキストから画像へのモデル学習における効率性の解禁
アルケミスト:メタ勾配データ選択によるテキストから画像へのモデル学習における効率性の解禁
Kaixin Ding Yang Zhou Xi Chen Miao Yang Jiarong Ou Rui Chen Xin Tao Hengshuang Zhao
概要
テキストから画像(Text-to-Image, T2I)を生成する生成モデルの近年の進展、例えばImagen、Stable Diffusion、FLUXなどは、視覚的品質において顕著な向上をもたらした。しかし、これらのモデルの性能は、訓練データの質に根本的に制約されている。ウェブクロールや合成画像から構成されるデータセットには、低品質または重複したサンプルが頻繁に含まれており、これにより視覚的忠実度の低下、学習の不安定化、計算効率の悪化が生じる。したがって、データ効率を向上させるためには、効果的なデータ選択が不可欠である。従来のアプローチは、高コストな手動によるデータ選別、あるいはテキスト-画像データフィルタリングにおいて単一次元の特徴に基づくヒューリスティックスコアリングに依存している。一方で、大規模言語モデル(LLM)ではメタラーニングに基づく手法が検討されているが、画像モダリティへの適用はまだ行われていない。この課題に対応するため、本研究では、大規模なテキスト-画像データペアから適切なサブセットを選択するためのAlchemistという、メタ勾配に基づくフレームワークを提案する。本手法は、データ中心の視点からモデルを反復的に最適化することで、各サンプルの影響力を自動的に学習する。Alchemistは、データ評価(data rating)とデータ削減(data pruning)という2つの主要ステージから構成される。まず、勾配情報に基づき、マルチスケールの認識能力を強化した軽量なレーティングモデルを訓練し、各サンプルの影響力を推定する。その後、情報量の高いサブセットを効率的なモデル学習に向け選定するために、Shift-Gsampling戦略を採用する。Alchemistは、T2Iモデルの学習に向けた、自動的かつスケーラブルなメタ勾配ベースのデータ選択フレームワークとして、世界初のものである。合成データおよびウェブクロールデータセットを用いた実験の結果、Alchemistは一貫して視覚的品質と下流タスク性能の向上を示した。Alchemistによって選別されたデータの50%で学習を行った場合でも、全データセットを用いた学習よりも優れた性能が達成された。
One-sentence Summary
Researchers from The University of Hong Kong, South China University of Technology, and Kuaishou Technology's Kling Team propose Alchemist, a meta-gradient-based framework for efficient Text-to-Image training that automatically selects high-impact data subsets. Unlike prior heuristic or manual methods, it employs a gradient-informed rater with multi-granularity perception and optimized sampling to identify informative samples, enabling models trained on just 50% of Alchemist-selected data to surpass full-dataset performance in visual fidelity and efficiency.
Key Contributions
- Text-to-Image models like Stable Diffusion face performance bottlenecks due to low-quality or redundant samples in web-crawled training data, which degrade visual fidelity and cause unstable training; existing data selection methods rely on costly manual curation or single-dimensional heuristics that fail to optimize for downstream model performance.
- Alchemist introduces a meta-gradient-based framework that automatically rates data samples using gradient-informed multi-granularity perception and employs a shift-Gaussian sampling strategy to prioritize mid-to-late scored samples, which exhibit more informative gradient dynamics and avoid overfitting from top-ranked plain samples.
- Validated on synthetic and web-crawled datasets, Alchemist-selected subsets (e.g., 50% of data) consistently outperform full-dataset training in visual quality and model performance, with empirical evidence showing optimal data lies in mid-to-late score ranges that balance learnability and diversity.
Introduction
The authors address data selection for text-to-image (T2I) model training, where efficiently identifying high-quality text-image pairs from large datasets is critical for reducing computational costs and improving model performance. Prior approaches typically use Top-K pruning—retaining only the highest-rated samples—but this often causes rapid overfitting due to uninformative, low-gradient samples in the top tier, while ignoring more dynamically valuable mid-to-late range data. The authors demonstrate that top-ranked samples exhibit minimal gradient changes during training, contributing little to learning, whereas mid-to-late range samples drive effective model updates but are discarded by conventional methods. Their key contribution is the pruning-based shift-Gaussian sampling (Shift-Gsample) strategy: it first discards the top n% of samples to avoid overfitting, then applies Gaussian sampling centered in the mid-to-late percentile range to balance data informativeness and diversity. This approach selectively retains detailed yet learnable samples, filters out plain or chaotic data, and achieves superior performance by aligning with human intuition for robust T2I training.
Method
The authors leverage a meta-gradient-based framework called Alchemist to enable data-efficient training of Text-to-Image (T2I) models by automatically selecting high-value subsets from large-scale text-image pairs. The overall pipeline consists of two principal stages: data rating and data pruning, which together form a scalable, model-aware data curation system. Refer to the framework diagram for a high-level overview of the workflow.
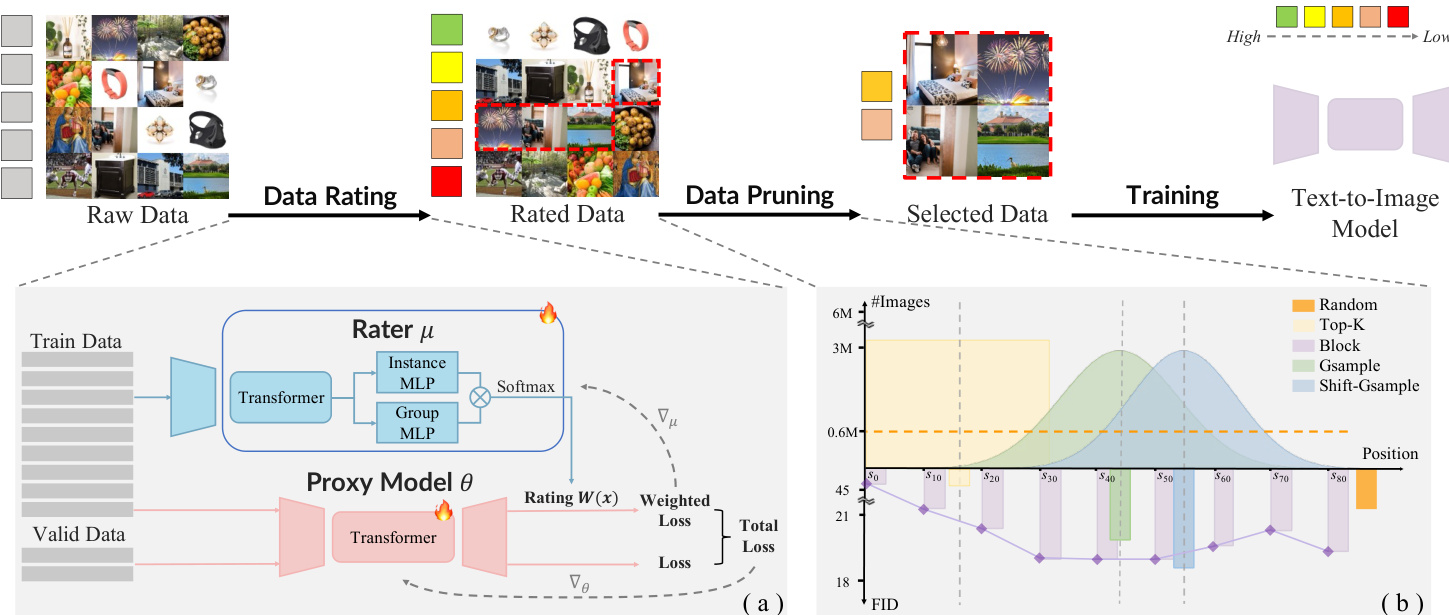
In the data rating stage, a lightweight rater network parameterized by μ is trained to assign a continuous weight Wxi(μ)∈[0,1] to each training sample xi. This weight reflects the sample’s influence on the downstream model’s validation performance. The rater is optimized via a bilevel formulation: the inner loop updates the proxy T2I model θ using a weighted loss over the training set, while the outer loop adjusts μ to minimize the validation loss. To avoid the computational burden of full inner-loop optimization, the authors adopt a meta-gradient approximation. During training, a reference proxy model θ^ is warmed up using standard training data, while the primary model θ is updated using a combination of validation gradients and weighted training gradients:
θk+1=θk−βk(gval(θk)+gtrain(θk,μk))where gtrain(θk,μk)=∑xi∈DtrainWxi(μk)∇θL(θk;xi). The rater’s parameters are then updated using an approximate gradient derived from the difference in loss between the primary and reference models:
μk+1=μk−αkL(θk;xi)∇μWxi(μk)To stabilize training, weights are normalized per batch via softmax:
Wxi=∑jexp(W^xj)exp(W^xi)To account for batch-level variability and enhance robustness, the rater incorporates multi-granularity perception. It includes two parallel MLP modules: an Instance MLP that processes individual sample features and a Group MLP that computes a batch-level weight from pooled statistics (mean and variance) of the batch. The final weight for each sample is the product of its instance weight and batch weight, enabling the rater to capture both local distinctiveness and global context.
In the data pruning stage, the authors introduce the Shift-Gsample strategy to select a subset of the rated data. This strategy prioritizes samples from the middle-to-late region of the rating distribution—those that are neither too easy (low gradient impact) nor too hard (outliers or noisy)—but are sufficiently informative and learnable. As shown in the figure below, this approach outperforms random sampling, top-K selection, and block-based methods in terms of both sample count and downstream FID performance.
The selected dataset is then used to train the target T2I model, achieving comparable or superior performance with significantly fewer training samples—often as little as 50% of the original corpus—while accelerating convergence and improving visual fidelity.
Experiment
- Alchemist data selection: 50% subset matched full dataset performance on MJHQ-30K and GenEval benchmarks, surpassing random sampling
- 20% Alchemist-selected data matched 50% random data performance, demonstrating significant data efficiency gains
- Achieved 2.33× faster training at 20% retention and 5× faster at 50% retention while matching random sampling results
- Consistently outperformed baselines across STAR (from-scratch) and FLUX-mini (LoRA fine-tuning) models
- Generalized to HPDv3-2M and Flux-reason-6M datasets, surpassing random selection at 20% and 50% retention rates
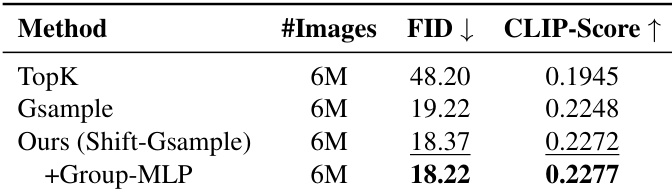
The authors use a Shift-Gsample pruning strategy with a Group-MLP to select informative data, achieving the lowest FID and highest CLIP-Score among compared methods on 6M image-text pairs. Results show that incorporating group-level information further improves performance over sample-level selection alone.
The authors use Alchemist to select subsets of HPDv3-2M and Flux-reason-6M datasets, achieving lower FID and higher CLIP-Score than random sampling at both 20% and 50% retention. Results show that even with half the data, Alchemist-selected subsets outperform randomly sampled ones, confirming its effectiveness across diverse data domains.
The authors use Alchemist to select a 50% subset of the LAION dataset, achieving better FID and CLIP-Score than training on the full dataset while matching its training time. Results show that even a smaller 20% subset (Ours-small) trained in less than half the time still outperforms several heuristic-based selection methods on GenEval. Alchemist’s selected data consistently improves efficiency and performance compared to random sampling and other image quality metrics.
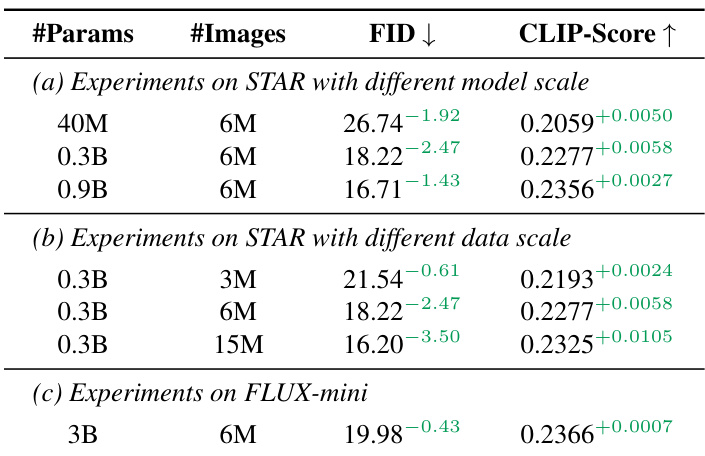
The authors use Alchemist to select training data for STAR and FLUX-mini models, showing consistent performance gains over random sampling across model scales and data sizes. Results show that using 6M Alchemist-selected images improves FID and CLIP-Score compared to both smaller and larger random subsets, and similar gains hold for FLUX-mini with 3B parameters. The method demonstrates scalability, as larger models and different architectures benefit from the same selected data without additional rater training.