Command Palette
Search for a command to run...
Depth Any Panoramas: パノラマ深度推定のためのファウンデーションモデル
Depth Any Panoramas: パノラマ深度推定のためのファウンデーションモデル
Xin Lin Meixi Song Dizhe Zhang Wenxuan Lu Haodong Li Bo Du Ming-Hsuan Yang Truong Nguyen Lu Qi
概要
本研究では、多様なシーン距離にわたる汎化性能を備えたパノラマメトリック深度基礎モデルを提案する。データ構築とフレームワーク設計の両面から「データをループに組み込む」パラダイムを検討した。大規模なデータセットを、公開データセットと、自社開発のUE5シミュレータから得た高品質な合成データ、テキストから画像を生成するモデル(text-to-image models)を用いたデータ、およびウェブ上から収集した実際のパノラマ画像を統合することで構築した。室内/室外、合成データ/実データ間のドメインギャップを低減するため、ラベルなし画像に対して信頼性の高い真値を生成するための三段階の擬似ラベル選別パイプラインを導入した。モデル構造においては、強力な事前学習による汎化性能を備えるDINOv3-Largeをバックボーンとして採用し、プラグアンドプレイ型の距離マスクヘッド、シャープネス中心の最適化、幾何学的整合性を重視した最適化を導入することで、距離の変化に対するロバスト性を向上させ、複数視点間の幾何学的整合性を強制した。複数のベンチマーク(例:Stanford2D3D、Matterport3D、Deep360)における実験結果から、優れた性能とゼロショット汎化能力を確認でき、特に多様な実世界シーンにおいて安定かつ堅牢なメトリック深度予測が可能であることが示された。プロジェクトページは以下の通り:https://insta360-research-team.github.io/DAP_website/
One-sentence Summary
Insta360 Research, UC San Diego, and Wuhan University propose DAP, a panoramic metric depth foundation model using a data-in-the-loop paradigm that fuses synthetic and real data with a three-stage pseudo-label pipeline. Leveraging DINOv3-Large with range mask head and geometry optimizations, it achieves robust zero-shot depth estimation across diverse real-world scenes, outperforming benchmarks like Stanford2D3D through enhanced distance robustness and cross-view consistency.
Key Contributions
- The work addresses the challenge of poor generalization in panoramic depth estimation across diverse real-world scenes, particularly outdoors, due to limited and non-diverse training data that hinders robust metric depth prediction for applications like robotic navigation.
- It introduces a three-stage pseudo-label curation pipeline that bridges indoor-outdoor and synthetic-real domain gaps by progressively refining ground truth for unlabeled images, alongside a foundation model with a plug-and-play range mask head and geometry/sharpness-centric optimizations to enforce metric consistency across varying distances.
- Evaluated on Stanford2D3D, Matterport3D, and Deep360 benchmarks, the model demonstrates strong zero-shot generalization and robust metric depth predictions in complex real-world scenarios, achieving state-of-the-art performance with perceptually coherent and scale-consistent outputs.
Introduction
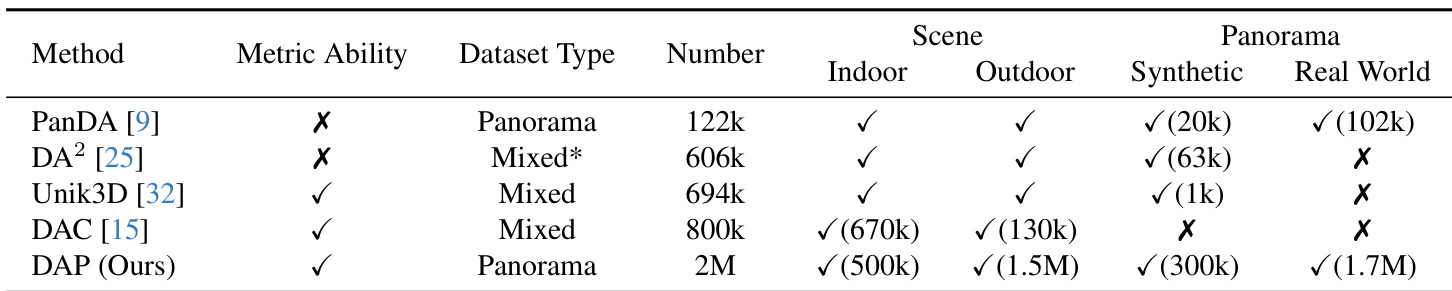
Panoramic depth estimation enables critical spatial intelligence for robotics, such as omnidirectional obstacle avoidance, by capturing full 360°×180° environmental coverage. However, existing methods—both panorama-specific relative-depth approaches and unified metric-depth frameworks—struggle to generalize across diverse real-world scenes, particularly outdoors, due to limited training data scale and diversity caused by high collection and annotation costs. The authors address this by introducing a data-in-the-loop paradigm that constructs a 2M+ sample dataset spanning synthetic and real domains, including curated indoor data, photorealistic outdoor simulations, and internet-sourced panoramas. They further develop a three-stage pseudo-label curation pipeline to bridge indoor-outdoor and synthetic-real domain gaps, alongside a foundation model incorporating geometry-aware losses and a plug-and-play depth-range mask for metric-consistent, scale-invariant depth estimation across complex real-world scenarios.
Dataset
The authors introduce the DAP data engine, a unified dataset scaling to 2 million panoramas across synthetic/real and indoor/outdoor domains. Key components include:
-
DAP-2M-Labeled (90K samples):
- Source: High-fidelity Airsim360 simulations of drone flights.
- Content: Pixel-aligned depth maps and panoramas from 5 outdoor scenes (e.g., NYC, Rome), covering 26,600+ sequences.
- Filtering: None specified beyond simulation parameters.
-
DAP-2M-Unlabeled (1.7M samples):
- Source: Internet-sourced panoramic videos (250K videos → 1.7M frames after processing).
- Filtering: Horizon validation to remove invalid samples; categorized via Qwen2-VL into 250K indoor and 1.45M outdoor.
- Augmentation: 200K additional indoor samples generated via DiT-360 to address scarcity.
The paper uses this data in a three-stage semi-supervised pipeline:
- Stage 1: Trains a Scene-Invariant Labeler on DAP-2M-Labeled for initialization.
- Stage 2: Uses a PatchGAN discriminator to select 600K high-confidence pseudo-labeled samples (300K indoor/outdoor each) from DAP-2M-Unlabeled, bridging synthetic-real domain gaps.
- Stage 3: Trains the final model on all labeled and pseudo-labeled data (2M total), enabling cross-domain generalization.
Processing details include horizon-based filtering for real data, Qwen2-VL for scene categorization, and DiT-360 for synthetic indoor data expansion. No cropping strategies are mentioned; depth maps remain pixel-aligned for synthetic data.
Method
The authors leverage a three-stage pseudo-label curation pipeline to construct a large-scale, high-quality training dataset for panoramic metric depth estimation, effectively bridging domain gaps between synthetic and real, indoor and outdoor environments. The pipeline begins with Stage 1, where a Scene-Invariant Labeler is trained on 20k synthetic indoor and 90k synthetic outdoor images with accurate metric depth annotations. This stage aims to learn depth cues that generalize across diverse scene geometries and lighting conditions, providing a robust foundation for pseudo-label generation. As shown in the framework diagram, the Scene-Invariant Labeler is then applied to 1.9M unlabeled real panoramic images to generate initial depth predictions.
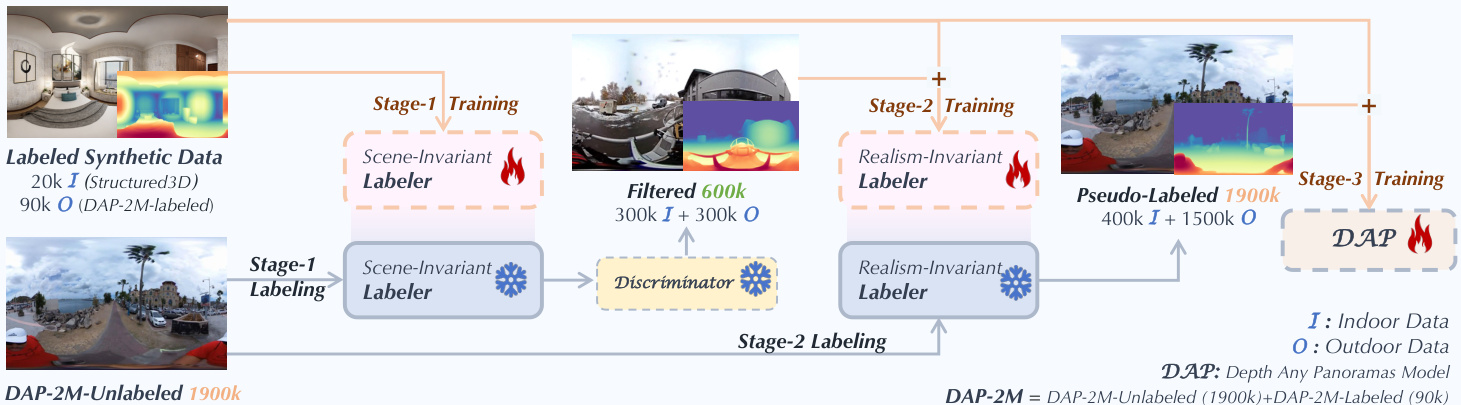
In Stage 2, a depth quality discriminator is pre-trained to distinguish between synthetic ground-truth depth maps (real) and Scene-Invariant Labeler outputs (fake), enabling scene-agnostic quality assessment. The top 300K indoor and 300K outdoor real images, as ranked by the discriminator, are selected as high-confidence pseudo-labeled data. These are combined with the synthetic datasets to train a Realism-Invariant Labeler, which learns to generalize beyond synthetic textures and lighting, improving robustness to real-world appearance variations. Stage 3 then trains the final DAP model on the full 1.9M pseudo-labeled dataset, along with previously labeled data, enabling dense supervision and strong generalization.
For the model architecture, the authors adopt DINOv3-Large as the visual backbone, chosen for its strong pre-trained generalization capabilities. The network features a dual-head design: a metric depth head that predicts a dense depth map D, and a plug-and-play range mask head that outputs a binary mask M defining valid spatial regions under predefined distance thresholds (10 m, 20 m, 50 m, 100 m). The final metric depth output is computed as M⊙D, ensuring physical validity and scale consistency across varying scene scales. The range mask head is optimized using a combination of weighted BCE and Dice losses:
Lmask=∥M−Mgt∥2+0.5LDice(M,Mgt),where M and Mgt denote predicted and ground-truth masks.
Training is guided by a multi-objective loss function that integrates both geometry-centric and sharpness-centric optimizations. The geometry-centric component includes the normal loss Lnormal, which computes the L1 distance between predicted and ground-truth surface normals npred,ngt∈RH×W×3:
Lnormal=∥npred(i,j)−ngt(i,j)∥1.Additionally, a point cloud loss Lpts is applied by projecting depth maps into spherical coordinates to obtain 3D point clouds Ppred,Pgt∈RH×W×3:
Lpts=∥Ppred(i,j)−Pgt(i,j)∥1.The sharpness-centric component introduces a dense fidelity loss LDF, which decomposes the equirectangular projection into 12 perspective patches using virtual cameras positioned at the vertices of an icosahedron. For each patch, a Gram-based similarity is computed between predicted and ground-truth depth maps:
LDF=N1k=1∑NDpred(k)⊙Dpred(k)T−Dgt(k)⊙Dgt(k)TF2,where N=12. To preserve edge fidelity directly in the ERP domain, a gradient-based loss Lgrad is applied within edge regions masked by Sobel operators:
Lgrad=LSILog(ME⊙Dpred,ME⊙Dgt).The overall training objective is a weighted sum of all losses, modulated by a distortion map Mdistort to account for non-uniform pixel distribution in equirectangular projections:
Ltotal=Mdistort⊙(λ1LSILog+λ2LDF+λ3Lgrad+λ4Lnormal+λ5Lpts+λ6Lmask),(ℓ=1,2,3,4,5,6).As shown in the architecture diagram, this multi-faceted optimization strategy ensures metric accuracy, edge fidelity, and geometric consistency across panoramic views.
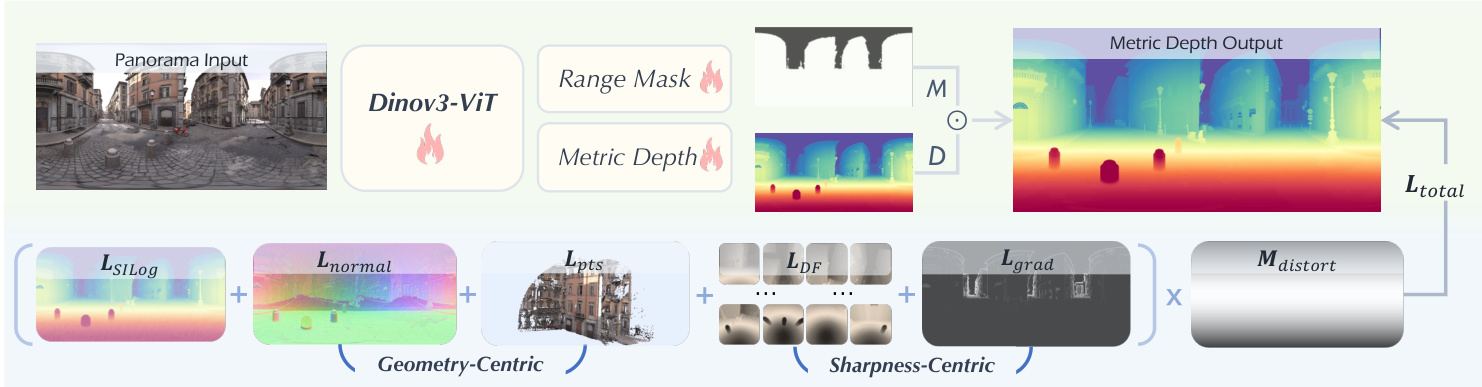
The authors further incorporate a distortion-aware depth decoder to mitigate stretching artifacts near the poles, enhancing the fidelity of depth predictions in high-distortion regions. This comprehensive design enables DAP to adapt robustly to diverse spatial scales and scene types, delivering stable and accurate metric depth estimation across real-world panoramic environments.
Experiment
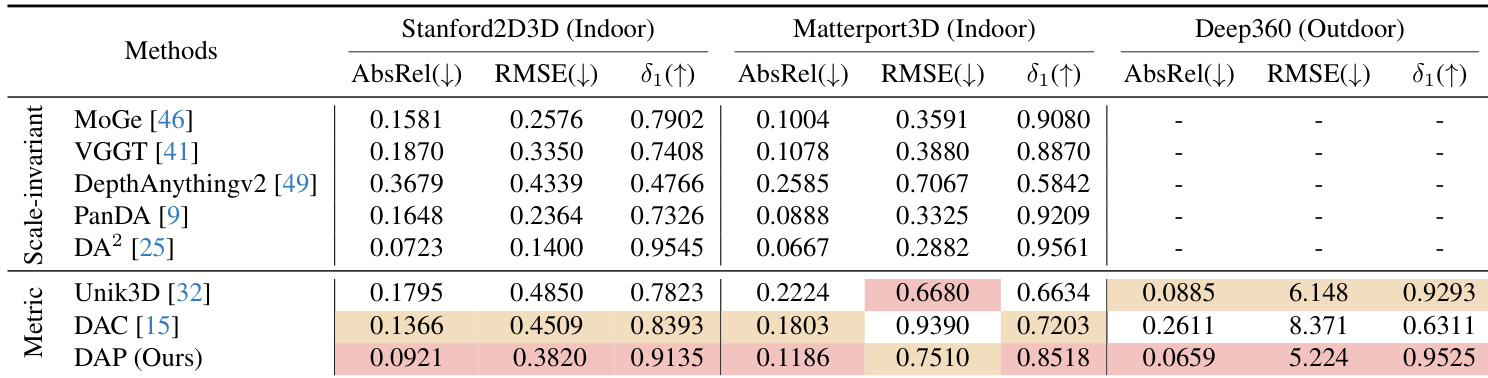
- DAP model evaluated on Stanford2D3D, Matterport3D, and Deep360 benchmarks achieves state-of-the-art zero-shot metric depth estimation without fine-tuning, significantly lowering AbsRel and increasing δ₁ compared to prior methods.
- On the DAP-Test benchmark, DAP reduces AbsRel from 0.2517 to 0.0781 and RMSE from 10.563 to 6.804 while raising δ₁ from 0.6086 to 0.9307 versus previous top methods (DAC and Unik3D).
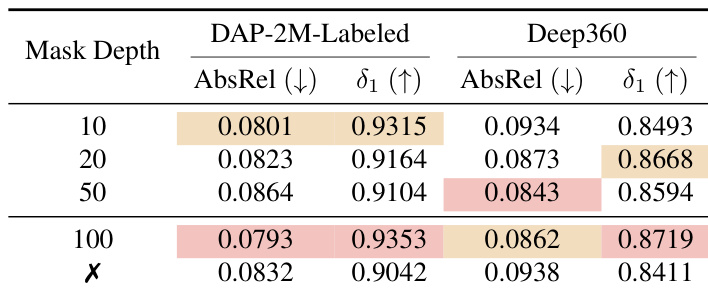
- Ablation studies confirm key components: adding sharpness-centric losses (ℒ_DF, ℒ_grad) yields best results (AbsRel 0.1084/0.0862 on Stanford2D3D/Deep360), and the range mask head at 100 m threshold optimizes performance (AbsRel 0.0793, δ₁ 0.9353 on DAP-2M-Labeled).
- DAP demonstrates robust metric consistency across indoor and outdoor scenes, maintaining accurate depth structures in challenging regions like distant skies and complex layouts where prior methods fail.
The authors evaluate the impact of different depth mask thresholds on model performance, finding that a 100 m threshold yields the best overall balance with the lowest AbsRel and highest δ1 on both DAP-2M-Labeled and Deep360. Removing the mask head degrades performance, confirming its role in stabilizing training and filtering unreliable far-depth predictions. Results show that smaller thresholds (10 m, 20 m) favor near-range accuracy, while the 100 m setting best preserves metric consistency across diverse scene scales.
The authors evaluate DAP against scale-invariant and metric depth estimation methods on three benchmarks, showing that DAP achieves the lowest AbsRel and RMSE while attaining the highest δ1 across all datasets. Results indicate DAP outperforms prior metric methods like Unik3D and DAC, particularly in outdoor scenes on Deep360, where it reduces AbsRel to 0.0659 and δ1 reaches 0.9525. These improvements reflect DAP’s ability to deliver metrically consistent depth without post-alignment, generalizing robustly across indoor and outdoor panoramic environments.
The authors evaluate DAP on the DAP-Test benchmark and show it outperforms DAC and Unik3D across all metrics, achieving a lower AbsRel of 0.0781, lower RMSE of 6.804, and higher δ₁ of 0.9370. These results demonstrate the effectiveness of their large-scale data scaling and unified training framework for metrically consistent panoramic depth estimation.

The authors use DAP to achieve metric depth estimation directly from panoramic inputs without post-alignment, outperforming prior methods across indoor and outdoor benchmarks. Results show DAP’s training on 2 million panorama samples enables strong generalization, with superior performance in AbsRel, RMSE, and δ1 metrics on Stanford2D3D, Matterport3D, and Deep360. The model’s design, including distortion handling and range-aware masking, supports robust, metrically consistent predictions across diverse real-world scenes.
The authors use ablation studies to evaluate the impact of distortion maps, geometry losses, and sharpness losses on panoramic depth estimation. Results show that combining all three components yields the best performance, achieving the lowest AbsRel and highest δ₁ on both Stanford2D3D and Deep360 datasets. The inclusion of sharpness losses contributes most significantly to improved metric accuracy and structural fidelity.
