Command Palette
Search for a command to run...
NVIDIA と他の企業は、18,000 年分の気候データを生成し、単一ステップの計算で長期的な天気予報を可能にする長距離蒸留を提案しました。

気象予報の精度と予測時間は、防災、農業生産、そして地球規模の資源配分に直接影響を及ぼします。短期的な警報から季節予測、さらには長期的な気候予測に至るまで、技術的課題は進歩するごとに指数関数的に増大しています。長年にわたる従来の数値気象予報の発展を経て、AIはこの分野に新たな勢いをもたらしました。近年、AI気象予報モデルは中期予報において飛躍的な進歩を遂げ、その性能は従来の高度な力学モデルに匹敵、あるいは凌駕しています。
現在主流のAI気象モデルのほとんどは自己回帰アーキテクチャを採用しており、短期的な大気変動に関する過去のデータから反復的に外挿・学習することで、今後数時間の気象を予測します。このタイプのモデルは中期予報において優れた性能を発揮します。しかし、サブシーズンからシーズン (S2S) などの長期的なスケールに拡大すると、根本的なボトルネックが発生しました。
長期予測は確率論的な手法に依存しているのに対し、自己回帰モデルは反復的な反復を通じてしか予測を行うことができないため、誤差が継続的に蓄積され、キャリブレーションが困難になります。根本的な矛盾は以下の点にあります。トレーニングの目的は短期的なパターンを学習することであり、長期予測には、気候変動の緩やかな速度を特徴付けることができる確率モデルの構築が必要です。
この限界を克服するため、研究者たちはシングルステップ予測の新たな方法を模索し始めました。しかし、新たな問題が発生しました。既存の再解析データに基づいて長期的なシングルステップモデルを学習する場合、データサンプルの不足により深刻な過剰適合が発生し、モデルの信頼性が保証されない可能性があるのです。
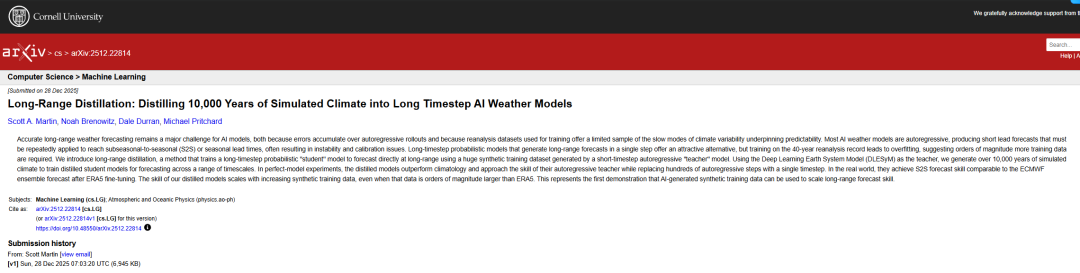
この文脈では、NVIDIA Research の研究チームはワシントン大学と共同で、長距離蒸留の新しい方法を開発しました。核となるアイデアは、現実的な大気変動を生成することに優れた自己回帰モデルを「教師」として用い、低コストかつ迅速なシミュレーションを通じて大量の合成気象データを生成することです。そして、このデータを用いて確率的な「生徒」モデルを学習させます。生徒モデルは、反復誤差の蓄積を回避し、データキャリブレーションという複雑な問題を回避しながら、1ステップの計算のみで長期予測を生成します。
このアプローチは、自己回帰モデリングの枠組みから脱却し、大規模な気候データを条件付き生成モデルに圧縮することで、先行研究における学習データの限界を克服するものです。本研究では、1世紀にわたる気候を安定的にシミュレートできる自己回帰結合モデルを教師として用い、実世界の記録規模をはるかに超える学習サンプルを生成しました。予備実験では、このモデルに基づいて学習された生徒モデルは、S2S予測においてECMWF統合予測システムと同等の性能を示し、合成データ量の増加に伴い性能が継続的に向上することが示されました。これは、将来的に、より信頼性が高く経済的な気候規模の予測を実現することが期待されます。
「長距離蒸留:1万年間のシミュレートされた気候を長期タイムステップ AI 気象モデルに蒸留する」と題された関連研究結果が arXiv で公開されました。
研究のハイライト:
* 実際の観測データの時間制限を突破し、AI気象モデルを使用して1万年以上の合成気候データを生成し、実際の観測では十分に表現されていなかったゆっくりと変化する気候モードをモデルが学習できるようにします。
* 従来の自己回帰フレームワークで数百回の反復によって発生する誤差の蓄積と不安定性の問題を克服し、1 ステップの計算だけで長期確率予測モデルを出力できる長距離蒸留法を提案します。
* 実際のデータに適応した後、このモデルの季節内予報から季節予報までの精度は、欧州中期予報センターの運用システムに匹敵するレベルに達しました。
用紙のアドレス:https://arxiv.org/abs/2512.22814 弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「長距離蒸留」と返信すると、完全な PDF を入手できます。
AIフロンティアに関するその他の論文: https://hyper.ai/papers
データセット:合成気候データの生成、分類、評価のためのフレームワーク
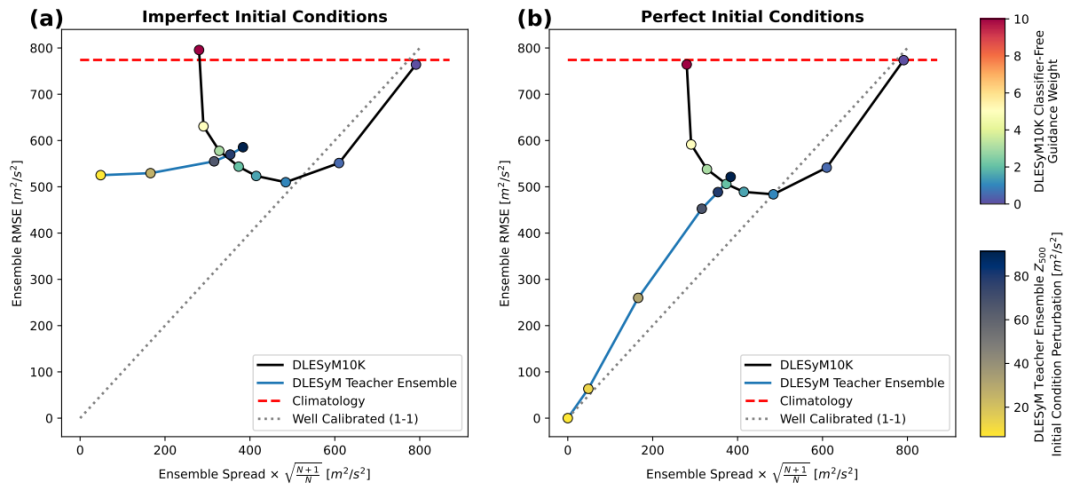
本研究では、長距離蒸留モデルのクロスタイム依存の統合予測能力を評価するために、まず制御された理想モデル実験でそれを検証しました。すべての評価データは、自己回帰教師モデル DLESyM (Deep Learning Earth System Model) によって保存されたシミュレーション データから取得されました。さらに、この設定は蒸留モデルの学習中には一切使用されていません。この設定の主な目的は、初期条件が完全に決定されていない状況において、ロングステップ蒸留モデルとDLESyM教師モデルが未知のシミュレートされた気象条件を予測する際の性能を検証し、評価の客観性を確保することでした。
この評価では、アンサンブル二乗平均平方根誤差(RMSE)などの決定論的指標を用いただけでなく、確率予測評価ツールである連続ランキング確率スコア(CRPS)を導入し、予測パフォーマンスをより包括的に測定しました。研究者は、予測可能性メカニズムが異なる3つの予測リードをテスト対象として選定しました。
* 中期的なタイムフレーム:
7 日間の日平均予測 (パラメーター N=28、M=4) では、2017 年 1 月 1 日から 2019 年 3 月 10 日 (シミュレーション年) までの予約データが使用され、2 日ごとに初期日付が選択され、400 を超えるサンプルが生成されました。
* S2Sタイムフレーム:
4週間の週平均予測(パラメータN=112、M=28)では、2017年1月1日から2021年5月16日(シミュレーション年)までのデータが使用され、4日ごとに開始日が設定され、サンプルサイズも400を超えました。
* 季節の有効期限:
12 週間の月平均予測 (パラメータ N=336、M=112) では、2017 年 1 月 1 日から 2025 年 9 月 28 日 (シミュレーション年) までのデータが使用され、初期日付は 8 日ごとに選択され、サンプル サイズは約 400 になりました。
独立性を確保するため、研究者らはDLESYMによって生成された約15,000年間の合成気候シミュレーションデータを、アンサンブルメンバーシップに基づいてトレーニングセット(751 TP3T、約11,000年)と検証セット(251 TP3T)に分割し、各予測リードタイムについて独立した蒸留モデルを学習させました。これらの合成データの生成には並列戦略が採用されました。200の初期日付は2008年1月1日から2016年12月31日までの間で均等に選択され、各日付は90年間のシミュレーションに対応していました。これにより、合計 18,000 年にわたる気候データが得られました。
本研究の最終目標は、学習済みモデルを実世界の長期予測に適用することです。DLESyMの長期運用によって生成される「モデル気候」は、実世界の気候とは異なることに留意することが重要です。したがって、モデルを実世界のアプリケーションに移植する際には、この「ドメイン転移」の問題を重要な焦点として取り組む必要があります。
長距離蒸留:「データ蒸留」と「確率論的較正」の二重の革新
長距離蒸留法の革新的なアイデアは...長期間安定して実行できるショートステップ自己回帰モデルを「教師」として使用し、1 ステップの計算だけで長期予測を出力できる「生徒」モデルをトレーニングします。これにより、従来の自己回帰フレームワークにおける何百もの反復によって発生するエラー蓄積の問題が根本的に回避されます。
具体的には、研究者らは教師モデルの長期ローリングシーケンスから、将来の時間枠における平均状態である長期予測目標を定義します。そして、生徒モデルは初期状態からこの長期目標までの条件付き確率分布を直接学習します。教師モデルの核となる価値は、元の再解析データの規模をはるかに超える膨大な量の合成データを効率的に生成できることにあります。これにより、長期予測におけるトレーニングサンプルの不足という問題を解決します。
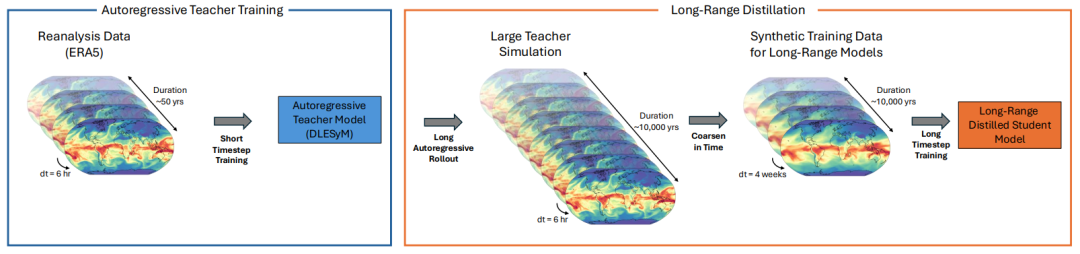
この目標を達成するために、この研究では、DLESyM モデルを「教師」として使用します。このモデルはERA5再解析データに基づいて初期化され、海面水温、気温、ジオポテンシャル高度といった主要変数を予測します。研究者らは効率的なデータ生成戦略を設計しました。2008年から2016年までの200の初期日付を均等に選択し、90年間にわたってシミュレーションを並行して実施することで、合計18,000年分の合成気候データが生成されました。強力なコンピューティング能力により、データ生成プロセスはわずか数時間で完了し、AI気候シミュレーションの効率性を十分に実証しました。品質スクリーニングの後、約15,000年分の有効なデータが、その後のモデルのトレーニングと検証に使用されました。
「Student」モデルは条件付き拡散モデル アーキテクチャを採用しており、確率予測用に特別に設計されています。目標は、将来の長期的な気象条件と入力条件(例えば、過去4日間の1日平均気象条件)との複雑な関係をモデル化することです。モデルアーキテクチャは、HEALPixグリッドに適合した改良型UNetネットワークに基づいています。このネットワークは、学習可能な空間埋め込みと周期的な時間埋め込みを導入することで、全球気象場の時空間依存性を効果的に捉えます。訓練中、研究者らは特定のノイズスケジューリング戦略を採用し、モデルがデータのあらゆるスケールで特徴を学習できるようにしました。
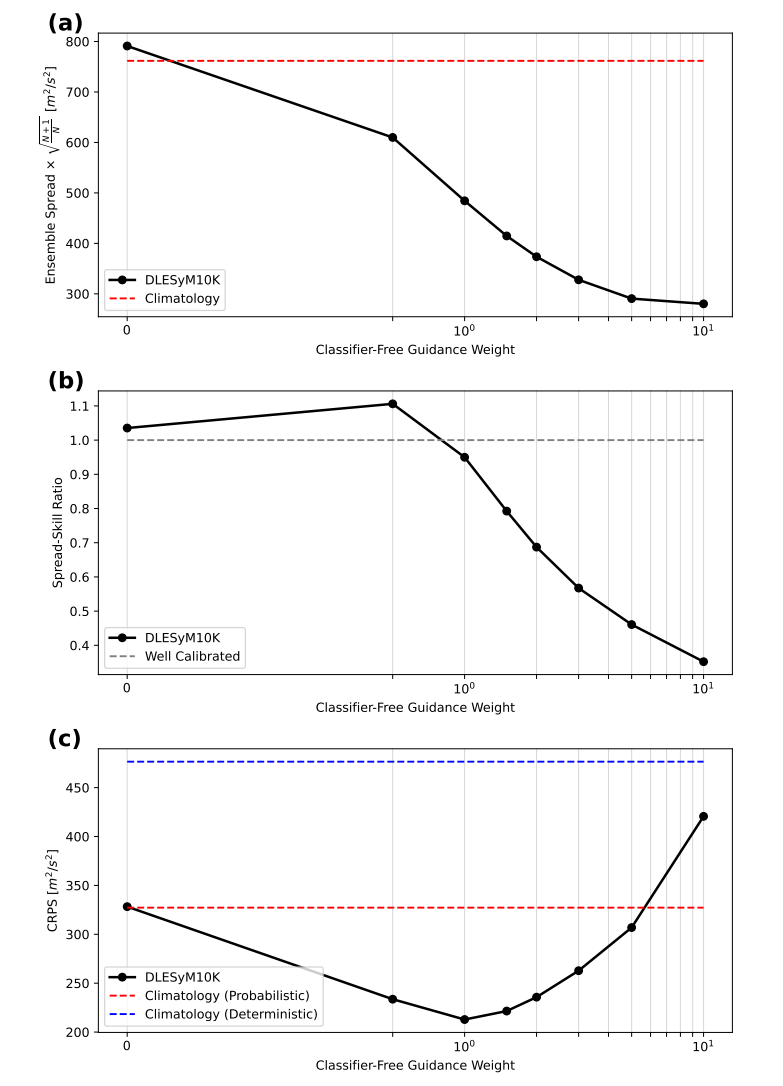
確率予測の不確実性を正確に調整するために、本研究では革新的な「分類器を使用しないガイダンス」を導入しています。モデル推論フェーズ中に単純な重みパラメータを調整することにより、予測アンサンブルの分散を柔軟に制御できます。これにより、予測誤差と正確な予測の間の最適なバランスが実現され、適切に調整された確率予測の生成が容易になります。
モデルを現実世界の予測タスクに活用できるよう、本研究では「ドメインシフト」問題に対処するための二重の戦略を実装しました。まず、気候バイアス補正を適用し、シミュレーションデータと平均状態における実観測値との間の系統的差異を修正しました。次に、ERA5再解析データを用いてモデルを微調整し、ネットワーク内の主要パラメータのみを更新しました。これにより、モデルは大量の合成データから学習したパターンを維持しながら、現実の大気の特性への適応性を高めることができました。最後に、欧州中期予報センター(ECMWF)などの主要な運用システムとの比較を通じて、現実世界のシナリオにおけるモデルの競争力を評価しました。
複数の側面でのブレークスルー:スケーラブルなデータ、調整可能な予測、トップレベルのビジネス システムに匹敵するスキル。
本研究では、一連の実験を通じて、トレーニングデータ規模の影響、予測不確実性の調整、複数時間予測スキル、運用システムとのベンチマークという 4 つの領域で、長距離蒸留モデルのパフォーマンスと可能性を体系的に検証しました。
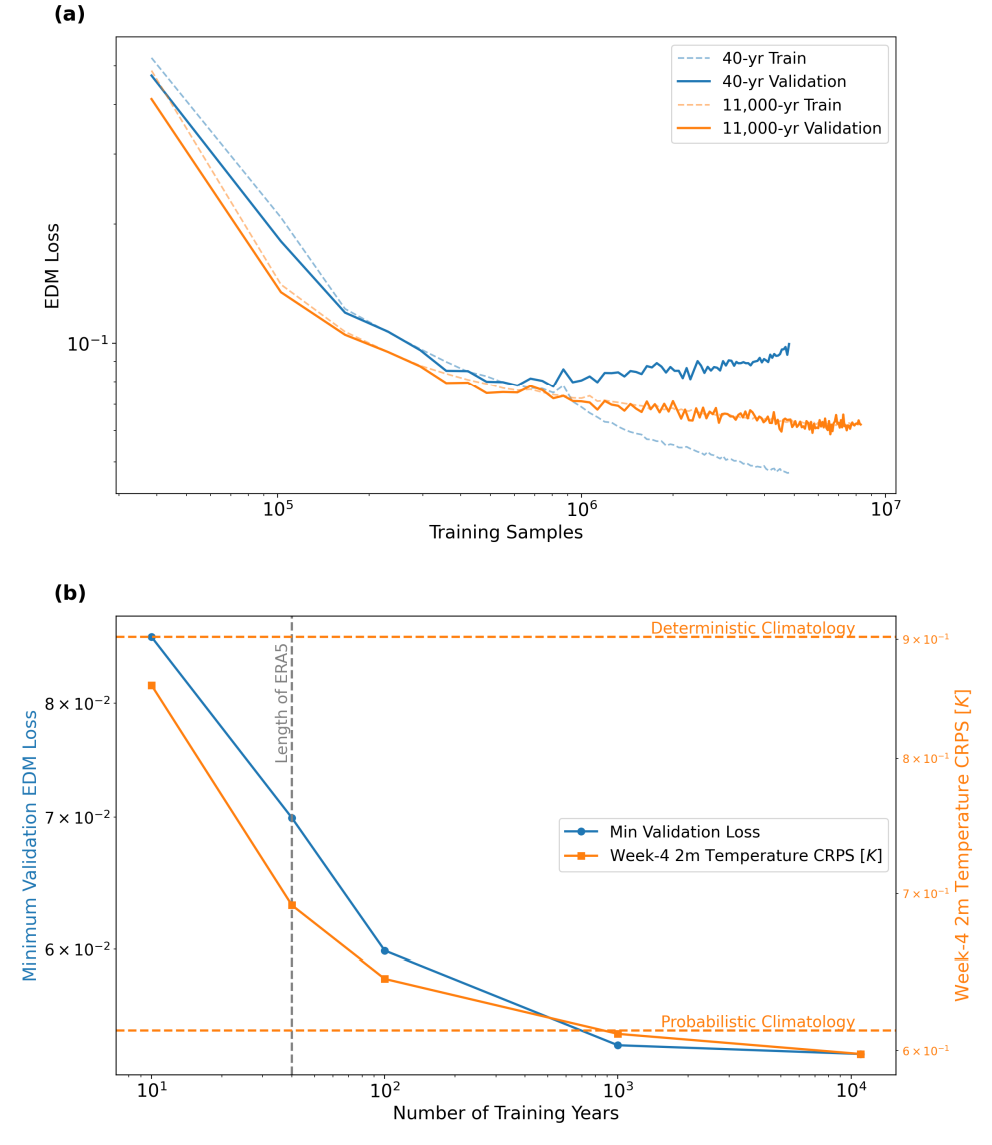
まず、本研究では、合成学習データの量を増やすことでモデルの予測能力を大幅に向上できるという中核仮説が検証されました。下図に示すように、わずか40年間のシミュレーションデータのみで学習したモデルはすぐに過学習しましたが、約11,000年間の合成データ(DLESyM10K)で学習したモデルは安定した学習曲線を示しました。さらに重要なのは、データ量の増加は、予測スキルの向上に直接つながります。4週間の気温予測において、CRPSスコアは14%減少しました。これは、自己回帰モデルを用いて大規模な合成データを生成することで、より堅牢な長期予測モデルを効果的に構築できることを初めて実証しています。
本研究では、「分類器を用いないガイダンス」手法を用いて確率予測の分散を較正する。ガイダンスの強度を調整することで、予測アンサンブルの分散を制御し、予測誤差との最適なバランスを実現できる。実験により…ガイダンス強度を 1 に設定すると、モデルは自動的に適切なキャリブレーションを実現できます。調整が必要な場合は、推論フェーズ中にパラメータを簡単に調整できます。これにより、確率予測のための効率的かつ柔軟なキャリブレーション手法が実現します。
このモデルは、中期、季節内から季節 (S2S)、季節の予測において堅牢なパフォーマンスを発揮します。中期予報において、このモデルは初期誤差に対して高い堅牢性を示し、その確率論的モデリング特性は初期条件の不確実性を軽減するのに役立ちます。より困難なS2S予報および季節予報において、DLESyM10Kは、特に熱帯や海洋などの予測可能性の高い地域において、気候学的ベンチマークを大幅に上回る性能を示します。特に、単一ステップの計算で、数百回の反復を伴う自己回帰教師モデルに匹敵するスキル レベルを実現します。これはフレームワークの効率性を示しています。
モデルを現実世界の予報に応用する際には、微調整とバイアス補正によって「モデル気候」と実際の気候の乖離が解消されました。欧州中期予報センター(ECMWF)の運用システムとの比較では、以下のことが示されています。微調整後、DLESyM10K の 4 週間気温予測スキルは ECMWF システムのそれに非常に近くなり、両方とも気候学的ベンチマークよりも大幅に優れています。地域分析の結果、各モデルはそれぞれ異なる地理的地域で強みを持っていることが明らかになりました。例えば、DLESyM10Kは南北アメリカ大陸と中央アフリカの一部地域で優れたパフォーマンスを発揮しています。これは、AIモデルが高度な業務システムと競合するポテンシャルを持ち、その差別化された価値を際立たせていることを示しています。
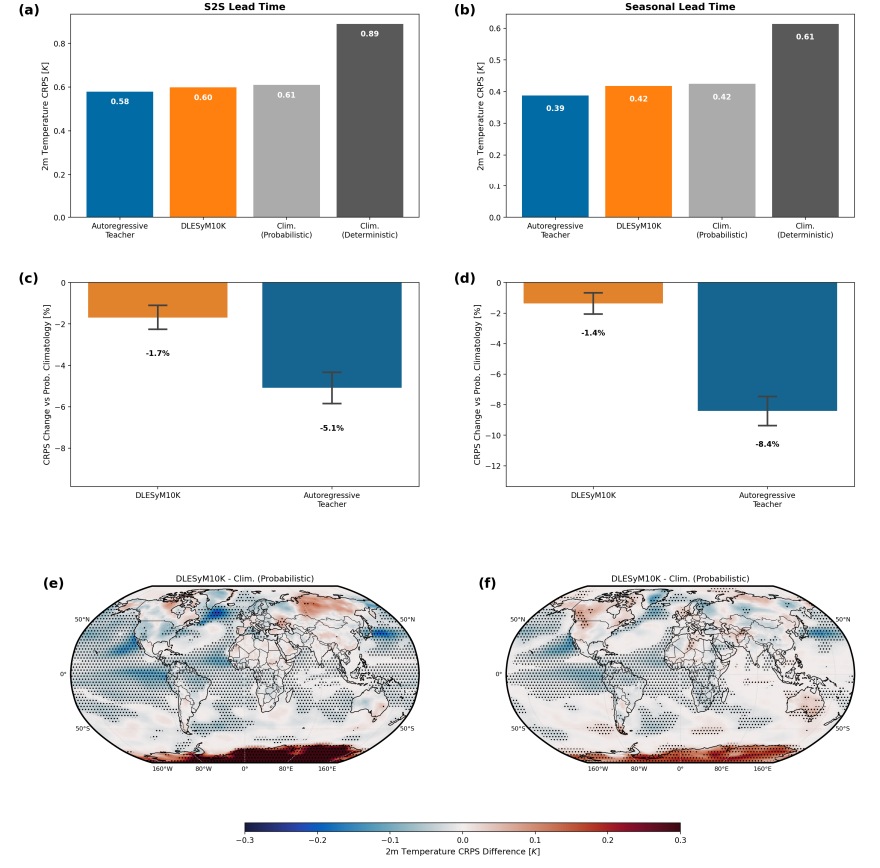
要約すると、長期蒸留法は、データスケーリングとシングルステップ確率モデリングを組み合わせることで、長期確率予測をシングルステップで出力できる条件付き拡散モデルを訓練し、分類器を使用しないガイダンス技術を組み込むことで柔軟な不確実性キャリブレーションを実現します。実験では…この方法は、季節内予報から季節予報まで、ヨーロッパ中期予報センター (ECMWF) の運用システムに匹敵するパフォーマンスを達成しました。このパラダイムは、長期的な天気予報への新しいアプローチを提供するだけでなく、気候科学の探究に役立つ一般的な生成モデルを構築するための基盤も築きます。
世界的な産学研究連携が気象技術の変革を加速
長期予報におけるデータのボトルネックを解消するために、AIを用いて合成データを生成することは、学術界と産業界が共同で気象予報のイノベーションを推進するための重要な方向性となりつつあります。一連の最先端の研究とエンジニアリングの実践が生まれ、長期気象予報を理論的な探求から実用化へと継続的に推進しています。
学術界では、学際的な連携が、核となる技術的課題を克服するための鍵となりつつあります。例えば、シカゴ大学の「AI気候イニシアチブ(AICE)」気候科学、コンピュータサイエンス、統計学の専門家を結集したこの組織は、気候予測の計算コストを大幅に削減することに尽力しています。彼らの技術は、一般的なノートパソコンを用いて高度な予測を行うことを可能にし、地域間の気象予測能力の格差を縮小することに貢献すると期待されています。
ケンブリッジ大学は、チューリング研究所、欧州中期予報センター、その他の機関と連携して、エンドツーエンドのデータ駆動型予報システムである Aardvark Weather を共同で開発しました。このシステムは、複数の観測データを統合し、全球グリッド予報と局地予報を同時に出力することができ、10日間の予報リードタイムにおいて、最適化された運用数値モデルに匹敵する性能を示します。エンドツーエンドのモデリングアプローチは、長距離蒸留による予報プロセスの簡素化という当初の目的に合致しており、長期予報の精度向上のための技術モデルを提供します。
* クリックして表示 アードバークの天気 詳細な分析:ネイチャー、ケンブリッジ大学などが、予測速度を数十倍向上させる初のエンドツーエンドのデータ駆動型天気予報システムをリリースした。
* 論文タイトル: エンドツーエンドのデータ駆動型気象予測
* 紙のアドレス:
https://www.nature.com/articles/s41586-025-08897-0
産業界における革新的な実践は、技術のエンジニアリング実装とシナリオベースの応用に重点を置いています。テクノロジー企業は、産学連携や独自の研究開発への深い関与を通じて、AI気象学の技術的限界を継続的に拡大しています。例えば、Microsoft、Google DeepMind、その他の組織が Aardvark Weather システムの開発に深く関わっていました。Google DeepMindの大規模データ処理とディープラーニングアーキテクチャにおける強みは、気象モデルの効率性と精度の向上につながります。さらに、Google DeepMindの生成モデルと確率的予測較正に関する専門知識は、長距離蒸留におけるアンサンブル分散制御などの問題の解決に重要な知見をもたらします。
同時に、企業はAI気象技術の具体的なシナリオへの応用を積極的に推進しています。例えば、公園管理や救急部門と連携し、高精度な長期予測技術をスマート防災システムに統合しています。災害の進展をフルプロセスでシミュレーションすることで、公園の安全、水利計画、農業生産といったシナリオに合わせてカスタマイズされた予測サービスを提供し、長期気象予報の価値がエンドユーザーに真に利益をもたらすようにしています。
学界と産業界によるこうした探究は、データ蒸留やシングルステップモデリングに代表される技術的アプローチの実現可能性を検証しただけでなく、「学術的なブレークスルーが方向を導き、エンジニアリングのイノベーションが実装を推進する」という好循環を徐々に形成し、より正確で効率的、かつ包括的な方向に向けた世界的なAI気象予報の継続的な発展を共同で促進してきました。
参考リンク:
1.https://climate.uchicago.edu/entities/aice-ai-for-climate/








