Command Palette
Search for a command to run...
具現化された知能に関するリソースの集大成:ロボット学習データセット、世界モデリングモデルのオンライン体験、NVIDIA、ByteDance、Xiaomi などの最新の研究論文。

過去 10 年間の人工知能の主な戦場が「世界を理解する」ことと「コンテンツを生成する」ことであったとすれば、次の段階の核心となる課題は、より困難な命題へと移行しています。AI はどのようにして物理世界に実際に参入し、その中で行動し、学習し、進化できるのでしょうか?「具現化された知能」という用語は、関連する研究や議論の中で頻繁に登場しています。
名前が示すように、具現化された知能は従来のロボットではありません。むしろ、知性は、知覚、意思決定、行動という閉ループの中で、エージェントと環境の相互作用を通じて形成されることを強調しています。この観点から見ると、知能はもはやモデルのパラメータや推論能力だけに存在するのではなく、センサー、アクチュエーター、環境フィードバック、そして長期的な学習に深く組み込まれています。ロボット工学、自動運転、エージェント、さらには汎用人工知能(AGI)に関する議論もすべてこの枠組みに組み込まれています。
だからこそ、ここ2年間、身体性知能は世界のテクノロジー大手や一流研究機関の注目を集めてきました。テスラのCEO、イーロン・マスク氏は、ヒューマノイドロボット「オプティマス」が自動運転に劣らず重要であると繰り返し強調してきました。NVIDIAの創業者ジェンスン・フアン氏は、フィジカルAIを生成AIに続く次世代の波と捉え、ロボットシミュレーションおよびトレーニングプラットフォームへの多額の投資を続けています。フェイフェイ・リー氏やヤン・ルカン氏らは、空間知能や世界モデルといった分野において、高品質な最先端の分析と成果を生み出し続けています。OpenAI、Google DeepMind、Metaも、マルチモーダルモデルや強化学習といった技術に基づき、現実環境または現実に近い環境でのインテリジェントエージェントの学習能力を研究しています。
このような背景から、身体性知能はもはや単一のモデルやアルゴリズムの問題ではなく、データセット、シミュレーション環境、ベンチマークタスク、そして体系的な手法からなる研究エコシステムへと徐々に進化してきました。より多くの読者がこの分野の核心を素早く理解できるよう、この記事では、具現化された知能に関連する一連の高品質なデータセット、オンライン チュートリアル、論文を体系的に整理して推奨し、さらなる学習と研究のための参考資料を提供します。
データセットの推奨
1. BC-Z ロボット学習データセット
推定サイズ:32.28 GB
ダウンロードアドレス:https://go.hyper.ai/vkRel

これは、Google、Everyday Robots、カリフォルニア大学バークレー校、スタンフォード大学が共同で開発した大規模なロボット学習データセットです。25,877件以上の運用タスクシナリオが含まれており、100種類もの多様な運用タスクを網羅しています。これらのタスクは、12台のロボットと7人のオペレーターによるエキスパートレベルの遠隔操作と共有自律プロセスを通じて収集され、合計125時間のロボット操作時間を記録しています。このデータセットは、タスクの口頭による説明や人間の操作ビデオに基づいて調整可能な7自由度マルチタスクポリシーの学習をサポートし、特定の運用タスクを実行します。
2.DexGraspVLA ロボット把持データセット
推定サイズ:7.29GB
ダウンロードアドレス:https://go.hyper.ai/G37zQ

Psi-Robotチームによって作成されたこのデータセットには、データとフォーマットを理解し、コードを実行してトレーニングプロセスを体験するための、51個の人間のデモンストレーションデータサンプルが含まれています。この研究は、雑然としたシーンにおける俊敏な把持において高い成功率を達成する必要性から生まれたもので、特に、見えない物体、照明、背景の組み合わせにおいて901 TP3Tを超える成功率を達成することが求められています。このフレームワークは、事前学習済みの視覚言語モデルを高レベルのタスクプランナーとして用い、拡散ベースのポリシーを低レベルのアクションコントローラーとして学習します。その革新性は、ベースモデルを活用して強力な一般化機能を実現し、拡散ベースの模倣学習を用いて俊敏な動作を習得することにあります。
3.EgoThink の一人称視点による視覚的な質問応答ベンチマーク データセット
推定サイズ:865.29 MB
ダウンロードアドレス:https://go.hyper.ai/5PsDP

清華大学が提案したこのデータセットは、一人称視点の視覚的質問応答ベンチマークデータセットであり、6つのコア機能を網羅し、12次元に細分化された700枚の画像が含まれています。画像はEgo4D一人称ビデオデータセットからサンプリングされており、データの多様性を確保するため、各ビデオから最大2枚の画像がサンプリングされています。データセット構築時には、一人称視点の思考を明確に示す高品質の画像のみが選定されました。EgoThinkは幅広い応用が可能であり、特に一人称視点タスクにおける視覚学習モデル(VLM)の性能評価と向上に役立ち、将来の具現化人工知能およびロボティクス研究のための貴重なリソースを提供します。
4.EQA の質問と回答のデータセット
推定サイズ:839.6 KB
ダウンロードアドレス:https://go.hyper.ai/8Uv1o
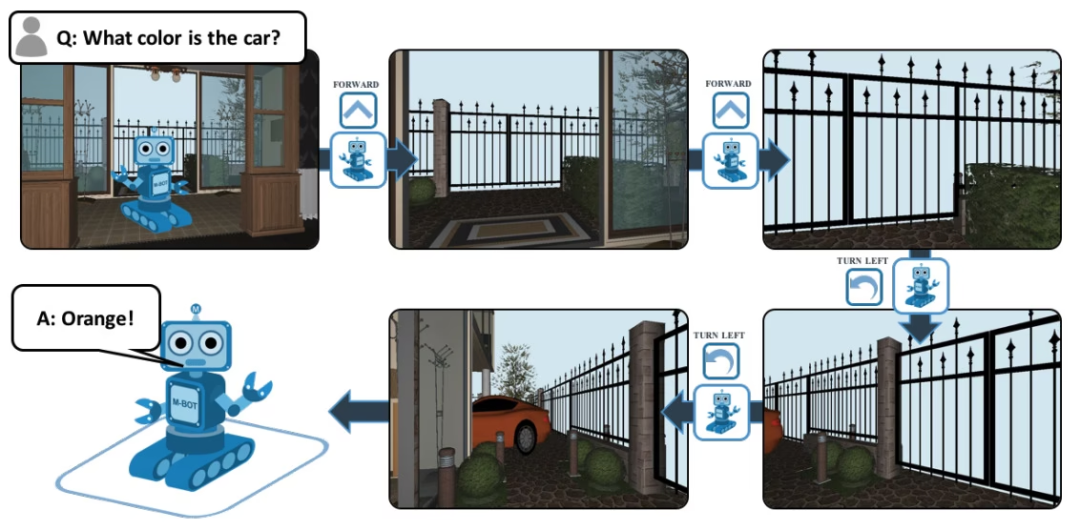
EQA (Embodied Question Answering の正式名) は、House3D に基づいた視覚的な質問と回答のデータ セットです。質問を受け取った後、エージェントは環境内のどこにいても、環境内の有用な情報を検索して質問に答えることができます。例: Q: 車の色は何色ですか?この質問に答えるには、エージェントはまずインテリジェント ナビゲーションを通じて環境を探索し、一人称視点で必要な視覚情報を収集してから、質問に「オレンジ」と答える必要があります。
5. OmniRetarget グローバルロボット
モーションリマッピングデータセット
推定サイズ:349.61MB
ダウンロードアドレス:https://go.hyper.ai/IloBI

これは、AmazonがMIT、カリフォルニア大学バークレー校、その他の機関と共同で公開した、ヒューマノイドロボットの全身動作リマッピングのための高品質な軌跡データセットです。G1ヒューマノイドロボットが物体や複雑な地形と相互作用する際の動作軌跡が含まれており、ロボットによる物体運搬、地形歩行、物体と地形のハイブリッド相互作用の3つのシナリオをカバーしています。ライセンス制限により、公開データセットにはLAFAN1のリマッピング版は含まれていません。このデータセットは3つのサブセットに分かれており、合計約4時間の動作軌跡データで構成されています。
* robot-object: OMOMO 3.0 データから得られた、ロボットが運ぶ物体の軌跡。
* robot-terrain: 内部の MoCap データ収集によって生成された、約 0.5 時間続く複雑な地形でのロボットの移動軌跡。
* robot-object-terrain: これは、地形と相互作用するオブジェクトの移動軌跡を伴い、約 0.5 時間続きます。
さらに、データセットにはモデル ディレクトリも含まれており、トレーニングではなく表示用に URDF、SDF、OBJ 形式の視覚モデル ファイルを提供します。
さらに高品質なデータセットを見る:https://hyper.ai/datasets
チュートリアルの推奨事項
身体化AIの研究では、物理世界における知覚、理解、計画、行動を実現するために、複数のモデルとモジュールを組み合わせることがよくあります。これには、世界モデルと推論モデルが含まれます。この記事では、主に以下の2つの最新のオープンソースモデルを推奨します。
さらに高品質なチュートリアルを見る:https://hyper.ai/notebooks
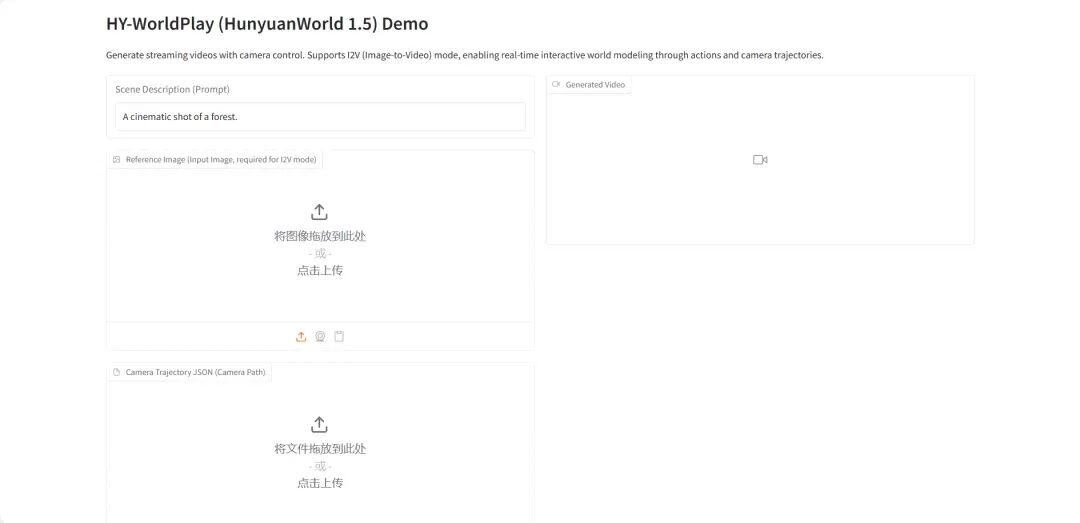
1.HY-World 1.5: インタラクティブな世界モデリングシステムのフレームワーク
HY-World 1.5(WorldPlay)は、テンセントのHunyuanチームがリリースした、長期的な幾何学的整合性を備えた初のオープンソースリアルタイムインタラクティブワールドモデルです。このモデルは、ストリーミングビデオ拡散技術を通じてリアルタイムインタラクティブワールドモデリングを実現し、従来の手法における速度とメモリのトレードオフを解決します。
オンラインで実行:https://go.hyper.ai/qsJVe
2.vLLM+Open WebUI デプロイメント ネモトロン3ナノ
Nemotron-3-Nano-30B-A3B-BF16は、NVIDIAがゼロから学習した大規模言語モデル(LLM)です。推論タスクと非推論タスクの両方に適用可能な統合モデルとして設計されており、主にAIエージェントシステム、チャットボット、RAG(検索拡張生成)システム、その他様々なAIアプリケーションの構築に使用されます。
オンラインで実行:https://go.hyper.ai/6SK6n
推奨用紙
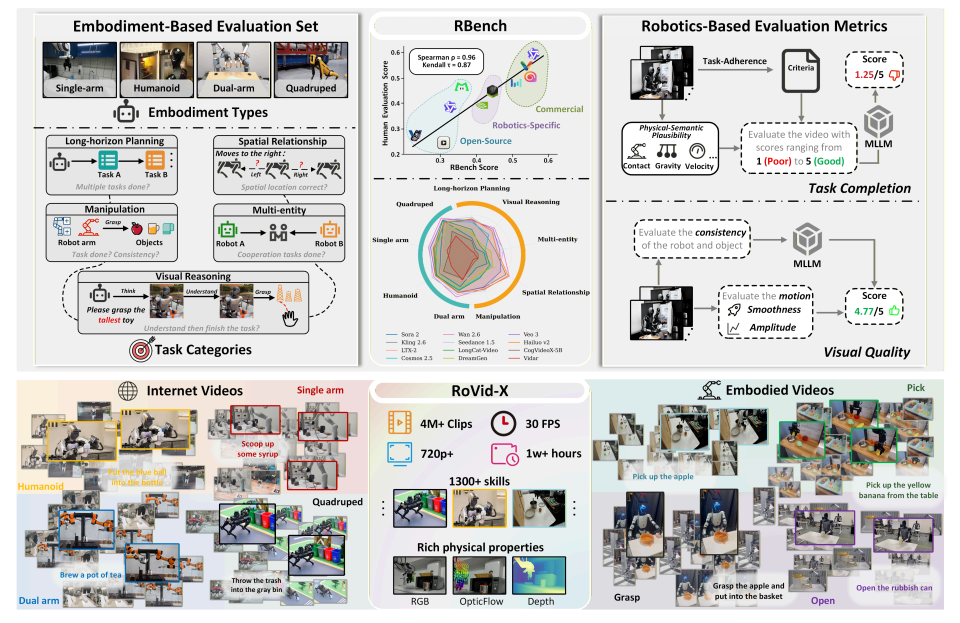
- Rベンチ
論文タイトル:身体化された世界のためのビデオ生成モデルの再考
研究チーム:北京大学、バイトダンスシード
論文を見る:https://go.hyper.ai/k1oMT
研究概要:
研究チームは、5つのタスクドメインと4つの異なるロボット形態を網羅する、ロボット動画生成のための包括的なベンチマークであるRBenchを提案しました。RBenchは、タスクレベルの正確性と視覚的な忠実度の2つの側面からロボット動画生成を評価し、構造の一貫性、物理的な妥当性、動作の完全性といった一連の再現可能なサブ指標を用いて評価します。25の代表的な動画生成モデルの評価結果から、現在の手法では物理的にリアルなロボット動作を生成する上で依然として重大な欠陥があることが示されました。さらに、RBenchと人間の評価との間のスピアマン相関係数は0.96に達し、モデル品質の測定におけるこのベンチマークの有効性を実証しました。
さらに、この研究では、包括的な物理的属性の注釈が補足された、数千のタスクを網羅した 400 万本の注釈付きビデオ クリップを含む、これまでで最大のオープンソース ロボット ビデオ生成データセットである RoVid-X も構築しました。
2. 存在-H0.5
論文のタイトル:Being-H0.5: 異体性汎化のための人間中心ロボット学習のスケーリング
研究チーム:ビーイングビヨンド
論文を見る:https://go.hyper.ai/pW24B
研究概要:
研究チームは、複数のロボットプラットフォームにまたがる強力な一般化と具現化能力を実現するために設計された、基礎的な視覚・言語・行動(VLA)モデルであるBeing-H0.5を提案しました。既存のVLAモデルは、ロボットの形態における大きな差異や利用可能なデータの不足といった問題によってしばしば制約を受けています。この課題に対処するため、研究チームは、人間のインタラクション軌跡を物理的インタラクション分野における普遍的な「母語」として扱う、人間中心の学習パラダイムを提案しました。
同時に、チームはUniHand-2.0もリリースしました。これは、30種類のロボット形態にわたる35,000時間を超えるマルチモーダルデータを網羅した、これまでで最大規模の身体性事前学習ソリューションの一つです。方法論レベルでは、異なるロボットの異種制御方法を意味的に整合したアクションスロットにマッピングする統合アクション空間を提案し、低リソースのロボットが人間のデータや高リソースプラットフォームから迅速にスキルを転送・学習できるようにしました。

3. ファストシンクアクト
論文のタイトル:Fast-ThinkAct: 言語化可能な潜在的計画による効率的な視覚・言語・行動推論
研究チーム:エヌビディア
論文を見る:https://go.hyper.ai/q1h7j
研究概要:
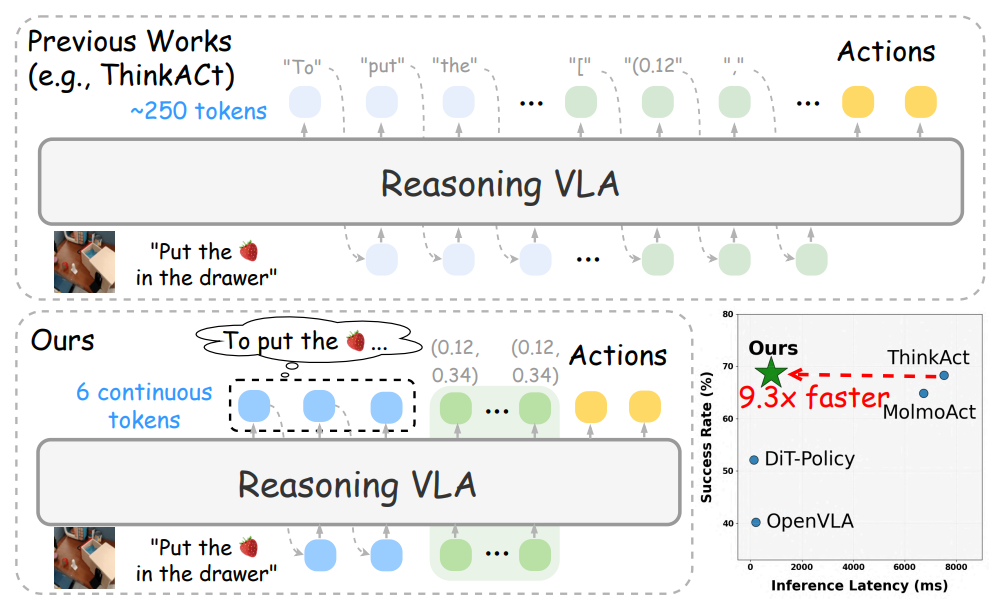
研究チームは、言語的潜在推論メカニズムを通じてパフォーマンスを維持しながら、よりコンパクトな計画プロセスを実現する効率的な推論フレームワーク「Fast-ThinkAct」を提案しました。Fast-ThinkActは、教師モデルから潜在的なCoTを抽出することで効率的な推論能力を学習し、嗜好に基づく目的関数の指示に従って操作軌跡を調整することで、言語的および視覚的な計画能力の両方を身体制御に応用します。
さまざまな具体化された操作と推論タスクを網羅した広範な実験結果により、Fast-ThinkAct は長期計画機能、少数サンプルの適応性、障害回復機能を維持しながら、現在の最先端の推論ベースの VLA モデルと比較して推論の待ち時間を最大 89.31 TP3T 短縮することで大幅なパフォーマンス向上を実現することが実証されています。
4. 裁判官RLVR
論文のタイトル:JudgeRLVR: 効率的な推論のためにまず判断し、次に生成する
研究チーム:北京大学、Xiaomi
論文を見る:https://go.hyper.ai/2yCxp
研究概要:
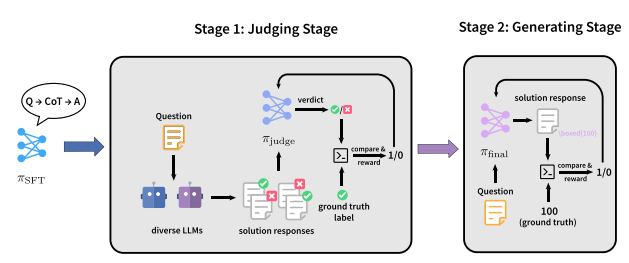
研究チームは、まず識別し、次に生成する2段階の学習パラダイム「JudgeRLVR」を提案した。第1段階では、検証可能な回答を用いて問題解決の応答を識別・評価するモデルを学習する。第2段階では、識別モデルを初期値として、標準的な生成RLVRを用いて同じモデルを微調整する。
同じ数学ドメインのトレーニング データで使用される Vanilla RLVR と比較して、JudgeRLVR は Qwen3-30B-A3B でより優れた品質と効率のトレードオフを実現します。ドメイン内の数学タスクでは、平均精度が約 3.7 パーセント ポイント向上し、平均生成長が 42% 短縮されます。ドメイン外のベンチマークでは、平均精度が約 4.5 パーセント ポイント向上し、より強力な一般化能力を示します。
5. ACoT-VLA
論文のタイトル:ACoT-VLA: 視覚・言語・行動モデルのための行動思考連鎖
研究チーム:北京航空航天大学、AgiBot
論文を見る:https://go.hyper.ai/2jMmY
研究概要:
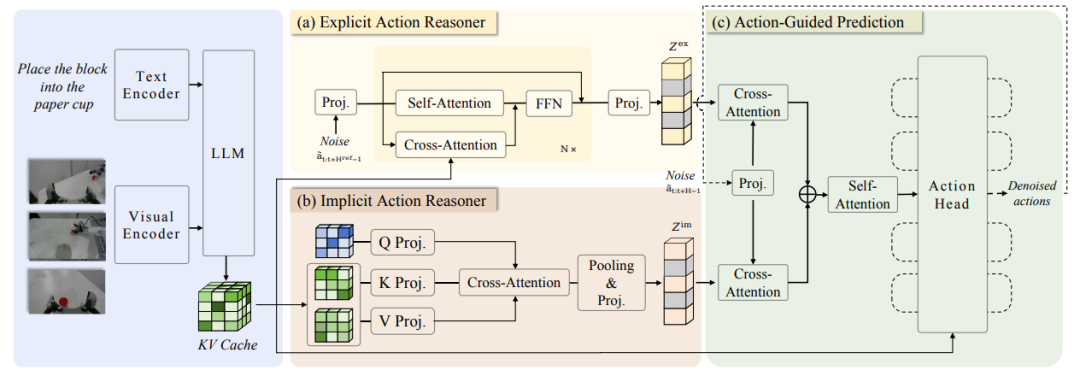
研究チームはまず、Action Chain-of-Thought(ACoT)を提案しました。これは、推論プロセス自体を、最終的なポリシー生成を導くための構造化された粗粒度の行動意図の連続としてモデル化したものです。さらに、ACoTパラダイムを具体化する新しいモデルアーキテクチャであるACoT-VLAを提案しました。
具体的な設計においては、明示的アクション推論器(EAR)と暗黙的アクション推論器(IAR)という2つの補完的なコアコンポーネントを導入しています。EARは、明示的なアクションレベルの推論ステップの形で粗粒度の参照軌跡を提示し、IARはマルチモーダル入力の内部表現から潜在的なアクション事前確率を抽出します。これらが組み合わさってACoTを構成し、下流のアクションヘッドへの条件付き入力として機能し、着地制約を伴う方策学習を実現します。
実際の環境とシミュレーション環境の両方で行われた広範な実験結果により、この方法の大きな利点が実証され、LIBERO、LIBEROPlus、VLABench ベンチマークでそれぞれ 98.51 TP3T、84.11 TP3T、47.41 TP3T のスコアが達成されました。
最新の論文を見る:https://hyper.ai/papers








