Command Palette
Search for a command to run...
3Dビジョンのブレークスルー:ByteSeedがDA3を発表。あらゆる視点からの視覚空間再構成が可能に。7万点以上の実世界の産業環境データを搭載!CHIPが産業データのギャップを埋め、6Dポーズ推定を実現。

視覚入力から三次元空間情報を知覚・理解する能力は、空間知能の基盤であり、ロボット工学や複合現実(ML)などのアプリケーションにとって重要な要件です。この基本的な能力は、単眼深度推定、動きからの構造推定、多眼ステレオビジョン、同時自己位置推定とマッピングなど、様々な三次元視覚タスクを生み出してきました。
これらのタスクは、入力ビューの数など、わずかな要素の違いしかない場合が多く、概念的な重複が非常に多く見られます。しかしながら、現在の主流のパラダイムは、依然として各タスクに特化したモデルを開発することです。複数のタスクに対応できる統一された3D理解モデルの構築は、重要な研究方向となっています。ただし、既存のソリューションは通常、複雑なカスタム設計されたネットワーク アーキテクチャに依存しており、マルチタスク共同最適化を通じてゼロからトレーニングする必要があります。そのため、大規模な事前学習済みモデルの知識や利点を十分に吸収し、活用することは困難です。
これに基づいて、ByteDance のシードチームは、Depth Anything 3 (DA3) をリリースしました。特別なレイ表現に基づいて特別に学習された単一のTransformerモデルは、あらゆる視点からの深度と姿勢を統合的に推定できます。モデルの極限的な簡素化を追求する中で、DA3は2つの重要な発見をもたらしました。
*単一の標準トランスフォーマー (バニラ DINO エンコーダーなど) をバックボーン ネットワークとして使用できます。タスク固有の構造のカスタマイズは必要ありません。
*単一の深度光線のみを使用してターゲットを予測します。複雑なマルチタスク学習メカニズムを必要とせずに、優れたパフォーマンスを実現できます。
研究チームはまた、カメラの姿勢推定、任意の視点の幾何学、視覚レンダリングを網羅した新たな視覚幾何学ベンチマークを確立した。このテストでは、DA3 はすべてのミッションの状態を更新します。カメラ姿勢の精度はVGGTよりも平均35.7%高く、幾何学的精度は23.6%向上し、単眼深度推定は前モデルDA2よりも優れています。実験では、この最小限の手法は、カメラ姿勢が既知であるかどうかにかかわらず、任意の枚数の画像から視空間を再構築するのに十分であることが示されています。
HyperAI の Web サイトには現在、「Depth-Anything-3: あらゆる視点からの視覚空間の回復」が掲載されていますので、ぜひお試しください。
オンラインでの使用:https://go.hyper.ai/MXyML
12月15日から12月19日までのhyper.ai公式サイトの更新内容の概要は次のとおりです。
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 3
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
1月締め切りのトップカンファレンス:11
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. VideoRewardBenchビデオ報酬モデル評価データセット
中国科学技術大学とHuawei Noah's Ark Labが共同でリリースしたVideoRewardBenchは、ビデオ理解の4つのコア要素(知覚、知識、推論、セキュリティ)を網羅した初の包括的な評価ベンチマークです。複雑なビデオ理解シナリオにおいて、モデルの選好判断能力と生成結果の品質評価能力を体系的に評価することを目的としています。データセットには、1,482本の異なるビデオと1,559の異なる質問を含む1,563のラベル付きサンプルが含まれています。各サンプルは、ビデオテキストプロンプト、好ましい応答、拒否応答で構成されています。
直接使用します:https://go.hyper.ai/JIB1B
2. アリーナライトライティング生成評価データセット
Arena-Writeは、シンガポール工科デザイン大学が清華大学知識工学研究所と共同で公開したライティングタスクデータセットです。長文生成モデルを評価し、現実的な使用シナリオ下における大規模言語モデルの長文コンテンツや複雑なライティングタスク生成能力を体系的に評価するために設計されています。データセットには100個のユーザーライティングタスクが含まれており、各タスクは現実世界のライティングプロンプトで構成され、対応するライティングシナリオタイプがラベル付けされています。
直接使用します:https://go.hyper.ai/4NQdD
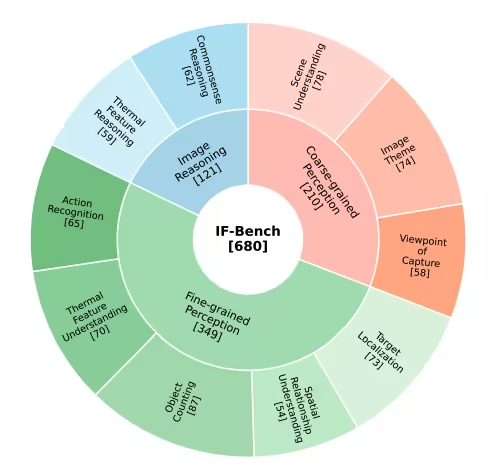
3. IF-Bench 赤外線画像理解ベンチマークデータセット
IF-Benchは、中国科学院自動化研究所と中国科学院大学人工知能学院が共同でリリースした、赤外線画像のマルチモーダル理解のための高品質ベンチマークです。赤外線画像に対するマルチモーダル大規模言語モデル(MLLM)の意味理解能力を体系的に評価することを目的としています。データセットには、499枚の赤外線画像と680組の視覚的質問応答(VQA)ペアが含まれています。画像は23の異なる赤外線画像データセットから取得されており、全体的に比較的バランスの取れた分布を維持しています。
直接使用します:https://go.hyper.ai/hty3u
4. CHIP 産業用椅子 6D 姿勢推定データセット
CHIPは、FBK-TeVがIkerlan氏およびAndreu World氏と共同で公開した、実世界の産業シナリオにおけるロボット操作のための6D姿勢推定データセットです。既存のベンチマークは主に家庭用品や実験室のセットアップを対象としており、実世界の産業環境に関するデータが不足しています。このデータセットには77,811枚のRGB-D画像が含まれており、7種類の異なる構造と素材の椅子モデルをカバーしています。
直接使用します:https://go.hyper.ai/AR5Xm
5. SSRB半構造化データ自然言語クエリデータセット
SSRBは、ハルビン工業大学(深圳)、香港理工大学、清華大学などの機関が共同で公開した、半構造化データに対する自然言語クエリのための大規模ベンチマークデータセットです。複雑な自然言語クエリ条件下での半構造化データ検索モデルの能力を評価・促進することを目的として、NeurIPS 2025データセットおよびベンチマークに選定されています。
直接使用します:https://go.hyper.ai/szsqF
6. INFINITY-CHAT 実世界自由回答質問応答データセット
ワシントン大学がカーネギーメロン大学およびアレン人工知能研究所と共同で公開した、実世界の自由回答形式のユーザー質問を対象とした初の大規模データセット「INFINITY-CHAT」が、NeurIPS 2025 Best Paper (DBトラック) を受賞しました。このデータセットは、自由回答形式生成における言語モデルの多様性、人間の嗜好の違い、「人工群集効果」といった重要な問題を体系的に研究することを目的としています。
直接使用します:https://go.hyper.ai/KmH1N
7. MUVRマルチモーダル非クロップ動画検索ベンチマーク
MUVRは、南京航空航天大学、南京大学、香港理工大学が共同で公開した、マルチモーダル未編集動画検索タスクのベンチマークデータセットです。NeurIPS 2025データセットおよびベンチマークに選定されており、長編動画プラットフォームにおける動画検索研究の促進を目指しています。このデータセットには、ビリビリ動画の未編集動画約53,000本、マルチモーダルクエリ1,050件、クエリと動画のマッチング関係84,000件が含まれており、ニュース、旅行、ダンスなど、様々な一般的な動画タイプをカバーしています。
直接使用します:https://go.hyper.ai/NRaSw

8. OpenGUグラフ忘却包括的評価データセット
OpenGUは、北京理工大学が公開したグラフ反学習(GU)の包括的な評価データセットです。NeurIPS 2025のデータセットとベンチマークに選定されており、グラフニューラルネットワークにおける忘却手法のための統一的な評価フレームワーク、マルチドメインデータリソース、標準化された実験設定を提供することを目的としています。
直接使用します:https://go.hyper.ai/qqHct
9. FrontierScience推論研究タスク評価データセット
OpenAIが公開したFrontierScienceは、推論および科学研究タスクを評価するためのデータセットです。専門家レベルの科学的推論および研究サブタスクにおける大規模モデルの能力を体系的に評価することを目的としています。このデータセットは、「専門家独自のコンテンツ+二層タスク構造+自動採点メカニズム」という設計メカニズムを採用しており、「Olympiad」と「Research」の2つのサブセットに分かれています。
直接使用します:https://go.hyper.ai/fUUzF
10. FirstAidQA 応急処置知識質問回答データセット
FirstAidQAは、イスラム科学技術大学が公開した、応急処置および緊急対応シナリオ向けのドメイン特化型質問応答データセットです。リソースが限られた緊急環境におけるモデルのトレーニングと応用を支援することを目的としています。このデータセットには、5,500件の高品質な質問と回答のペアが含まれており、様々な典型的な応急処置および緊急対応シナリオを網羅しています。
直接使用します:https://go.hyper.ai/QQphC
選択された公開チュートリアル
1. 奥行き-何でも-3: あらゆる視点から視覚空間を復元する
Depth-Anything-3(DA3)は、ByteDance-Seedチームがリリースした画期的なビジュアルジオメトリモデルです。「ミニマリストモデリング」というコンセプトでビジュアルジオメトリタスクに革命をもたらします。バックボーンネットワークとして、一般的なTransformer(例えば、バニラDINOエンコーダー)を1つだけ使用し、複雑なマルチタスク学習を「深度光線表現」に置き換えることで、あらゆる視覚入力(既知および未知のカメラポーズの両方)から空間的に一貫性のある幾何学構造を予測します。
オンラインで実行:https://go.hyper.ai/MXyML
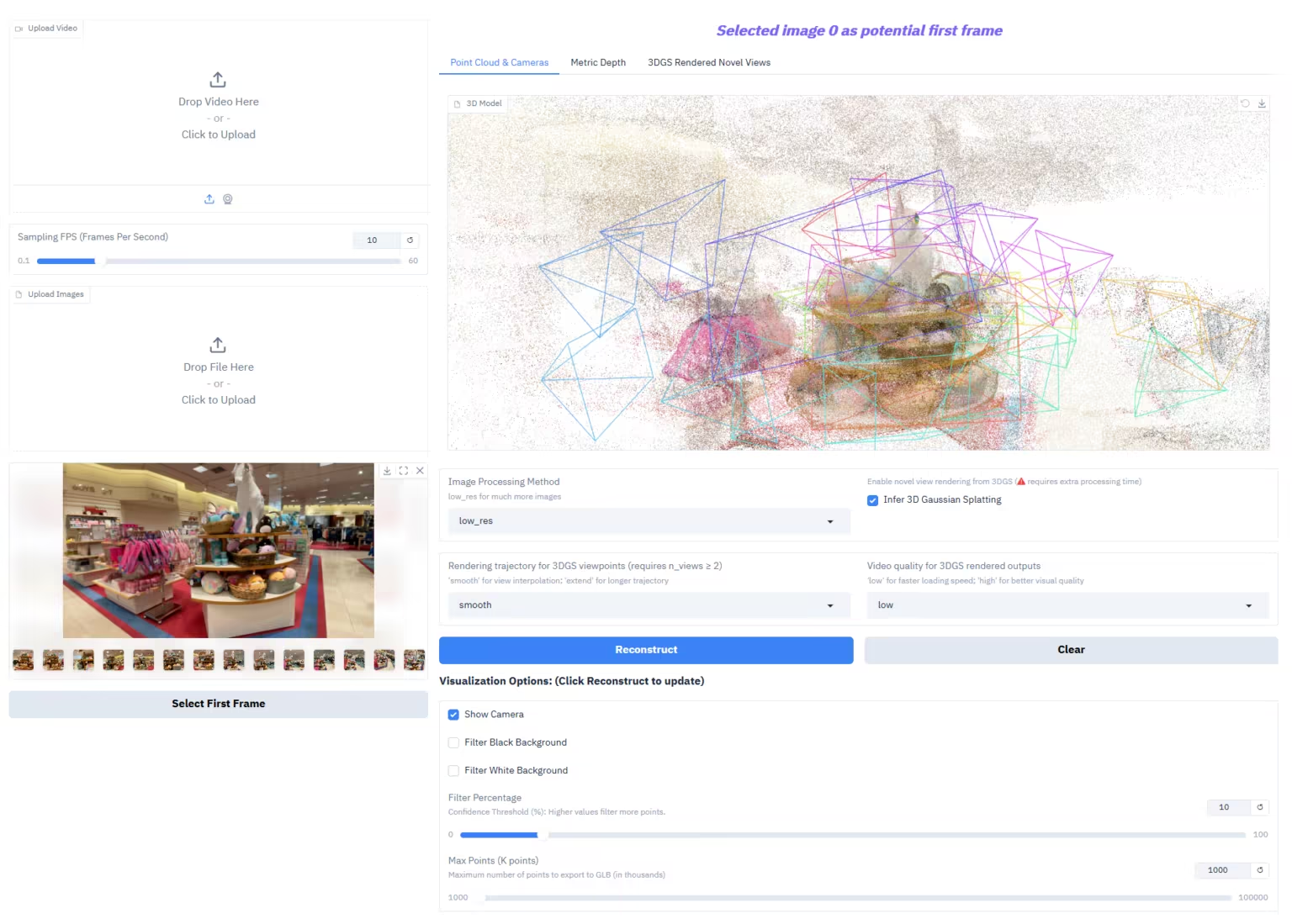
2. Microsoftのオープンソースドキュメント変換ツール「MarkItDown」
MarkItDownは、Microsoftが開発した軽量でプラグアンドプレイのPythonドキュメント変換ツールです。様々な一般的なドキュメントやリッチメディア形式を効率的かつ構造的にMarkdown形式に変換し、大規模言語モデル(LLM)におけるテキスト理解・分析パイプラインに最適化された入力形式を提供します。
オンラインで実行:https://go.hyper.ai/7WIGP
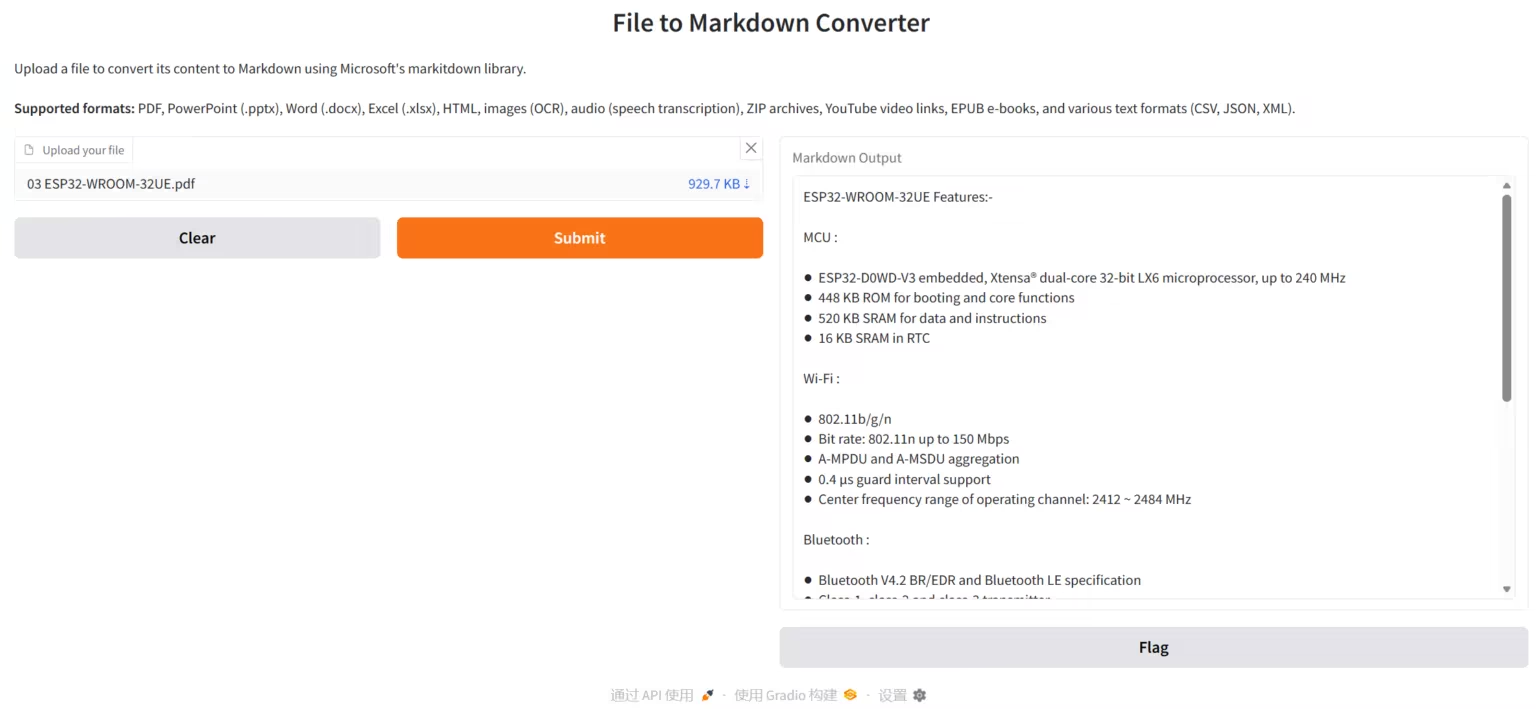
3. Chandra: 高精度ドキュメントOCR
Chandraは、Datalab-toチームによって開発された高精度ドキュメントOCR(光学式文字認識)システムで、ドキュメントレイアウト認識とテキスト抽出に重点を置いています。ChandraはPDFファイルや画像ファイルを直接処理し、構造化テキスト、Markdown、HTML出力を生成するだけでなく、OCR結果を容易に確認できる視覚的なレイアウト図も提供します。
オンラインで実行:https://go.hyper.ai/nZhF5
今週のおすすめ紙
1. LongVie 2: マルチモーダル制御可能な超長尺ビデオ世界モデル
この論文では、長距離制御性、時間的一貫性、視覚的忠実度において最先端のパフォーマンスを実現し、最大 5 分間の連続ビデオの生成をサポートするエンドツーエンドの自己回帰フレームワークである LongVie 2 を提案します。これは、統一されたビデオの世界をモデル化するための重要な一歩となります。
論文リンク:https://go.hyper.ai/toK8K
2. MMGR: マルチモーダル生成推論
本稿では、マルチモーダル生成推論評価およびベンチマークフレームワーク(MMGR)を提案します。これは、物理的推論、論理的推論、3D空間推論、2D空間推論、時間的推論という5つのコア推論能力に基づく体系的な評価システムです。MMGRは、抽象的推論(ARC-AGI、数独)、具体化ナビゲーション(現実世界の3Dナビゲーションとポジショニング)、そして物理的常識理解(スポーツシナリオや複雑なインタラクティブ動作)という3つの主要分野において、生成モデルの推論能力を評価します。
論文リンク:https://go.hyper.ai/Gxwuz
3. QwenLong-L1.5: 長期文脈推論と記憶管理のための訓練後レシピ
本稿では、体系的な学習後イノベーションを通じて優れたロングコンテキスト推論能力を実現するモデル、QwenLong-L1.5を紹介します。Qwen3-30B-A3B-ThinkingアーキテクチャをベースとするQwenLong-L1.5は、ロングコンテキスト推論ベンチマークにおいてGPT-5およびGemini-2.5-Proに近いパフォーマンスを示し、ベースラインモデルと比較して平均9.90ポイントの向上を達成しました。超長時間タスク(100万~400万トークン)では、メモリエージェントフレームワークがベースラインエージェントと比較して9.48ポイントの大幅な向上を達成しました。
論文リンク:https://go.hyper.ai/DxYGd
4. AIエージェント時代の記憶
本論文は、エージェント記憶研究における最新の進展を体系的にレビューすることを目的としています。まず、エージェント記憶の範囲を明確にし、大規模言語モデル(LLM)記憶、検索拡張生成(RAG)、コンテキストエンジニアリングといった関連概念と明確に区別します。次に、エージェント記憶を「形態」「機能」「ダイナミクス」という3つの統一的な観点から分析します。
論文リンク:https://go.hyper.ai/zfHTr
5. ReFusion: 並列自己回帰デコードを備えた拡散型大規模言語モデル
本論文では、並列デコードをトークンレベルからより高次の「スロット」レベルに引き上げることで、優れた性能と効率を実現する新しいマスク拡散モデル、ReFusionを提案します。各スロットは固定長の連続サブシーケンスです。ReFusionは、従来のMDMと比較して平均34%の性能向上と平均18倍以上の推論速度向上を実現するだけでなく、平均2.33倍の高速化という優位性を維持しながら、強力な自己回帰モデルとの性能差を大幅に縮小します。
論文リンク:https://go.hyper.ai/YosaF
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. スイス連邦工科大学ローザンヌ校 (EPFL) は、トレーニングに 100,000 未満の構造化データ ポイントを使用して、専門的なモデルに匹敵する原子シミュレーション精度を実現する PET-MAD を提案しました。
スイス連邦工科大学ローザンヌ校 (EPFL) が提案した PET-MAD モデルは、従来のモデルよりもはるかに少ないトレーニング サンプルを使用しながら、広範囲の原子多様性を網羅するデータセットを備えた専用モデルに匹敵する精度を実現しており、原子シミュレーションの開発における効率性と汎用性の向上に向けた強力なデモンストレーションとなっています。
レポート全体を表示します。https://go.hyper.ai/cpeR5
2. オンラインチュートリアル | マイクロソフトがVibeVoiceをオープンソース化、4つの役割間で90分間の自然な対話を実現
マイクロソフトは、スケーラブルな長編・複数話者音声合成を可能にするVibeVoiceをオープンソース化しました。このモデルは、64KBのコンテキストウィンドウ内で最大4人の話者による最長90分の音声を合成でき、より豊かな音色、より自然なイントネーション、そしてリアルな会話の雰囲気を捉えます。また、多言語アプリケーションにおいて高い移植性を示し、その総合的なパフォーマンスは既存のオープンソースおよびプロプライエタリな対話モデルを凌駕しています。
レポート全体を表示します。https://go.hyper.ai/YfDjq
3. CUDA の初期チーム メンバーは、cuTile が Triton を「特にターゲットにしている」ことを厳しく批判しています。Tile パラダイムは、GPU プログラミング エコシステムの競争環境を再形成できるでしょうか?
CUDAのリリースから約20年が経った2025年12月、NVIDIAは新たなGPUプログラミングのエントリポイントとなる「cuTile」を発表しました。この新しいcuTileは、タイルベースのプログラミングモデルを用いてGPUカーネルをリファクタリングすることで、開発者がCUDA C++の深い知識を必要とせずに効率的にカーネルを記述できるようにし、コミュニティ内で活発な議論を巻き起こしました。まだ初期段階ではありますが、タイルベースのアプローチの抽象的な利点、コミュニティによる移行ツールの検討、そして実践的な試みは、cuTileがGPUプログラミングの新たなパラダイムとなる可能性を秘めていることを示唆しています。その将来は、エコシステムの成熟度、移行コスト、そしてパフォーマンスにかかっています。
レポート全体を表示します。https://go.hyper.ai/H1b0n
4. 積極的な監視を重視するダリオ・アモデイ氏は、OpenAI を去った後、AI の安全性を同社の使命に組み込みました。
世界的なAI競争が加速する中、「早期規制」を掲げる少数派の立場をとるダリオ・アモデイ氏は、シリコンバレーにおいて揺るぎない影響力を持つようになりました。憲法に基づくAIの推進から欧米の規制枠組みへの影響力行使まで、彼はAI時代におけるTCP/IPに類似した「ガバナンス・プロトコル」の確立を試みています。これはセキュリティの問題だけでなく、AIが今後10年間で急速な技術進歩から安定した応用へと移行できるかどうかという問題でもあります。アモデイ氏の戦略は、世界のAI業界の根底にある論理を再構築しつつあります。
レポート全体を表示します。https://go.hyper.ai/SwyNW
5. 清華大学のLi Yong氏が率いるチームは、60%によって予測精度を向上させ、高精度のネットワークダイナミクス式を自動的に導き出すことができるニューラルシンボリック回帰法を提案した。
清華大学電子工学部のYong Li教授と彼のチームは、データから数式を自動的に導出することでシステムのダイナミクスを特徴付けるニューラルシンボリック回帰法ND²を提案しました。この手法は、高次元ネットワーク上の探索問題を1次元システムに簡略化し、事前学習済みのニューラルネットワークを用いて高精度な数式発見を導きます。
レポート全体を表示します。https://go.hyper.ai/wVktJ
人気のある百科事典の項目を厳選
1. 核の規範
2. 双方向長短期記憶(Bi-LSTM)
3. グラウンドトゥルース
4. 具現化されたナビゲーション
5. 1秒あたりのフレーム数(FPS)
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
1月の締め切り会議

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1800以上の公開データセットの国内高速ダウンロードノードを提供
* 600以上の古典的で人気のあるオンラインチュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 600 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








