Command Palette
Search for a command to run...
Polymathic AI は、天体物理学、地球科学、レオロジー、音響学など 19 のシナリオをカバーし、13 億のモデルを構築して正確な連続媒体シミュレーションを実現します。
科学計算と工学シミュレーションの分野において、複雑な物理システムの進化をいかに効率的かつ正確に予測するかは、学術界と産業界の両方にとって常に重要な課題です。従来の数値解析手法は、理論的にはほとんどの物理方程式を解くことができますが、高次元、マルチフィジックスシナリオ、または非一様境界条件を扱う場合、計算コストが高く、大規模なマルチタスクへの適応性に欠けています。一方、自然言語処理とコンピュータービジョンにおけるディープラーニングの飛躍的進歩により、研究者は物理シミュレーションに「基本モデル」を適用する可能性を模索するようになりました。
しかし、物理システムは複数の時間的・空間的スケールにわたって進化することが多いのに対し、多くの学習モデルは短期的なダイナミクスのみに基づいて学習されます。長期予測に使用すると、複雑なシステムでは誤差が蓄積され、モデルの不安定性につながります。さらに、スケールの違いやシステムの異質性により、下流のタスクではモデリング解像度、次元数、物理場の種類に関する要件が異なり、固定入力形式を好む現代のトレーニングアーキテクチャにとって大きな課題となっています。そのため、これまでシミュレーションに使用されてきた基礎モデルのほとんどは、より現実的な3次元状況ではなく、2次元の問題のみを扱うなど、比較的均質なデータシナリオに限定されています。
このような背景から、Polymathic AI Collaboration の研究チームは、パッチ ジッタリング、2D-3D シナリオ向けの負荷分散型分散トレーニング戦略、適応型コンピューティング トークン化メカニズムなど、前述の課題に対処するための一連の新しい方法を導入しました。これを基に研究チームは、13億のパラメータを持ち、Transformerをコアアーキテクチャとして使用し、主に流体のような連続体ダイナミクスに重点を置いたWalrusと呼ばれる基本モデルを提案しました。 Walrusは、事前学習段階で、天体物理学、地球科学、レオロジー、プラズマ物理学、音響学、古典流体力学など、複数の分野を網羅する19の非常に多様な物理シナリオをカバーします。実験結果では、Walrusが下流タスクの短期予測と長期予測の両方において従来のベースラインモデルを上回り、事前学習データ分布全体にわたってより強力な汎化性能を示すことが実証されています。
「Walrus: 連続体ダイナミクスのクロスドメイン基盤モデル」と題された関連研究成果が、arXiv でプレプリントとして公開されています。
研究のハイライト:
Walrus は、13 億のモデルパラメータスケール、革新的な安定化技術、問題の複雑さに合わせて計算を適応させる機能を備えています。
* コスト適応、安定性、ネイティブ解像度での高度に異質なトレーニング データに対する効率的なトレーニングなど、連続体ダイナミクスの現在の基本モデルのいくつかの制限に対処します。
* Walrus は、現在までに最も正確な連続体シミュレーションの基礎モデルであり、複数の科学分野と複数の時間スケールにわたる 26 の独自の連続体シミュレーション タスクにわたって追跡された 65 のメトリックのうち 56 で最先端の結果を達成しました。

用紙のアドレス:https://arxiv.org/abs/2511.15684
完全な PDF を取得するには、当社の公式 WeChat アカウントをフォローし、バックグラウンドで「メディア シミュレーション」と返信してください。
AIフロンティアに関するその他の論文:
https://hyper.ai/papers
異種、多次元、高品質のデータセットの構築
Walrusの成功は、多様性と高品質データと切り離せないものです。研究チームは、WellとFlowBenchのハイブリッドデータセットを事前学習に使用しました。Wellデータセットは、実際の科学的問題から得られた大量の高解像度データを提供し、FlowBenchは標準的な流体シナリオに幾何学的に複雑な障害物を導入することで、モデルに複雑な流れのパターンを学習する機会を提供します。
研究チームは、さまざまな方程式、境界条件、物理的なパラメータ設定など、63 個の状態変数をカバーする合計 19 個のデータセットを使用しました。データ次元は2次元と3次元の両方を網羅しており、異なる空間次元にわたるモデルの汎化能力を確保しています。モデルの移植性を検証するため、研究チームはWell、FlowBench、PDEBench、PDEArena、PDEGymのデータを含む予約データセットの一部を用いて、事前学習後にモデルを微調整しました。データ分割は標準的な分割戦略に従い、学習/検証/テストでは軌跡に基づいて80/10/10の比率で分割しました。
学習設定に関しては、Walrusモデルは約40万回の事前学習ステップを実行し、2Dデータセットごとに約400万サンプル、3Dデータセットごとに約200万サンプルを使用しました。高次元マルチタスクデータでの効率的な学習を実現するために、AdamWオプティマイザーと学習率スケジューリング戦略が使用されました。主要な評価指標として、データセットとタスク間で統一的な評価を可能にするVRMSE(標準化二乗平均平方根誤差)を使用しました。
この非常に多様なトレーニング データと戦略により、Walrus は事前トレーニング段階で豊富な物理的特性をキャプチャし、下流のタスクのクロスドメイン一般化の基盤を築くことができます。
時空間分解に基づくトランスフォーマーアーキテクチャ
Walrusモデルは、空間時間分解変換アーキテクチャを採用しています。時空間テンソル構造データを処理する際には、空間次元と時間次元の両方に沿ってアテンション演算を実行し、効率的なモデリングを実現します。このプロセスは下図に示されています。
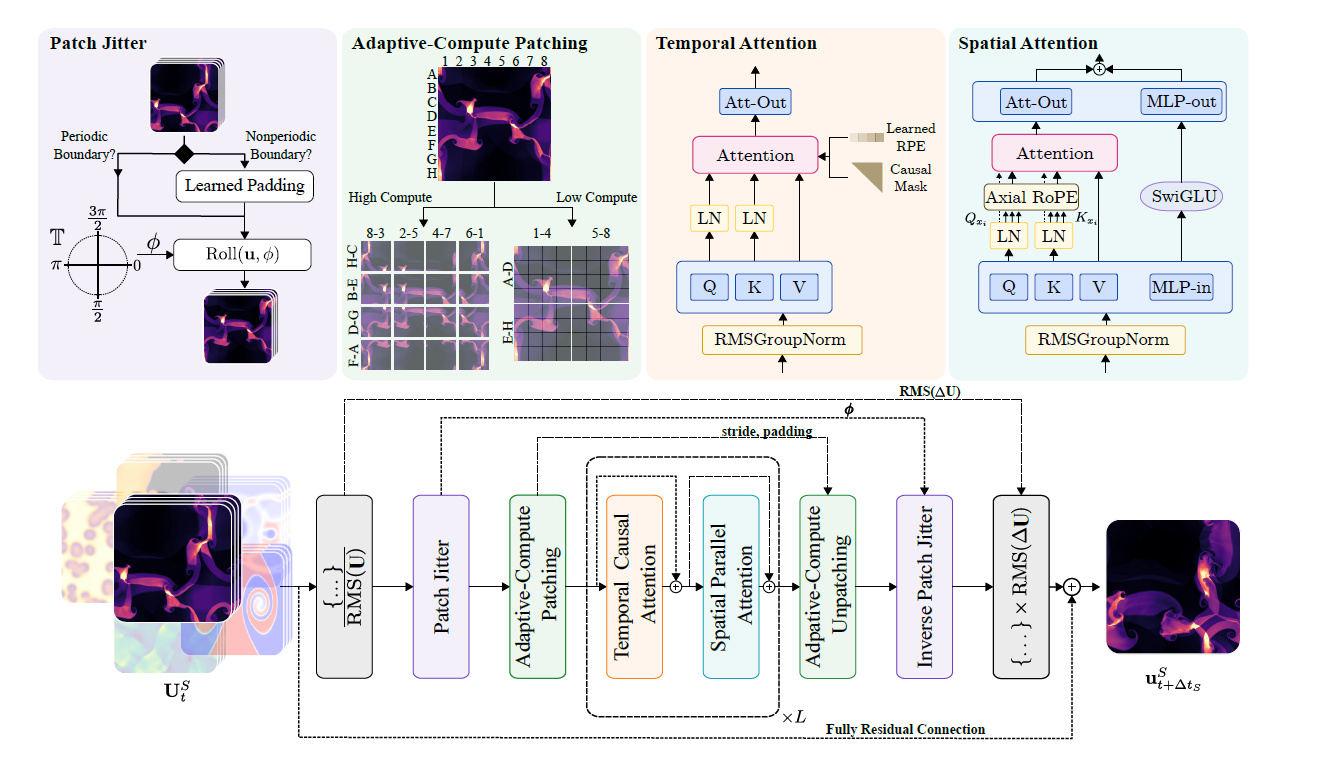
* 宇宙処理:位置エンコーディングには、Wang が提案した並列アテンションと Axial RoPE を組み合わせます。
* タイムライン処理:因果的注意とT5スタイルの相対位置符号化を組み合わせます。学習の安定性を向上させるため、空間モジュールと時間モジュールの両方にQK正規化を適用します。
* 計算適応型圧縮:エンコーダーモジュールとデコーダーモジュールでは、畳み込みストライド変調(CSM)を用いて、異なる解像度のデータをネイティブに処理します。各エンコーダー/デコーダーブロックのダウンサンプリング/アップサンプリングレベルを調整することで、柔軟な解像度処理を実現します。従来のシミュレーションモデルでは、固定圧縮エンコーダーが使用されることが多かったため、下流タスクのさまざまな解像度要件に対応できる柔軟性が不足していました。CSMを用いることで、研究者はダウンサンプリング時の畳み込みストライドを調整し、タスクに適した空間圧縮レベルを選択できます。
* 共有エンコーダー/デコーダー:同じ次元のすべての物理システムは、共通の特徴を学習するために単一のエンコーダとデコーダを共有します。2次元データと3次元データは、それぞれ2つのエンコーダと2つのデコーダに対応し、軽量階層型MLP(hMLP)を用いてエンコードおよびデコードされます。
* RMS GroupNormと非対称入力/出力正規化:RMSGroupNormは、各Transformerブロック内の正規化に使用され、学習の安定性を向上させます。非対称正規化は、入力と出力の増分予測に使用され、さまざまなシナリオにわたる数値安定性を確保します。
* パッチのジッタリング:入力データをランダムにシフトし、出力時に逆順に処理することで、高周波アーティファクトの蓄積が削減され、特に ViT スタイルのアーキテクチャにおいて長期的な予測の安定性が大幅に向上します。
* 高効率マルチタスクトレーニング:階層的サンプリングと正規化損失関数を採用することで、急速に変化する分野の予測が、ゆっくりと変化する分野に支配されないようにしています。同時に、マイクロバッチと適応型トークン化戦略を組み合わせることで、高次元の異種データの学習における負荷の不均一性の問題を解決しています。
* 2次元表現と3次元表現の統合:2次元データに1次元を追加してゼロ埋めし、3次元空間に埋め込み、対称性強化(回転、反射)を使用して多様化増幅することで、次元間トレーニング機能を実現します。
全体として、Walrus アーキテクチャは、空間次元と時間次元の両方でテンソル データを効率的に処理するだけでなく、多様な戦略と効率的な分散トレーニングを通じて、マルチタスクおよびマルチ物理シナリオの課題にも対処します。
Walrus は、複数の 2D および 3D ダウンストリーム タスクで大きな利点を発揮します。
ベースモデルとしての Walrus のパフォーマンスと下流タスクでのパフォーマンスを検証するために、研究者は一連の実験を設計しました。
① 下流タスクのパフォーマンス
MPP-AViT-L、Poseidon-L、DPOT-H などの既存のベースライン モデルと比較すると、Walrus は、次の図に示すように、シングル ステップ予測で平均 VRMSE を約 63.61 TP3T、短期軌道予測で 56.21 TP3T、中期軌道予測で 48.31 TP3T 削減します。
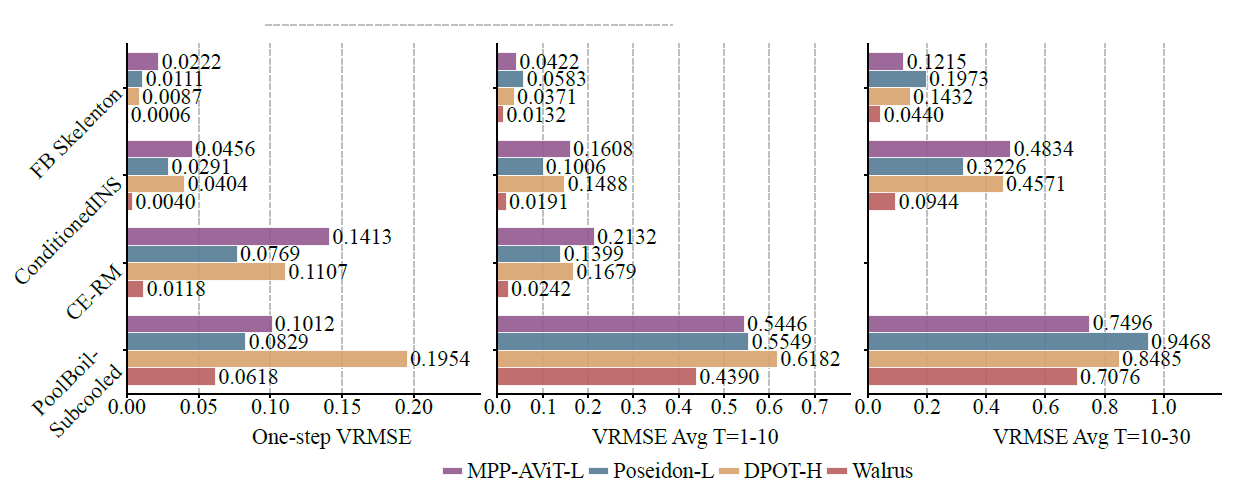
非カオスシステムでは、パッチジッタリングによってアーティファクト生成が少ないため、モデルの長期予測性能が安定します。より確率的なシステム (BubbleML の Pool-BoilSubcool など) では、Walrus が最初はリードしますが、短期的な履歴情報では材料やバーナーの特性を完全に反映できないため、長期的なローリング予測の利点は弱まります。
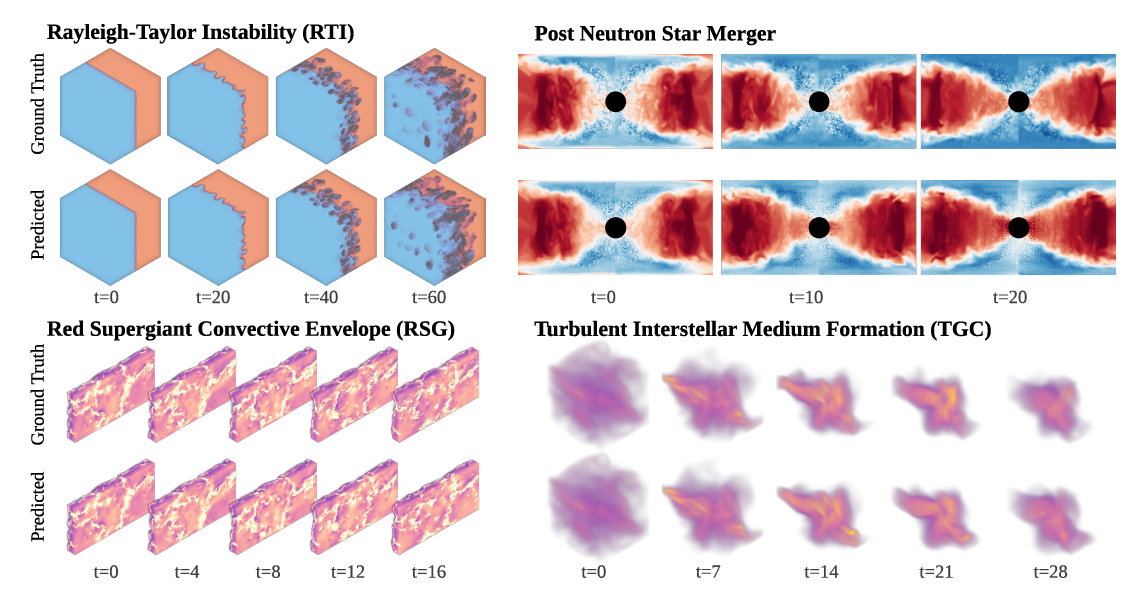
現実世界の物理シミュレーションのほとんどが3次元システムであるため、3次元タスクは特に重要です。Walrusは、PNS(ポスト中性子星合体)およびRSG(赤色超巨星対流圏)データセットの生成に数百万コア時間を要するにもかかわらず、これらのデータセットで非常に優れたパフォーマンスを発揮します(下図参照)。
② クロスドメイン機能
Walrus のクロスドメイン機能も検証され、最適なベースラインと比較して、Walrus はシングルステップ予測で平均損失を 52.21 TP3T 削減しました。19 個の事前トレーニング済みデータセットを微調整した後、Walrus は 19 個のタスクのうち 18 個で最も低い単一ステップ損失を達成し、20 ステップと 20 ~ 60 ステップでの中期ローリング予測でそれぞれ 30.5% と 6.3% の平均利点を達成しました (以下の表を参照)。
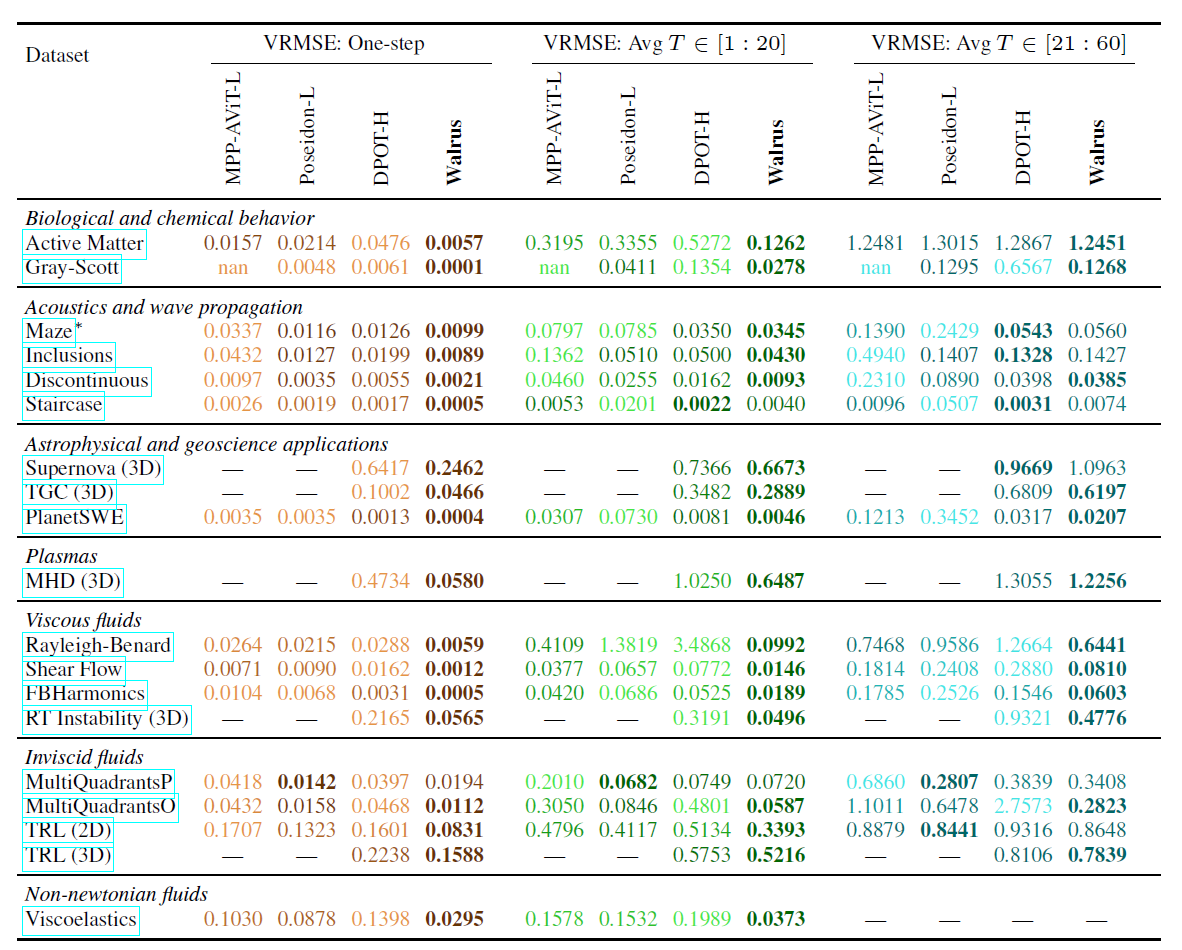
比較すると、DPOTは音響および線形波動伝播タスクにおいてWalrusに近い性能を示し、Poseidonは非粘性流タスクにおいて優れた性能を発揮します。しかし、Walrusは広範な事前学習と汎用的なアーキテクチャにより、ほとんどのタスクにおいてWalrusに匹敵する、あるいはそれ以上の性能を発揮します。
③事前トレーニング戦略の影響
アブレーション実験により、Walrusの多様な事前学習戦略が下流のパフォーマンスに極めて重要であることが示されました。2次元データのみを使用する半分のサイズのモデル(HalfWalrus)においてさえ、包括的な空間的および時間的拡張を備えた事前学習戦略は、全く未知の新しいタスクにおいて、ゼロから学習したモデルや単純な2次元事前学習戦略を用いたモデルよりも大幅に優れた性能を示しました。
3D CNSタスクにおいて、HalfWalrusは、3Dデータを見なくても、ごく少量のデータでわずかな改善を達成できます。Walrusモデル全体は、3Dデータによる事前学習を通じて大きな優位性を達成し、多次元かつ多様なデータの重要性を浮き彫りにしました。
Polymathic AI は、学際的な人工知能アプリケーションの実装を加速します。
科学計算と工学モデリングの分野において、基礎モデルの潜在力が新たなパラダイムシフトを引き起こしています。Polymathic AIは、科学データ向けの汎用的な基礎モデルを構築し、学際的な人工知能アプリケーションの実装を加速することを主な目標とする、注目すべきオープンソース研究プロジェクトです。
自然言語やビジョンタスク用の汎用大規模モデルとは異なり、Polymathic AI は、連続動的システム、物理場シミュレーション、エンジニアリング システム モデリングなどの一般的な科学計算の問題に重点を置いています。その中核となるアイデアは、大規模、マルチフィジックス、マルチスケールのデータを通じて統合モデルをトレーニングし、ドメイン間転送機能を実現して、科学的問題ごとにモデルをゼロから構築するコストを削減することです。この「ドメイン間一般化機能」は、科学的 AI における重要なブレークスルーと考えられています。
Polymathic AIは、純粋機械学習研究者と専門分野の科学者からなるチームを結成し、世界をリードする専門家からなる科学諮問グループの指導を受け、チューリング賞受賞者でMetaの主任科学者であるヤン・ルカン氏の助言を受けていると報じられています。また、ケンブリッジ大学AI+天文学/物理学助教授のマイルズ・クランマー氏をはじめとする著名な学術関係者からも支援を受けており、科学データの基礎モデルの開発に注力し、学際的な共通概念を用いてAI for Scienceにおける産業界の課題を解決することを目指しています。
2025年、Polymathic AI Collaborationのメンバーは、天文学や流体のようなシステムの問題に対処するために設計された、現実世界の科学的データセットでトレーニングされた2つの新しい人工知能モデルを発表しました。1つは前述のWalrusで、もう1つは天文学初の大規模マルチモーダル基礎モデルファミリーであるAION-1(Astronomical Omni-modal Network)です。AION-1は、画像、スペクトル、星カタログデータなどの異種の観測情報を、統合された初期融合バックボーンネットワークを通じて統合し、モデル化します。ゼロショットシナリオで非常に優れたパフォーマンスを発揮するだけでなく、タスク固有のモデルに匹敵する線形検出精度を誇り、幅広い科学的タスクにわたって優れたパフォーマンスを発揮します。単純な前方検出でも、そのパフォーマンスは最先端(SOTA)レベルに達し、データ量の少ないシナリオでは教師ありベースラインを大幅に上回ります。
論文のタイトル:AION-1: 天文学科学のためのオムニモーダル基礎モデル
用紙のアドレス:https://arxiv.org/abs/2510.17960
全体として、Polymathic AIは、「科学的AIの基本モデル」という新たな技術パラダイムの最先端の探求を表しています。その長期的な意義は、パフォーマンスの向上だけでなく、学際的な知識移転のための汎用コンピューティング基盤の構築にあり、「科学のためのAI」がツールレベルのアプリケーションからインフラレベルの機能へと移行するための基盤を築きます。
参考文献:
1.https://arxiv.org/abs/2511.15684
2.https://www.thepaper.cn/newsDetail_forward_32173693
3.https://polymathic-ai.org
4.https://arxiv.org/abs/2510.17960
5.https://www.163.com/dy/article/KGMRMMQM055676SU.html








