Command Palette
Search for a command to run...
欧州宇宙機関は、ハッブル宇宙望遠鏡からの1億のデータポイントを3日間で横断した後、AnomalyMatchを提案し、1000を超える異常な天体を発見しました。

現在、大規模、多波長、広視野、高深度の天体観測により、天文学はかつてないほどデータ集約的な時代へと突入しています。ユークリッド宇宙望遠鏡、ルービン天文台、ローマン宇宙望遠鏡といった次世代施設の稼働により、宇宙はかつてない規模と精度で体系的に地図化されています。これらの観測によって、数十億もの天体画像と分光データが生成されることが期待されており、これは天体観測の核となる科学的可能性の一つです…つまり、特別な天体物理学的価値を持つ希少な天体を体系的に発見し、特定することです。例としては、強い重力レンズ効果、銀河の合体、クラゲ銀河、エッジ方向の原始惑星系円盤などが挙げられます。
これらの稀少な天体は、しばしば「天体物理学的異常」と呼ばれ、銀河進化モデル、重力理論、そして宇宙論的パラメータの検証において重要な役割を果たします。しかしながら、その発見は長らく、研究者による偶然の視覚的特定や、市民科学プロジェクトによる手作業によるスクリーニングに大きく依存してきました。これらの方法は非常に主観的で非効率的であるだけでなく、これから出現する膨大な量のデータに適応することも困難です。
同時に、従来の教師あり機械学習手法では、希少な天体ラベル付きサンプルの数が極めて限られており、データ カテゴリの極端な不均衡により、根本的な課題に直面しています。このボトルネックに対処するため、研究は徐々に教師なしまたは弱教師ありの異常検出フレームワークへと移行してきました。これらの手法は、特定の対象カテゴリを事前に定義するのではなく、アルゴリズムを用いてデータ自体の全体的な構造や分布を学習し、「正常」グループから大きく逸脱した「外れ値」を自動的に特定します。例えば、孤立フォレストや局所異常因子といったアルゴリズムに基づくツール、あるいは自己教師学習によって表現空間を構築し、類似度検索を行う手法は、大規模なスカイサーベイデータから強い重力レンズ効果をスクリーニングするといったタスクにおいて有効性を実証しています。
しかし、純粋に教師なしの手法では、天体物理学の関心とは無関係な「ノイズ」異常が多数生成される可能性があります。この欠点を補うために、欧州宇宙機関(ESA)の一部門である欧州宇宙天文学センター(ESAC)の研究チームは、AnomalyMatchと呼ばれる新しい手法を提案し、適用した。希少天体検出タスクは、極めて不均衡な半教師あり二値分類問題として定義され、能動学習ループと深く統合されています。10個未満のごく少数のラベル付き異常サンプルから開始できます。同時に、擬似ラベルや一貫性正則化といった半教師あり学習技術を用いることで、膨大なラベルなしデータの価値を最大限探索し、活用します。さらに、プロセス全体を通して専門家による検証メカニズムが導入され、ラベルなしデータと専門家の知識を最大限に活用することで、検出性能が徐々に向上します。
「AnomalyMatch を使用してハッブル宇宙望遠鏡レガシー アーカイブからの 9,960 万のソース切り抜きにおける天体物理学的異常を特定する」と題された関連研究結果が Astronomy & Astrophysics に掲載されました。
研究のハイライト:
* AnomalyMatch は、ハッブル ヘリテージ アーカイブ全体 (約 1 億枚の画像スライス) にわたって異常な天体を初めて体系的にスクリーニングするために使用されました。
* このシステムは、新たに発見された天体物理学的異常のカタログを公開し、417 個の新しい銀河合体、138 個の重力レンズ候補、18 個のクラゲ銀河、および 2 個の衝突リング銀河など、珍しい現象のサンプル ライブラリを大幅に拡張しました。
* この手法は、極めて高い処理効率と精度が実証され、わずか2~3日で完全なデータ解析が完了し、ユークリッド望遠鏡やその他のソースからの将来の超大規模天体調査データの処理に革新的な可能性をもたらすことが実証されました。
用紙のアドレス:https://doi.org/10.1051/0004-6361/202555512
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「珍しい天体」と返信すると、完全な PDF を入手できます。
AIフロンティアに関するその他の論文:
https://hyper.ai/papers
約1億のハッブルソースカットマップの標準化されたデータセットに基づいて構築されています
本研究で使用したデータセットは、O'Ryanらによって生成されたソースカットアウトに由来しています。この研究は当初、ハッブル・レガシー・アーカイブから相互作用銀河や合体銀河を体系的に探索することを目的としており、アーカイブ内のほぼすべての拡張ソースを処理して、最終的に大規模で標準化された画像セットを構築しました。データの一貫性と操作性を確保するために、研究者らは、ハッブル宇宙望遠鏡の調査用先進カメラの広視野チャンネルで F814W フィルターを使用して取得されたレベル 3 の較正済みモザイク画像のみを選択しました。これは、科学的な分析に直接使用できるレベルまで処理されたデータを指します。
このスクリーニング プロセスにより、Whitmore らが SourceExtractor ソフトウェアを使用して公開したハッブル ソース カタログ内の拡張ソースをカバーする約 1 万件の観測結果が得られました。その結果、約 9,960 万点の単一ソースの切り抜き画像を含む画像ライブラリが完成しました。各スライスは150×150ピクセルに固定されており、これは約7.5秒角四方の天体領域に相当します。Astropyの線形ストレッチングとZScaleInterval法を用いて強調され、グレースケールJPEG形式で保存されます。ハッブル宇宙望遠鏡のソースカタログ自体には重複除去のためのMatchIDが含まれていますが、Orionらは相互作用系や多核合体銀河の構造情報を保持するために、分類後にのみ重複除去を行うことを選択しました。研究者らは、トレーニングセットに同じソースからの異なるスライスが含まれないようにするためにも、同じ戦略を採用しました。
さらに、アンドロメダ銀河、マゼラン雲、球状星団などの特定のコンパクトな星域の深部観測では、密集した点光源がソフトウェアによって単一の「拡張光源」に結合され、特殊なタイプの画像アーティファクトが形成されることがあります。研究者らはその後の能動学習でそのような事例を特定し、注釈付きモデルを使用してそれらを低スコアの異常オブジェクトとして分類しました。データ アクセスの効率を向上させるために、約 9,960 万のスライスすべてが、約 1,000 個の HDF5 ファイルにまたがってブロックに保存されます。
トレーニングセットの構築にあたり、研究者らは当初、エッジアラインメントした原始惑星系円盤を対象としました。そのため、下図に示すように、初期のトレーニングデータには、そのような異常なサンプルが3つ、ラベル付きの正常サンプルが128個、そしてラベルなしの画像が多数含まれていました。正常サンプルは、データベース全体からのランダムサンプリングと手動スクリーニングによって取得され、孤立した銀河、星野、そして一般的なアーティファクトを網羅しています。
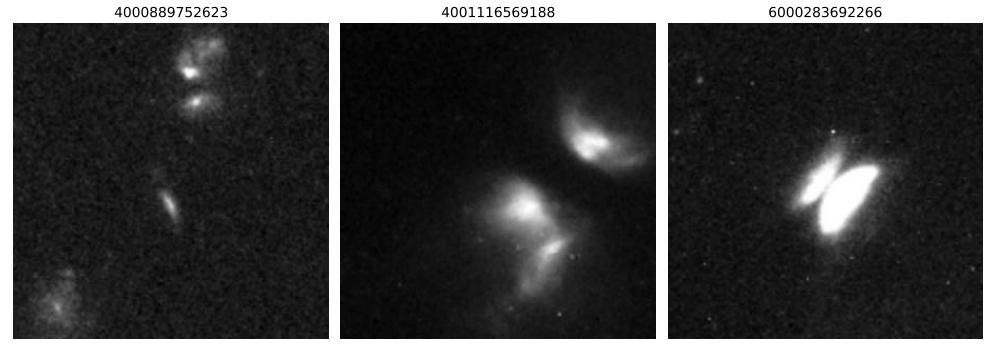
しかし、アクティブラーニングの導入により、モデルによって示された信頼性の高い候補天体は、特殊な形状と研究価値を持つ他の天体にもすぐに拡大されました。研究者たちはこれを用いて、より一般化されたトレーニングセットを徐々に構築・拡張し、最終的に1,400枚のラベル付き画像を含むようになりました。そのうち375枚は異常画像、1,025枚は正常画像でした。異常サンプルには主に、合体銀河(178個)と重力レンズ系(63個)が含まれていました。

トレーニングセットの多様性と規模が増大しているにもかかわらず、研究者たちはF814Wデータにおいて新たなエッジアラインメント型原始惑星系円盤を発見することができませんでした。これは主に2つの理由によるものです。第一に、この観測帯域ではこのような天体は極めて稀であること、第二に、他の異常種が徐々にトレーニングセットに組み込まれるにつれて、既知の原始惑星系円盤サンプルがトレーニングデータの一部となり、「未知の」異常とみなされて再検出される可能性が低下したことです。このプロセスは、この手法が特定のターゲット探索ツールから汎用的な異常検出フレームワークへと進化してきた実際の軌跡も反映しています。
AnomalyMatch: 半教師あり学習と能動学習を組み合わせたインタラクティブで効率的な異常検出フレームワーク。
AnomalyMatchは、大規模な天文データセットから希少天体を検出するという課題を解決するために研究者によって開発された機械学習フレームワークです。この手法の核となる革新性は…異常検出を極めて不均衡なバイナリ分類問題として明示的に定義し、半教師あり学習と能動学習ループを創造的に組み合わせています。これにより、ごく少数の既知の異常なサンプルのみに頼って、膨大な量のラベルなしデータから潜在的な希少ターゲットを効率的に発見できるようになります。
下図に示すように、このモデルの設計はFixMatchなどの高度な半教師あり学習パラダイムに基づいています。そのバックボーンは、ユーザーデータセットのラベル付きデータとラベルなしデータを用いてEfficientNetアーキテクチャを学習し、計算効率と特徴抽出能力のバランスを図っています。全体的なフレームワークは、2 つの協調学習コンポーネントで構成されています。教師あり学習部分では、焦点損失と動的重み付け戦略を組み合わせて使用します。また、まれな異常カテゴリに対してインテリジェントなオーバーサンプリングを実装し、極端なクラスの不均衡によって引き起こされるトレーニング バイアスを効果的に軽減します。教師なし部分では、弱く強調された画像を通じて信頼性の高い疑似ラベルを生成します。さらに、一貫性正規化制約が強力に強化されたバージョンに課され、モデルは表面アーティファクトに頼るのではなく、データ内の堅牢な形態学的表現を学習するように強制されます。
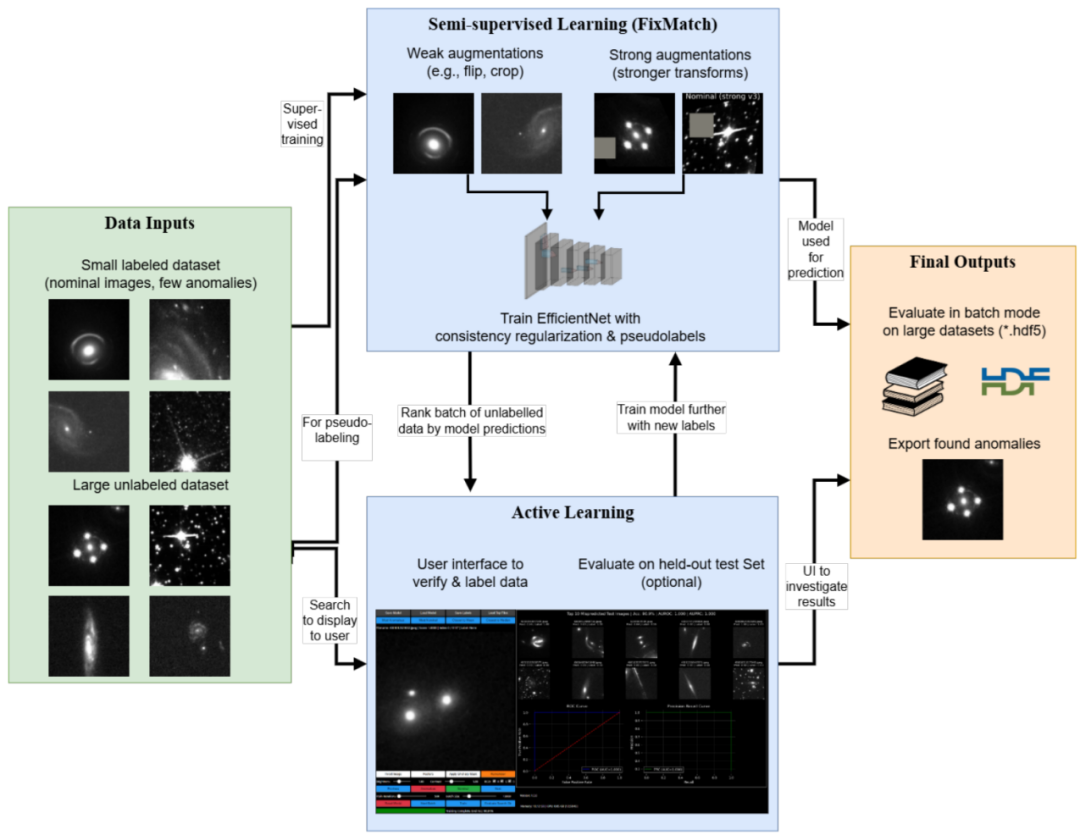
トレーニング メカニズムに関しては、モデルは段階的な最適化戦略を採用しています。初期段階では、少数のラベル付きサンプルを使用して教師ありウォームアップを行い、その後、ラベルなしデータとその疑似ラベルを徐々に導入して半教師ありトレーニングを行います。各トレーニングラウンドの後、モデルはラベルなしデータセット全体を推論し、各サンプルの「異常スコア」を出力します。このスコアは、異常カテゴリーにおけるモデルの予測信頼度に基づいており、ランキングの信頼性はキャリブレーション戦略によって強化されます。
重要なのは、AnomalyMatchがインタラクティブなアクティブラーニングワークフローをシームレスに統合していることです。このワークフローは、天文画像レビュー専用に設計されたWebインターフェースを通じて、モデル予測スコアが最も高い候補サンプルをドメインエキスパートに提示します。エキスパートはサンプルを迅速に分類、ラベル付け、または除外することができ、検証結果はリアルタイムでトレーニングループにフィードバックされます。新たに確認されたサンプルはラベルセットを拡張するだけでなく、そのアノテーション情報を使用してクラス重みと疑似ラベル閾値を動的に調整することで、「モデル推奨 - エキスパートによる確認 - モデルの反復」という自己強化的な閉ループを形成します。
約 1 億のソース カットを含む Hubble Heritage Archive の場合、モデルは完全なデータ推論の 1 ラウンドをわずか 2.5 日ほどで完了し、ブレークポイントの再開と増分更新をサポートします。このフレームワークは、実用化において、合体銀河、重力レンズ効果、クラゲ銀河といった多数の希少天体の発見に成功しただけでなく、文献に未だ記載されていないいくつかの特異なシステムも特定しました。その高い効率性と強力な汎化能力は、次世代の超大規模天体サーベイデータの処理におけるハイブリッドインテリジェントフレームワークの重要な価値を十分に実証しています。
ハッブル・ヘリテージ・アーカイブで1,339個の珍しい天体が発見された
モデルのトレーニングを完了した後、この研究ではそれをハッブル・ヘリテージ・アーカイブのデータセット全体に適用し、異常な天体を体系的に検索して分類しました。
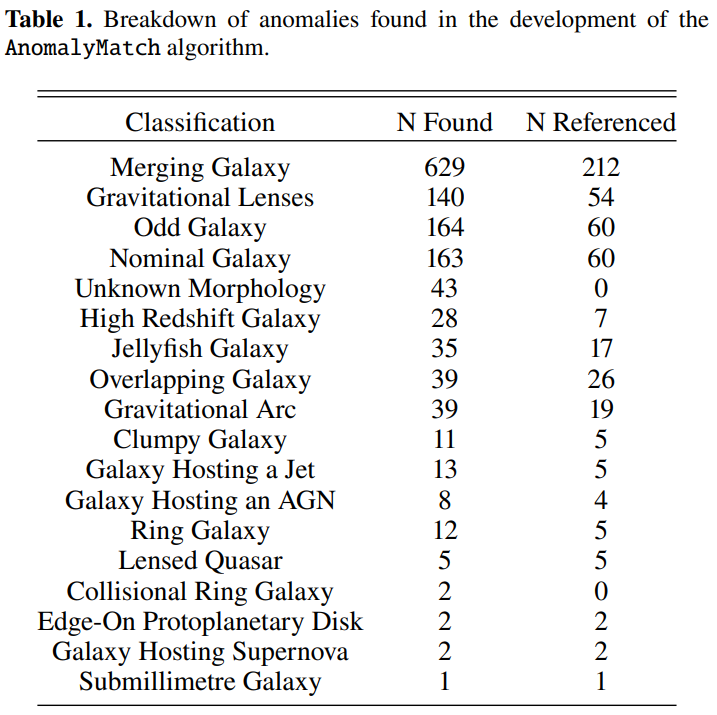
まず、研究者たちは、モデル出力において異常スコアが最も高かった5,000個の候補サンプルを厳密に重複排除しました。具体的には、サンプルのソースIDをハッブル宇宙望遠鏡のソースカタログと照合し、座標を抽出した後、半径10秒角の積極的なラジアルマッチングを行いました。2つの独立した異常天体がこのような小さな角度距離内に共存する確率は極めて低いため、この手法はデータの断片化によって生じる重複画像カットを効果的に排除します。このステップを経た結果は、下の図に示されています。研究者らは 1,339 個の固有の異常候補を取得しましたが、それ自体が元のデータセットに存在する高い繰り返し率の問題を直感的に反映しています。
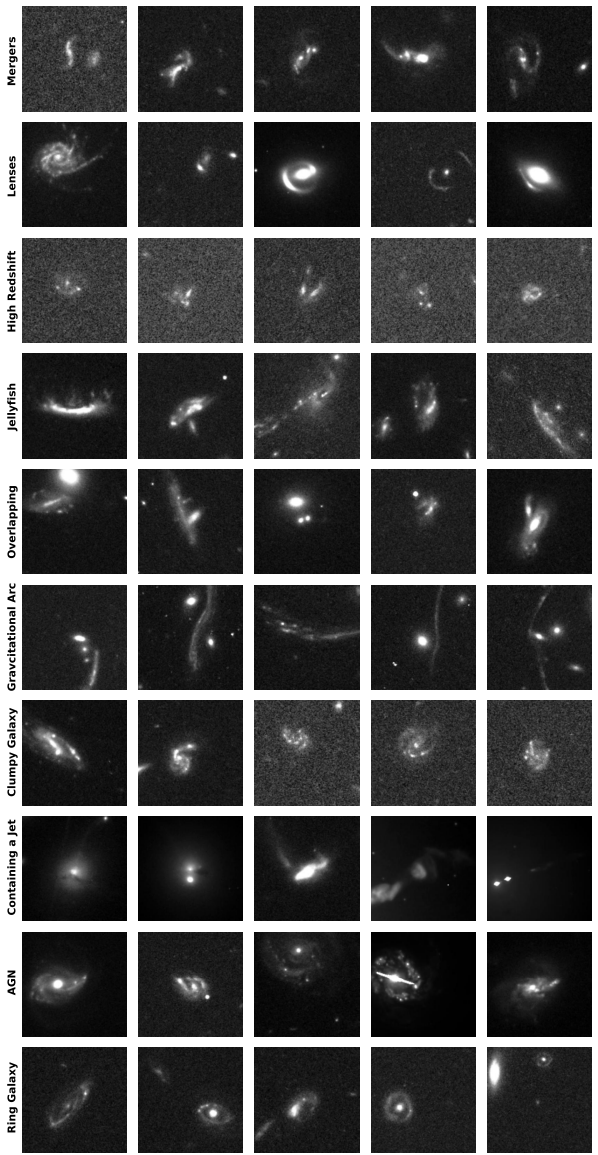
その後、分野の専門家が形態素解析とSIMBADやESASkyなどのデータベースにおける文献検索に基づき、1,339個の個別サンプルを綿密にサブ分類しました。分類結果は…合体または相互作用する銀河は最も頻繁に発見されるカテゴリーであり、合計 629 個の独立したシステムがあり、全体のおよそ 501 TP3T を占めています。
これは、このような天体が比較的一般的な異常なタイプであるという事実と、強い潮汐相互作用によって非常に独特な形態を呈し、モデルで容易に捉えられるという事実によるものです。研究者がプロットする視野は限られているため、非常に摂動的な後期合体系が画像上で単一の天体として現れる場合があることに注意が必要です。これらの合体特性は、視野を調整したり文献を参照したりしてさらに確認する必要があります。
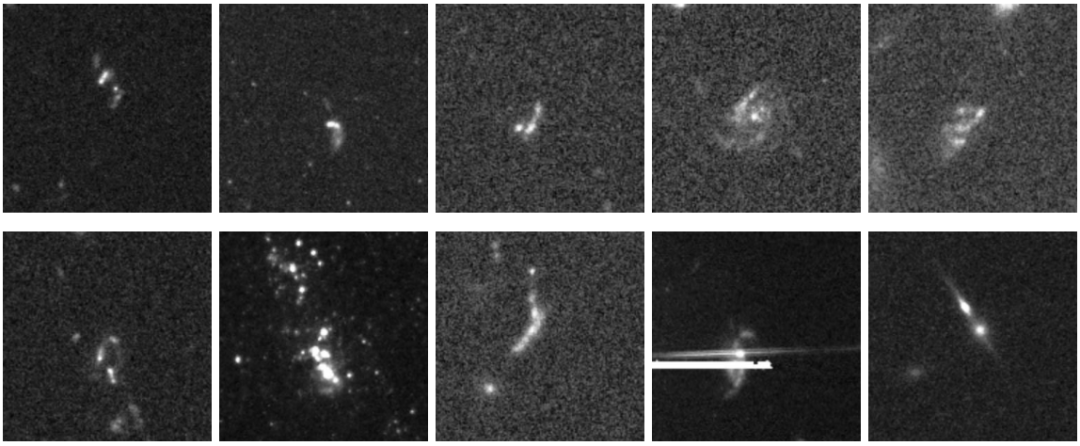
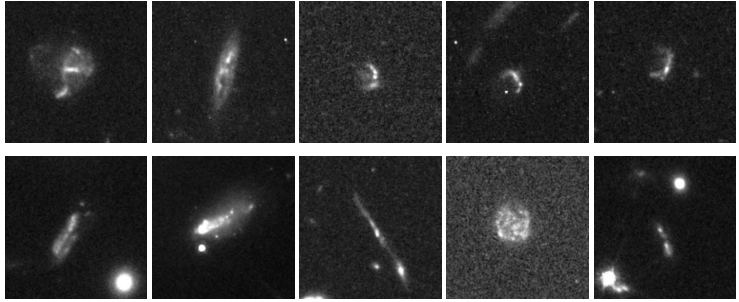
重力レンズ効果と関連現象は、異常現象の発見における第二の主要なカテゴリーを構成します。研究者らは、既知のレンズ効果系と多数の新たな候補を含む、強力な重力レンズ効果の候補を多数特定しました。さらに、彼らは39個の重力アークを識別しました。これらは典型的には前景の銀河団によって生成され、そのスケールはしばしば単一のチルダの範囲を超え、データ上では巨大な光の弧の断片としてのみ現れます。モデルはまた、高赤方偏移銀河群の検出にも成功しました。これらの銀河は、画像上では低い信号対雑音比、高密度でわずかに乱雑な斑点として現れ、このような天体の観測特性と一致しています。
他のカテゴリーでは、研究者らは厳しい基準を満たすクラゲ型銀河(すべて銀河団内に位置し、前縁のバウショックとストリッピングトレイルを呈している)を35個、クラスター型銀河を11個、そして同数の重なり合う銀河を発見した。特筆すべきは、このモデルは特別な訓練を一切行っていないにもかかわらず、形態学的特徴の認識において驚くべき一般化能力を示したことである。いくつかのクエーサーレンズ(「アインシュタインの十字」のような構造が特徴)と、可視帯域では非常に珍しい 13 個の相対論的ジェットホスト銀河が発見されました。これは、AnomalyMatch が学習した知識を転送し、トレーニング セットに出現していない異常なサブタイプを検出できることを示しています。
上記の明確に分類されたメンバーに加えて、最終的なカタログには、3 つの一般的なカテゴリも含まれています。「特殊銀河」は、既存のどのサブカテゴリにも当てはまらない、著しく不規則な形状を持つ天体を指します。「通常の銀河」は、モデルの判断が間違っている誤検出 (約 10%) を表し、主にわずかな構造的摂動、高密度の星野、または機器のアーティファクトを持つ孤立した銀河が含まれます。「未知の銀河」は、既存の知識に基づいて現在分類できない 43 の特異なターゲットをカバーしており、将来の研究の余地を残しています。
AIが現代天文学を変革する
次世代の大規模天体観測によってもたらされるデータの津波に直面して、世界の天文学研究は大きなパラダイムシフトを経験しています。
学術界では、天文データにおける複雑な時間的・状態的変化を機械がよりインテリジェントに理解できるようにする方法が研究の焦点の一つとなっています。例えば、トロント大学、インペリアル・カレッジ・ロンドン、ハーバード・スミソニアン天体物理学センターの研究チームは、連続空間隠れマルコフモデルに基づく新しい手法を開発し、天文源の異なる物理的状態を自動的に識別・分離しました。
簡単に言えば、この手法は恒星の活動を、連続的に変化する隠れた状態の連続としてモデル化します。私 望遠鏡で捉えた多帯域の光の変化曲線を分析することで、天体の物理的状態を常にインテリジェントに推測することが可能になります。研究チームはこのアルゴリズムをEV Lacと呼ばれる活発なフレア星に適用しました。AIはX線データから「静穏」や「フレア」といった異なる状態を区別することに成功し、噴火現象の特徴を正確に定量化しました。
論文のタイトル:
隠れマルコフモデルを用いた天文源の状態分離:EV Lacにおけるフレアと静穏化の事例研究
論文リンク:https://doi.org/10.1093/mnras/stae2082
同時に、ビジネス界は、もはや単なる技術提供者ではなく、科学ミッションの設計、構築、運用者として、前例のない形でこの天文データ革命に参加しています。その好例が、ヨーロッパを代表する宇宙技術企業であるOpen Cosmosです。同社は2024年にカタルーニャ宇宙研究所と提携しました…同社は、天体物理学研究専用の初の衛星プラットフォーム「PhotSat」を正式に設計・構築した。この小型ながらも強力なキューブサットは、2基の望遠鏡を搭載し、可視光線と紫外線の波長域で2日ごとに全天をスキャンし、数千万もの明るい恒星の変化を継続的に監視する予定です。その科学的目標は非常に明確です。太陽系外惑星の探索、恒星の特性評価、超新星爆発の観測といった重要な研究に貴重なデータストリームを提供することです。
大学の研究室で開発され、データの深層状態を洞察できる隠れマルコフモデルであれ、特定の科学的目標の達成に専念する民間宇宙企業が建造する天体物理衛星であれ、その核心的な原動力は、データの規模と複雑性の指数関数的な増大への対応です。ルービン天文台やローマ宇宙望遠鏡といった新世代施設の稼働に伴い、「インテリジェントアルゴリズム+革新的プラットフォーム」というこの双発モデルがさらに普及し、天文学を仮説主導からデータとアルゴリズムの両方が主導する新しい時代へと押し進め、広大な宇宙における稀少で貴重な宇宙の謎をより効率的に発見できるようになることが予測されます。








