Command Palette
Search for a command to run...
TRELLIS.2: O-Voxel テクノロジを採用し、複雑な 3D ジオメトリとマテリアルを効率的に生成します。患者離脱予測データセット: 離脱リスクのある患者を特定するのに役立ちます。

現在、画像から実用的な3Dモデルを生成するには時間と労力がかかり、従来のプロセスは専門のモデラーによる手作業に大きく依存しています。AIの支援があっても、複雑な形状、透明な素材、開いた表面を扱う場合、モデルは品質の低い結果や異常な構造を生成することが多く、ゲームや電子商取引で直接使用できるリアルな素材を使用した完成品を生成することは困難です。
このような背景から、Microsoft チームは、単一の画像から高品質の 3D アセットとテクスチャリング タスクを生成するオープンソース プロジェクト TRELLIS.2 を 2025 年 12 月にリリースしました。このプロジェクトは、入力画像から 3D シェイプやマテリアルまでのエンドツーエンドのプロセスを提供し、迅速な体験とアセットのエクスポートを可能にするインタラクティブな Web デモが付属しています。 TRELLIS.2 は、幾何学的な詳細とテクスチャの一貫性の向上に重点を置いており、複数の解像度とカスケード推論構成をサポートし、制御可能な推論パラメータを通じて速度と品質のバランスをとるため、3D コンテンツ制作、ラピッドプロトタイピング、クリエイティブな探求などのシナリオに適しています。
HyperAIのWebサイトでは「TRELLIS.2 3D世代デモ」を公開していますので、ぜひお試しください。
オンラインでの使用:https://go.hyper.ai/drI7I
1月19日から1月23日までのhyper.ai公式サイトの更新内容の概要は次のとおりです。
* 高品質の公開データセット: 5
* 厳選された高品質のチュートリアル:9
* 今週のおすすめ論文: 5
* コミュニティ記事の解釈:4件
* 人気のある百科事典のエントリ: 5
1月締め切りのトップカンファレンス:3
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. 患者セグメンテーションデータセット
患者セグメンテーションは、医療分析とマーケティングのための患者分類データセットです。患者の人口統計、健康状態、保険の種類、医療利用パターンを分析し、患者を意味のあるグループに分類することで、パーソナライズされたケアとマーケティングの効果を高めることを目的としています。
直接使用します:https://go.hyper.ai/Wp8LS
2. CCTV事故転倒検知データセット
CCTV Incidentは、コンピュータービジョンタスクにおける転倒検知、姿勢推定、事故監視のために特別に設計されたオープンな合成データセットです。CCTVの俯瞰画像から分析するように設計されており、モデルが人間の姿勢を理解し、立っている人と転倒した人を正確に区別することを可能にします。
直接使用します:https://go.hyper.ai/q60Dm

3. 患者離脱予測データセット
患者離脱予測データセットは、離脱リスクのある患者を特定し、事前に維持対策を講じることができるように設計された 2,000 件の患者記録を含む医療分野のカテゴリ データセットです。
直接使用します:https://go.hyper.ai/QAeYw
4. RealTimeFaceSwap-10kビデオ通話なりすましデータセット
RealTimeFaceSwap-10k ビデオ通話ディープフェイク検出データセットは、ビデオ会議シナリオにおけるディープフェイク動画の検出に使用されるデータセットです。このデータセットには、様々なアプリケーションシナリオとデータタイプが含まれており、動画スプーフィング検出のための基本的なデータサポートを提供することを目指しています。
直接使用します:https://go.hyper.ai/SGZRO
5. TransPhy3D 透明反射合成ビデオデータセット
TransPhy3Dは、北京人工知能研究院が南カリフォルニア大学、清華大学、その他の研究機関と共同で開発した合成動画データセットで、透明シーンと反射シーンに焦点を当てています。このデータセットは、Blender/Cyclesを使用してレンダリングされた11,000シーケンスで構成されており、高品質のRGBフレームに加え、物理ベースの深度ラベルと法線ラベルが提供されています。
直接使用します:https://go.hyper.ai/5ExjE
選択された公開チュートリアル
1.vLLM + Open WebUI デプロイ Nemotron-3 Nano
Nemotron-3-Nano-30B-A3B-BF16は、NVIDIAがゼロから学習した大規模言語モデル(LLM)であり、推論タスクと非推論タスクの両方に適用可能な統合モデルとして設計されています。このモデルは、AIエージェントシステム、チャットボット、RAGシステム、その他のAIアプリケーションを設計する開発者に適しています。
オンラインで実行:https://go.hyper.ai/VUuDA
2. MedGemma 1.5 マルチモーダルAI医療モデル
MedGemma 1.5は、医療マルチモーダルタスクに優れたモデルです。画像分類、視覚的な質問応答、医療知識推論において卓越した能力を発揮し、様々な臨床シナリオに適しており、医療研究と医療現場を効果的にサポートします。このモデルは、SigLIP画像エンコーダーと高性能言語モジュールを基盤とし、医療画像、テキスト、臨床検査レポートなど、多様なデータセットで事前学習されています。これにより、高次元医療画像、病理画像全体、縦断画像解析、解剖学的局在、医療文書理解、電子医療記録解析といったタスクを効率的に処理できます。
オンラインで実行:https://go.hyper.ai/dZRn9
3. Nemotron-Speech-Streaming-ASR: 自動音声認識デモ
Nemotron Speech Streaming ASRは、NVIDIAのNemotron Speechチームがリリースしたストリーミング自動音声認識モデルです。低遅延、リアルタイムの音声書き起こしシナリオ向けに設計されており、高スループットのバッチ推論機能も備えているため、音声アシスタント、リアルタイムキャプション作成、会議書き起こし、会話型AIなどのアプリケーションに適しています。このモデルは、キャッシュ対応のFastConformerエンコーダーとRNN-Tデコーダーアーキテクチャを採用しており、連続したオーディオストリームを効率的に処理しながら、エンドツーエンドの遅延を大幅に削減しながら認識精度を維持します。
オンラインで実行:https://go.hyper.ai/SDEBI
4. TranslateGemma-4B-IT: Google のオープンソース翻訳モデル シリーズ。
TranslateGemmaは、Google翻訳チームがリリースした軽量なオープンソース翻訳モデルファミリーです。Gemma 3モデルファミリーをベースに構築され、多言語テキスト翻訳と実世界への導入シナリオ向けに特別に設計されています。コンパクトなパラメータスケールで安定した使いやすい翻訳機能を提供するため、GPUメモリが限られている環境や迅速な導入が求められる環境での読み込みと推論に適しています。
オンラインで実行:https://go.hyper.ai/FRy35
5. GLM-Image: 正確なセマンティクスを備えた高忠実度画像生成モデル
GLM-Imageは、Zhipu AIが開発したオープンソースの画像生成モデルで、自己回帰デコードと拡散デコードを統合しています。このモデルは、テキストから画像への生成と画像から画像への生成の両方をサポートし、統一された視覚言語表現に基づいて構築されています。これにより、同じモデルでテキストプロンプトと入力画像の両方を理解し、DiT(Diffusion Transformer)スタイルの拡散バックボーンネットワークを通じて洗練された画像生成を行うことができます。
オンラインで実行:https://go.hyper.ai/2bcfV

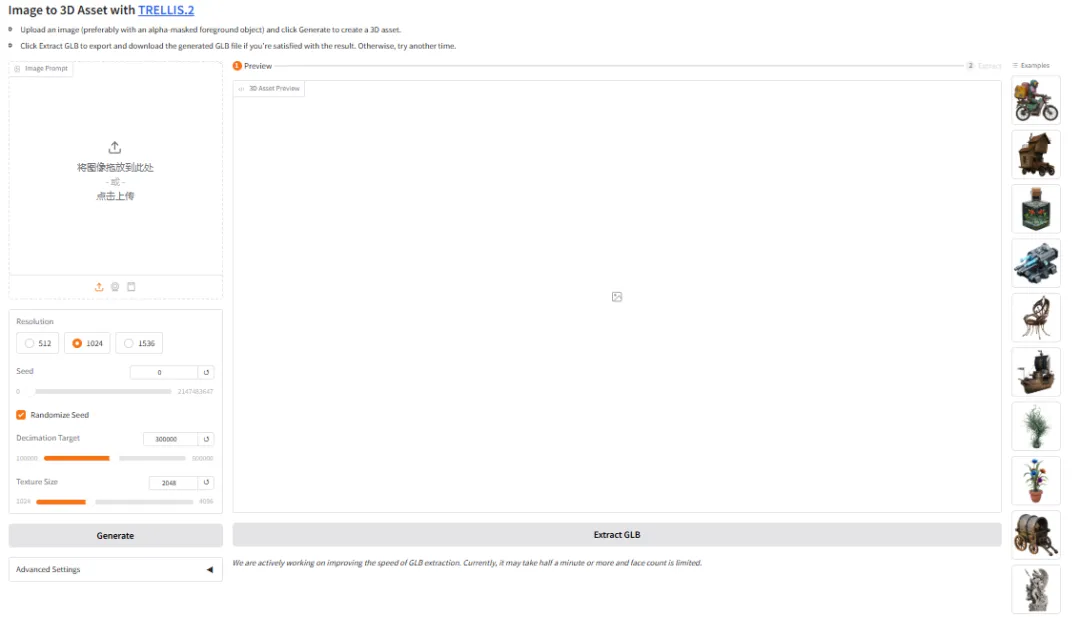
6. TRELLIS.2 3Dデモ生成
TRELLIS.2は、Microsoftがリリースしたオープンソースプロジェクトです。40億のパラメータを持つ大規模モデルで、1枚の画像からテクスチャが完全に組み込まれ、すぐに使用できる3Dアセットを直接生成することに重点を置いています。このモデルは、高品質なジオメトリとマテリアル生成を統合し、高忠実度のジオメトリ再構築とフルディメンションPBRマテリアル合成を単一のワークフローで実現します。
オンラインで実行:https://go.hyper.ai/drI7I
7.vLLM+Open WebUI展開機能Gemma-270m-it
FunctionGemma-270m-itは、Google DeepMindがリリースした2億7000万のパラメータを持つ軽量な関数呼び出し専用モデルです。Gemma 3 270Mアーキテクチャを基盤とし、Geminiシリーズと同じ研究手法を用いて学習されています。関数呼び出しシナリオ向けに特別に設計されたこのモデルは、2024年8月までの6TBの学習データを活用し、公開ツール定義とツール使用インタラクションデータを網羅しています。FunctionGemmaは最大32KBのコンテキスト長をサポートし、厳格なコンテンツセキュリティフィルタリングと責任あるAI開発プロセスを経ています。
オンラインで実行:https://go.hyper.ai/pdN7q

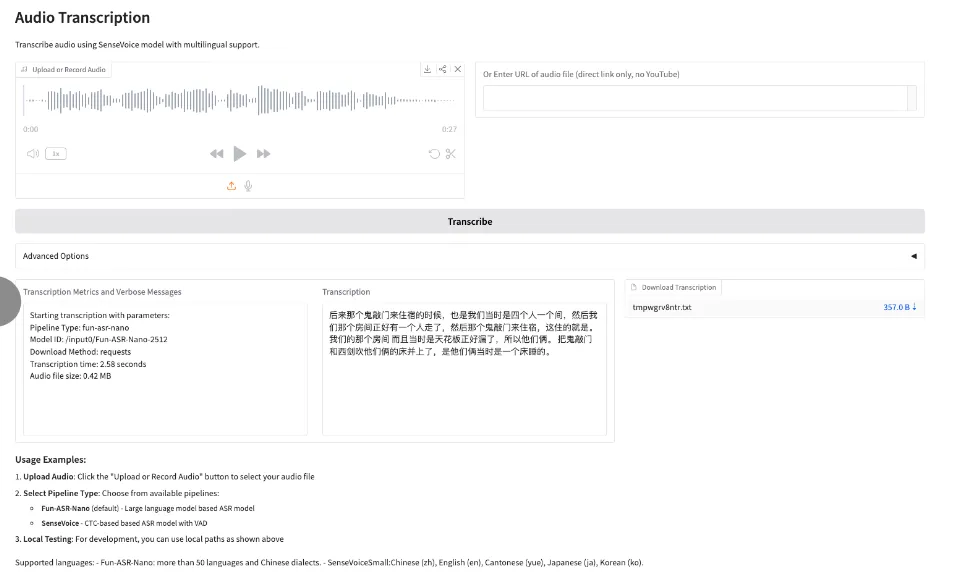
8. Fun-ASR-Nano: 大規模エンドツーエンド音声認識モデル
Fun-ASR-Nanoは、Alibaba Tongyi Labsが発表したエンドツーエンドの大規模モデル音声認識ソリューションであり、Fun-ASRシリーズの一部です。このソリューションは、低コンピューティングパワーの導入シナリオ向けに設計されており、低遅延の音声テキスト化を実現することを目指し、実世界の評価セットにおけるパフォーマンスに重点を置いています。その機能には、多言語自由音声認識(フリーコードスイッチング)、カスタマイズ可能なホットワード、幻覚抑制などがあります。
オンラインで実行:https://go.hyper.ai/j7OdD
9. Fara-7B: 効率的なWebベースのインテリジェントエージェントモデル
Fara-7Bは、Microsoft Researchが発表した、コンピュータ向けの初のエージェント型SLM(Small Language Model)です。わずか70億(7B)のパラメータ数でありながら、実世界のWebページ操作タスクにおいて非常に優れたパフォーマンスを発揮し、複数のWebエージェントベンチマークにおいて最先端(SOTA)性能を達成しました。また、一部のタスクでは、より大規模なモデルに迫り、あるいは凌駕する性能を発揮しています。
オンラインで実行:https://go.hyper.ai/2e5rp
今週のおすすめ紙
1. 視聴、推論、検索:オープンウェブ上のエージェントビデオ推論のためのビデオディープリサーチベンチマーク
本論文では、ビデオディープラーニングのベンチマークとして初めてVideoDRを構築しました。このベンチマークでは、モデルがビデオから視覚アンカーを抽出し、インタラクティブな検索を実行し、複数のソースのエビデンスに基づいてマルチホップ推論を実行することが求められます。様々な大規模モデルの評価により、エージェントパラダイムが必ずしもワークフローパラダイムよりも優れているわけではないことが明らかになりました。その有効性は、長い検索チェーンにおいて初期の視覚アンカーを維持するモデル能力に依存します。本研究では、ターゲットドリフトと長期的な一貫性が主要なボトルネックであると特定しています。
論文リンク:https://go.hyper.ai/uB9jE
2. BabyVision: 言語を超えた視覚的推論
本研究では、既存のMLLMが言語的事前知識に過度に依存しており、幼児が持つ中核的な視覚能力を欠いていることが明らかになりました。研究チームによるBabyVisionベンチマークテストでは、最高性能のモデル(例えばGeminiは49.7)が成人レベル(94.1)を大幅に下回るスコアを記録し、6歳児のスコアにも及ばないことが示されました。これは、基本的な視覚理解能力に根本的な欠陥があることを示唆しています。本研究は、MLLMを人間レベルの視覚知覚と推論能力へと進化させることを目指しています。
論文リンク:https://go.hyper.ai/cjtcE
3. STEP3-VL-10B技術レポート
本論文では、高性能なオープンソース・マルチモーダル基盤モデルとしてSTEP3-VL-10Bを提案します。統合された事前学習、強化学習、そして革新的な並列協調推論メカニズムにより、わずか100億パラメータで卓越した性能を実現します。複数のベンチマークテストにおいて、10~20倍の巨大モデルやトップクラスのクローズドソースモデルに匹敵、あるいは凌駕する性能を示し、視覚言語知能のための強力かつ効率的なベンチマークとしてコミュニティに提供します。
論文リンク:https://go.hyper.ai/q6kmv
4. 地図で考える:地理位置情報のための強化並列地図拡張エージェント
本論文では、モデルが「地図を使って考える」ことを可能にすることを提案しています。エージェントマップループと二段階最適化、強化学習、並列テスト時間スケーリングを採用することで、画像による地理位置情報の精度を大幅に向上させます。新たに構築された実世界画像ベンチマークMAPBenchにおいて、この手法は既存のオープンソースおよびクローズドソースモデルを凌駕し、500メートル以内の精度を8.01 TP3Tから22.11 TP3Tへと飛躍的に向上させました。
論文リンク:https://go.hyper.ai/Fn9XT
5. 視覚言語推論による都市社会意味セグメンテーション
本研究では、衛星画像における社会的意味エンティティのセグメンテーションという課題に対処するため、視覚言語モデルを用いた推論のためのSocioSegデータセットとSocioReasonerフレームワークを提案する。この手法は、クロスモーダル認識と多段階推論を通じて人間のアノテーションプロセスをシミュレートし、強化学習を用いて最適化されている。実験的に、既存の最先端モデルを凌駕する性能を示し、強力なゼロショット汎化能力を示した。
論文リンク:https://go.hyper.ai/PW7g4
コミュニティ記事の解釈
1. タンパク質配列、3D 構造、機能特性データを統合し、ドイツのチームはメトリック学習に基づいてヒト E3 ユビキチンリガーゼの「パノラマビュー」を構築しました。
生物において、細胞タンパク質の適時な分解と再生は、タンパク質恒常性の維持に不可欠です。ユビキチン-プロテアソームシステム(UPS)は、シグナル伝達とタンパク質分解を制御する中核的なメカニズムです。このシステムにおいて、E3ユビキチンリガーゼは重要な触媒ユニットとして機能し、これまで研究されてきたE3リガーゼは高い異質性を示しています。こうした背景から、ドイツのゲーテ大学の研究チームは「ヒトE3リゴーム」を分類しました。この分類法は、弱教師付き階層的フレームワークを用いた計量学習パラダイムに基づいており、E3ファミリーとそのサブファミリー間の真の関係性を捉えています。
レポート全体を表示します。https://go.hyper.ai/zyM1F
2. イェール大学は、2,000人以上のAI化学専門家のチームを構築し、効率的な特化と最適な合成経路の特定を可能にするMOSAICを提案しました。
現代の合成化学は、知識の急速な蓄積とその応用・変換の効率性の間に、顕著な矛盾に直面しています。現在、この分野の発展は主に二つの要因によって制約されています。第一に、専門家の経験だけでは拡大し続ける反応空間をカバーするのに苦労しており、学際的な合成課題において試行錯誤のコストが高額になることがよくあります。第二に、人工知能技術の急速な発展にもかかわらず、化学における汎用モデルの信頼性は依然として不十分です。こうした背景から、イェール大学の研究チームは最近、汎用的な大規模言語モデルを、多数の専門化学専門家で構成される協調システムへと変換するMOSAICモデルを提案しました。
レポート全体を表示します。https://go.hyper.ai/oatBT
3. オンラインチュートリアル | GLM-Image: 自己回帰型デコーダと拡散型デコーダのハイブリッドアーキテクチャに基づく指示の正確な理解と正しいテキストの記述
画像生成分野において、拡散モデルは安定した学習能力と強力な汎化能力により、徐々に主流となりつつあります。しかし、「知識集約型」のシナリオにおいては、従来のモデルは指示理解と詳細な特性評価を同時に処理することが困難でした。この問題を解決するため、ZhipuはHuaweiと共同で、新世代の画像生成モデルGLM-Imageをオープンソース化しました。このモデルは、Ascend Atlas 800T A2とMindSpore AIフレームワーク上で完全に学習されています。その中核となる特徴は、「自己回帰+拡散デコーダー」(9B自己回帰モデル+7B DiTデコーダー)という革新的なハイブリッドアーキテクチャを採用し、言語モデルの深い理解能力と拡散モデルの高品質な生成能力を融合させています。
レポート全体を表示します。https://go.hyper.ai/LTojo
4. 清華大学とシカゴ大学による最新のNature研究結果!AIは科学者の昇進を1.37年早め、科学研究の範囲を4.631 TP3T削減することを可能にする
最近、清華大学とシカゴ大学の研究チームが「人工知能ツールは科学者の影響力を拡大するが、科学の焦点を縮小する」と題する最新の研究結果をネイチャー誌に発表し、AIが科学に与える根本的な影響を業界が理解するための前例のない体系的な証拠を提供しました。
レポート全体を表示します。https://go.hyper.ai/0NhLI
人気のある百科事典の項目を厳選
1. 1秒あたりのフレーム数(FPS)
2. 逆ソート融合RRF
3. 視覚言語モデル(VLM)
4. ハイパーネットワーク
5. ゲート型注意
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
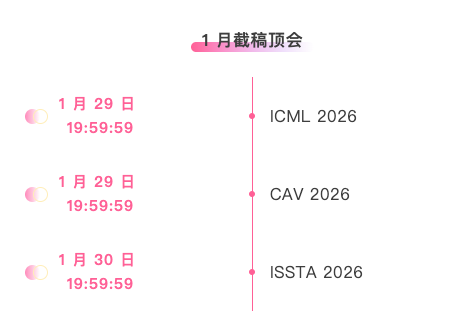
トップ AI 学術会議を追跡できるワンストップ プラットフォーム:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








