Command Palette
Search for a command to run...
Open-AutoGLM の低障壁トライアル: 画面理解と自動実行を組み合わせたインテリジェント エージェント エクスペリエンス、Spatial-SSRL-81k: 空間認識のための自己監督型改善パスの構築。

「豆宝モバイル」がまだ流行りつつあるという議論の最中だったが、Zhipu AIは、モバイルインテリジェントアシスタントフレームワークであるOpen-AutoGLMをオープンソース化したと発表した。画面コンテンツのマルチモーダル理解と自動操作を可能にします。
従来のモバイル自動化ツールとは異なり、電話エージェントは、ビジュアル言語モデルを使用して画面コンテンツの深い意味理解を実現し、インテリジェントな計画機能を組み合わせて操作プロセスを自動的に生成して実行します。システムはADB(Android Debug Bridge)を介してデバイスを制御します。ユーザーは「小紅書を開いて食べ物を探す」など、自然言語でニーズを説明するだけで、Phone Agentが自動的にその意図を解析し、現在のインターフェースを理解し、次のアクションを計画して、プロセス全体を完了します。
セキュリティと制御性の観点から、システムは繊細な操作確認メカニズムを備えており、ログイン、支払い、認証コードなど、手動介入が必要なシナリオにおいてユーザーの操作を引き継ぎ、安全で信頼性の高いユーザーエクスペリエンスを保証します。さらに、Phone AgentはリモートADBデバッグ機能を備えており、Wi-Fiまたはモバイルネットワーク経由のデバイス接続をサポートし、開発者や上級ユーザーに柔軟なリモートコントロールとリアルタイムデバッグサポートを提供します。
現在のところ、このフレームワークに基づいて実装された Open-AutoGLM は、WeChat、Taobao、Xiaohongshu など 50 を超える中国の主流アプリケーションに適用されています。ソーシャルインタラクションや電子商取引の買い物からコンテンツの閲覧まで、さまざまな日常のタスクを処理でき、衣食住交通など、ユーザーの生活のあらゆる側面をカバーするインテリジェントアシスタントへと徐々に進化しています。
HyperAIのWebサイトでは「Open-AutoGLM:モバイルデバイス向けスマートアシスタント」を特集していますので、ぜひお試しください。
オンラインでの使用:https://go.hyper.ai/QwvOU
12月8日から12月12日までのhyper.ai公式サイトの更新内容の概要は次のとおりです。
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 5
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
1月締め切りのトップカンファレンス:11
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. Envision マルチステージイベントビジュアル生成データセット
Envisionは、上海人工知能研究所が公開した複数画像テキストペアデータセットで、現実世界の出来事における因果関係を理解し、多段階の物語を生成するモデルの能力をテストするために設計されています。このデータセットには、自然科学と人文科学/歴史の6つの主要分野を網羅する1,000のイベントシーケンスと4,000の4段階テキストプロンプトが含まれています。イベント資料は教科書やオンラインリソースから収集され、専門家によって選定され、GPT-4oによって生成・改良され、明確な因果関係と段階的に展開する物語プロンプトを形成しています。
直接使用します:https://go.hyper.ai/xD4j6
2. DetectiumFire マルチモーダル火災理解データセット
DetectiumFireは、チューレーン大学がアアルト大学と共同で公開したデータセットで、炎の検知、視覚推論、マルチモーダル生成タスク向けに設計されています。NeurIPS 2025のデータセットおよびベンチマークトラックに含まれており、コンピュータービジョンおよび視覚言語モデルにおける火災現場の統合的なトレーニングおよび評価リソースの提供を目指しています。このデータセットには、145,000枚を超える高品質な実世界の火災画像と25,000本の火災関連動画が含まれています。
直接使用します:https://go.hyper.ai/7Z92Z

3. Care-PD パーキンソン病 3D 歩行評価データセット
CARE-PDは、トロント大学がベクター研究所、KITE研究所(トロント大学ハーバード大学病院)などの研究機関と共同で公開したデータセットであり、現在、パーキンソン病に関する公開3D歩行メッシュデータセットとしては最大規模です。NeurIPS 2025データセットおよびベンチマークに選定されており、臨床スコア予測、パーキンソン病の歩行表現学習、そして統一された施設間分析のための高品質なデータ基盤を提供することを目指しています。このデータセットには、8つの臨床機関から9つの独立したコホートに所属する362名の被験者の歩行記録が含まれています。すべての歩行ビデオとモーションキャプチャデータは均一に処理され、匿名化されたSMPL 3D人間歩行メッシュに変換されています。
直接使用します:https://go.hyper.ai/CH7Oi
4. PolyMath多言語数学推論ベンチマークデータセット
PolyMathは、アリババのQianwenチームが上海交通大学と共同で公開した多言語数学推論評価データセットです。NeurIPS 2025データセットおよびベンチマークに選定されており、多言語環境下における大規模言語モデルの数学的理解、推論の深さ、および言語間の一貫性性能を体系的に評価することを目的としています。
直接使用します:https://go.hyper.ai/VM5XK
5. VOccl3D 3Dヒューマンオクルージョンビデオデータセット
VOccl3Dは、カリフォルニア大学が公開した大規模な合成データセットで、複雑な遮蔽シーンにおける3D人間の理解に焦点を当てています。人間の姿勢推定、再構成、およびマルチモーダル知覚タスクのための、より現実的なベンチマークを提供することを目的としています。このデータセットには、背景シーン、人間の動作、多様なテクスチャから構築された25万枚以上の画像と約400本の動画シーケンスが含まれています。
直接使用します:https://go.hyper.ai/vBFc2

6. Spatial-SSRL-81k 空間認識自己教師データセット
Spatial-SSRL-81kは、上海人工知能研究所が上海交通大学、香港中文大学などの研究機関と共同で公開した、空間理解と空間推論のための自己教師あり視覚言語データセットです。本データセットは、手動によるアノテーションなしで大規模モデルに空間認識機能を提供し、マルチモーダルシナリオにおける推論および汎化性能を向上させることを目的としています。
直接使用します:https://go.hyper.ai/AfHSW

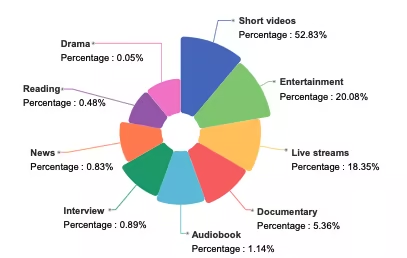
7. WenetSpeech-Chuan(四川省・重慶省方言音声データセット)
WenetSpeech-Chuanは、西北工科大学がHillbeike、中国電信人工知能研究所などの機関と共同で公開した、大規模な四川語および重慶語方言音声データセットです。このデータセットは9つの実世界シナリオを網羅しており、短編動画は52,83%を占めています。その他、エンターテイメント、ライブストリーミング、オーディオブック、ドキュメンタリー、インタビュー、ニュース、朗読、ドラマなどが含まれており、非常に多様でリアルな音声分布を示しています。
直接使用します:https://go.hyper.ai/dFlE2
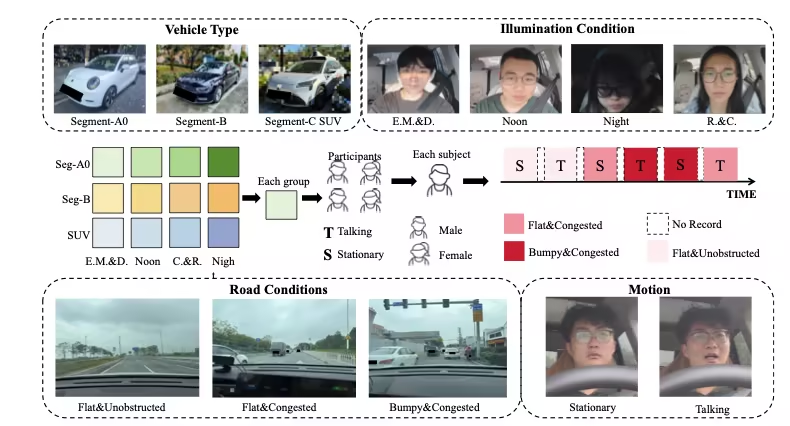
8. PhysDriver生理学的検査データセット
PhysDriveは、香港科技大学(広州)、香港科技大学、清華大学などの機関によって公開された、実運転環境における車内非接触生理学的計測のための初の大規模マルチモーダルデータセットです。NeurIPS 2025データセットおよびベンチマークに選定されており、運転者状態モニタリング、スマートコックピットシステム、マルチモーダル生理学的知覚手法の研究と評価を支援することを目的としています。
直接使用します:https://go.hyper.ai/4qz9T
9. MMSVGBench マルチモーダルベクターグラフィックス生成ベンチマークデータセット
MMSVG-Benchは、復旦大学とStepFunが共同でリリースした、マルチモーダルSVG生成タスク向けに設計された包括的なベンチマークです。NeurIPS 2025のデータセットとベンチマークに選定されており、統一されたオープンで標準化されたテストセットが不足している現在のベクターグラフィックス生成分野におけるギャップを埋めることを目的としています。
直接使用します:https://go.hyper.ai/WiZCR
10. PolypSense3D ポリープサイズ認識データセット
PolypSense3Dは、杭州師範大学がデンマーク工科大学、河海大学などの研究機関と共同で公開した、深度センシングによるポリープサイズ測定タスク向けに特別に設計されたマルチソースベンチマークデータセットです。NeurIPS 2025に選定されており、ポリープ検出、深度推定、サイズ測定、シミュレーションから実世界への転移学習のための高品質なトレーニングおよび評価リソースを提供することを目的としています。
直接使用します:https://go.hyper.ai/SZnu6
選択された公開チュートリアル
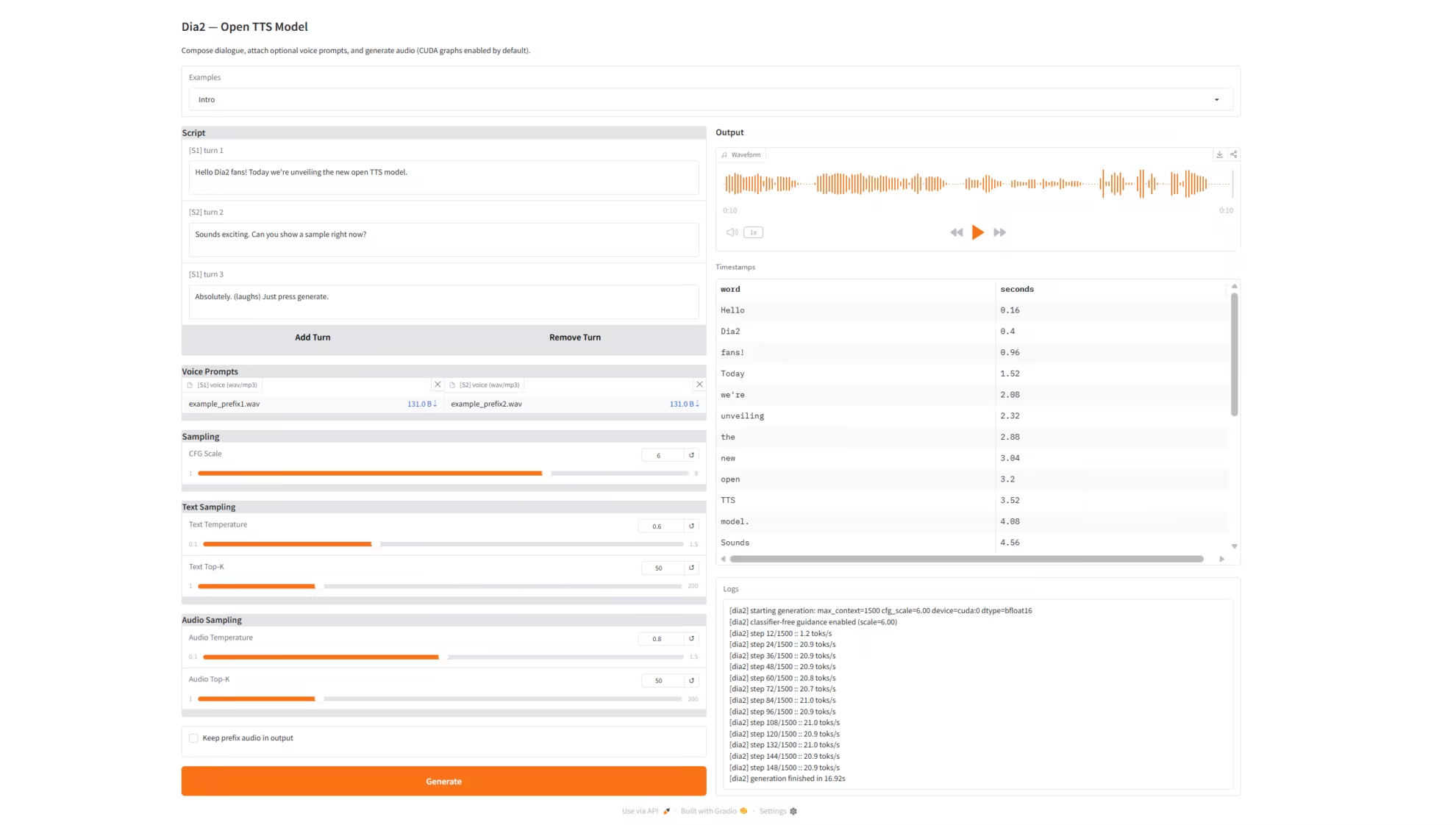
1. Dia2-TTS: リアルタイム音声合成サービス
Dia2-TTSは、nari-labsチームがリリースしたDia2大規模音声生成モデル(Dia2-2B)をベースに構築されたリアルタイム音声合成サービスです。マルチターンの対話スクリプト入力、デュアルロール音声プロンプト(Prefix Voice)、マルチパラメータ制御可能なサンプリングに対応し、Gradoを介して完全なWebベースのインタラクティブインターフェースを提供し、高品質な会話音声合成を実現します。このモデルは、連続したマルチターンの対話スクリプトを直接入力することで、自然で一貫性のある高品質な音声を生成することができ、バーチャルカスタマーサービス、音声アシスタント、AIダビング、ショートドラマ生成などのアプリケーションに適しています。
オンラインで実行:https://go.hyper.ai/Qbfni
2. Open-AutoGLM: モバイルデバイス向けスマートアシスタント
Open-AutoGLMは、Zhipu AIがAutoGLMを基盤としてリリースしたモバイルインテリジェントアシスタントフレームワークです。このフレームワークは、モバイル画面のコンテンツをマルチモーダルに理解し、自動操作によってユーザーのタスク完了を支援します。従来のモバイル自動化ツールとは異なり、Phone Agentは画面認識のための視覚言語モデルとインテリジェントなプランニング機能を組み合わせることで、操作プロセスを自動生成・実行します。
オンラインで実行:https://go.hyper.ai/QwvOU
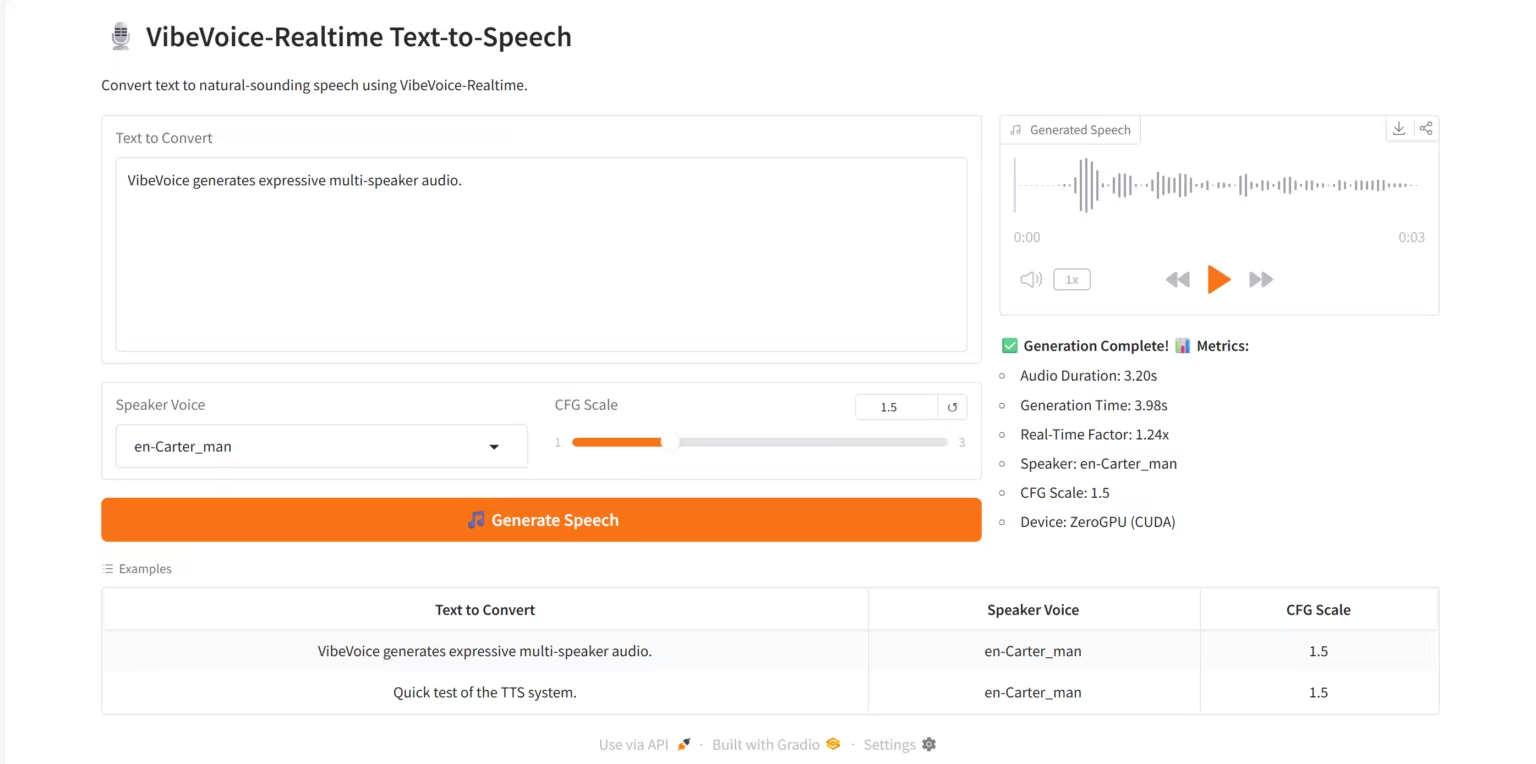
3. VibeVoice-Realtime TTS: リアルタイム音声合成サービス
VibeVoice-Realtime TTSは、Microsoft Researchチームがリリースしたストリーミング音声合成モデルVibeVoice-Realtime-0.5Bをベースに構築された、高品質なリアルタイム音声合成(TTS)システムです。このシステムは、Gradoウェブプラットフォーム上で、複数話者による音声生成、低遅延のリアルタイム推論、インタラクティブなビジュアル表示をサポートします。
オンラインで実行:https://go.hyper.ai/RviLs
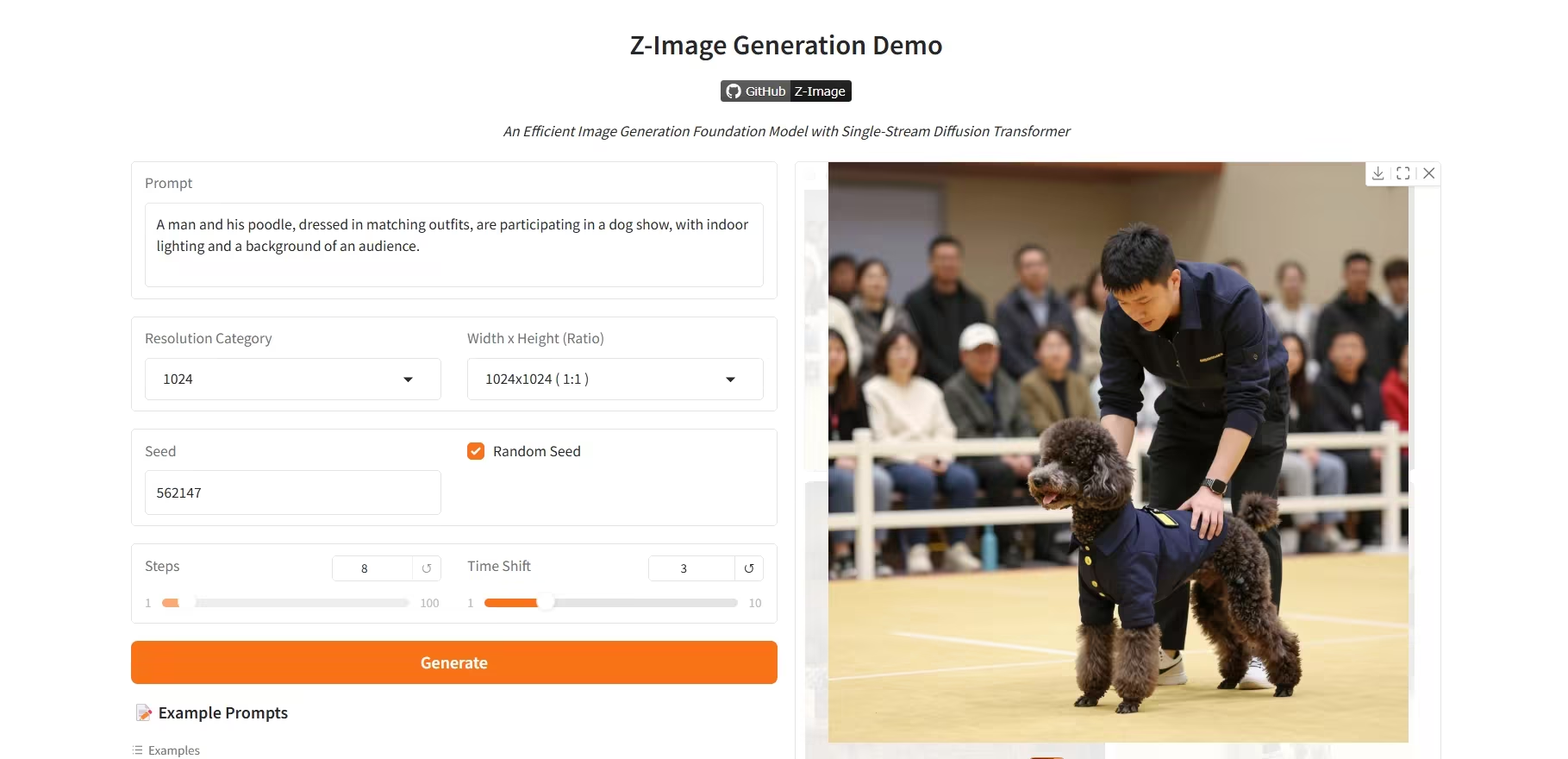
4. Z-Image-Turbo: 高効率6Bパラメータ画像生成モデル
Z-Image-Turboは、アリババのTongyi Qianwenチームがリリースした新世代の高効率画像生成モデルです。わずか6バイトのパラメータで、20バイトを超えるパラメータを持つフラッグシップのクローズドソースモデルに匹敵するパフォーマンスを実現し、特に高忠実度でフォトリアリスティックなポートレートの生成に優れています。
オンラインで実行:https://go.hyper.ai/R8BJF
5. Ovis-Image: 高品質画像生成モデル
Ovis-Imageは、AIDC-AIチームがリリースした高忠実度テキスト画像生成モデルOvis-Image-7Bをベースに構築された、高品質なテキスト画像(T2I)生成モデルシステムです。このシステムは、マルチスケールTransformerエンコーダーと自己回帰生成アーキテクチャを採用しており、高解像度画像生成、詳細表現、マルチスタイル適応において卓越した性能を発揮します。
オンラインで実行:https://go.hyper.ai/NoaDw

今週のおすすめ紙
1. Wan-Move: 潜在軌道誘導による動作制御可能なビデオ生成
本論文では、ビデオ生成モデルにモーション制御機能を導入する、シンプルでスケーラブルなフレームワークであるWan-Moveを提案する。既存のモーション制御手法は、制御粒度が粗くスケーラビリティが限られているという問題を抱えており、結果として生成される結果は実用的なアプリケーションの要件を満たさないものとなる。このギャップを埋めるために、Wan-Moveは高精度かつ高品質なモーション制御を実現する。その核となるアイデアは、元の条件付き特徴にモーション認識機能を直接付与し、ビデオ生成を導くことである。
論文リンク:https://go.hyper.ai/h3uaG
2. ビジョナリー: WebGPU 搭載のガウススプラッティング プラットフォーム上に構築された世界モデル キャリア
本稿では、オープンソースでネイティブWeb指向のリアルタイムレンダリングプラットフォームであるVisionaryを提案します。Visionaryは、様々なガウス分布のラスターおよびメッシュタイプのリアルタイムレンダリングをサポートします。高性能WebGPUレンダリングエンジンをベースとし、フレームごとに実行されるONNX推論メカニズムと組み合わせることで、軽量設計と「クリックして実行」できるブラウザエクスペリエンスを維持しながら、動的なニューラル処理機能を実現します。
論文リンク:https://go.hyper.ai/NaBv3
3. ネイティブ並列推論器:自己蒸留強化学習による並列推論
本論文では、大規模言語モデル(LLM)が真の並列推論能力を自律的に進化させることを可能にする教師不要のフレームワーク、Native Parallel Reasoner(NPR)を提案します。8つの推論ベンチマークテストにおいて、Qwen3-4Bモデルで学習されたNPRは、最大24.51 TP3Tの性能向上と、最大4.6倍の推論速度向上を達成しました。
論文リンク:https://go.hyper.ai/KWiZQ
4. TwinFlow: 自己敵対的フローを用いた大規模モデルでのワンステップ生成の実現
本論文では、生成モデル学習フレームワークであるTwinFlowを提案する。この手法は、固定された事前学習済み教師モデルに依存せず、学習中に標準的な敵対的ネットワークの使用を回避するため、大規模かつ高効率な生成モデルの構築に特に適している。テキストから画像への生成タスクにおいて、このフレームワークは1次関数評価(1-NFE)のみでGenEvalスコア0.83を達成し、SANA-Sprint(GAN損失に基づくフレームワーク)やRCGM(一貫性メカニズムに基づくフレームワーク)といった強力なベースラインモデルを大幅に上回る性能を示した。
論文リンク:https://go.hyper.ai/l1nUp
5. 実在を超えて:長文脈LLMのための回転位置埋め込みの虚数拡張
回転位置エンコーディング(RoPE)は、クエリベクトルとキーベクトルを複素平面上で回転させる手法であり、大規模言語モデル(LLM)におけるシーケンス順序のエンコーディングの標準的な手法となっています。しかし、既存の標準実装では、アテンションスコアの計算に複素内積の実部のみを使用し、重要な位相情報を含む虚部は無視されています。そのため、長距離依存関係をモデル化する際に、重要な相対関係の詳細が失われる可能性があります。本論文では、これまで無視されていた虚部情報を再導入する拡張手法を提案します。この手法は、完全な複素表現を最大限に活用して、2成分のアテンションスコアを構築します。
論文リンク:https://go.hyper.ai/iGTw6
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. 200億ドルの賭け!xAIはマスク氏の巨額の資金をOpenAIに賭けているが、その将来の商業的実現可能性は依然として最大の疑問符となっている。
2025年、xAIはマスク氏の強力な推進力の下、かつてないほどの資金調達の勢いを獲得しましたが、その商業化は依然としてXとテスラのエコシステムに大きく依存しており、キャッシュフローと規制圧力が同時に高まっていました。Grokの「弱い連携」アプローチは、ますます厳格化する世界的な規制を背景にますます危険となり、Xとの深い結びつきは独自の成長の可能性を弱めました。コストの不均衡、限られたビジネスモデル、そして規制上の摩擦に直面し、xAIの将来は依然として巨大企業の思惑、政策変更、そしてマスク氏の個人的な意志の間で揺れ動いています。
レポート全体を表示します。https://go.hyper.ai/NmLi4
2. 全議題 | 上海イノベーションラボ、TileAI、Huawei、Advanced Compiler Lab、AI9Stars が上海に集まり、オペレーターの最適化プロセス全体を詳細に分析します。
第8回Meet AI Compilerテクニカルサロンが12月27日に上海イノベーションアカデミーで開催されます。本セッションでは、上海イノベーションアカデミー、TileAIコミュニティ、Huawei HiSilicon、Advanced Compiler Lab、AI9Starsコミュニティの専門家が参加し、ソフトウェアスタック設計、オペレータ開発、パフォーマンス最適化に至るまで、テクノロジーチェーン全体にわたる知見を共有します。トピックには、TVMのクロスエコシステム相互運用性、PyPTOのフュージョンオペレータの最適化、TileRTによる低レイテンシシステム、複数のアーキテクチャにわたるTritonの主要な最適化手法、AutoTritonのオペレータ最適化などがあり、理論から実装までの包括的な技術パスを紹介します。
レポート全体を表示します。https://go.hyper.ai/xpwkk
3. オンラインチュートリアル | SAM 3 は、2 倍のパフォーマンス向上によりヒント付きコンセプトセグメンテーションを実現し、100 個の検出オブジェクトを 30 ミリ秒で処理します
SAMおよびSAM 2モデルは画像セグメンテーションにおいて大きな進歩を遂げましたが、入力コンテンツ内に存在する概念のインスタンスをすべて自動的に検出し、セグメンテーションすることは依然として困難でした。このギャップを埋めるため、Metaは最新バージョンであるSAM 3をリリースしました。この新バージョンは、手がかりとなる視覚セグメンテーション(PVS)において前バージョンのパフォーマンスを大幅に上回るだけでなく、手がかりとなる概念セグメンテーション(PCS)タスクにおいても新たな基準を確立しました。
レポート全体を表示します。https://go.hyper.ai/YfmLc
4. カーネギーの学際的なチームは、406 個のサンプルに基づくランダム フォレスト モデルを使用して、33 億年前の生命の痕跡を捉えることに成功しました。
米国のカーネギー科学研究所は、世界中の複数の大学と連携して、熱分解ガスクロマトグラフィー質量分析と教師あり機械学習を組み合わせた「技術融合」ソリューションを改良するための学際的なチームを結成し、混沌とした分子断片の中に古代の生命の痕跡を捉えることができるようになりました。
レポート全体を表示します。https://go.hyper.ai/CNPMQ
5. イベント概要 | 北京大学、清華大学、Zilliz、MoonBitがオープンソースについて議論。ビデオ生成、画像理解、ベクターデータベース、AIネイティブプログラミング言語などについて解説
HyperAIは、COSCon'25の共催コミュニティとして、12月7日に「産業界と研究機関のオープンソースコラボレーションフォーラム」を主催しました。この記事は、4名の講演者による詳細なプレゼンテーションの要点をまとめたものです。プレゼンテーションの全編は後日、動画でも公開予定ですので、どうぞお楽しみに!
レポート全体を表示します。https://go.hyper.ai/XrCEl
人気のある百科事典の項目を厳選
1. 双方向長短期記憶(Bi-LSTM)
2. グラウンドトゥルース
3. レイアウト制御(レイアウトから画像へ)
4. 具現化されたナビゲーション
5. 1秒あたりのフレーム数(FPS)
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
1月の締め切り会議

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1800以上の公開データセットの国内高速ダウンロードノードを提供
* 600以上の古典的で人気のあるオンラインチュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 600 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








