Command Palette
Search for a command to run...
AI推論の解明:OpenAIのスパースモデルが初めてニューラルネットワークを透明化;消費カロリー予測:フィットネスモデルに正確なエネルギーデータを注入

リン・ジアミンによるオリジナル記事 HyperAI スーパーニューラル2026年1月14日 17時06分北京
近年、大規模言語モデルの機能は急速に向上していますが、その内部の意思決定プロセスは依然として複雑に絡み合った「ブラックボックス」であり、追跡や理解が困難です。この根本的な問題は、医療や金融といった高リスク分野におけるAIの確実な応用を著しく阻害しています。モデルの思考プロセスを透明かつ追跡可能にする方法は、依然として重要な未解決の問題です。
これに基づいて、OpenAIは2025年12月に0.4億パラメータの大規模言語モデルであるCircuit Sparsityをリリースしました。これは、回路スパース技術を使用して99.9%の重みをゼロにリセットし、解釈可能なスパース計算アーキテクチャを構築します。このモデルは、従来のTransformerの「ブラックボックス」的な意思決定の限界を打ち破り、AI推論プロセスを層ごとに分析することを可能にします。その核心は、独自の学習手法によって、従来の高密度ニューラルネットワークを構造化された疎な「回路」に変換することです。
*動的強制スパース性従来の方法とは異なり、トレーニングの各ステップで「動的プルーニング」を実行し、各ラウンドで絶対値が最大 (0.1% など) の非常に少数の重みのみを保持し、残りを強制的にゼロにすることで、モデルが最初から最小限の接続性で動作するように学習するように強制します。
*スパース性を有効にする注意機構などの重要な場所に活性化関数を導入することで、ニューロンの出力は「どちらか一方」の離散状態になりやすく、それによって疎ネットワーク内に明確な情報チャネルが形成されます。
*カスタマイズされたコンポーネントスパース性の破壊を防ぐために、LayerNorm の代わりに RMSnorm が使用されています。また、単純な単語予測を処理するために Bigram ルックアップ テーブルが導入されており、メイン ネットワークが複雑なロジックにさらに集中できるようになります。
上記の方法を用いて学習されたモデルは、機能的に定義され、解決可能な「回路」を自発的に形成します。各回路は特定のサブタスクを担当します。研究者は、一部のニューロンが「シングルクォート」の検出に特化して使用され、他のニューロンが論理的な「カウンター」として機能することを明確に特定できます。従来の高密度モデルと比較して、同じタスクを完了するために必要なアクティブノードの数が大幅に削減されます。これに付随する「ブリッジ ネットワーク」テクノロジは、スパース回路から得られた解釈を GPT-4 などの高性能な高密度モデルにマッピングし直すことを試みるとともに、既存の大規模モデルを分析するための潜在的なツールも提供します。
HyperAI の Web サイトには現在、「Circuit Sparsity: OpenAI の新しいオープン ソース スパース モデル」が掲載されていますので、ぜひお試しください。
オンラインでの使用:https://go.hyper.ai/WgLQc
1 月 5 日から 1 月 9 日までの hyper.ai ウェブサイトの更新の概要は次のとおりです。
* 高品質の公開データセット: 8
* 厳選された高品質のチュートリアル:4
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
※1月提出締切:9日
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. MCIFマルチモーダルクロスランゲージ指導データセット
MCIFは、科学音声に基づく多言語、マルチモーダル、手作業で注釈が付けられた評価データセットで、2025年にFondazione Bruno Kesslerがカールスルーエ工科大学およびTranslatedと共同で公開しました。このデータセットは、マルチモーダル大規模言語モデルが言語横断的なシナリオにおける指示を理解し実行する能力、および推論のために音声、視覚情報、テキスト情報を統合する能力を評価することを目的としています。
直接使用します:https://go.hyper.ai/SyUiL
2. TxT360-3efforts マルチタスク推論データセット
TxT360-3effortsは、モハメド・ビン・ザイード人工知能大学が2025年にリリースした、教師あり微調整(SFT)用の非常に大規模な言語モデルトレーニングデータセットです。チャットテンプレートを通じてモデルの3つの推論強度を制御するように設計されています。
直接使用します:https://go.hyper.ai/fMEbf
3. X線密輸品検出データセット
X線禁制品検出データセットは、華南師範大学が香港理工大学およびサスカチュワン大学と共同で2025年に公開したデータセットです。このデータセットは、複雑で混雑したセキュリティ画像における検出モデルの検出能力を向上させることを目的としており、特にクラスの不均衡やサンプルの不足といった現実世界の問題に対処することを目的としています。
直接使用します:https://go.hyper.ai/ppXub
4. MCD-rPPGマルチカメラ遠隔光電式容積脈波記録データセット
MCD-rPPGは、2025年にSber AI Labによってリリースされたマルチカメラビデオデータセットです。このデータセットは、さまざまな州の600人の被験者が撮影した同期ビデオと生体信号データで構成されており、遠隔光電式容積脈波記録法(rPPG)と健康バイオマーカーの推定を実行するように設計されています。
直接使用します:https://go.hyper.ai/6KY40
5. LongBench-Pro Long Context 包括的評価データセット
LongBench-Pro は、長いコンテキストの言語モデルを評価するためのデータセットであり、さまざまなコンテキストの長さ、タスクの種類、実行条件下で長いテキストを理解して処理するモデルの能力を体系的に評価するように設計されています。
直接使用します:https://go.hyper.ai/7esQI
6. 人間の顔データセット
Human Facesは、顔に関連するコンピュータービジョンタスク向けに2025年にリリースされたデータセットです。顔認識、検出、表情分析、生成モデリングなどのアプリケーション向けに、高品質で構造化された画像データのサポートを提供することを目的としています。
直接使用します:https://go.hyper.ai/9WlDl

7. 消費カロリー予測データセット
Calories Burnt Predictionは、運動エネルギー消費量を予測するための教師あり学習データセットです。個人の生理学的特性と運動状況情報を用いて、運動中の消費カロリー数を予測することを目的としています。
直接使用します:https://go.hyper.ai/o6X59
8. MapTrace パストレーシング データセット
MapTraceは、Googleがペンシルベニア大学と共同で2025年に公開した大規模な合成地図パストレーシングデータセットです。このデータセットは、地図シーンにおけるマルチモーダル大規模言語モデル(MLLM)のきめ細かな空間推論とパスプランニング機能の向上を目指しています。主な目的は、出発地から目的地までのピクセル精度で連続的かつ歩行可能なパスを生成するモデルをトレーニングすることです。
直接使用します:https://go.hyper.ai/BGHUu
選択された公開チュートリアル
1. 回路スパース性: OpenAIの新しいオープンソーススパースモデル
Circuit-sparsityは、OpenAIが公開した0.4億パラメータの大規模言語モデルです。Circuit-sparsity技術を採用し、99.9%の重みをゼロにリセットすることで、解釈可能なスパース計算アーキテクチャを構築します。これにより、従来のTransformerの「ブラックボックス」的な意思決定の限界が打破され、AI推論を層ごとに分析することが可能になります。本モデルに同梱されているStreamlitツールキットは「アクティベーションブリッジ」技術を提供し、研究者は内部信号経路をトレースし、対応する回路を分析し、スパースモデルと密なモデルのパフォーマンスの違いを比較することができます。
オンラインで実行:https://go.hyper.ai/zui8w
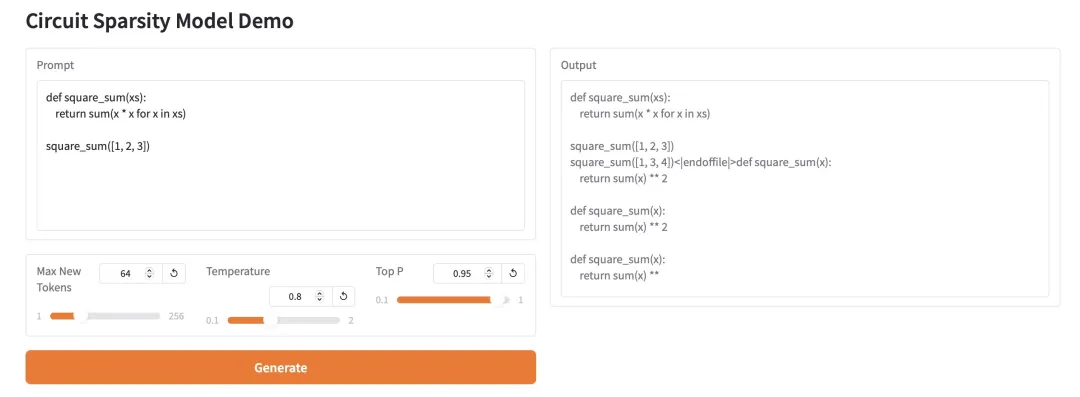
2. HY-MT1.5-1.8B: 多言語ニューラル機械翻訳モデル
HY-MT1.5-1.8Bは、テンセントのHunyuanチームがリリースした18億パラメータの多言語機械翻訳モデルです。統合Transformerアーキテクチャを基盤とし、33言語と5つの民族言語・方言間の相互翻訳をサポートし、混在言語や用語管理といった現実世界のシナリオに最適化されています。7Bモデルに近い翻訳品質を実現しながらも、パラメータ数は3分の1に抑えられており、HuggingFaceエコシステムへの定量的な展開と統合をサポートし、効率的で低コストのオンライン多言語翻訳サービスに適しています。
オンラインで実行:https://go.hyper.ai/I0pdR
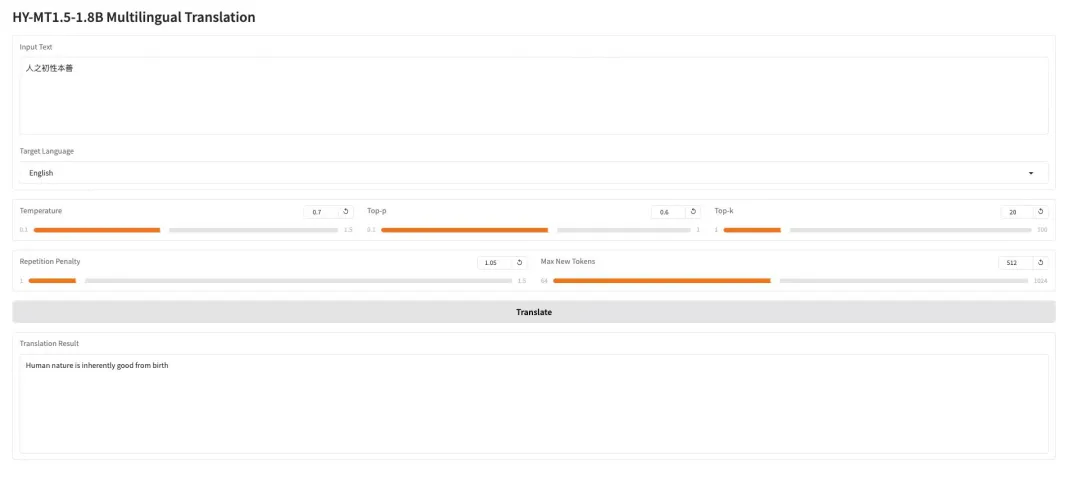
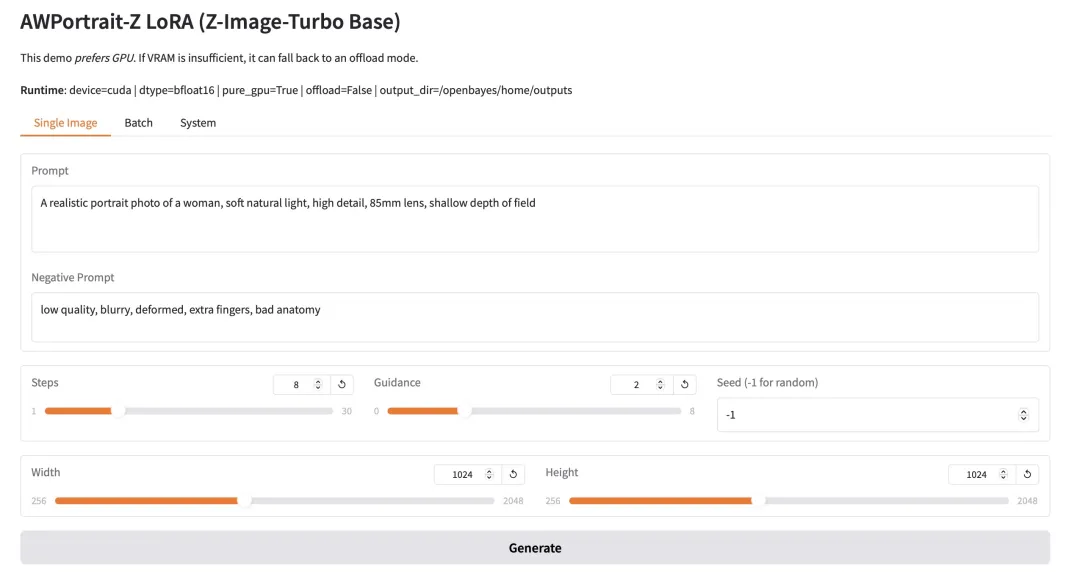
3. AWPortrait-Z ポートレートアート LoRA
AWPortrait-Zは、LoRA技術をベースとしたポートレート補正モデルです。プラグインとして、主流のテキストベースの画像拡散モデルと統合することで、ベースモデルの再学習を必要とせずに、生成されるポートレートのリアリティと写真品質を大幅に向上させます。このモデルは、顔の構造、肌の質感、照明のレンダリングを特に最適化することで、より自然で洗練された効果を生み出し、写真のようなリアリティが求められるポートレート作成や画像合成に適しています。
オンラインで実行:https://go.hyper.ai/wRjIp
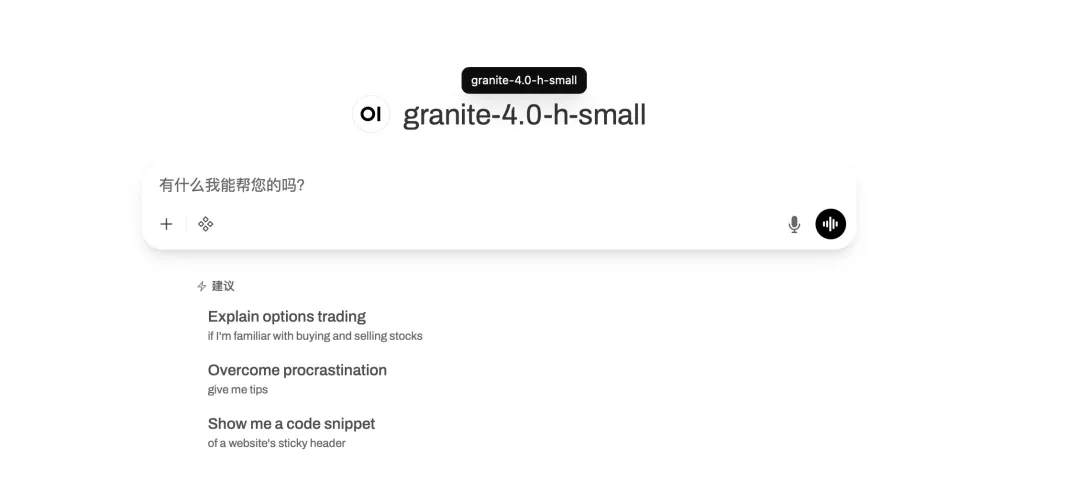
4. Granite-4.0-h-small: 多言語の対話とコーディングタスクのためのワンストッププラットフォーム。
Granite-4.0-h-smallは、IBMがリリースした32億パラメータのロングコンテキスト命令ファインチューニングモデルです。ベースモデルをベースとし、オープンソースデータと合成データを統合し、教師ありファインチューニング、強化学習アライメント、モデルマージ技術を採用しています。優れた命令コンプライアンスとツール呼び出し機能を誇り、構造化対話形式を採用し、高効率なエンタープライズレベルのアプリケーション向けに最適化されています。
オンラインで実行:https://go.hyper.ai/1HhB9
今週のおすすめ紙
1. mHC: 多様体制約超接続
本論文では、多様体制約ハイパーコネクション(mHC)を提案する。これは、HCの残余接続空間を特定の多様体に射影することでHCの恒等写像性を復元する汎用フレームワークであり、厳密なインフラストラクチャ最適化によって計算効率を確保する。実験結果では、mHCは大規模学習において非常に優れた性能を示し、目に見えるパフォーマンス向上だけでなく、優れたスケーラビリティも実現する。HCの柔軟かつ実用的な拡張として、mHCはトポロジー設計のより深い理解に貢献し、基本モデルの進化に有望な新たな方向性をもたらすと期待される。
論文リンク:https://go.hyper.ai/ZePnH
2. Youtu-LLM: 軽量大規模言語モデルにおけるネイティブインテリジェントエージェントの潜在能力を引き出す
著者らは、Youtu-LLMチームが開発した19億6000万パラメータの軽量言語モデル、Youtu-LLMを提案する。「常識STEMエージェント」原理のカリキュラムを用いてゼロから事前学習することで、20億パラメータ未満のモデルの中で最先端の性能を達成した。このモデルは、コンパクトなマルチレイテンシーアテンションアーキテクチャ、STEM指向のトークナイザー、そしてスケーラブルなパイプラインを統合し、数学、プログラミング、ディープリサーチ、ツール使用といった分野における高品質なエージェント軌跡データを生成する。これにより、モデルはネイティブな計画、リフレクション、アクション能力を内在化することができ、強力な一般推論能力と長期文脈性能力を維持しながら、エージェントベンチマークにおいて大規模なモデルを大幅に上回る性能を発揮する。
論文リンク:https://go.hyper.ai/gitUc
3. Youtu-LLM: 軽量大規模言語モデルにおけるネイティブインテリジェントエージェントの潜在能力を引き出す
本稿ではまず、記憶の定義と機能を、認知神経科学から大規模言語モデル、そして知的エージェントへと進化してきた過程を辿りながら明らかにする。次に、記憶の分類システム、記憶機構、そして記憶管理ライフサイクル全体を、生物学的および人工的な観点から比較・分析する。その上で、現在主流となっている知的エージェントの記憶評価ベンチマークを体系的にレビューする。さらに、本稿では、攻撃と防御の両面から、記憶システムのセキュリティ問題を考察する。最後に、マルチモーダル記憶システムとスキル獲得メカニズムの構築に焦点を当て、今後の研究の方向性を展望する。
論文リンク:https://go.hyper.ai/01H6H
4. 思考を流す: ロック ミュージックのコンテキストでインテリジェント エージェントを構築し、オープン インテリジェント エージェント学習エコシステム内で ROME モデルを作成する。
著者らは、Agenetic Learning Ecosystem(ALE)に基づくオープンソースのエージェントモデルであるROMEを提案する。このフレームワークは、ROCKのサンドボックスオーケストレーション、ROLLの学習後最適化、そしてiFlow CLIのコンテキストアウェアなエージェント実行を統合している。ROMEは、独自のポリシー最適化アルゴリズム(IPA)を用いてセマンティックインタラクションブロックにクレジットを割り当てることで、Terminal-Bench 2.0およびSWE-bench Verifiedにおいて最先端のパフォーマンスを実現する。また、実世界への導入をサポートすることで、スケーラブルでセキュア、かつ実運用可能なエージェントワークフローを構築できる。
論文リンク:https://go.hyper.ai/UaAXZ
5. IQuest-Coder-V1 技術レポート
本論文では、大規模言語モデル(LLM)の新しいファミリーであるIQuest-Coder-V1シリーズ(7B/14B/40B/40Bループ)を提案します。従来の静的コード表現とは異なり、コードフローに基づく多段階学習パラダイムを提案し、パイプラインの様々な段階におけるソフトウェアロジックの進化を動的に捉えます。このモデルは、進化的学習パイプラインを通じて構築されます。IQuest-Coder-V1シリーズのリリースは、自律コードインテリジェンスと実世界におけるインテリジェントエージェントシステムの研究を大きく前進させるでしょう。
論文リンク:https://go.hyper.ai/DBYN7
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. NVIDIA 社などは、18,000 年分の気候データを生成し、単一ステップの計算で長期天気予報を可能にする長距離蒸留を提案しました。
NVIDIA Researchの研究チームは、ワシントン大学と共同で、長期予測のための新たな手法を発表しました。その核となるアイデアは、リアルな大気変動の生成に優れた自己回帰モデルを「教師」として用い、低コストで迅速なシミュレーションを通じて大量の合成気象データを生成するというものです。このデータを用いて、確率的な「生徒」モデルを学習させます。生徒モデルは、反復誤差の蓄積を回避し、複雑なデータキャリブレーションの課題を回避しながら、1ステップの計算で長期予測を生成します。予備実験では、この方法で学習された生徒モデルは、S2S予測においてECMWF統合予測システムと同等の性能を示しており、合成データ量の増加に伴い性能は向上し続けており、将来的にはより信頼性が高く経済的な気候規模の予測が可能になると期待されます。
レポート全体を表示します。https://go.hyper.ai/Ljebq
2. ジェンセン・フアンの最新講演:5つのイノベーション、初めて公開されたRubinのパフォーマンスデータ、エージェント/ロボット/自動運転/AI4Sをカバーする多様なオープンソース
新年早々、米国ラスベガスで「テック・スプリング・フェスティバル・ガラ」とも呼ばれるCES 2026(コンシューマー・エレクトロニクス・ショー)が開幕しました。ジェンセン・フアン氏はCESの公式基調講演リストには名を連ねていませんでしたが、様々なイベントに出演し、精力的に活動していました。中でも特に注目すべきは、NVIDIA LIVEでの自身のプレゼンテーションでした。先日終了したプレゼンテーションで、トレードマークの黒いレザージャケットを身にまとったフアン氏は、5つのイノベーションを統合したRubinプラットフォームの詳細を紹介し、オープンソースの成果をいくつか公開しました。具体的には、エージェントAI向けのNVIDIA Nemotronシリーズ、フィジカルAI向けのNVIDIA Cosmosプラットフォーム、自動運転研究向けのNVIDIA Alpamayoシリーズ、ロボティクス向けのNVIDIA Isaac GR00T、そしてバイオメディカル分野向けのNVIDIA Claraです。
レポート全体を表示します。https://go.hyper.ai/YMK1J
3. ベゾス、ビル・ゲイツ、NVIDIA、インテルなどが賭けに出ている。NASAのエンジニアが率いるチームでは汎用ロボット脳を開発しており、同社の評価額は20億ドルに上る。
大規模モデルはインターネット、画像ライブラリ、膨大なテキストから「無限に成長」できる一方、ロボットは別の世界に閉じ込められています。現実世界のデータは非常に希少で、高価で、再利用不可能です。物理世界におけるデータ規模の不足と構造の限界という制約に対処するため、FieldAIは、主流の知覚優先戦略とは異なるアプローチを選択しました。FieldAIは、物理的制約を中心とした汎用ロボット知能システムをゼロから構築し、現実世界環境におけるロボットの汎化能力と自律性の向上を目指しています。
レポート全体を表示します。https://go.hyper.ai/9T1rE
4. フルリプレイ | 上海Chuangzhi/TileAI/Huawei/Advanced Compiler Lab/AI9Stars AIコンパイラ技術実践の深掘り
AIコンパイラ技術は絶え間なく進化を続け、数々の探求が行われ、知見が蓄積され、収束しています。こうした背景の下、12月27日に第8回Meet AI Compilerが開催されました。このセッションでは、上海イノベーションアカデミー、TileAI Community、Huawei HiSilicon、Advanced Compiler Lab、AI9Starsから5名の専門家が招かれ、ソフトウェアスタック設計、オペレーター開発、パフォーマンス最適化に至るまで、テクノロジーチェーン全体にわたる知見を共有しました。講演者は、各チームの長年の研究成果に基づき、様々な技術的アプローチの実装方法とトレードオフを実際のシナリオで実演し、抽象的な概念をより具体的な基盤へと導きました。
レポート全体を表示します。https://go.hyper.ai/8ytqF
5. 高度に選択的な基質設計の実現: MIT とハーバード大学は、生成 AI を使用して新しいプロテアーゼ切断パターンを発見しました。
MIT とハーバード大学は共同で、予測モデルと生成モデルを連携させてプロテアーゼ基質設計の既存のパラダイムに革命を起こし、関連する基礎研究と生物医学開発にまったく新しいソリューションを提供することを目的とした AI ベースのエンドツーエンドの設計プロセスである CleaveNet を提案しました。
レポート全体を表示します。https://go.hyper.ai/tcYYZ
人気のある百科事典の項目を厳選
1. ヒューマンマシンループ(HITL)
2. 超相互ソート融合RRF
3. 具現化されたナビゲーション
4. 多層パーセプトロン
5. 強化の微調整
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
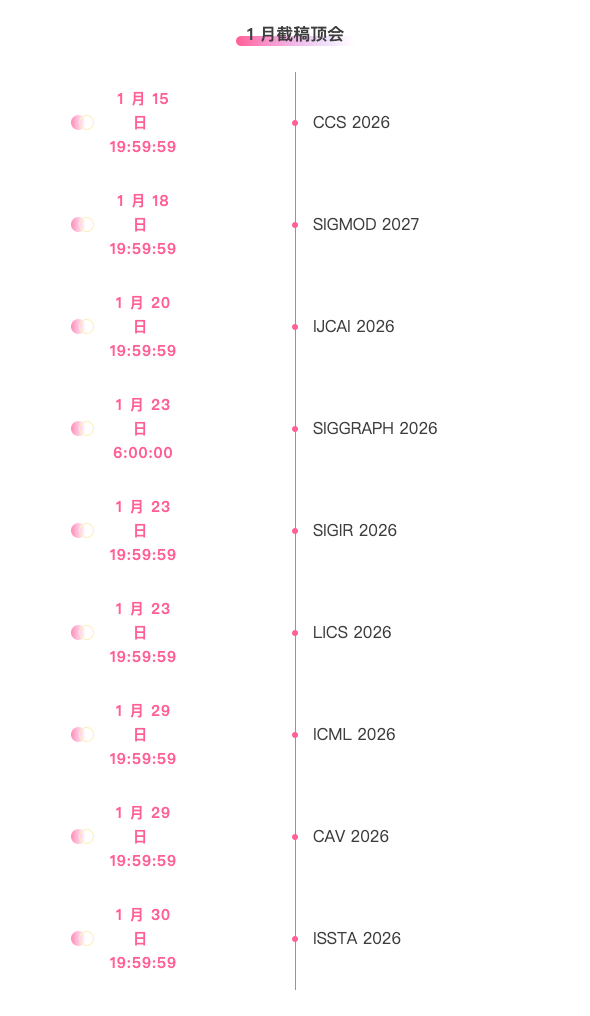
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








