HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

Mise à l'échelle du pré-entraînement vidéo par mélange d'experts pour l'intelligence incarnée

LAME M-VLA : MÉMOIRE LATENTE DOUBLE DANS LES MODÈLES VISION-LANGAGE-ACTION POUR LA MANIPULATION ROBOTIQUE



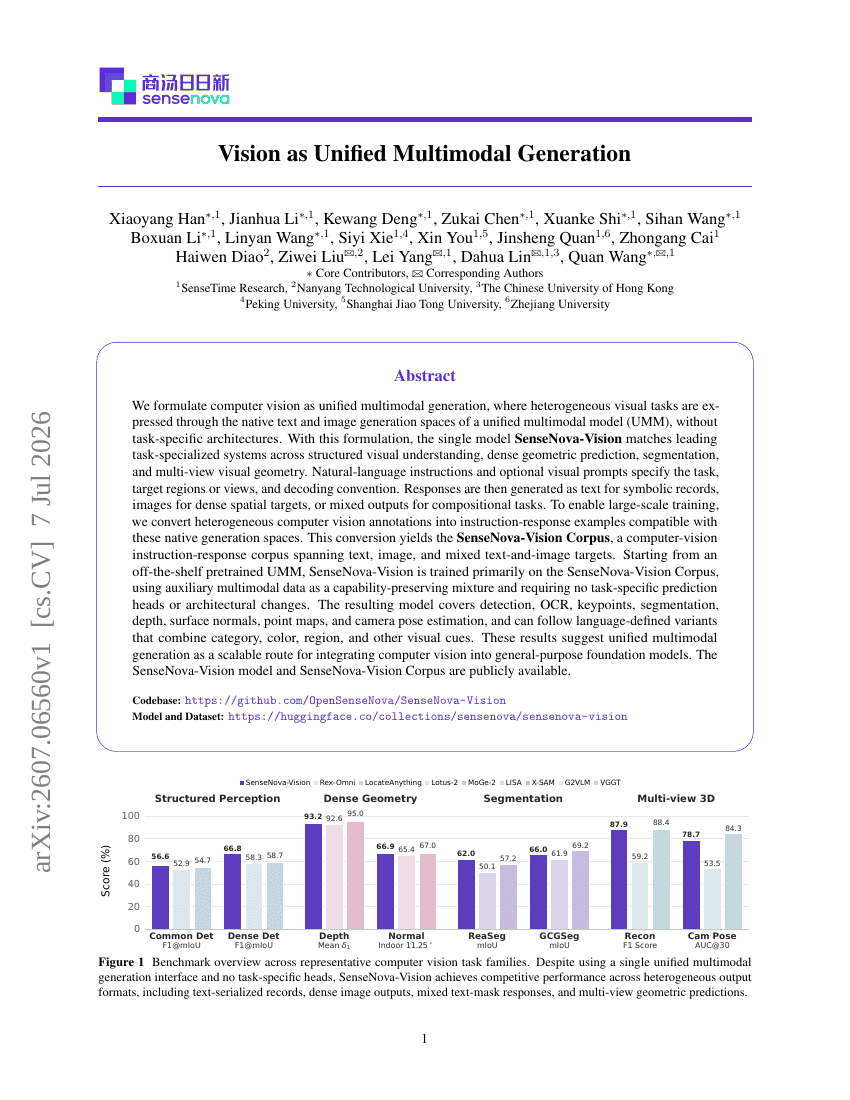
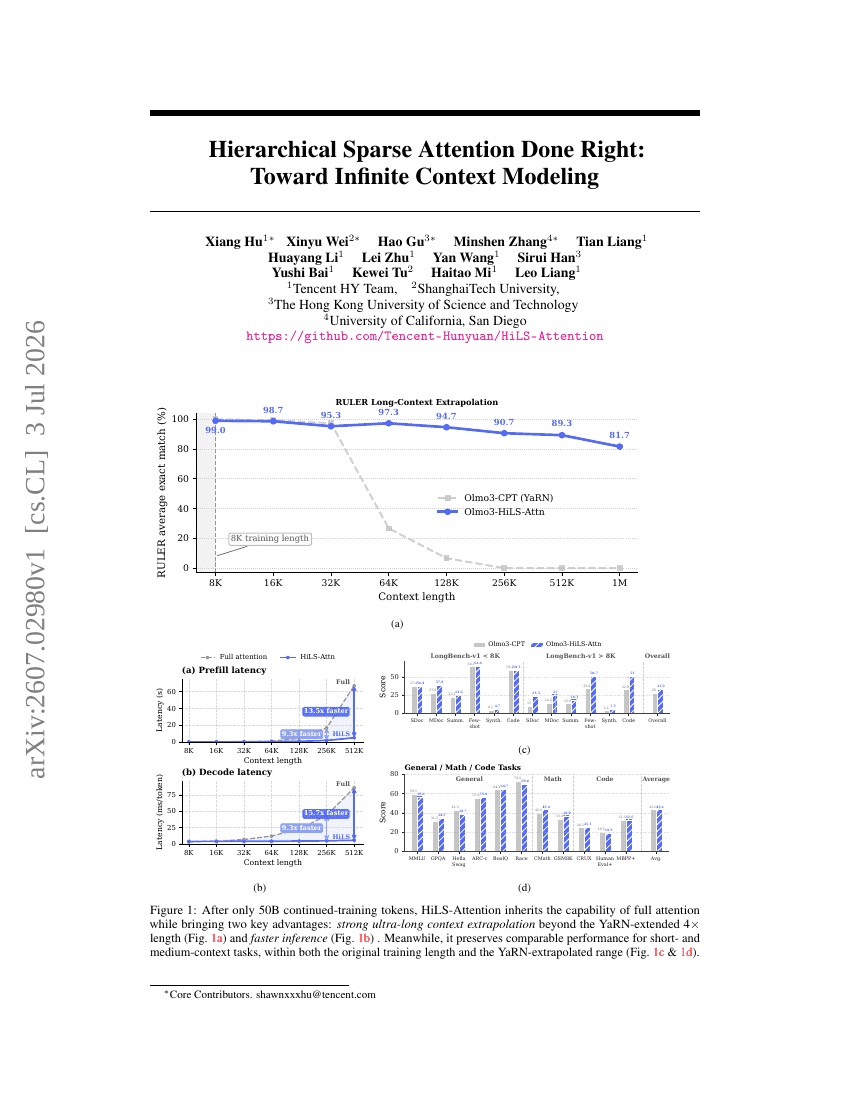



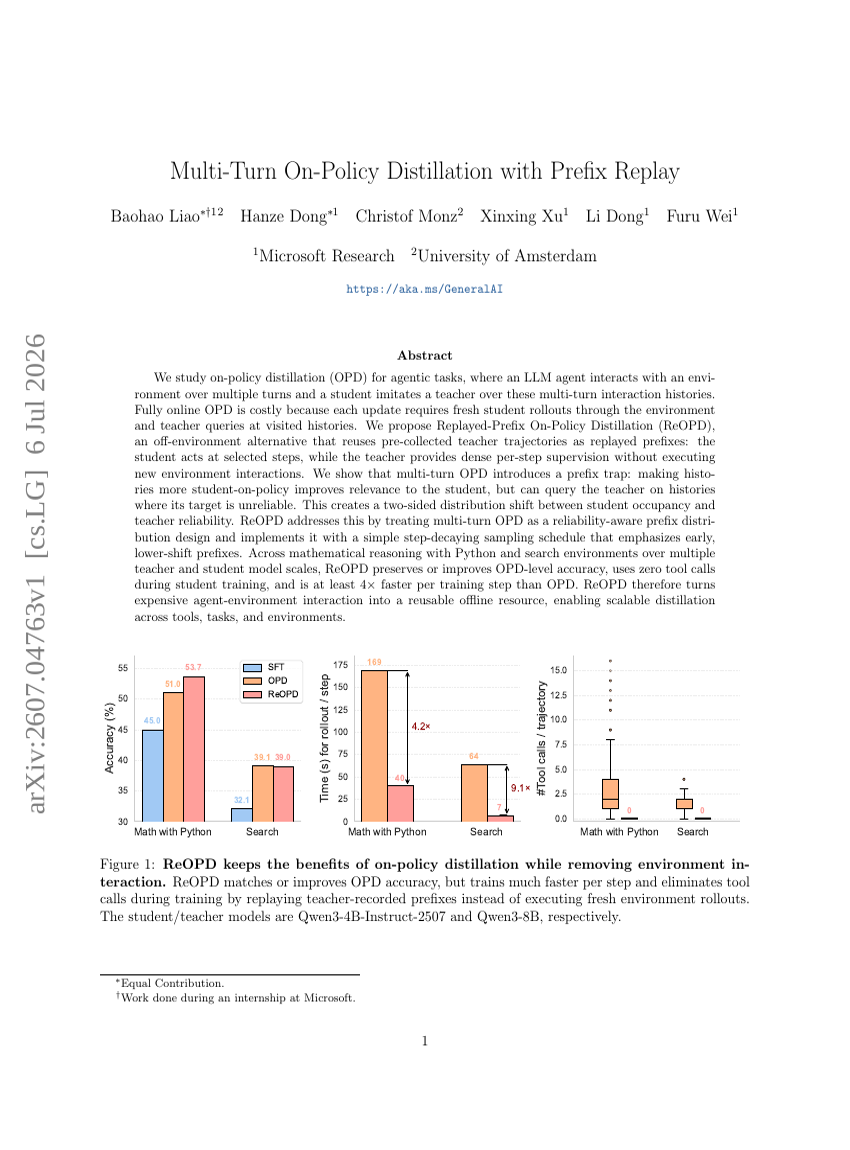





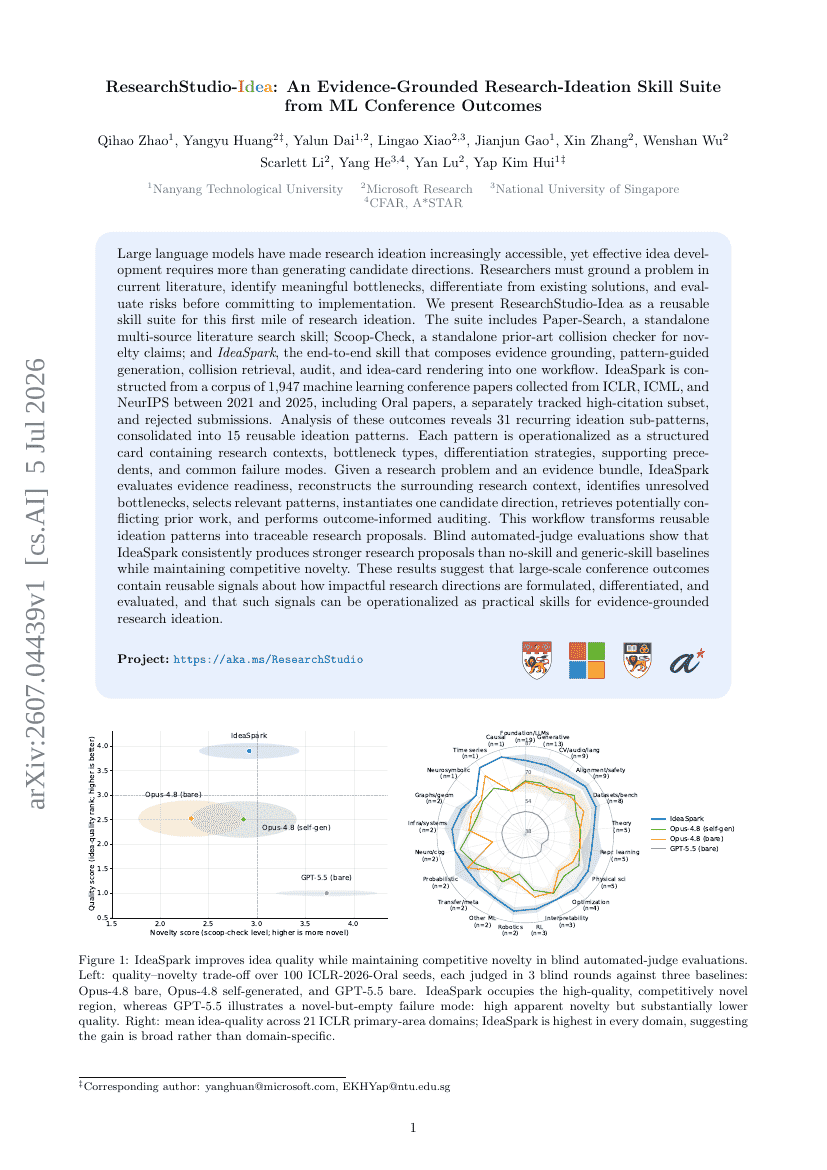














Mise à l'échelle du pré-entraînement vidéo par mélange d'experts pour l'intelligence incarnée
LAME M-VLA : MÉMOIRE LATENTE DOUBLE DANS LES MODÈLES VISION-LANGAGE-ACTION POUR LA MANIPULATION ROBOTIQUE
Compréhension précise, interdisciplinaire et transparente des relations structure-propriété grâce au raisonnement structurel natif profond
Décodage autorégressif parallélisé pour le sous-titrage dense de vidéos omni-modales
Light-Omni : Réflexe plutôt que raisonnement dans la compréhension vidéo agentique avec mémoire à long terme
La vision comme génération multimodale unifiée
Attention Hiérarchique Éparse Bien Faite : Vers une Modélisation de Contexte Infini
AlayaWorld : Génération de mondes vidéo jouables à long horizon
RynnWorld-4D : Modèles du monde incarnés en 4D pour la manipulation robotique
Nemotron-Labs-3-Puzzle-75B-A9B : Compression des LLMs hybrides à mélange d'experts
Distillation sur politique multi-tours avec rejeu de préfixes
Rapport technique Gemma 4
UI-MOPD : Distillation multi-plateforme on-policy pour l’apprentissage continu d’agents d’interface graphique
Wan-Streamer v0.2 : Résolution Supérieure, Même Latence
EVA-Client : un cadre unifié pour le déploiement, l'évaluation et la collecte de données sur des robots réels
GigaWorld-1 : Une feuille de route pour construire des modèles du monde pour l'évaluation de politiques robotiques
ResearchStudio-Idea : Une suite de compétences pour l'idéation de recherche fondée sur des preuves à partir des résultats de conférences en apprentissage automatique
ResearchStudio-Reel : Automatiser le dernier kilomètre de la recherche, de l'article à l'affiche, la vidéo et le blog
FINAL Bench : Mesurer le raisonnement métacognitif fonctionnel dans les grands modèles de langage
SceneFun3D : Compréhension fine des fonctionnalités et des affordances dans les scènes 3D
TheoremGraph : relier les mathématiques formelles et informelles
Agents perpétuellement actifs : un état de l’art sur la mémoire persistante, l’état et la gouvernance dans les agents LLM
Sécuriser l’agent IA : un cadre unifié pour l’évaluation offensive multi-couche des agents
DataComp-VLM : Jeux de données ouverts améliorés pour les modèles vision-langage
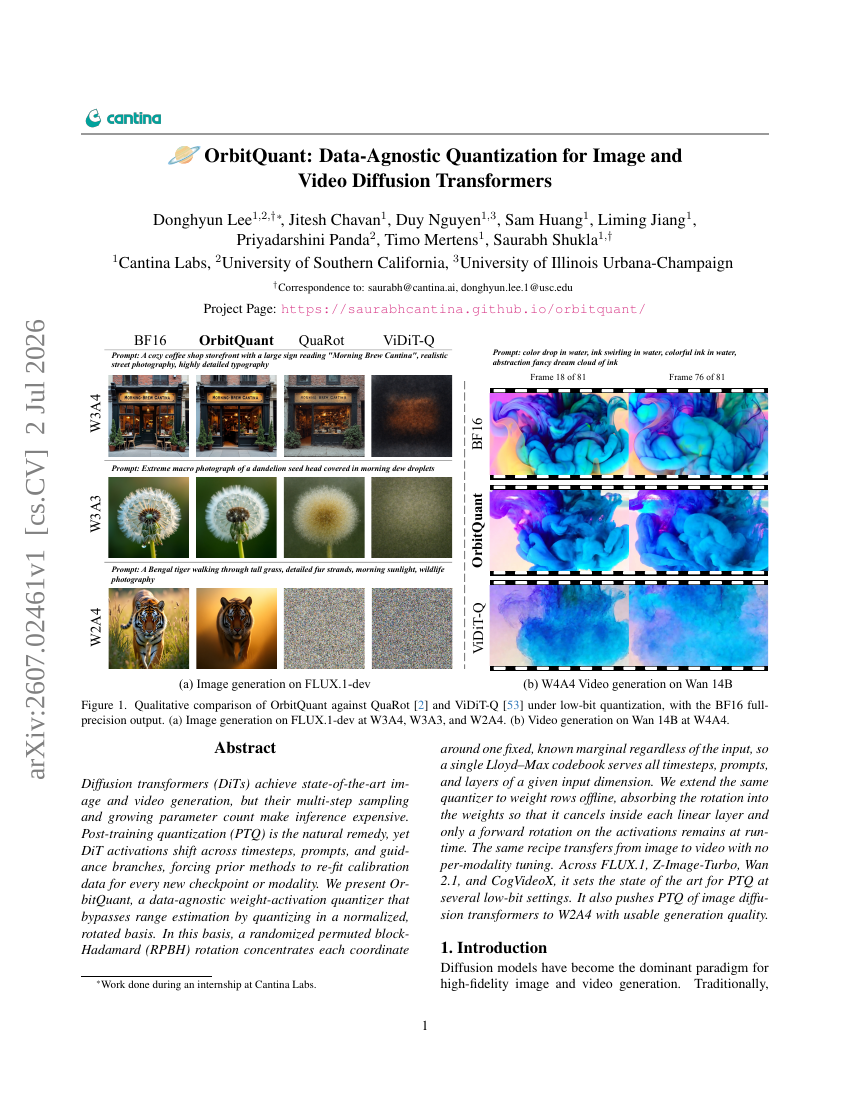
OrbitQuant : Quantification indépendante des données pour les transformeurs de diffusion d’images et de vidéos
VLA-Corrector : Inférence légère de détection et correction pour un horizon d’action adaptatif
Embodied.cpp : un moteur d'exécution portable pour modèles d'IA incarnée sur des robots hétérogènes
Le mirage de l’optimisation des politiques d’entraînement : les politiques d’inférence monotones comme véritable objectif pour l’apprentissage par renforcement des grands modèles de langage
GeneBench-Pro : Évaluation du raisonnement statistique multi-étapes en génomique, biologie quantitative et biomédecine translationnelle
Position : La recherche sur les deepfakes en IA/ML est mal alignée avec l’imagerie intime non consensuelle générée par IA (AIG-NCII)
Comprendre le grokking : Preuves de grokking en régression ridge
Une perspective de théorie des matrices aléatoires sur la cohérence des modèles de diffusion
Compréhension précise, interdisciplinaire et transparente des relations structure-propriété grâce au raisonnement structurel natif profond
Décodage autorégressif parallélisé pour le sous-titrage dense de vidéos omni-modales
Light-Omni : Réflexe plutôt que raisonnement dans la compréhension vidéo agentique avec mémoire à long terme
La vision comme génération multimodale unifiée
Attention Hiérarchique Éparse Bien Faite : Vers une Modélisation de Contexte Infini
AlayaWorld : Génération de mondes vidéo jouables à long horizon
RynnWorld-4D : Modèles du monde incarnés en 4D pour la manipulation robotique
Nemotron-Labs-3-Puzzle-75B-A9B : Compression des LLMs hybrides à mélange d'experts
Distillation sur politique multi-tours avec rejeu de préfixes
Rapport technique Gemma 4
UI-MOPD : Distillation multi-plateforme on-policy pour l’apprentissage continu d’agents d’interface graphique
Wan-Streamer v0.2 : Résolution Supérieure, Même Latence
EVA-Client : un cadre unifié pour le déploiement, l'évaluation et la collecte de données sur des robots réels
GigaWorld-1 : Une feuille de route pour construire des modèles du monde pour l'évaluation de politiques robotiques
ResearchStudio-Idea : Une suite de compétences pour l'idéation de recherche fondée sur des preuves à partir des résultats de conférences en apprentissage automatique
ResearchStudio-Reel : Automatiser le dernier kilomètre de la recherche, de l'article à l'affiche, la vidéo et le blog
FINAL Bench : Mesurer le raisonnement métacognitif fonctionnel dans les grands modèles de langage
SceneFun3D : Compréhension fine des fonctionnalités et des affordances dans les scènes 3D
TheoremGraph : relier les mathématiques formelles et informelles
Agents perpétuellement actifs : un état de l’art sur la mémoire persistante, l’état et la gouvernance dans les agents LLM
Sécuriser l’agent IA : un cadre unifié pour l’évaluation offensive multi-couche des agents
DataComp-VLM : Jeux de données ouverts améliorés pour les modèles vision-langage
OrbitQuant : Quantification indépendante des données pour les transformeurs de diffusion d’images et de vidéos
VLA-Corrector : Inférence légère de détection et correction pour un horizon d’action adaptatif
Embodied.cpp : un moteur d'exécution portable pour modèles d'IA incarnée sur des robots hétérogènes
Le mirage de l’optimisation des politiques d’entraînement : les politiques d’inférence monotones comme véritable objectif pour l’apprentissage par renforcement des grands modèles de langage
GeneBench-Pro : Évaluation du raisonnement statistique multi-étapes en génomique, biologie quantitative et biomédecine translationnelle
Position : La recherche sur les deepfakes en IA/ML est mal alignée avec l’imagerie intime non consensuelle générée par IA (AIG-NCII)
Comprendre le grokking : Preuves de grokking en régression ridge
Une perspective de théorie des matrices aléatoires sur la cohérence des modèles de diffusion