Command Palette
Search for a command to run...
DexJoCo : une plateforme d'évaluation et une boîte à outils pour la manipulation déxtere orientée tâche sur MuJoCo
DexJoCo : une plateforme d'évaluation et une boîte à outils pour la manipulation déxtere orientée tâche sur MuJoCo
Résumé
Atteindre une dextérité de niveau humain nécessite des mains robotiques capables d’interactions complexes avec les objets. Pour faire progresser davantage ces capacités, il est indispensable de disposer de benchmarks standardisés permettant une évaluation systématique. Toutefois, les benchmarks existants dédiés à la manipulation délicate manquent de tâches reflétant les capacités spécifiques des mains déplexes par rapport aux pinces parallèles, ainsi que de pipelines d’évaluation complets. Dans cet article, nous présentons DexJoCo, un benchmark et une boîte à outils pour la manipulation délicate orientée vers les tâches, comprenant 11 tâches ancrées fonctionnellement qui évaluent l’utilisation d’outils, la coordination bimanuelle, l’exécution sur de longues durées et le raisonnement. Nous avons développé un système de collecte de données à faible coût et recueilli 1,1 K trajectoires sur ces tâches, avec prise en charge de la randomisation de domaine afin d’évaluer la robustesse. Nous évaluons des modèles modernes dans divers contextes, incluant la randomisation visuelle et dynamique, l’entraînement multi-tâches et l’adaptation de la tête d’action. Grâce à une analyse empirique approfondie, nous identifions plusieurs insights importants et les limites courantes des politiques actuelles en matière de manipulation délicate, mettant en lumière les défis clés pour la recherche future dans l’apprentissage robotique des mains déplexes. La page du projet est disponible à l’adresse : https://dexjoco.github.io
One-sentence Summary
DexJoCo is a benchmark and toolkit for task-oriented dexterous manipulation on MuJoCo that introduces eleven functionally grounded tasks evaluating tool-use, bimanual coordination, long-horizon execution, and reasoning, integrates a low-cost data collection system yielding 1.1K trajectories with domain randomization, and systematically benchmarks modern policies under diverse settings including visual and dynamics randomization, multi-task training, and action-head adaptation to expose current limitations and guide future research.
Key Contributions
- This work introduces DexJoCo, a benchmark and toolkit comprising 11 functionally grounded tasks that evaluate tool-use, bimanual coordination, long-horizon execution, and reasoning.
- A low-cost data collection pipeline pairing motion-capture gloves with a specialized retargeting algorithm records 1.1K trajectories and supports domain randomization for robustness assessment.
- Extensive empirical evaluations of modern models under visual and dynamics randomization, multi-task training, and action-head adaptation identify key policy limitations and demonstrate the necessity of embodiment-aware and multi-modal architectures.
Introduction
Achieving human-level robotic manipulation requires dexterous hands capable of fine-grained, contact-rich interactions that surpass standard parallel grippers, yet the field lacks standardized benchmarks that capture these unique capabilities while supporting comprehensive evaluation pipelines. Prior work suffers from simplified hand-only setups, limited task diversity, unreliable data collection due to hardware constraints or occlusion, and a critical misalignment where modern vision-language-action models are pretrained on gripper data rather than dexterous actions. To bridge these gaps, the authors present DexJoCo, a benchmark and toolkit for task-oriented dexterous manipulation featuring 11 functionally grounded tasks that evaluate tool-use, bimanual coordination, and long-horizon reasoning. They leverage a low-cost teleoperation system with retargeting to collect 1.1K high-quality human demonstration trajectories, enabling robust policy evaluation under domain randomization and revealing key insights into the limitations of current approaches, such as the necessity for embodiment-aware representations and multi-modal sensing.
Dataset
-
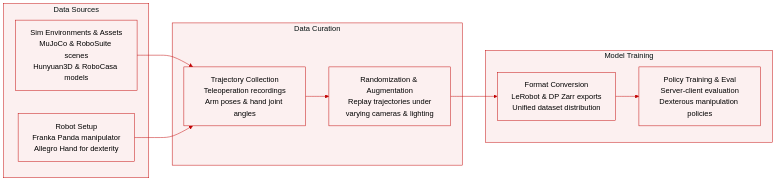
Dataset Composition and Sources: The authors construct a simulated dexterous manipulation dataset using a Franka Panda manipulator and Allegro Hand within the MuJoCo physics engine. Task environments and assets are sourced from RoboSuite, MuJoCo Menagerie, RoboCasa, and PartNet-Mobility, with unannotated assets generated via Hunyuan3D and manually adjusted for physical plausibility. The benchmark covers four capability categories: tool-use, reasoning, bimanual coordination, and long-horizon manipulation.
-
Subset Details and Structure: The benchmark is organized into four capability-oriented categories rather than traditional train or validation splits. While the authors do not disclose exact trajectory counts or explicit filtering rules, each task subset is defined by interactive objects and functional success constraints. Observations combine third-person and wrist-mounted RGB or RGB-D images with object poses, robot motion states, end-effector poses, and hand joint angles. Actions are recorded as target absolute end-effector poses for the arm and target absolute joint angles for the hand.
-
Data Usage and Training Setup: The authors convert collected trajectories into standard formats like LeRobot and DP Zarr for downstream policy training. The dataset serves as the primary training corpus for evaluating dexterous manipulation policies within a server-client evaluation framework. The authors do not specify fixed training splits or mixture ratios, instead treating the full benchmark as a unified distribution for policy development and assessment.
-
Processing and Augmentation Pipeline: To expand data diversity without additional teleoperation, the authors apply replay-based domain randomization. This involves re-rendering the same trajectories under randomized camera poses, lighting conditions, table heights, tabletop textures, and object placements. Camera poses are densely sampled on a sphere with fifty selected to minimize occlusion. The pipeline also embeds explicit visual state changes into assets to provide interactive feedback, ensuring trajectories align with structured success conditions before being exported through the provided toolkit interface.
Method
The authors leverage a teleoperation-based data collection system to gather human demonstration data for training robotic manipulation policies. The overall framework, shown in the figure below, integrates hardware and software components to enable accurate and low-cost motion capture and retargeting. The system employs a Rokoko Smartglove to capture hand poses and two HTC Vive trackers mounted on the wrists to track end-effector motion. These sensors are connected to a computer, where the hand motion data is processed in real time. The captured human hand movements are then retargeted to the robot using a neural network model, which maps human fingertip positions to the joint configurations of the Allegro hand. This retargeting process is performed by a multilayer perceptron (MLP) that is trained to preserve key motion characteristics while adapting to the structural differences between human and robotic hands.

The retargeting model is trained using a self-supervised approach, eliminating the need for paired human-robot annotations. The objective function for training the retargeting model f minimizes a composite loss that includes several terms: Ldir to preserve fingertip motion directions, Lcover to maximize workspace coverage, Lflat to maintain uniform sensitivity across the workspace, Lpinch to preserve pinch behaviors, and Lcol to prevent self-collisions. Only fingertip workspace data is recorded during demonstration collection, which reduces the complexity of the training data and enables real-time teleoperation. For wrist motion, the system tracks the relative pose changes of the HTC Vive trackers with respect to an initial reference pose, allowing the robot to execute delta actions that replicate the human operator's wrist movements.
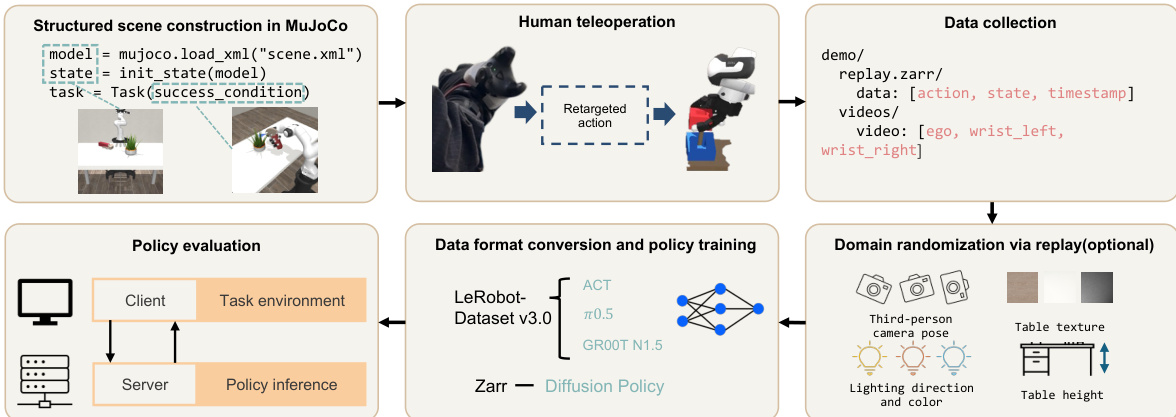
The collected data, including action, state, and timestamp information, is stored in a structured format and then processed for policy training. The data is converted into a standardized format compatible with the LeRobot-Dataset v3.0, which supports multiple model evaluations, including ACT, Diffusion Policy, and GR00T-N1.5. The system also incorporates domain randomization techniques during data collection to enhance the robustness of the learned policies. This includes randomizing third-person camera poses, lighting conditions, table textures, and table heights, ensuring that the trained policies generalize across diverse and dynamic environments. The framework supports a wide range of dexterous manipulation tasks, including tool-use, bimanual, long-horizon, and reasoning tasks, each designed to test different aspects of robotic dexterity and decision-making.
Experiment
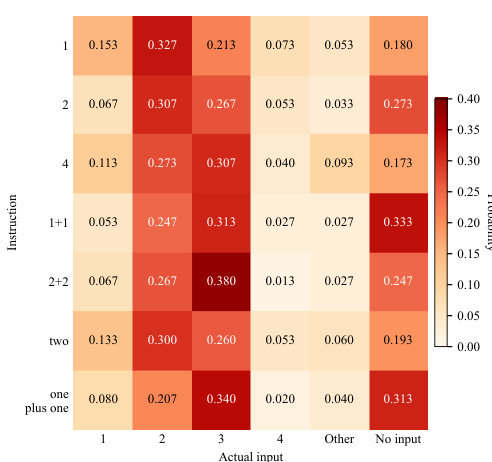
The evaluation benchmarks five imitation learning policies on complex bimanual manipulation tasks using asynchronous inference, systematically validating their robustness across varying visual randomization regimes, physical dynamics, multi-task joint training, action-head initialization strategies, and language instruction generalization. Qualitative analysis reveals that the benchmark effectively exposes fundamental trade-offs between pre-training scale, architectural design, and training methodology, with large-scale pre-trained models maintaining a general advantage despite performance drops when additional action dimensions are randomly initialized from scratch. While policies consistently struggle with fine-grained interactions, precise insertions, and temporal memory demands, retaining pretrained action heads significantly enhances robustness to dynamic variations and overall task success. Furthermore, the experiments demonstrate that multi-task joint training often degrades performance across architectures, and current vision-language-action models fail to generalize language instructions, instead relying on fixed action biases rather than true semantic conditioning.
The authors evaluate various imitation learning policies on a benchmark that tests dexterous manipulation capabilities, focusing on success rates under different training and evaluation conditions. Results show that while some policies perform well on specific tasks, others exhibit failure modes in fine-grained actions, insertion, and memory-dependent operations, with performance influenced by pre-training, model architecture, and task complexity. The benchmark reveals trade-offs between pre-training, model scale, and architecture, with different policies excelling in specific tasks like precise operations or bimanual manipulation. Policies often fail in fine-grained actions such as button pressing and insertion, indicating challenges in perception and memory for complex manipulation tasks. Retaining pretrained action-head weights improves performance, suggesting that pre-training contributes to robustness under varying conditions.

The authors evaluate several imitation learning policies on a dexterous manipulation benchmark, comparing their performance across different tasks and conditions. Results show that some policies achieve high success rates on certain tasks while failing on others, with performance varying significantly under visual and dynamic randomization. The analysis reveals that pre-trained action heads and architectural choices like FiLM injection contribute to better performance on precise manipulation tasks. Policies show varied success rates across tasks, with some excelling in specific operations like button pressing and hinge interactions while failing in insertion and memory-dependent actions. Performance drops sharply under visual randomization, indicating limited robustness, though some models maintain competitive results on bimanual tasks. Retaining pretrained action-head weights improves success rates, and architectural differences such as FiLM injection contribute to better performance on precise manipulation tasks.
The authors evaluate several imitation learning policies on a challenging dexterous manipulation benchmark, comparing their performance across different tasks and conditions. Results show that while some policies achieve high success rates on certain tasks, others fail on fine-grained actions, insertion, and memory-dependent operations, with performance varying significantly under different training and evaluation regimes. DP-T performs comparably to larger models on bimanual tasks despite being trained from scratch. DP-C outperforms other models on tasks requiring precise operations and hinge interactions. Retaining pretrained action-head weights leads to better overall success rates than random initialization.
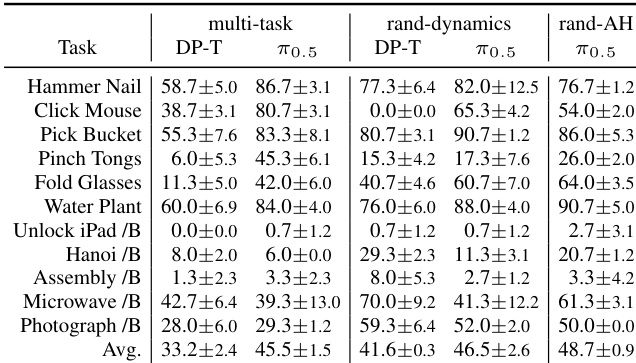
The authors evaluate multiple imitation learning policies on a challenging dexterous manipulation benchmark, comparing their performance across different tasks and conditions. Results show that while some policies achieve high success rates on certain tasks, others struggle with fine-grained actions and memory-dependent operations, and performance varies significantly under different training regimes and architectural choices. DP-C outperforms other policies on tasks requiring precise operations and hinge interactions, likely due to its use of FiLM for observation injection. Success rates drop sharply under visual randomization, indicating limited robustness across all policies. Retaining pretrained action-head weights leads to better performance compared to fully random initialization on most tasks.
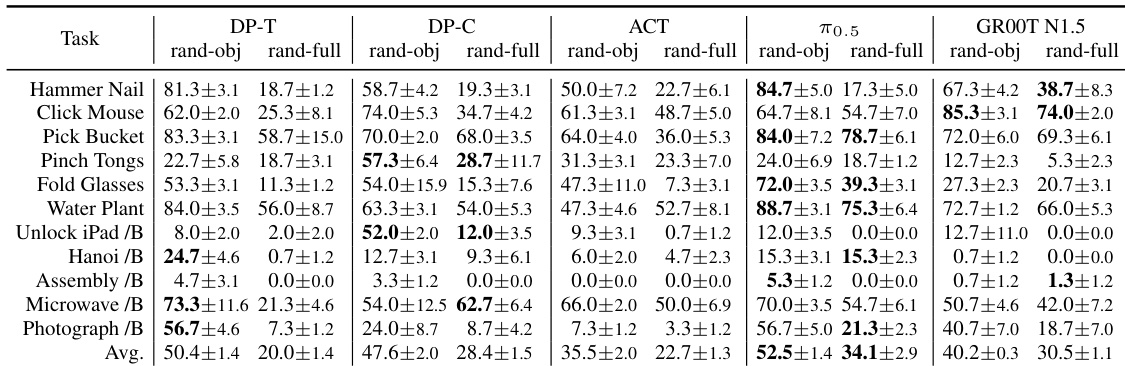
The experiments evaluate multiple imitation learning policies on a dexterous manipulation benchmark to validate their task-specific capabilities, robustness to environmental randomization, and the impact of architectural design choices. Qualitative results reveal that policies consistently struggle with fine-grained actions, insertion, and memory-dependent operations, while showing high sensitivity to visual perturbations that limit generalization. However, retaining pre-trained action-head weights and utilizing FiLM injection significantly enhance precision and overall success rates across varying conditions. These findings collectively demonstrate that strategic initialization and architectural features are more decisive for robust manipulation performance than model scale alone.