Command Palette
Search for a command to run...
ESI-BENCH : Vers une intelligence spatiale incarnée qui referme la boucle perception-action
ESI-BENCH : Vers une intelligence spatiale incarnée qui referme la boucle perception-action
Yining Hong Jiageng Liu Han Yin Manling Li Leonidas Guibas Li Fei-Fei Jiajun Wu Yejin Choi
Résumé
L’intelligence spatiale se déploie au sein d’une boucle perception-action : les agents agissent afin de recueillir des observations, puis raisonnnent sur la manière dont ces observations varient en fonction de l’action. Plutôt que de traiter passivement ce qui est visible, ils explorent activement ce qui est occulté — la structure cachée, la dynamique, la contenance et la fonctionnalité — qui ne peuvent être résolues par une perception passive seule. Nous dépassons les formulations antérieures de l’intelligence spatiale, qui partaient du postulat d’observations oraculaires, en reformulant l’observateur comme un acteur. Nous présentons ESI-BENCH, un benchmark complet pour l’intelligence spatiale incarnée, couvrant 10 catégories de tâches et 29 sous-catégories, construit sur OmniGibson et ancré dans les systèmes de connaissances fondamentales de Spelke. Les agents doivent décider quelles capacités déployer — perception, locomotion et manipulation — et comment les séquencer afin d’accumuler activement les preuves pertinentes pour la tâche. Nous menons des expériences approfondies sur des MLLM de pointe et constatons que l’exploration active surpasse nettement les approches passives : les agents découvrent spontanément des stratégies spatiales émergentes sans instructions explicites, tandis que l’acquisition aléatoire de multiples points de vue ajoute souvent du bruit plutôt que du signal, et ce bien qu’elle consomme beaucoup plus d’images. La majorité des échecs ne proviennent pas d’une perception faible, mais d’une « cécité actionnelle » : de mauvais choix d’action conduisent à de mauvaises observations, qui entraînent à leur tour des erreurs en cascade.
One-sentence Summary
The authors introduce ESI-BENCH, a comprehensive benchmark for embodied spatial intelligence on OmniGibson grounded in Spelke's core knowledge systems that closes the perception-action loop by requiring agents to sequence perception, locomotion, and manipulation abilities to actively accumulate task-relevant evidence, demonstrating through experiments on state-of-the-art MLLMs that active exploration substantially outperforms passive counterparts and that most failures stem from action blindness rather than weak perception.
Key Contributions
- ESI-BENCH is introduced as a comprehensive benchmark for embodied spatial intelligence built on OmniGibson that spans 10 task categories, 29 subcategories, and 3,081 task instances grounded in Spelke's core knowledge systems. The benchmark addresses the perception-action gap by requiring agents to determine which embodied abilities to deploy and sequence to answer questions that cannot be resolved from passive observation alone.
- Spatial intelligence is recast from passive sensing to active exploration, requiring agents to determine which observations are worth acquiring to prioritize task-relevant information. Experiments on state-of-the-art MLLMs show that active exploration substantially outperforms passive counterparts, with agents spontaneously discovering emergent spatial strategies without explicit instructions.
- Analysis reveals that action blindness dominates perceptual blindness, as poor action choices lead to uninformative views that drive cascading errors. Further investigation indicates that while explicit 3D grounding stabilizes reasoning on depth-sensitive tasks, imperfect reconstructions distort fine-grained spatial relations and mislead downstream reasoning.
Introduction
Spatial intelligence fundamentally depends on a perception-action loop where agents actively reveal latent physical properties rather than relying on passive sensing. Previous approaches often assume passive oracle observations, which limits evaluation to visual recognition instead of embodied competence. The authors introduce ESI-BENCH, a comprehensive benchmark spanning ten task categories and 3,081 instances to address the gap between sensing and acting. This framework evaluates whether agents can select appropriate abilities and resolve ambiguities, demonstrating that action selection frequently dominates perceptual accuracy.
Dataset

Dataset Composition and Sources
- The authors introduce ESI-BENCH as a benchmark comprising 3,081 task instances organized into 10 categories and 29 subcategories.
- Data is sourced from the BEHAVIOR-1K scene pool which includes 51 interactive 3D scenes with over 9,000 object instances.
- The environment is simulated using OmniGibson to ensure accurate physics, lighting, and object states.
Key Details for Each Subset
- Each task instance is defined by a scene, initial agent pose, natural-language question, and ground-truth answer.
- The action space covers locomotion, perception, and manipulation with a step budget capped at 30 steps.
- Subcategories address specific reasoning challenges such as material transparency, liquid volume, partial occlusion, and specular reflection.
- Categories align with core knowledge systems including object representation, geometry, number, and agent reasoning.
Usage in the Model
- The dataset serves as an evaluation benchmark for zero-shot testing rather than a training set for fine-tuning.
- Models are evaluated on their ability to acquire evidence through active exploration instead of relying on fixed observations.
- Performance is measured against human baselines and passive observation settings to quantify the benefit of active perception.
Processing and Metadata Construction
- GPT-4o proposes candidate objects, placements, questions, and trajectories based on scene graphs before simulation.
- Physics simulations settle objects, and automated checks validate stability and physical plausibility.
- Human annotators verify correctness, answerability, and non-triviality using a majority vote system for disagreements.
- Final metadata is stored in JSON files containing scene details, agent poses, verification flags, and action trajectories.
- The authors audit for linguistic and object-category biases by testing shortcut baselines that exclude visual observations.
Method
The authors leverage an active exploration framework where the evaluated Multimodal Large Language Model (MLLM) controls an embodied agent through a discrete action space. At each timestep, the model receives the task question, the current egocentric observation, the previous action-observation history, and the full action vocabulary. It is then prompted to select exactly one next action. This process creates a feedback loop where the selected action is executed in the OmniGibson simulator, producing the next egocentric observation. The sequential flow of this active exploration process, from initial perception to terminal answer, is illustrated in the figure below.
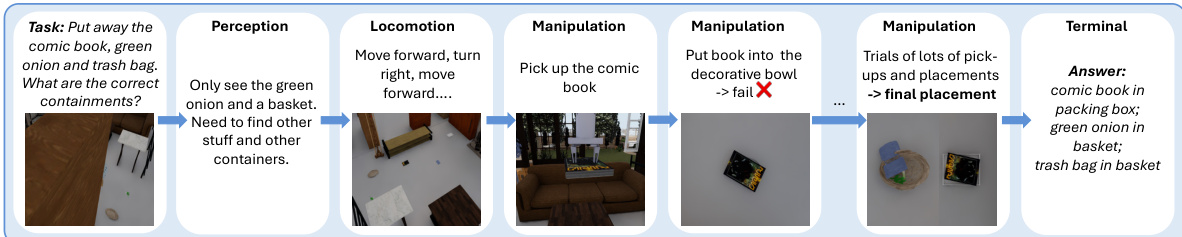
To guide this behavior, the system uses a standardized prompt template across all task categories. The prompt instructs the agent to actively explore the scene to answer the question, emphasizing that actions should only be taken to gather evidence. The available actions include navigation primitives like move_forward and turn_left, as well as manipulation commands such as pick_up and put. The model is required to output a reason for the next step and the specific action string. This loop continues until the model issues the terminal answer or reaches the maximum budget of Tmax=30 steps.
Regarding execution, model outputs are parsed into the nearest valid action string. If the output is invalid or malformed, the system reprompts the model once. If the response remains invalid, the step is counted as invalid and the agent remains in place. For manipulation actions, object names are matched to visible identifiers. Notably, failed physical executions, such as attempting to pick up an unreachable object, are executed as simulator failures and included in the trajectory to reflect the agent's action-selection behavior accurately.
For specific task modules like Cognitive Mapping, the authors employ procedural generation. In the Connectivity task, the system selects one navigable render point for each room from the traversability map. It captures eight evenly spaced room reference views from these points. Question generation involves extracting room regions and sampling navigable candidate points. The ground-truth label is determined by checking if a valid shortest path exists between the two rooms using the scene segmentation map.
The benchmark encompasses a wide variety of capabilities, ranging from Physical Structure and Specular Reflection to Perceptual Grounding and Cognitive Mapping. The distribution of these task categories is visualized in the pie chart below, highlighting the emphasis on areas like Perceptual Grounding and Physical Dynamics.
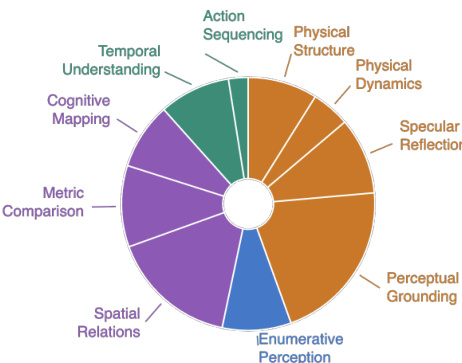
The full taxonomy of tasks is presented in the grid below, which details specific sub-categories such as Liquid Volume, Spatial Segmentation, and Action Sequencing. Each sub-category includes example scenarios and questions designed to test specific embodied intelligence capabilities.

Experiment
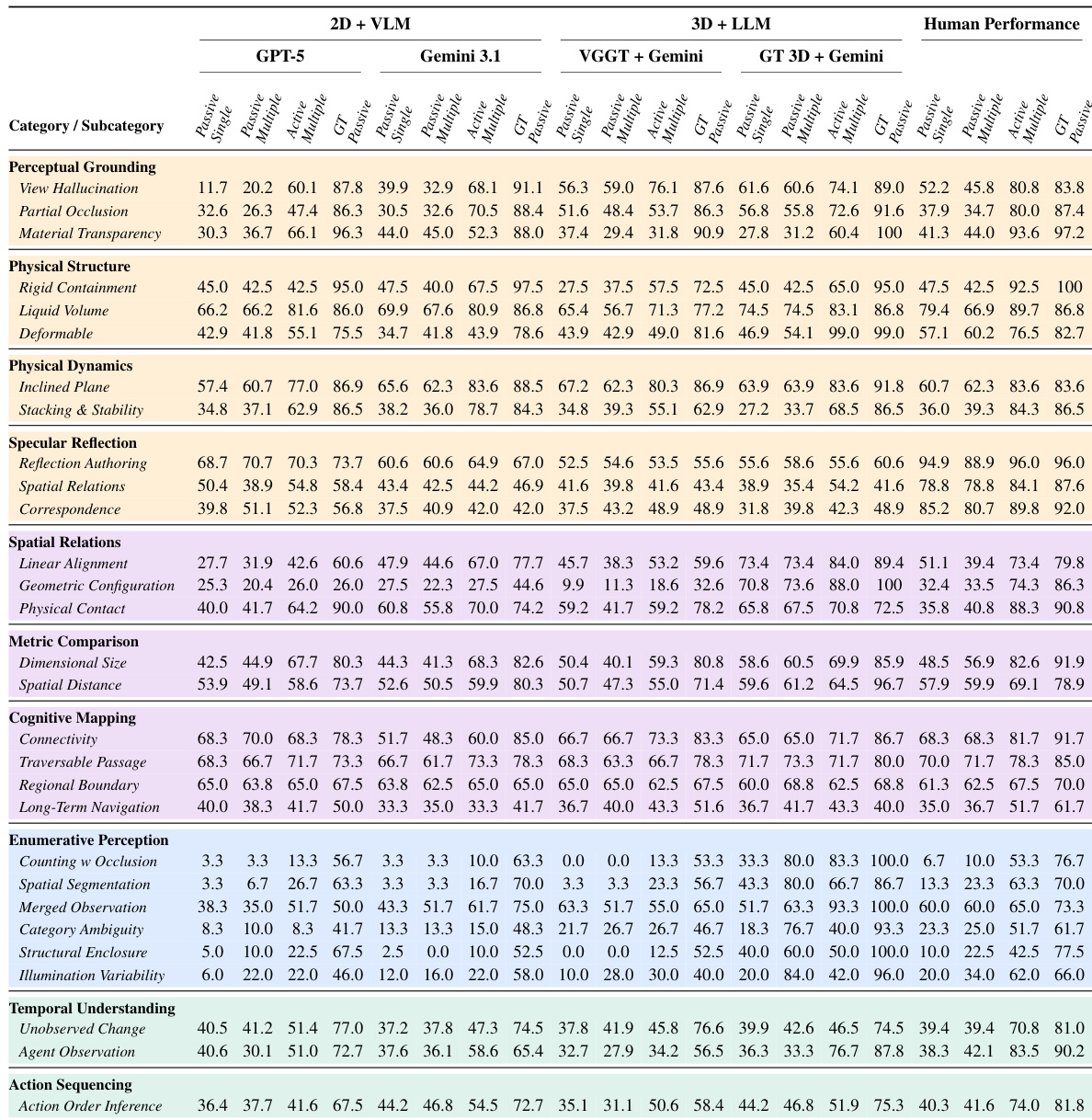
The study evaluates models across four paradigms ranging from passive observation to active exploration, demonstrating that agents significantly outperform passive counterparts by spontaneously discovering emergent strategies to gather task-relevant evidence. Experiments identify action selection as the primary bottleneck rather than perception, while also showing that perfect 3D grounding improves depth-sensitive tasks but imperfect reconstructions actively distort spatial relations. Finally, human comparisons reveal a metacognitive gap where models commit prematurely with high confidence instead of seeking falsifying viewpoints or revising beliefs under contradiction.
The authors evaluate spatial intelligence across passive, active, and oracle paradigms using 2D VLMs, 3D-augmented LLMs, and human participants. Results indicate that active exploration substantially outperforms passive multi-view inputs, which often degrade performance by adding noise. While perfect 3D grounding significantly aids spatial reasoning, imperfect 3D reconstructions can be more harmful than 2D baselines. A significant gap remains between models and humans, primarily driven by the models' inability to select informative actions and their tendency to commit prematurely without seeking falsifying evidence. Active exploration yields substantial gains over passive multi-view baselines, which often introduce noise rather than signal. Imperfect 3D reconstruction degrades performance on fine-grained spatial tasks, proving more harmful than standard 2D baselines. Human performance significantly exceeds models in active settings due to better epistemic calibration and belief revision strategies.
The authors operationalize the metacognitive gap by measuring view diversity, contrastive view rates, and belief revision rates. Data shows that human agents outperform active models across all three metrics, demonstrating superior evidence gathering and belief updating capabilities. Human agents demonstrate significantly higher view diversity than model agents. Models exhibit a lower rate of seeking contrastive views compared to humans. Humans revise their beliefs more often when faced with contradictory evidence.

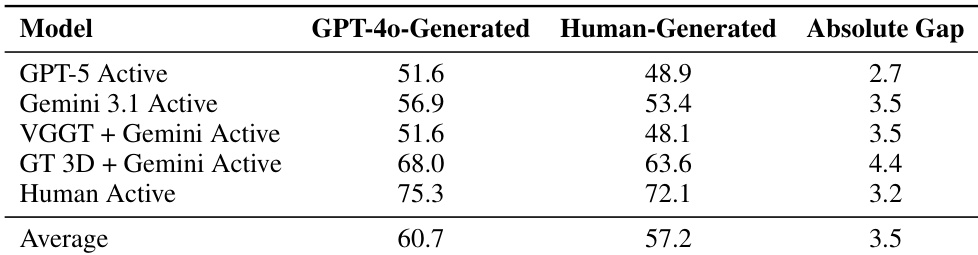
The authors evaluate whether GPT-4o-generated tasks introduce a systematic difficulty bias by comparing model accuracy on AI-generated versus human-authored subsets under active exploration. Results show that model performance is broadly similar across both task sources, with only minor variations in scores. This suggests that GPT-4o can effectively generate scalable task proposals without significantly altering the benchmark's difficulty level. Model accuracy remains consistent across AI-generated and human-authored task subsets. Performance gaps between task sources are minimal, indicating comparable difficulty levels. GPT-4o is validated as a viable method for generating scalable benchmark tasks.
The the the table evaluates model performance across text-only baselines, passive single-view observation, and active exploration paradigms. Active exploration consistently yields the highest accuracy across all spatial reasoning categories, significantly outperforming passive observation. Passive single-view results generally exceed text-only baselines, demonstrating the necessity of visual input while highlighting the superior efficacy of active evidence gathering. Active exploration achieves the highest average performance, substantially surpassing passive single-view observation. Passive single-view observation outperforms text-only baselines, confirming the necessity of visual grounding. Performance gains from active exploration are consistent across diverse categories such as Physical Dynamics and Perceptual Grounding.
The the the table presents quality statistics for the ten task categories within the ESI-BENCH benchmark. It indicates that the dataset is well-constructed with high answer balance and object diversity across all categories to ensure robust evaluation. Answer balance is consistently high across all categories, with Metric Comparison reaching the peak value. Object diversity is maintained at strong levels, particularly in Enumerative Perception and Spatial Relations. The average scores confirm the benchmark's overall effectiveness in minimizing bias and ensuring visual variety.
The authors evaluate spatial intelligence across passive, active, and oracle paradigms, demonstrating that active exploration substantially outperforms passive inputs while imperfect 3D reconstructions prove more harmful than standard 2D baselines. A significant gap remains between models and humans, primarily caused by the models' inability to effectively gather evidence or revise beliefs compared to human participants. Finally, the study validates the scalability of GPT-4o generated tasks and confirms the ESI-BENCH benchmark offers high diversity and answer balance for robust spatial reasoning evaluation.