HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

ASPIRE: Agentic /Skills Discovery for Robotics
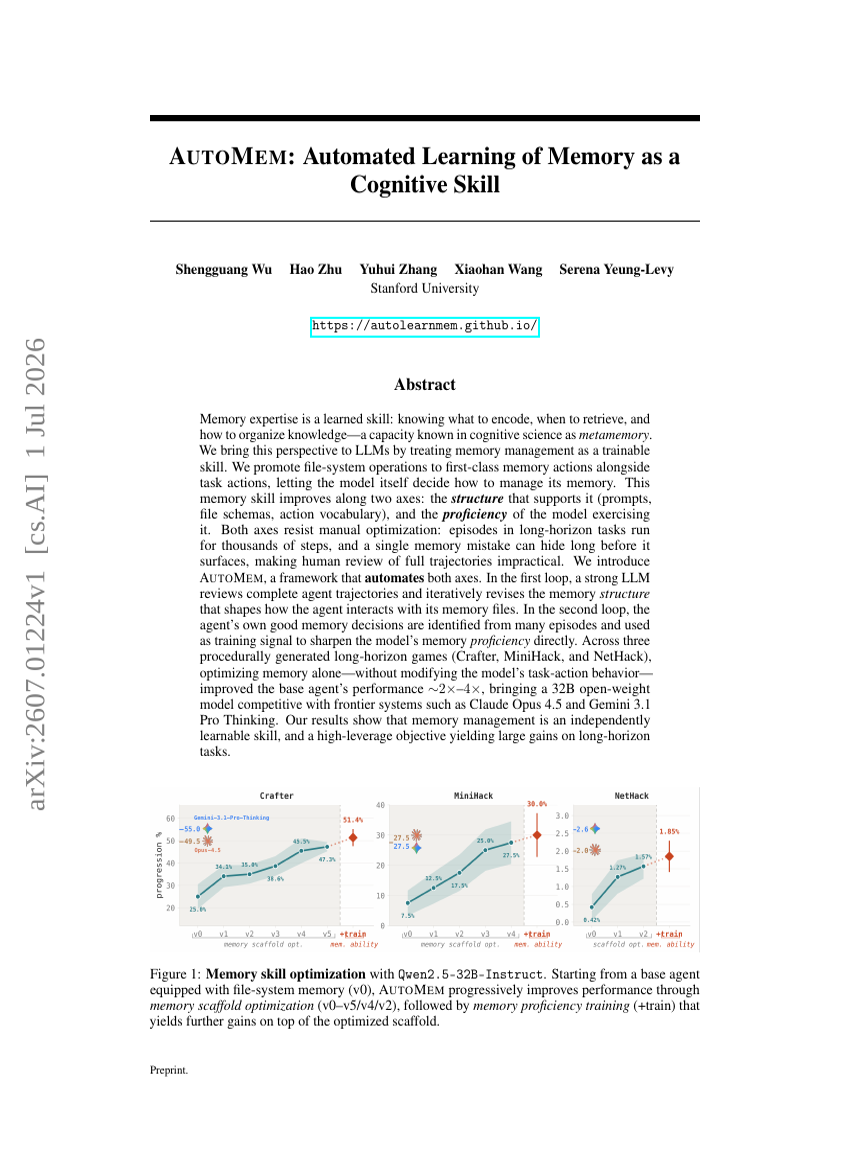
AUTOMEM: Automated Learning of Memory as a Cognitive Skill


























ASPIRE: Agentic /Skills Discovery for Robotics
AUTOMEM: Automated Learning of Memory as a Cognitive Skill
The Decode-Work Law: Margin-Governed, Provably-Exact Spatial Joins over Compressed Geometry
Neural Certificate Pricing for Combinatorial Optimization Problems
Optimal Resource Utilization for Autonomous Laboratory Orchestrators
TERA: A Unified Taylor Model Enabled Reachability Analysis Framework
Perceive-to-Reason: Decoupling Perception and Reasoning for Fine-Grained Visual Reasoning
Trie-based Experiment Plans for Efficient IR Pipeline Experiments
On the Nonlinearity of Learning Rate Scaling for LLM Training
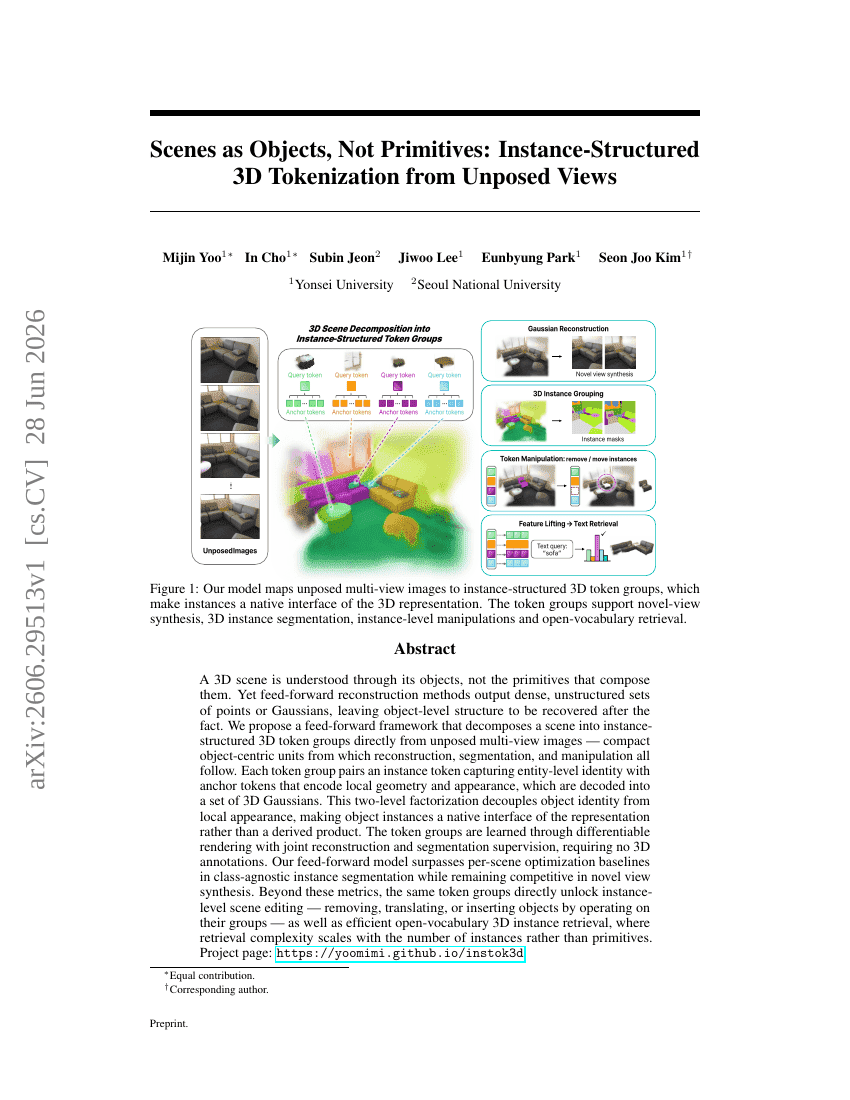
Scenes as Objects, Not Primitives: Instance-Structured 3D Tokenization from Unposed Views
BlockPilot: Instance-Adaptive Policy Learning for Diffusion-based Speculative Decoding
DOPD: Dual On-policy Distillation
Dockerless: Environment-Free Program Verifier for Coding Agents
Orca: The World is in Your Mind
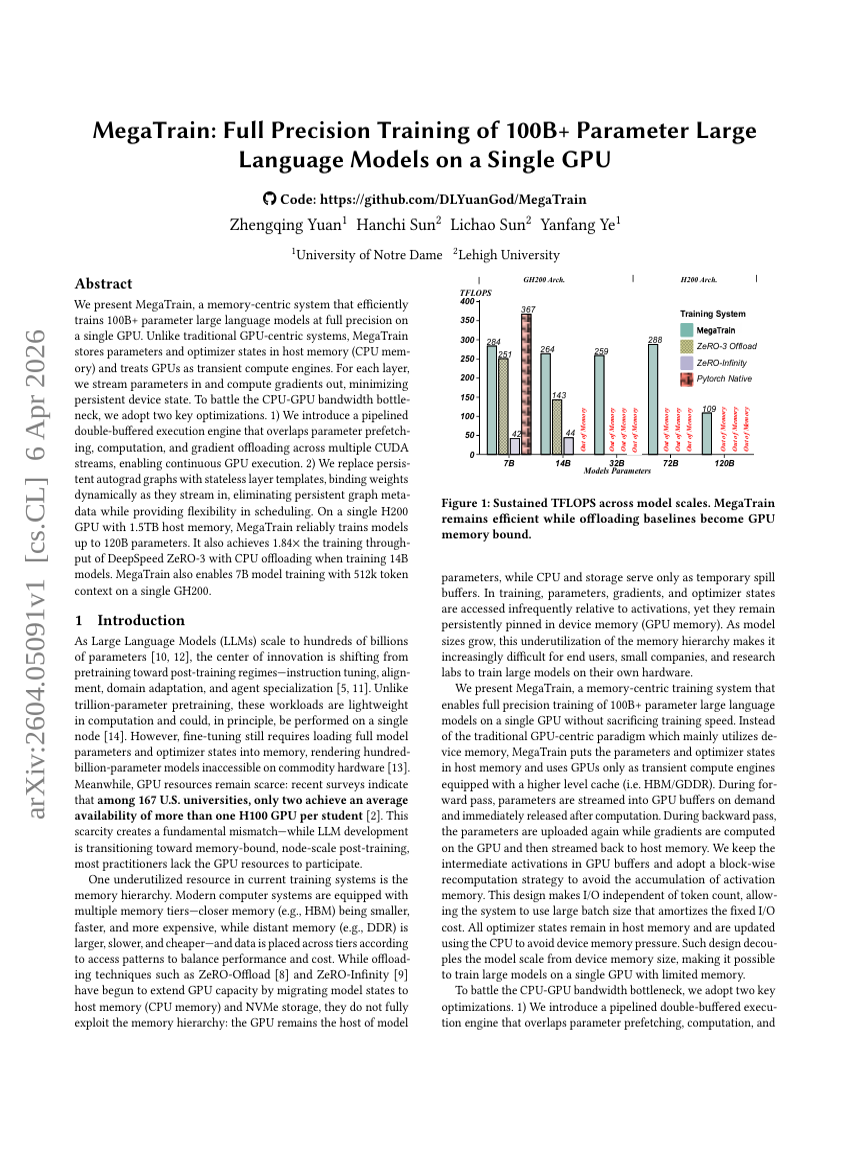
MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
Finding the Time to Think: Learning Planning Budgets in Real-Time RL
What do near-optimal learning rate schedules look like?
Beyond IID: How General Are Tabular Foundation Models, Really?
ReFreeKV: Towards Threshold-Free KV Cache Compression
TUA-Bench: A Benchmark for General-Purpose Terminal-Use Agents
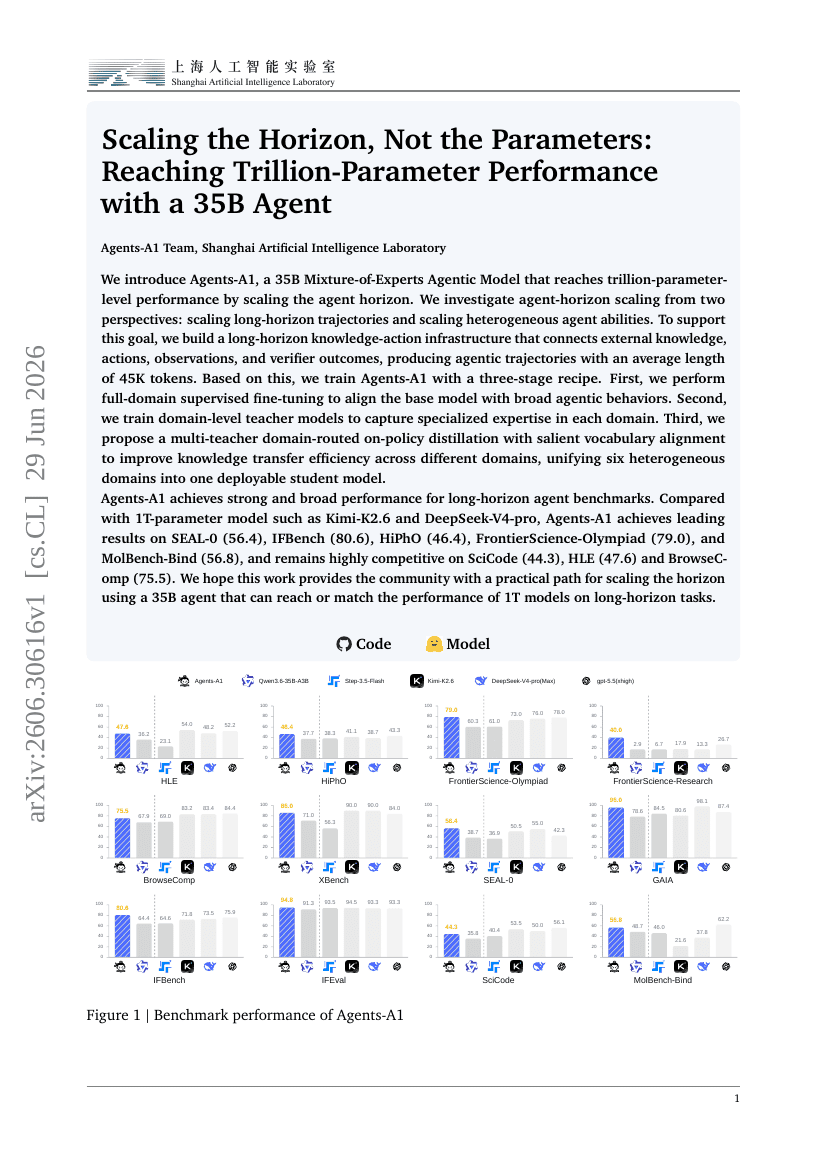
Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
Agentic Abstention: Do Agents Know When to Stop Instead of Act?
EVA-Bench: A New End-to-end Framework for Evaluating Voice Agents
SingGuard: A Policy-Adaptive Multimodal LLM Guardrail with Dynamic Reasoning
Formalizing Latent Thoughts: Four Axioms of Thought Representation in LLMs
MultiHashFormer: Hash-based Generative Language Models
Qwen-Image-2.0-RL Technical Report
Translation as a Bridging Action: Transferring Manipulation Skills from Humans to Robots
PhysisForcing: Physics Reinforced World Simulator for Robotic Manipulation
OpenTME: An Open Dataset of AI-powered H&E Tumor Microenvironment Profiles from TCGA
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
The Decode-Work Law: Margin-Governed, Provably-Exact Spatial Joins over Compressed Geometry
Neural Certificate Pricing for Combinatorial Optimization Problems
Optimal Resource Utilization for Autonomous Laboratory Orchestrators
TERA: A Unified Taylor Model Enabled Reachability Analysis Framework
Perceive-to-Reason: Decoupling Perception and Reasoning for Fine-Grained Visual Reasoning
Trie-based Experiment Plans for Efficient IR Pipeline Experiments
On the Nonlinearity of Learning Rate Scaling for LLM Training
Scenes as Objects, Not Primitives: Instance-Structured 3D Tokenization from Unposed Views
BlockPilot: Instance-Adaptive Policy Learning for Diffusion-based Speculative Decoding
DOPD: Dual On-policy Distillation
Dockerless: Environment-Free Program Verifier for Coding Agents
Orca: The World is in Your Mind
MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
Finding the Time to Think: Learning Planning Budgets in Real-Time RL
What do near-optimal learning rate schedules look like?
Beyond IID: How General Are Tabular Foundation Models, Really?
ReFreeKV: Towards Threshold-Free KV Cache Compression
TUA-Bench: A Benchmark for General-Purpose Terminal-Use Agents
Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
Agentic Abstention: Do Agents Know When to Stop Instead of Act?
EVA-Bench: A New End-to-end Framework for Evaluating Voice Agents
SingGuard: A Policy-Adaptive Multimodal LLM Guardrail with Dynamic Reasoning
Formalizing Latent Thoughts: Four Axioms of Thought Representation in LLMs
MultiHashFormer: Hash-based Generative Language Models
Qwen-Image-2.0-RL Technical Report
Translation as a Bridging Action: Transferring Manipulation Skills from Humans to Robots
PhysisForcing: Physics Reinforced World Simulator for Robotic Manipulation
OpenTME: An Open Dataset of AI-powered H&E Tumor Microenvironment Profiles from TCGA
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling