Command Palette
Search for a command to run...
TUA-Bench: A Benchmark for General-Purpose Terminal-Use Agents
TUA-Bench: A Benchmark for General-Purpose Terminal-Use Agents
Shoufa Chen Luyuan Wang Xuan Yang Zhiheng Liu Yuren Cong Yuanfeng Ji Feiyan Zhou Xiaohui Zhang Fanny Yang Belinda Zeng
Abstract
As large language models and harness frameworks continue to advance, agents operating in terminals are increasingly capable of performing a broader range of general computer-use tasks beyond coding. However, existing benchmarks do not adequately evaluate general-purpose terminal computer-use agents (TUAs): general computer-use benchmarks primarily target graphical user interfaces (GUIs), whereas terminal-based benchmarks largely emphasize technical and programming-centric workflows historically native to the shell. We introduce TUA-Bench, a general-purpose benchmark for terminaluse agents. TUA-Bench includes 120 real-world tasks across five task families, covering routine digital activities—including document editing, email management, and live-web information seeking—as well as scientific and engineering workflows co-designed with PhD-level domain experts that require specialized software. This breadth distinguishes TUA-Bench from prior shell-focused or domain-specific benchmarks. Each task is manually designed, runs in a real terminal with a deterministic setup script, and is evaluated by an execution-based scoring protocol. We find that the strongest frontier agent, Claude Code with Claude Opus 4.8 max reasoning effort, achieves 65.8% overall performance, with substantial gaps across both tracks. By providing a broad and realistic evaluation of terminal-use capabilities, TUA-Bench aims to accelerate the transition from narrow, task-specific assistants to general-purpose agents capable of operating reliably across diverse digital environments.
One-sentence Summary
Researchers from Meta AI, Duke University, and Stanford University present TUA-Bench, a benchmark of 120 real-world terminal tasks spanning routine digital activities and PhD-level scientific workflows, where the top performer Claude Code with Claude Opus 4.8 achieves only 65.8%, revealing gaps and aiming to accelerate the development of reliable general-purpose terminal-use agents.
Key Contributions
- TUA-Bench introduces a general-purpose benchmark with 120 manually designed terminal tasks covering everyday digital activities and domain-specific scientific/engineering workflows co-developed with PhD-level experts.
- Each task runs in a real terminal with a deterministic setup script and is evaluated through an execution-based scoring protocol.
- The strongest frontier agent, Claude Code with Claude Opus 4.8 max reasoning effort, attains 65.8% overall success, revealing substantial gaps across both tracks in reliable terminal-based computer use.
Introduction
As large language models evolve into autonomous agents that carry out multi-step digital work, evaluating their computer use reliably has become critical. Most existing benchmarks rely on graphical user interfaces, which force agents to handle visual grounding and layout changes, making it hard to isolate planning and reasoning skills. Meanwhile, command-line interfaces (CLIs) offer a text-native interaction well-suited to language models and are already central to many professional workflows, but prior CLI benchmarks like Terminal-Bench focus narrowly on shell programming and technical tasks. The authors introduce TUA-Bench, a benchmark of 120 manually curated terminal-use tasks spanning everyday computer use and expert workflows co-designed with domain scientists, to evaluate general-purpose CLI agents. The strongest tested agent achieves only a 65.8% success rate, highlighting open challenges in long-horizon planning, tool use, and error recovery.
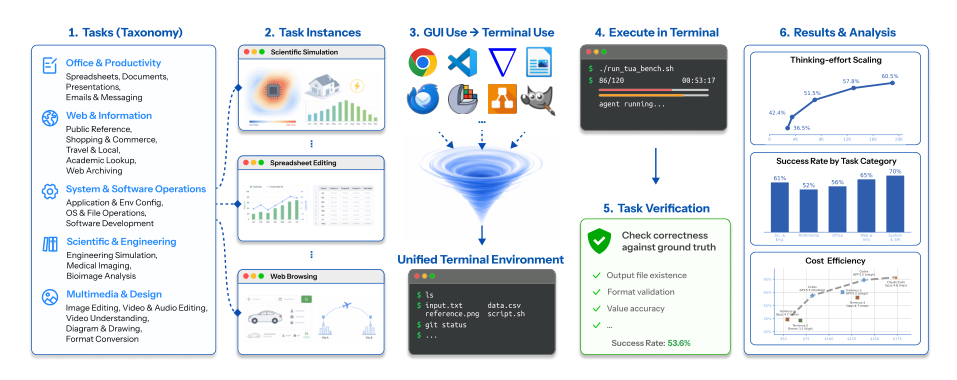
Dataset
TUA-Bench is a benchmark of 120 terminal-based tasks designed to evaluate how well agents plan, interact with software, and verify outcomes in realistic computing environments. The tasks are split into two complementary groups that cover everyday workflows and specialized professional procedures.
Dataset composition and sources
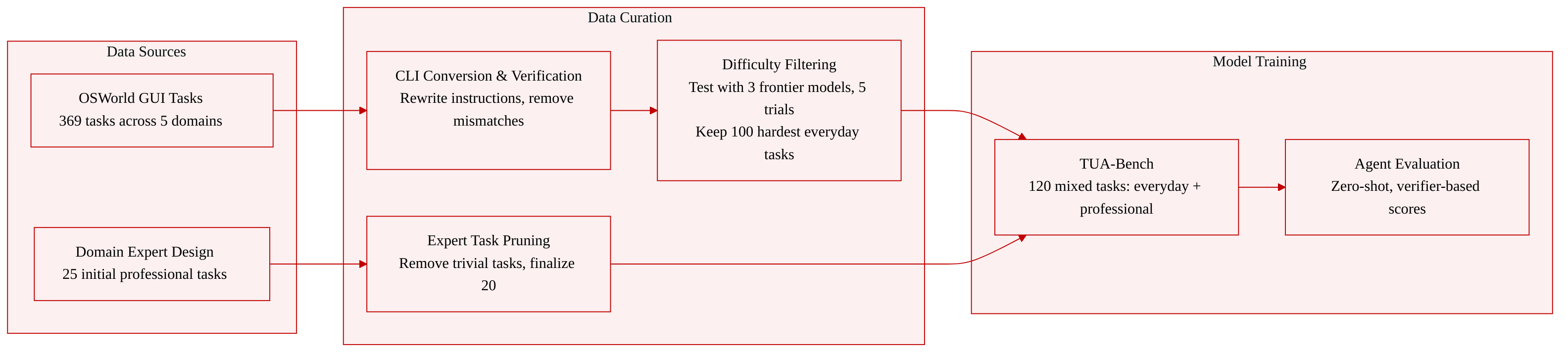
- Everyday digital tasks (100 tasks): Sourced from OSWorld, a GUI-centric benchmark of 369 tasks spanning web, office, multimedia, and system operations. The authors convert each GUI task into a terminal-native specification by rewriting instructions for command-line use, while preserving the original input files and gold output artifacts. After conversion, a human verification step removes tasks where input files and gold artifacts are inconsistent (e.g., mismatched slide themes), ensuring only reliable evaluation items remain. The remaining candidate tasks are then scored for difficulty using three frontier models (GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro) under the Terminus-2 agent framework, with five trials per task. The 100 tasks with the lowest mean solvability (i.e., the most challenging) are retained.
- Professional scientific tasks (20 tasks): Co-designed with PhD-level domain experts in biology, medical physics, architectural engineering, and mechanical engineering. An initial set of 25 tasks is built around authentic multi-step workflows that demand specialized software and domain-specific procedural knowledge. Each task comes with executable verifiers or expert-informed judging rubrics. After removing tasks that are trivially solved by multiple agents, 20 challenging tasks remain.
Task packaging and execution environment Every task is a self-contained package that includes a Dockerfile, task input files, natural-language instructions, environment variables, and an in-environment verifier. The benchmark runs on Harbor, an orchestration framework that provisions isolated Linux containers, manages parallel execution, and collects trajectories, token usage, and scores. This ensures reproducibility while allowing agents to use real files, shell commands, and optional internet access.
Task taxonomy and statistics (Figure 2) The 120 tasks fall into five top-level families: Office & Productivity (38.3%), Web & Information (18.3%), System & Software Operations (16.7%), Scientific & Engineering (13.3%), and Multimedia & Design (13.3%). These families are further divided into 20 subcategories, covering spreadsheet editing, email management, engineering simulation, medical imaging, software configuration, and more.
How the benchmark is used TUA-Bench is an evaluation suite, not a training dataset. The authors use it to measure agentic performance on open-ended computer-use tasks. Agents are evaluated in a zero-shot manner inside the Harbor environment, and their success is determined by the task verifiers. The benchmark’s difficulty-aware curation and mixed everyday/professional composition aim to provide a long-term challenge for assessing planning, tool selection, and verification capabilities across heterogeneous real-world workflows.
Method
The authors construct TUA-Bench through a principled, two-pronged curation strategy supported by a standardized execution layer. The methodology spans environment packaging, task transformation, quality screening, and difficulty-driven filtering, ensuring a reproducible and challenging benchmark for terminal‑agent evaluation.
The evaluation infrastructure is built on Harbor, the same orchestration framework used in Terminal‑Bench. Harbor manages the full lifecycle of a trial: task configuration, containerized environment setup, parallel execution, and collection of trajectories, token usage, scores, and runtime metadata. Each task runs inside an isolated, resettable Linux container, so failed or unsafe executions do not contaminate subsequent runs. Beyond Docker, Podman is supported for rootless execution on shared clusters. This substrate lets agents operate in realistic terminal environments with files, packages, optional internet access, and native CLI‑based agent interfaces.
Every task is packaged as a self‑contained unit that includes a Dockerfile, input artifacts, natural‑language instructions, environment variables, model and runtime settings, and an in‑environment verifier. This packaging fixes the initial state, execution procedure, and evaluation protocol, giving consistent and reproducible comparisons while still permitting stochastic agent behavior and internet‑dependent variation when networking is enabled.
Task curation proceeds along two orthogonal dimensions: breadth, which captures everyday digital work (web browsing, document editing, email, media processing), and depth, which targets expert workflows co‑designed with PhD‑level domain experts in biology, medical physics, architectural engineering, and mechanical engineering. The two tracks follow distinct design pipelines.
For everyday tasks, the authors start from OSWorld, a GUI‑based benchmark of 369 realistic computer‑use tasks. They translate each task into a CLI‑centric formulation by preserving the underlying intent but stripping away application‑specific assumptions. Input files and gold artifact specifications are retained from OSWorld, while instructions are rewritten to be natural and actionable from a terminal. Crucially, agents are not forced to use the original GUI application; they may choose any command‑line tools, utilities, or workflow to reach the goal.
This conversion is followed by two quality‑control stages. First, human verification inspects failed execution trajectories and the artifacts produced by agents, identifying tasks where failure stems from input‑gold inconsistencies rather than agent shortcomings (for example, mismatched slide themes in presentation tasks). Any task with a verified discrepancy is removed. Second, a difficulty‑aware selection procedure is applied: each remaining candidate is evaluated with three frontier models (GPT‑5.5, Claude Opus 4.7, and Gemini 3.1 Pro), each running within the Terminus‑2 agent framework. For each model–task pair, five independent trials are run and the mean reward is recorded as an empirical solvability score. Tasks are ranked by aggregate solvability, and the 100 hardest tasks are retained. This ensures that the benchmark resists saturation even as foundation models continue to improve, sustaining long‑term discriminative power.
The depth track follows a complementary co‑design approach with domain experts, though its detailed construction is separate; it emphasizes realistic procedures, domain‑specific constraints, and executable evaluation crafted directly for terminal‑agent interaction. Together, the two tracks produce the 120‑task benchmark, all of which are uniformly packaged for the Harbor‑based execution environment and ready for large‑scale agent evaluation.
Experiment
the paper evaluate five terminal-based agent frameworks paired with a broad suite of frontier and open models on TUA‑Bench, measuring execution‑grounded success and reliability across repeated trials. The benchmark cleanly separates capability tiers: the strongest models achieve high average success, yet scaffold choice can reverse model rankings and reliable, consistent performance remains challenging. Longer task time limits and increased reasoning effort both improve success but yield diminishing returns, while cost‑efficiency analysis shows that lightweight scaffolds with open‑weight models can offer competitive results at low cost. Category‑level performance varies widely, with specific hard tasks resisting all tested systems, indicating that future progress requires addressing these difficult cases rather than simply raising overall averages.
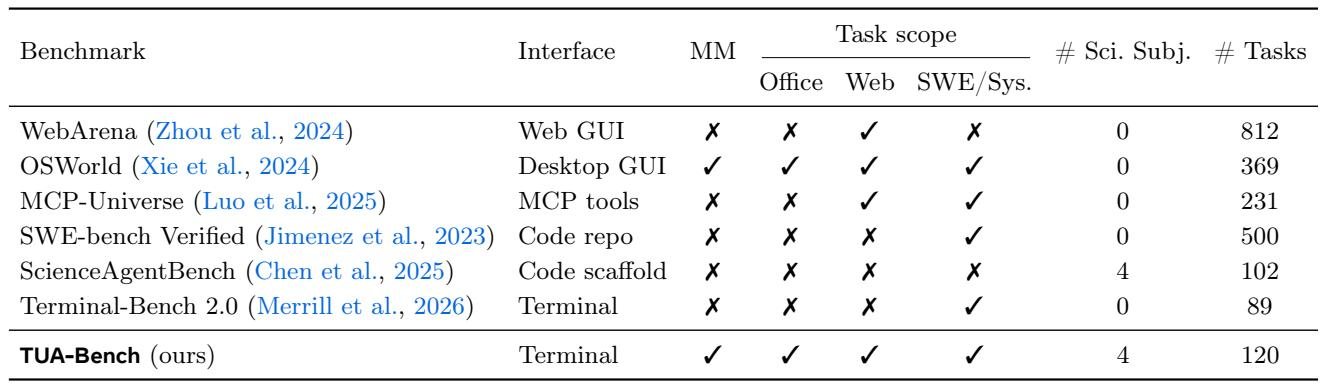
Existing benchmarks reveal a clear split: tools with broad task coverage across office, web, and system operations are built on graphical interfaces, while command-line benchmarks remain limited to software and system tasks. No terminal-based benchmark offers office or web task evaluation, highlighting a gap that leaves text-native interaction for everyday computer use unevaluated. OSWorld is the only benchmark that covers office, web, and system tasks, and it operates through a desktop GUI. All listed terminal (or code-repo) benchmarks, such as Terminal-Bench 2.0 and SWE-bench Verified, lack office and web task coverage, focusing exclusively on software or system challenges.
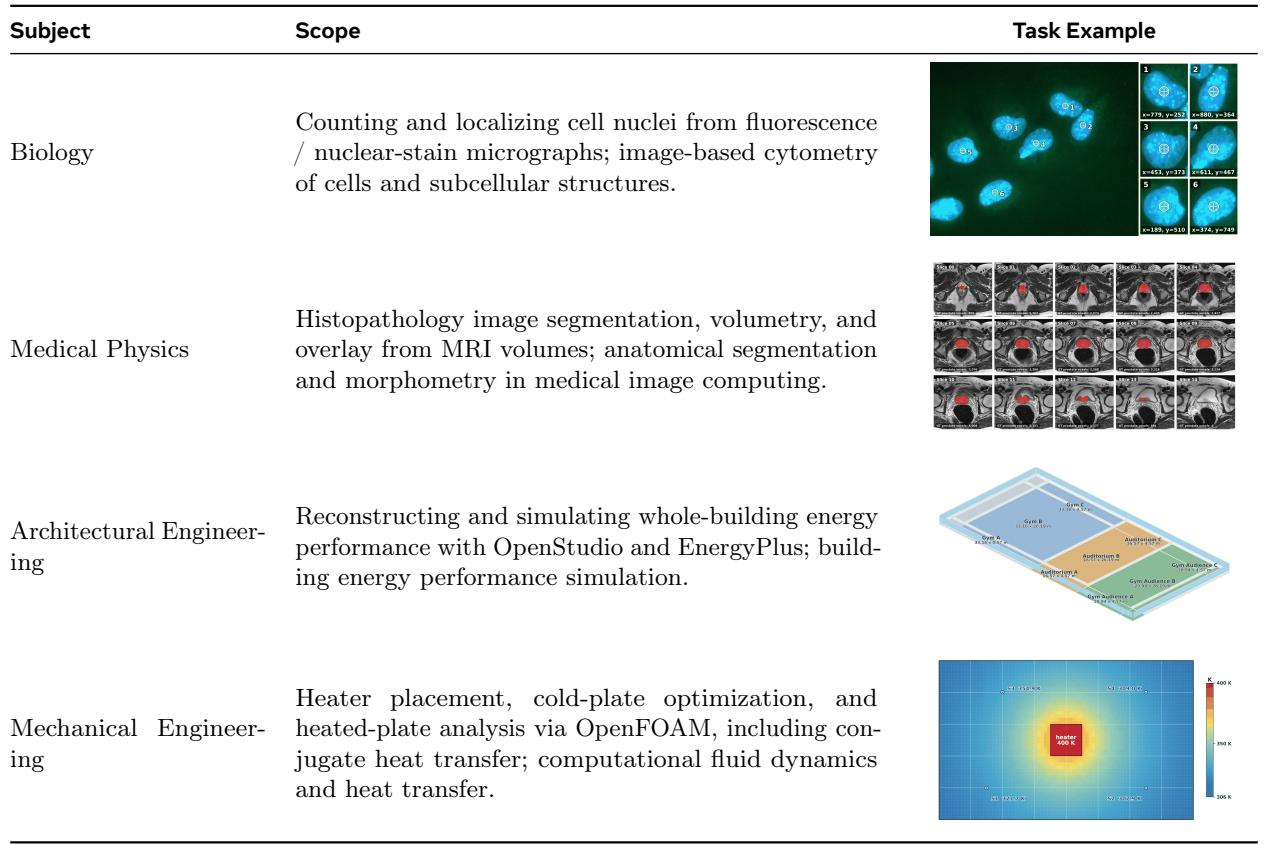
The benchmark encompasses four scientific and engineering domains—biology, medical physics, architectural engineering, and mechanical engineering—each with a distinct task scope. Tasks range from image-based cytometry and histopathology segmentation to whole-building energy simulation and computational fluid dynamics, representing real-world workflows. This diversity provides a broad testbed for evaluating AI agents on practical scientific tasks. Biology tasks focus on counting and localizing cell nuclei from fluorescence and nuclear-stain micrographs, including image-based cytometry of cells and subcellular structures. Architectural engineering involves reconstructing and simulating whole-building energy performance using OpenStudio and EnergyPlus.
Fixing the agent scaffold to Terminus-2, the top three models (GPT-5.5, Claude Opus 4.8, and Claude Opus 4.7) achieve average success rates within a narrow 58–60% range, but Claude Opus 4.8 is markedly more consistent, solving all five attempts on 42.5% of tasks versus 31.7% for GPT-5.5. A clear capability hierarchy emerges within the Claude family, from Opus 4.8 (59.7%) down to Haiku 4.5 (23.9%). When each agent is paired with its best model, Claude Code with Claude Opus 4.8 reaches 65.8%, while the leading scaffolds all fall within a 5.7-percentage-point band, suggesting that strong frontier models can deliver competitive results across diverse agent implementations. On the Terminus-2 scaffold, GPT-5.5 and Claude Opus 4.8 are nearly tied in average success rate, but Opus 4.8 solves all five seeds on 42.5% of tasks, substantially outperforming GPT-5.5’s 31.7% all-5 rate. The best agent-model combination, Claude Code with Claude Opus 4.8, achieves a 65.8% success rate, only 5.7 points above the basic Terminus-2 with GPT-5.5, indicating that agent scaffold tuning provides a modest but meaningful edge.
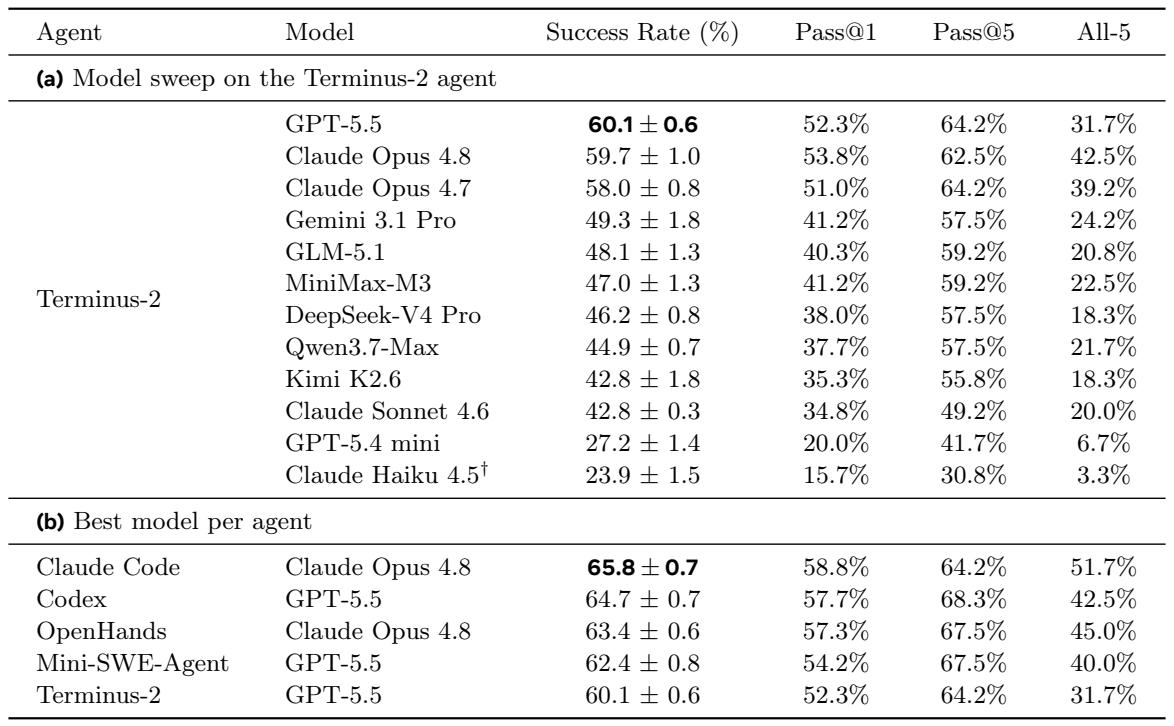
When averaged across three open-source agent scaffolds, GPT-5.5 and Claude Opus 4.8 achieve similar success rates (61.3% vs. 60.2%), but this small gap hides large scaffold-dependent variation. GPT-5.5 leads by 5 points with Mini-SWE-Agent, whereas Opus 4.8 leads by 2 points with OpenHands, and the two are nearly tied under Terminus-2, demonstrating that relative model performance is not invariant to the agent harness. The ranking of GPT-5.5 and Claude Opus 4.8 flips depending on the agent scaffold, with each model performing best on a different harness. Under Terminus-2 the two models are effectively tied, separated by only 0.4 percentage points. The choice of agent scaffold can have an impact comparable to the choice of underlying model, so single-scaffold comparisons may misrepresent relative model capabilities.
A new terminal-based benchmark fills the evaluation gap for office and web tasks while also covering diverse scientific domains such as biology and architectural engineering. Experiments show that leading models achieve similar average success rates but differ in consistency, and that the choice of agent scaffold can change model rankings, indicating that both components significantly influence capability assessments.