Command Palette
Search for a command to run...
MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
Zhengqing Yuan Hanchi Sun Lichao Sun Yanfang Ye
Abstract
We present MegaTrain, a memory-centric system that efficiently trains 100B+ parameter large language models at full precision on a single GPU. Unlike traditional GPU-centric systems, MegaTrain stores parameters and optimizer states in host memory (CPU memory) and treats GPUs as transient compute engines. For each layer, we stream parameters in and compute gradients out, minimizing persistent device state. To battle the CPU-GPU bandwidth bottleneck, we adopt two key optimizations. 1) We introduce a pipelined double-buffered execution engine that overlaps parameter prefetching, computation, and gradient offloading across multiple CUDA streams, enabling continuous GPU execution. 2) We replace persistent autograd graphs with stateless layer templates, binding weights dynamically as they stream in, eliminating persistent graph metadata while providing flexibility in scheduling. On a single H200 GPU with 1.5TB host memory, MegaTrain reliably trains models up to 120B parameters. It also achieves 1.84× the training throughput of DeepSpeed ZeRO-3 with CPU offloading when training 14B models. MegaTrain also enables 7B model training with 512k token context on a single GH200.
One-sentence Summary
Researchers from the University of Notre Dame and Lehigh University propose MegaTrain, a memory-centric system that trains 100B+ parameter large language models at full precision on a single H200 GPU with 1.5TB host memory by offloading parameters and optimizer states to host memory and streaming layers, employing a pipelined double-buffered execution engine with stateless layer templates to overlap computation and data movement, achieving 1.84× the training throughput of DeepSpeed ZeRO-3 with CPU offloading for 14B models and enabling 7B model training with 512k token context on a single GH200.
Key Contributions
- MegaTrain is a memory-centric training system that stores all parameters and optimizer states in host CPU memory and treats GPUs as transient compute engines, enabling full-precision training of models up to 120B parameters on a single H200 GPU. It achieves 1.84× the training throughput of DeepSpeed ZeRO-3 with CPU offloading for 14B models and supports 7B model training with 512k token contexts on a single GH200.
- A pipelined double-buffered execution engine overlaps parameter prefetching, layer computation, and gradient offloading across multiple CUDA streams, hiding CPU–GPU transfer latency and keeping the GPU continuously utilized during training.
- Stateless layer templates replace persistent autograd graphs by dynamically binding weights as they stream in, eliminating the memory overhead of graph metadata and reducing GPU memory usage to a per-layer footprint.
Introduction
As large language models scale to hundreds of billions of parameters, the focus of innovation shifts from pretraining to memory-bound post-training workloads such as instruction tuning and alignment. These tasks are computationally lightweight enough to run on a single node, but they still require loading full model parameters and optimizer states into GPU memory, putting them out of reach for most practitioners who lack high-memory GPUs. Existing offloading systems like ZeRO-Offload use host memory as a temporary spill buffer while the GPU remains the primary parameter host, underutilizing the memory hierarchy and leaving persistent states pinned in device memory.
The authors present MegaTrain, a memory-centric training system that inverts this relationship by making host memory the authoritative store for parameters and optimizer states while GPUs serve only as transient compute engines. Parameters are streamed into GPU buffers on demand during forward and backward passes and immediately released, with a block-wise recomputation strategy keeping activation memory bounded. A pipelined double-buffered execution engine overlaps parameter streaming with computation, and stateless layer templates eliminate the memory overhead of persistent autograd graphs. This design decouples model scale from GPU memory capacity, enabling full-precision training of 100B+ parameter models on a single GPU with higher throughput than existing offloading baselines.
Dataset
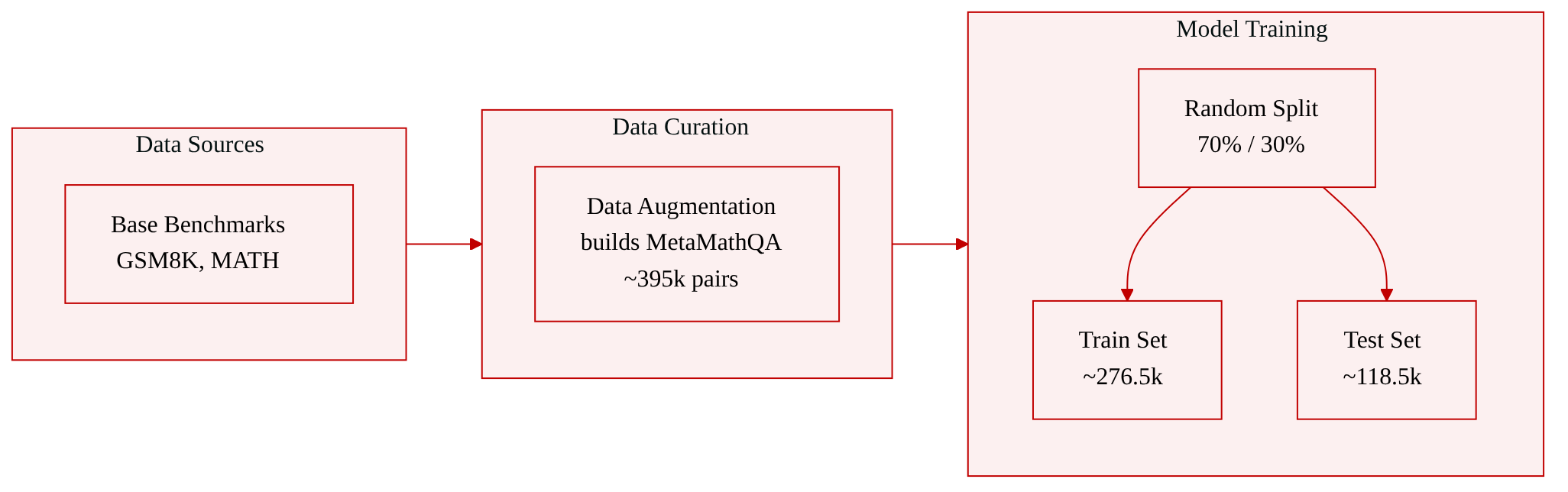
The authors use the MetaMathQA benchmark to evaluate model accuracy on mathematical reasoning. This dataset contains roughly 395,000 English math problem-answer pairs, built by applying data augmentation to base benchmarks such as GSM8K and MATH. The result is a collection of diverse, multi-step word problems with deterministic ground-truth answers.
Key details about the dataset and its usage:
- The full dataset is randomly split into 70% training (about 276,500 samples) and 30% testing (about 118,500 samples).
- The authors report exact-match accuracy: a prediction is correct only when the model’s final answer exactly matches the reference answer.
- The paper focuses on how the data is used for evaluation rather than on additional filtering or preprocessing steps. No cropping strategy, metadata construction, or mixture ratios are described beyond the train/test split.
Method
The authors designMegaTrain as a memory-centric training system that inverts the conventional relationship between host and device memory. Host memory serves as the primary store for all persistent training state, including model parameters, optimizer states, and accumulated gradients, while device memory acts solely as a transient compute cache.
In the execution workflow, the system streams parameters from host memory into a weight buffer in device memory layer by layer during the forward phase. Activations are checkpointed periodically and kept in device memory. During the streaming backward phase, the system proceeds in reverse block order. It starts from the checkpoint and streams parameters to recompute activations, then streams parameters in reverse order to compute backward passes, immediately offloading each layer's gradients to host memory. This block-wise recomputation trades extra forward compute for bounded memory. Finally, the optimizer update phase executes entirely on the CPU. Since optimizer updates are compute-light but I/O-intensive, executing them on the CPU avoids the costly round-trip of streaming optimizer states to the GPU and back, matching or exceeding GPU throughput while eliminating significant data movement.
To hide data movement latency behind computation, the authors orchestrate three concurrent CUDA streams: compute (Scomp), weight transfer (SH2D), and gradient transfer (SD2H).
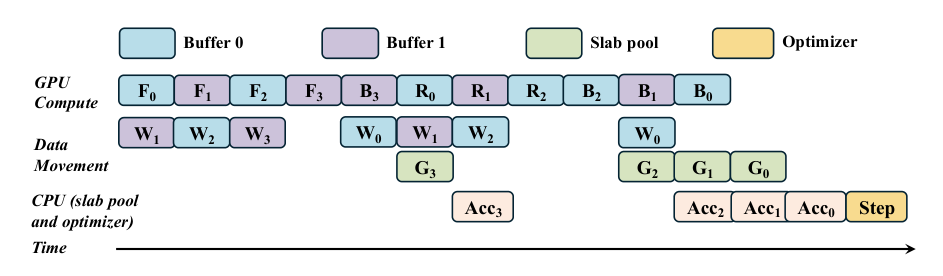
As shown in the framework diagram, the system employs double-buffered staging to achieve continuous GPU execution. It maintains two sets of staging buffers in both CPU and GPU domains, enabling a ping-pong prefetching strategy. The compute stream executes a layer using one buffer while the weight-transfer stream concurrently packs and streams the next layer's weights into the other buffer. This overlapping ensures that GPU compute units never stall waiting for parameters. The same double-buffering applies during the backward pass. While gradients are being evacuated, parameters for the next layer are already streaming in. Separating the gradient transfer stream from the compute stream is critical for asynchronous gradient evacuation, preventing device-to-host latency from entering the critical path. Coordination across these streams is governed by lightweight CUDA events, such as a Weights-Ready event recorded after weight transfer completes, which the compute stream waits on before binding the layer.
To maximize PCIe bandwidth, the authors employ layer-contiguous tiling. All states for each layer, including BF16 weights, BF16 gradients, and FP32 Adam moments, are packed into a single contiguous block aligned to 4KB pages. This enables single-burst DMA transfers. Rather than pinning the entire model, which would exhaust host physical memory, the system allocates a small pool of pinned staging buffers. A dedicated CPU worker performs just-in-time packing from the pageable layer store to a pinned slab, from which DMA transfers proceed at full bandwidth.
Finally, the authors adopt a stateless execution model that decouples mathematical structure from physical data. Standard autograd graphs assume parameters and activations persist on the GPU, which is inapplicable under layerwise streaming. Instead, the system employs a stateless template pool where each template encapsulates the CUDA kernels for blocks but holds no persistent weight pointers. Before execution, a Bind primitive dynamically maps views from the streaming buffer to the template's input slots. This ping-pong binding allows one layer to execute on a template while the next is being bound to another, eliminating weight preparation latency. The runtime preserves an explicit dispatch path instead of relying on CUDA graph capture, enabling dynamic buffer assignment and precise tensor lifecycle management essential for deterministic memory bounds.
Experiment
The evaluation uses MetaMathQA for accuracy testing across GH200 and H200 systems, spanning models from 7B to 120B parameters. MegaTrain demonstrates that host memory, not device memory, is the true scaling boundary, maintaining a flat memory growth curve and high sustained TFLOPS while competing systems exhibit near-exponential memory demand and throughput collapse. Ablation studies confirm that double buffering and balanced recomputation granularity are critical for performance, while depth and width scalability experiments show MegaTrain scales to 180 layers and 5× width where baselines run out of memory. Long-context tests reveal stable memory usage and improved compute efficiency up to 512K sequence length, and verification on PCIe-based A100, RTX A6000, and RTX 3090 systems confirms consistent speedups and the ability to train large models on consumer-grade hardware where other offloading methods fail.
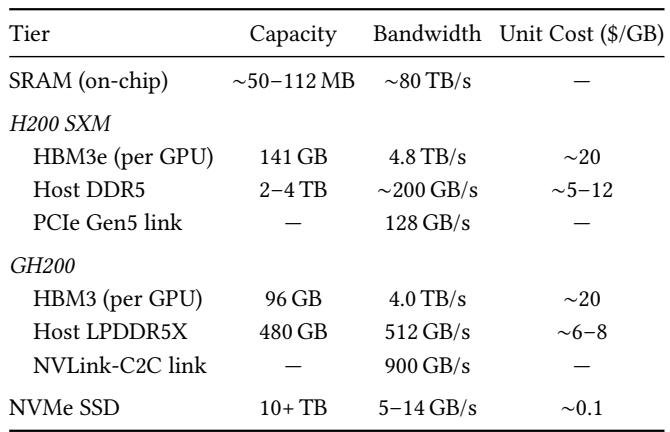
Modern GPU servers present a four-tier memory hierarchy where faster tiers are smaller and more expensive, with the CPU–GPU interconnect being a critical differentiator. The GH200's NVLink-C2C provides roughly seven times the bandwidth of the H200's PCIe Gen5 link, fundamentally altering which data offloading strategies are practical. MegaTrain exploits this by treating host memory as the primary store and device memory as a transient cache, enabling high throughput even on memory-constrained devices. On-chip SRAM delivers the highest bandwidth at roughly 80 TB/s but is limited to tens of megabytes in capacity. HBM device memory provides terabytes-per-second bandwidth and hundreds of gigabytes of capacity, serving as the primary compute memory. Host memory offers terabytes of capacity at hundreds of gigabytes per second and is approximately ten times cheaper per byte than HBM. The GH200 co-packages 480 GB of LPDDR5X and connects it via NVLink-C2C at 900 GB/s, a roughly sevenfold interconnect advantage over the H200's PCIe Gen5 at 128 GB/s.
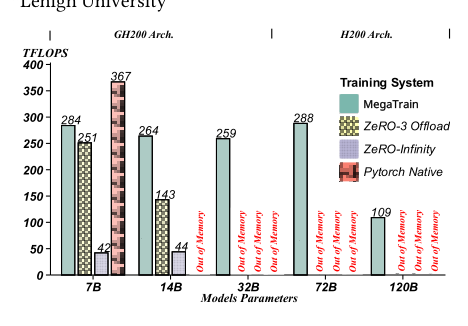
The evaluated model configurations span dense architectures from 7B to 72B parameters and one 120B mixture-of-experts model, with hidden sizes ranging from 3584 to 8192 and depths from 28 to 80 layers. MegaTrain demonstrates consistent throughput advantages over offloading baselines across datacenter and consumer GPUs, and it successfully trains larger models on memory-constrained devices where baselines fail with out-of-memory errors. MegaTrain achieves up to 12.20× higher TFLOPS than ZeRO-3 CPU offloading on an A100 system when training a 14B model. On a 24 GB RTX 3090, MegaTrain scales to 14B-parameter training while ZeRO-3 fails due to out-of-memory errors. MegaTrain sustains over 93% device memory utilization on an RTX A6000 across batch sizes from 9 to 15. Even without NVLink-class interconnects, MegaTrain trains 32B models on an A100 where both Gemini and ZeRO-3 encounter out-of-memory failures.
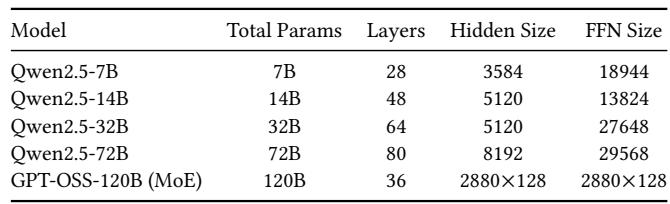
Across 7B and 14B scales, MegaTrain delivers final accuracy virtually identical to ZeRO-3 Offload, ZeRO Infinity, and PyTorch Native (where available). The negligible differences confirm that the system's memory and compute optimizations introduce no numerical drift or training instability, preserving standard full-GPU correctness. MegaTrain's 7B accuracy is within 0.06% of ZeRO-3 Offload and ZeRO Infinity, and its 14B accuracy is within 0.16%, showing near-identical convergence. PyTorch Native does not complete 14B training, while MegaTrain scales to that size and still matches the accuracy of all offloading baselines.
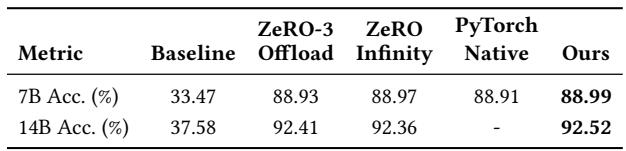
An ablation study on MegaTrain shows that overlapping parameter prefetching, computation, and gradient offloading via double buffering is critical for high throughput, as its removal causes a 31.3% drop in TFLOPS. Other components like the gradient slab pool have a minor impact, while reducing recomputation granularity increases memory pressure and lowers both maximum batch size and throughput. Removing double buffering causes the largest throughput degradation, reducing performance from 266.3 TFLOPS to 182.9 TFLOPS. Disabling the gradient slab pool results in only a minor throughput decrease to 257.6 TFLOPS, indicating it is not a primary performance driver. Setting the checkpoint interval to 1 reduces the maximum feasible batch size from 96 to 32 and lowers throughput to 184.2 TFLOPS due to increased activation memory pressure.
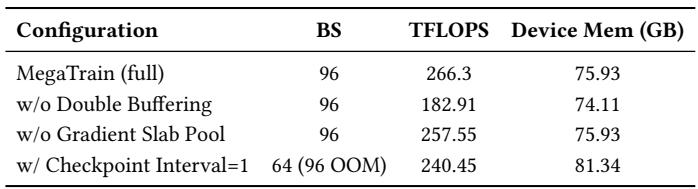
When model depth increases with constant device memory, MegaTrain sustains high throughput, dropping only 20.1% from 28 to 180 layers, while offloading baselines suffer severe performance collapse and out-of-memory failures beyond 84 layers. MegaTrain also uses far less host memory at every depth, enabling training of over 43 billion parameters on a single GPU with just 3.83 GB of device memory. MegaTrain throughput declines only 20.1% from 28 to 180 layers (284 to 227 TFLOPS), while FSDP throughput drops to 43 TFLOPS at 56 layers and ZeRO-3 degrades to 43 TFLOPS at 84 layers before both run out of memory. At 84 layers, FSDP host memory reaches 518 GB, 2.50 times more than MegaTrain's 207 GB; MegaTrain continues scaling to 180 layers using 418 GB.
The evaluation examines MegaTrain's performance across a four-tier GPU memory hierarchy, where the GH200's NVLink-C2C interconnect provides a sevenfold bandwidth advantage over PCIe Gen5, enabling effective use of host memory as primary storage. MegaTrain achieves up to 12.20× higher throughput than ZeRO-3 offloading on an A100, scales to 14B-parameter training on a 24 GB RTX 3090 where baselines fail, and maintains over 93% device memory utilization, while preserving final accuracy within 0.16% of offloading baselines. An ablation study reveals that double buffering for overlapping prefetch, computation, and offloading is critical, as its removal causes a 31.3% throughput drop, and MegaTrain sustains high throughput even as model depth increases to 180 layers, whereas baselines encounter out-of-memory failures beyond 84 layers. Overall, MegaTrain enables training of models over 43 billion parameters on a single GPU with limited device memory, demonstrating robust scalability and efficiency across diverse hardware configurations.