Command Palette
Search for a command to run...
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
Ted Zadouri Markus Hoehnerbach Jay Shah Timmy Liu Vijay Thakkar Tri Dao
Abstract
Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. While FLASHATTENTION-3 optimized attention for Hopper GPUs through asynchronous execution and warp specialization, it primarily targets the H100 architecture. The AI industry has rapidly transitioned to deploying Blackwell-based systems such as the B200 and GB200, which exhibit fundamentally different performance characteristics due to asymmetric hardware scaling: tensor core throughput doubles while other functional units (shared memory bandwidth, exponential units) scale more slowly or remain unchanged. We develop several techniques to address these shifting bottlenecks on Blackwell GPUs: (1) redesigned pipelines that exploit fully asynchronous MMA operations and larger tile sizes, (2) software-emulated exponential and conditional softmax rescaling that reduces non-matmul operations, and (3) leveraging tensor memory and the 2-CTA MMA mode to reduce shared memory traffic and atomic adds in the backward pass. We demonstrate that our method, FLASHATTENTION-4, achieves up to 1.3× speedup over cuDNN 9.13 and 2.7× over Triton on B200 GPUs with BF16, reaching up to 1613 TFLOPs/s (71% utilization).
One-sentence Summary
FlashAttention-4, a co-design of algorithm and kernel pipelining for asymmetric hardware scaling on Blackwell GPUs, employs fully asynchronous MMA operations with larger tile sizes, software-emulated exponential and conditional softmax rescaling, and tensor memory with 2-CTA MMA mode to reduce shared memory traffic and atomic adds, delivering up to 1.3× speedup over cuDNN 9.13 and 2.7× over Triton on B200 GPUs with BF16, reaching 1613 TFLOPs/s (71% utilization).
Key Contributions
- Redesigned pipelines exploit fully asynchronous MMA operations and larger tile sizes to address Blackwell GPUs’ asymmetric scaling, where tensor core throughput doubles while other functional units scale more slowly.
- Software-emulated exponential and conditional softmax rescaling reduces non-matmul operations, easing the bottleneck imposed by the slower exponential functional units.
- The backward pass leverages tensor memory and the 2-CTA MMA mode to cut shared memory traffic and atomic adds; together, these innovations enable FLASHATTENTION-4 to reach 1613 TFLOPs/s (71% utilization), a 1.3× speedup over cuDNN 9.13 and 2.7× over Triton on B200 with BF16.
Introduction
The attention mechanism is a critical performance bottleneck in large language models and long-context Transformers. Prior work, FlashAttention-3, introduced asynchronous execution and warp specialization to optimize attention on Hopper (H100) GPUs, but these techniques do not directly address the new Blackwell architecture. In Blackwell GPUs like the B200 and GB200, tensor core throughput has doubled while shared memory bandwidth and exponential units scale far more modestly, creating asymmetric hardware bottlenecks that stall earlier algorithms. The authors introduce FlashAttention-4, which co-designs algorithms and kernel pipelining for this new balance. They present redesigned pipelines that exploit fully asynchronous matrix multiply-accumulate operations and larger tile sizes, software-emulated exponentials and conditional softmax rescaling to cut non-matmul work, and the use of tensor memory with 2-CTA MMA mode to reduce shared memory traffic and atomic adds in the backward pass, achieving up to 1.3× speedup over cuDNN and 2.7× over Triton on B200.
Method
The authors propose FlashAttention-4, a co-designed algorithm and kernel implementation tailored for the NVIDIA Blackwell architecture (B200 and GB200). Unlike previous generations where matrix multiplication units were the primary bottleneck, Blackwell exhibits asymmetric scaling: tensor core throughput has doubled compared to Hopper, while shared memory bandwidth and exponential unit throughput remain largely unchanged. Consequently, non-matmul operations such as softmax and shared memory traffic become the dominant bottlenecks. FlashAttention-4 addresses these shifts through a redesigned pipeline, software-emulated exponentials, and novel memory management strategies.
The authors begin with a roofline analysis of the attention forward pass, revealing that for typical tile configurations, shared memory traffic and exponential operations dominate execution time. To mitigate this, they introduce a new pipeline that maximizes overlap between tensor core operations and softmax computation.
As shown in the figure below:
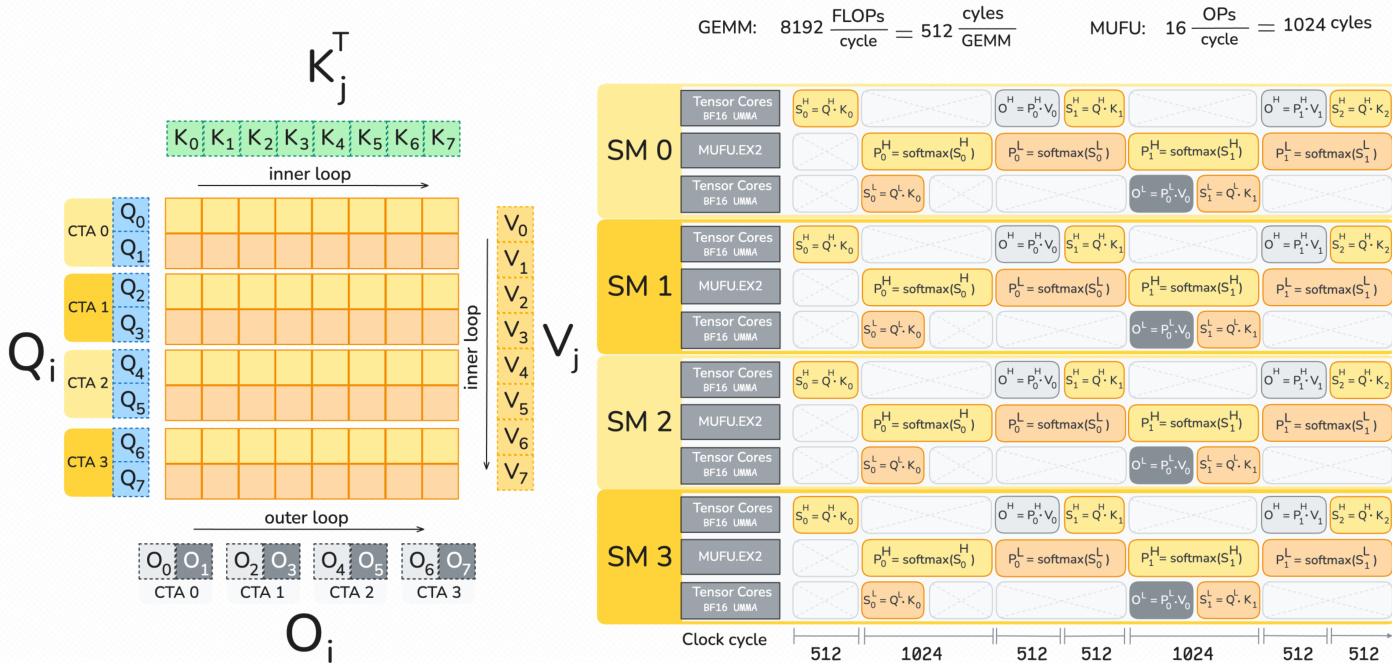
The authors leverage a ping-pong schedule where two tiles of the output are computed per thread block. While one tile undergoes tensor core operations, the other computes softmax. Unlike Hopper, where accumulators are held in registers, Blackwell tensor cores write outputs directly to Tensor Memory (TMEM). This allows the authors to decouple the rescaling of the output to a separate correction warpgroup, removing it from the critical path. The pipeline utilizes two warpgroups for softmax computation, explicitly synchronized to avoid overlap during the exponential computation phase.
To further address the exponential unit bottleneck, the authors implement a software emulation of the exponential function using floating-point FMA units. Since the multifunction unit (MUFU) has significantly lower throughput compared to tensor cores, this emulation distributes the workload. They use a polynomial approximation for the fractional part of the exponent and bit manipulation for the integer part. To balance throughput and register pressure, this emulation is applied to only a subset of entries in each softmax row, with the rest computed via hardware MUFU.
Additionally, the authors introduce conditional softmax rescaling. In standard FlashAttention, the intermediate output is rescaled whenever a new maximum is found. FlashAttention-4 skips this rescaling step if the difference between the current maximum and the previous maximum is below a threshold τ. This reduces unnecessary vector multiplications while maintaining numerical accuracy through a final normalization step.
For the backward pass, the roofline analysis indicates that shared memory traffic is the primary bottleneck, exceeding MMA compute time. The backward pass involves five matrix multiply-accumulate (MMA) operations.
As shown in the figure below:
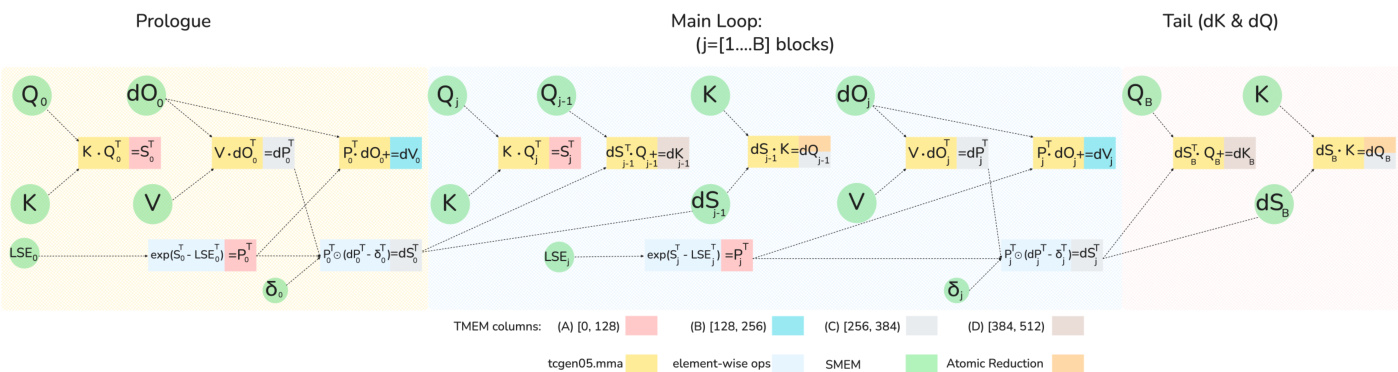
The authors design a new software pipeline to overlap these MMA operations with element-wise computations. By utilizing TMEM to store intermediate results, they can hide the latency of softmax calculations. Specifically, the dQ and dK MMA operations from the previous iteration are overlapped with the current iteration's computations.
To further reduce shared memory traffic, the authors exploit Blackwell's 2-CTA MMA mode. In this mode, a pair of Cooperative Thread Arrays (CTAs) cooperatively executes a single MMA, allowing them to partition the accumulator and operands.
As shown in the figure below:
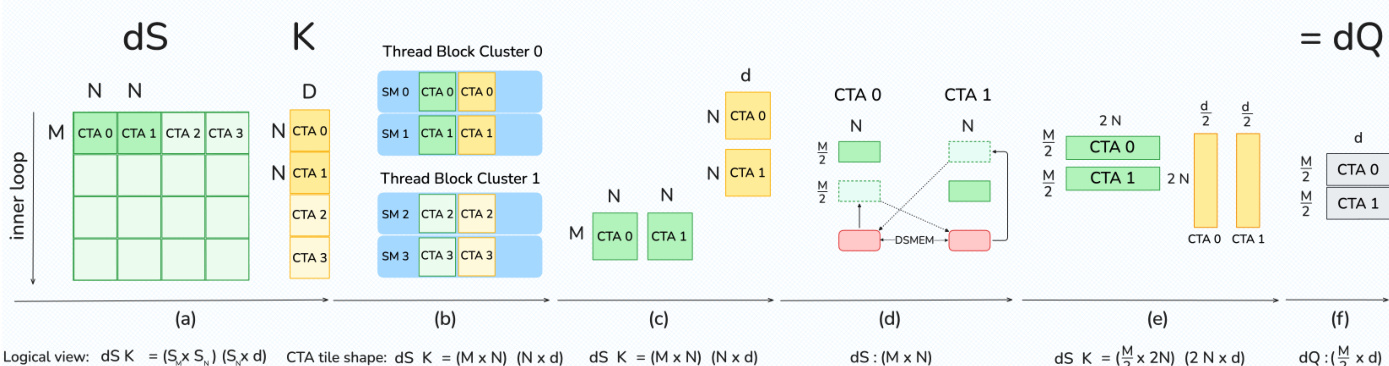
For the dQ step, the CTA pair uses Distributed Shared Memory (DSMEM) to exchange half of the dS tile. This allows each CTA to form a larger operand and run a CTA-pair UMMA with a doubled reduction dimension. This restructuring not only halves the shared memory traffic for operand B but also halves the number of global atomic reductions required for dQ, as each CTA writes only half of the tile.
To ensure reproducibility for reinforcement learning applications, the authors also provide a deterministic execution mode. This mode serializes global reductions using a semaphore lock, ensuring that CTAs write to common dQ tiles in a predefined order. They employ a shortest-processing-time-first schedule and CTA swizzling to minimize stalls caused by this serialization.
The authors implement Longest-Processing-Time-First (LPT) scheduling to handle load imbalance in causal masking and variable sequence length scenarios. For causal masking, they process batches as the outermost dimension and swizzle over heads to optimize L2 cache usage. For variable sequence lengths, a preprocessing kernel sorts batches according to their maximum execution time to enforce LPT order.
Finally, FlashAttention-4 is implemented entirely in CuTe-DSL embedded in Python. This approach provides full expressivity comparable to C++ templates while achieving significantly faster compile times through Just-In-Time (JIT) compilation, lowering the barrier for researchers to prototype new attention variants.
Experiment
The evaluation benchmarks FLASHATTENTION-4 on an NVIDIA B200 GPU using BF16 inputs across various sequence lengths and head dimensions, comparing it with cuDNN, Triton, and other libraries. The forward pass consistently outperforms all baselines, with particularly large improvements for causal masking due to a longest-processing-time-first scheduler, while the backward pass (including a deterministic variant) also delivers substantial speedups. FLASHATTENTION-4 achieves a high fraction of the GPU's theoretical peak throughput, and many of its optimizations have since been integrated into newer cuDNN releases.
The authors compare the numerical accuracy of various approximation techniques and data types by analyzing relative errors against a FP64 baseline. For BF16 precision, the error rates are consistent across all methods, suggesting the precision format is the limiting factor rather than the approximation algorithm. For FP32 precision, higher-degree polynomial approximations yield significantly lower errors, eventually matching the accuracy of the hardware implementation. BF16 comparisons show uniform error rates across all methods that align with the ideal conversion limit. Higher polynomial degrees substantially reduce relative error for FP32 inputs. The hardware special function unit and Degree 5 approximation achieve comparable high accuracy for FP32.

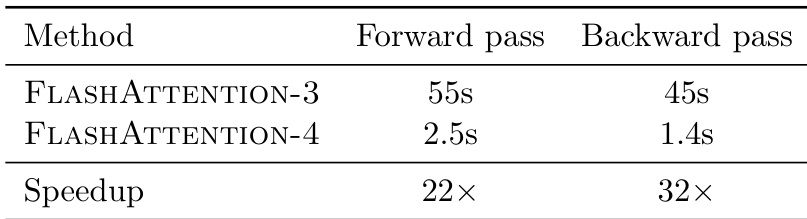
The authors compare the runtime of FlashAttention-4 against FlashAttention-3 to evaluate efficiency improvements. The results demonstrate that the newer version drastically reduces execution time for both forward and backward passes, achieving massive speedups over its predecessor. FlashAttention-4 significantly outperforms FlashAttention-3 in the forward pass, requiring a fraction of the original time. The backward pass shows an even larger relative speedup, indicating highly efficient gradient computation. The proposed method delivers substantial performance gains across both computational phases compared to the previous iteration.
The authors benchmark FlashAttention-4 against baselines like cuDNN and Triton on B200 GPUs, demonstrating consistent speedups for medium and long sequences. The resource analysis indicates that increasing the configuration size proportionally scales the requirements for MMA compute, shared memory, and exponential units. FlashAttention-4 outperforms cuDNN and Triton baselines, with larger gains observed in causal masking scenarios. Resource usage for MMA compute, shared memory, and exponential units scales linearly with the configuration size. The optimized backward pass design yields consistent speedups across long sequence lengths.

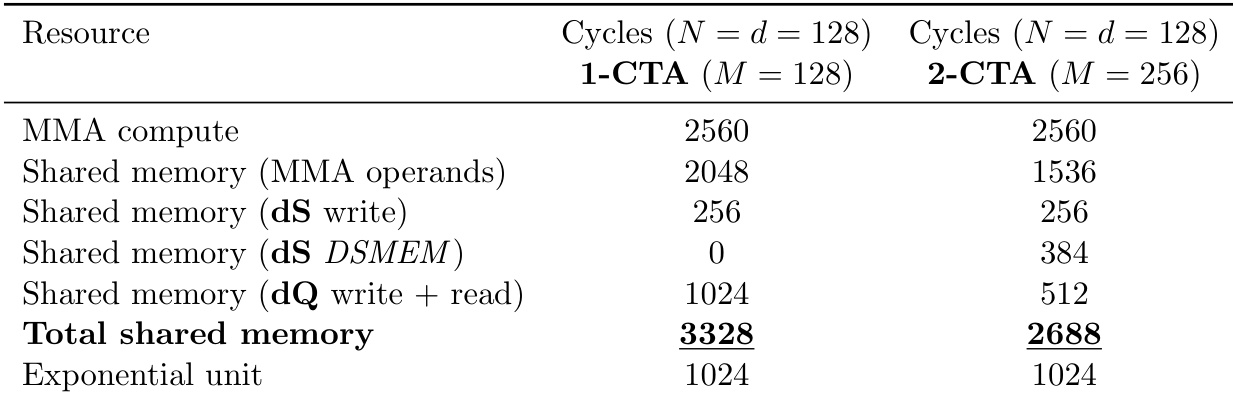
The authors compare the resource cycles of a 1-CTA and a 2-CTA configuration to demonstrate the efficiency of their backward pass implementation. Results show that the 2-CTA approach reduces the total shared memory cycles required, primarily by lowering the cycles needed for MMA operands and dQ operations. Although the 2-CTA method introduces some overhead for DSMEM, the overall shared memory cost is lower while compute cycles remain unchanged. The 2-CTA configuration achieves a lower total shared memory cycle count than the 1-CTA baseline. Compute cycles for MMA and exponential units remain constant between the two configurations. Reductions in MMA operand and dQ operation cycles offset the new DSMEM cycles in the 2-CTA setup.
Numerical accuracy experiments show that BF16 precision limits approximation error uniformly across methods, whereas FP32 benefits from higher-degree polynomials, matching hardware special-function accuracy. Performance benchmarks demonstrate that FlashAttention-4 achieves substantial speedups over FlashAttention-3 and outperforms cuDNN and Triton on B200 GPUs, with particularly large gains in causal masking scenarios. Resource analysis reveals that the 2-CTA backward pass configuration reduces shared memory cycles by lowering MMA operand and dQ operation costs, while compute cycles remain unchanged.