Command Palette
Search for a command to run...
Formalizing Latent Thoughts: Four Axioms of Thought Representation in LLMs
Formalizing Latent Thoughts: Four Axioms of Thought Representation in LLMs
Fahd Seddik Fatemeh Fard
Abstract
We introduce an axiomatic evaluation framework for latent thought representations in LLMs, comprising metrics that are independent of downstream benchmark scores and reveal representational failures that benchmark accuracy masks. Existing evaluations conflate representation quality with model capacity. Therefore, failures cannot be attributed to the representation rather than to the model that processes it. We formalize four functional axioms (Causality, Minimality, Separability, and Stability) and define a quantitative measure for each, computed directly on the representation independently of downstream accuracy. We audit open-weight LLMs across 23 reasoning tasks (e.g., Spatial Reasoning, Factual QA). We find that no candidate satisfies all four axioms simultaneously, that the representations distinguish task type reliably but cannot distinguish between two questions within the same task, and that the representations encode little information beyond what is already present in the input embedding. The failure is consistent across dense, reasoning-distilled, and RL-trained model families, indicating that the gap is structural rather than a property of model size or training procedure.
One-sentence Summary
Researchers from the University of British Columbia formalize four functional axioms—Causality, Minimality, Separability, and Stability—with corresponding quantitative measures to audit latent thought representations directly, and on 23 reasoning tasks (e.g., Spatial Reasoning, Factual QA) find that no open-weight model satisfies all axioms, as representations distinguish tasks cleanly but fail to separate intra-task questions and encode little information beyond the input embedding, indicating a structural gap across dense, reasoning-distilled, and RL-trained model families.
Key Contributions
- An axiomatic evaluation framework for latent thought representations in LLMs formalizes four axioms (Causality, Minimality, Separability, Stability) with quantitative metrics computed directly on representations, independent of downstream benchmark accuracy.
- An empirical audit across 23 reasoning tasks and five open-weight LLMs reveals that no existing representation satisfies all four axioms, distinguishes task types but not individual questions within a task, and encodes minimal information beyond the input embedding.
- The representational failures are consistent across dense, reasoning-distilled, and RL-trained models, indicating a structural gap, and the framework enables decomposing reasoning accuracy changes into specific axiomatic properties for targeted representation design.
Introduction
Large language models increasingly use continuous latent vectors instead of explicit chain-of-thought tokens for reasoning, motivated by efficiency and accuracy gains. However, prior work evaluates these continuous thought representations solely through downstream task accuracy, lacking a formal definition of what a valid thought representation should encode and how to measure its quality independently of the final answer. The authors propose an axiomatic framework that defines four necessary functional properties: Causality, Minimality, Separability, and Stability. They introduce corresponding quantitative metrics that can be computed directly on the source LLM without retraining, enabling a principled audit of thought representations. Applying this protocol to several candidate methods across multiple LLMs reveals a representational collapse on per-question identity that downstream accuracy obscures, establishing a new diagnostic toolkit for future research.
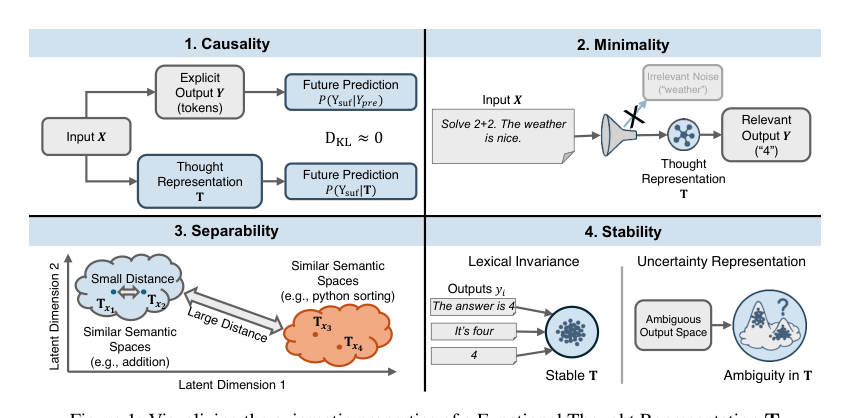
Method
The authorspropose an axiomatic framework to characterize a Functional Thought Representation T, defined not as a communicable linguistic artifact but as a latent state that mediates the transformation from an input space X to a semantic output space S. To rigorously evaluate these representations, they first establish a criterion for semantic equivalence. Two sequences y,y′∈Y are semantically equivalent, denoted y∼semy′, if a semantic mapping function satisfies Φ(y)=Φ(y′). This semantic manifold S is equipped with a metric dS, which is computationally approximated using the cosine similarity between high-dimensional text embeddings.
A robust thought representation must satisfy four axiomatic properties: Causality, Minimality, Separability, and Stability.
1. Causality The output sequence y is partitioned into a reasoning prefix ypre and an answer suffix ysuf. For T to be a valid thought representation derived from ypre, it must functionally substitute the explicit tokens of ypre within the model's computational graph. This means conditioning on T should yield a predictive distribution over ysuf indistinguishable from conditioning on ypre. The authors quantify this via the Causality Error: Causality Error=DKL(P(ysuf∣ypre)∥P(ysuf∣T)) A lower value indicates that T successfully encapsulates the causal effect of the reasoning prefix on subsequent generation.
2. Minimality Aligning with the Information Bottleneck principle, an optimal T must compress the input X while retaining maximum relevance to the output distribution Y. It should filter out nuisance variables that do not contribute to the generation of high-probability semantic outputs. The ideal objective minimizes I(X;T) subject to a constraint on I(T;Y). Since the mutual information terms are intractable, the authors construct a cross-entropy surrogate that preserves the ranking of the Lagrangian at β=2: ΔIB=CE(X∣Y,T)−CE(Y∣T) A larger ΔIB signifies a representation that is simultaneously relevant and minimal.
3. Separability This axiom defines the functional injectivity of the mapping from semantic content to the latent space. The representation must contain sufficient topological structure to distinguish between semantically nonequivalent output distributions using a bounded capacity projection. For inputs x1,x2 inducing disjoint high-probability semantic spaces, their representations Tx1 and Tx2 must be resolvable by an optimal semantic projection ϕ:T→S such that dS(ϕ(Tx1),ϕ(Tx2))>δ. To quantify this, the authors instantiate ϕ as a learned binary discriminator fdisc(T,Y), realized as a trainable linear projection mapping T into the embedding space of a frozen LLM backbone, followed by a classification head. Classification accuracy serves as the metric for separability.
4. Stability The representation must be invariant to surface-level lexical variations and robust to sampling stochasticity. Rather than encoding a single realization, T should encode the parameters of the semantic distribution P(S∣x). This requires Mode Collapse Resistance, where T reflects the entropy of P(Y∣x), and Lexical Invariance, where semantically equivalent sibling outputs induce approximately identical representations. The authors quantify distributional uncertainty via semantic entropy Hx, computed by binarizing pairwise cosine similarities between output embeddings to form semantic equivalence classes. To measure whether T linearly encodes this property, they adopt a difference-of-means probe and report the cross-validated AUROC for predicting Hx>0, yielding a Distributional Consistency Score.
Experiment
Using a shared frozen-model probe across five open-weight LLMs and beam-search generations, the study evaluates thought representations (last input token, soft tokens, latent thinking) on causality, minimality, separability, and stability. No candidate consistently outperforms the simple input prompt embedding on any axis, with iterative thinking families degrading as step count increases and within-task separability collapsing to near-random except for output embeddings. These representation-level gaps persist even when models achieve strong benchmark accuracy, revealing that current reasoning-time computation does not reliably encode additional task-relevant information beyond the prompt.
Across multiple language models, no thought representation candidate consistently exceeds a simple input embedding reference on causality, minimality, separability, or stability. The output embedding stands alone in surpassing a random baseline for within-task separability, while iterative thinking approaches show mixed results, often improving minimality but suffering degradation as step counts increase. No thought representation family outperforms the input embedding baseline on all four axioms simultaneously when averaged across the tested language models. Only the output embedding clears the random baseline on within-task separability, and iterative thinking methods tend to fall back as the number of reasoning steps grows.

Across tested language models and reasoning tasks, no thought representation candidate consistently surpasses the simple input prompt embedding on all four evaluation axes. Output embeddings achieve strong within-task separability but fail on minimality, while iterative thinking methods improve minimality but degrade with additional steps and cannot match the input embedding on every axis. The evaluation protocol reveals a disconnect between downstream benchmark accuracy and the geometric quality of internal thought representations. Only output embeddings clear the random baseline on within-task separability. Iterative thinking families exceed the input embedding reference on minimality, whereas the last input token falls below it. Adding Gumbel noise to soft tokens reduces stability, aligning with the expected role of noise in exploration. When averaged across models, no candidate representation beats the input embedding reference on any single axis. Iterative thinking variants consistently degrade in representation quality as the number of thinking steps increases.

Across the five source LLMs spanning dense, sparse-MoE, reasoning-distilled, and native-RL paradigms, no candidate thought representation consistently exceeds the input prompt embedding on any evaluation axis. Iterative thinking methods degrade as step count grows and fail to simultaneously achieve strong within-task clustering, wide task separability, and high within-question stability. The output embedding clears the random baseline on separability but is unsuitable as a minimality reference, while last input token representations lag behind iterative approaches on minimality. No representation outperforms the input embedding on all four axes when results are averaged across LLMs. Iterative thinking families (soft tokens, latent thinking) surpass last input token on minimality but lose performance as the number of thinking steps increases. Only the output embedding exceeds the random baseline on within-task separability; its construction violates the assumptions of the minimality decomposition. On stability, soft tokens with Gumbel noise are the only outlier, falling below the input embedding reference and other iterative methods. The output embedding and input embedding produce comparable perturbation effects on the continuation distribution, leaving neither dominant on the causality axis.
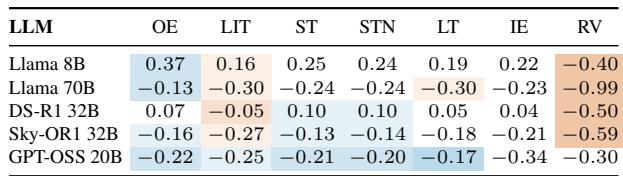
The Minimality metric measures how well a representation compresses input-specific details while retaining output-relevant information, with higher values indicating better compression. The Output Embedding achieves the highest scores but is not interpretable on this axis due to how it is constructed. Among the remaining candidates, no representation consistently surpasses the Input Embedding reference; Last Input Token typically scores below it, while soft-thinking and last-token variants perform near or slightly above it, with substantial variation across source models. Output Embedding attains the highest Minimality values but is excluded from valid comparison because its construction violates the decomposition assumption. Last Input Token scores below Input Embedding on most models, signaling that it carries input-specific information not essential for output prediction. Soft-thinking variants (ST, STN) and Last Token are at or slightly above the Input Embedding level, with no consistent advantage over the prompt representation.
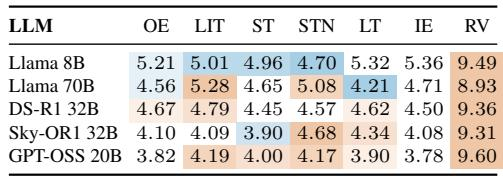
All thought representations achieve causality KL divergence far below the random vector baseline, confirming they encode continuation-relevant information. However, none consistently surpasses the input embedding reference, indicating they carry no additional causal information beyond what the prompt already provides. The best-performing variant varies across models, with differences from the input embedding remaining small and inconsistent. Every thought representation yields KL divergence substantially lower than the random vector baseline (roughly 4–5 nats vs. 9.3–9.6 nats), demonstrating they capture continuation-relevant structure. No representation family consistently beats the input embedding; some variants occasionally score slightly lower, but the ranking flips across models and the margins are small, showing no reliable causal advantage.
Across several language models, the experiments evaluate thought representation candidates on four axioms (causality, minimality, separability, stability), comparing them to an input embedding baseline. No representation outperforms the baseline on all axes; output embeddings achieve strong within-task separability but are excluded from minimality comparisons, while iterative thinking methods can improve minimality yet degrade as step counts increase. All representations capture continuation-relevant structure but never add causal information beyond the prompt, and adding Gumbel noise reduces stability. Overall, the geometric quality of thought representations does not consistently surpass that of a simple input prompt, and downstream accuracy does not imply better representation properties.