HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation

ViQ: Text-Aligned Visual Quantized Representations at Any Resolution
























DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation
ViQ: Text-Aligned Visual Quantized Representations at Any Resolution
The Verification Horizon: No Silver Bullet for Coding Agent Rewards
Qwen-Image-Agent: Bridging the Context Gap in Real-World Image Generation
OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
In-Context World Modeling for Robotic Control
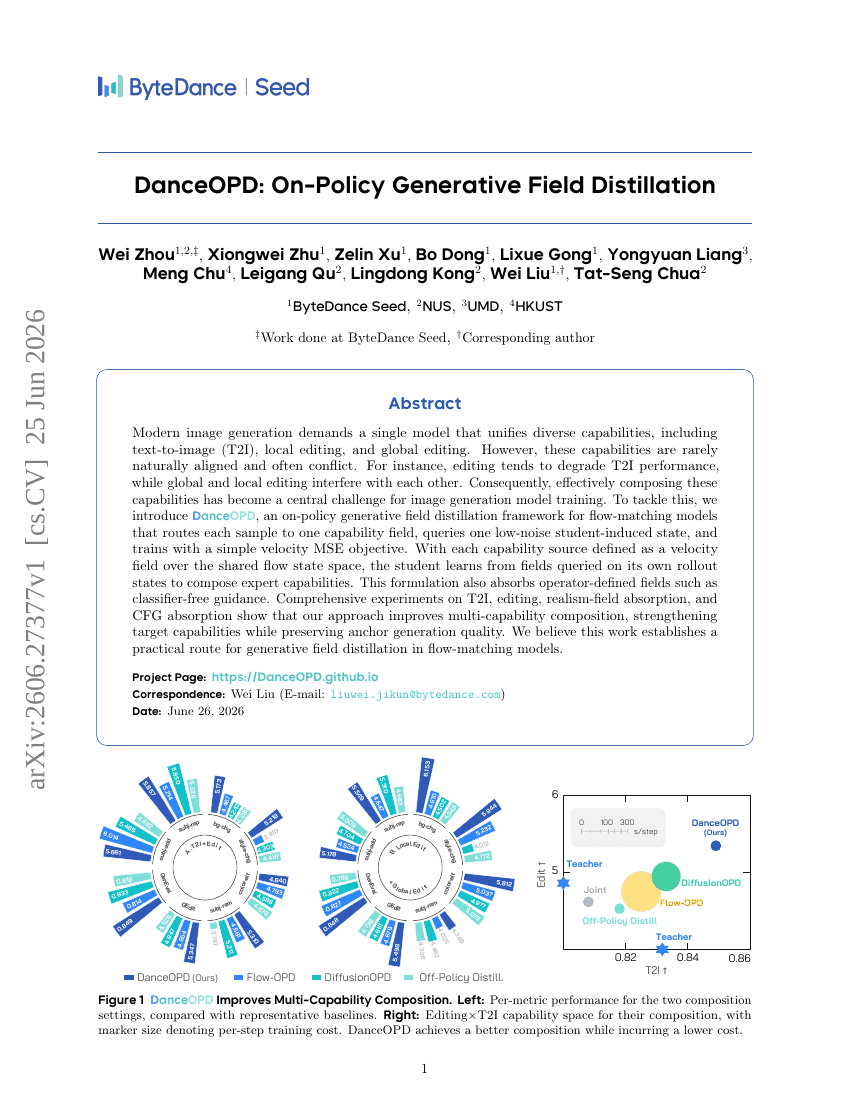
DanceOPD: On-Policy Generative Field Distillation
Autodata: An agentic data scientist to create high quality synthetic data
Improved Large Language Diffusion Models
How Robust is OCR-Reasoning? Evaluating OCR-Reasoning Robustness of Vision-Language Models under Visual Perturbations
RoboAtlas: Contextual Active SLAM
Learning Robot Visual Navigation in Crowds via Intention-Aware Scene Representations
Deep Reinforcement Learning-Enhanced Event-Triggered Data-Driven Predictive Control for a 3D Cable-Driven Soft Robotic Arm
Natural Ungrokking: Asymmetric Control of Which Rules Survive Pretraining
Every Nonnegative Integer Is a Sum of a Triangular, a Pentagonal, and a Heptagonal Number
Loop Engineering: The Anthropic Playbook for Designing Systems That Prompt Your Agents
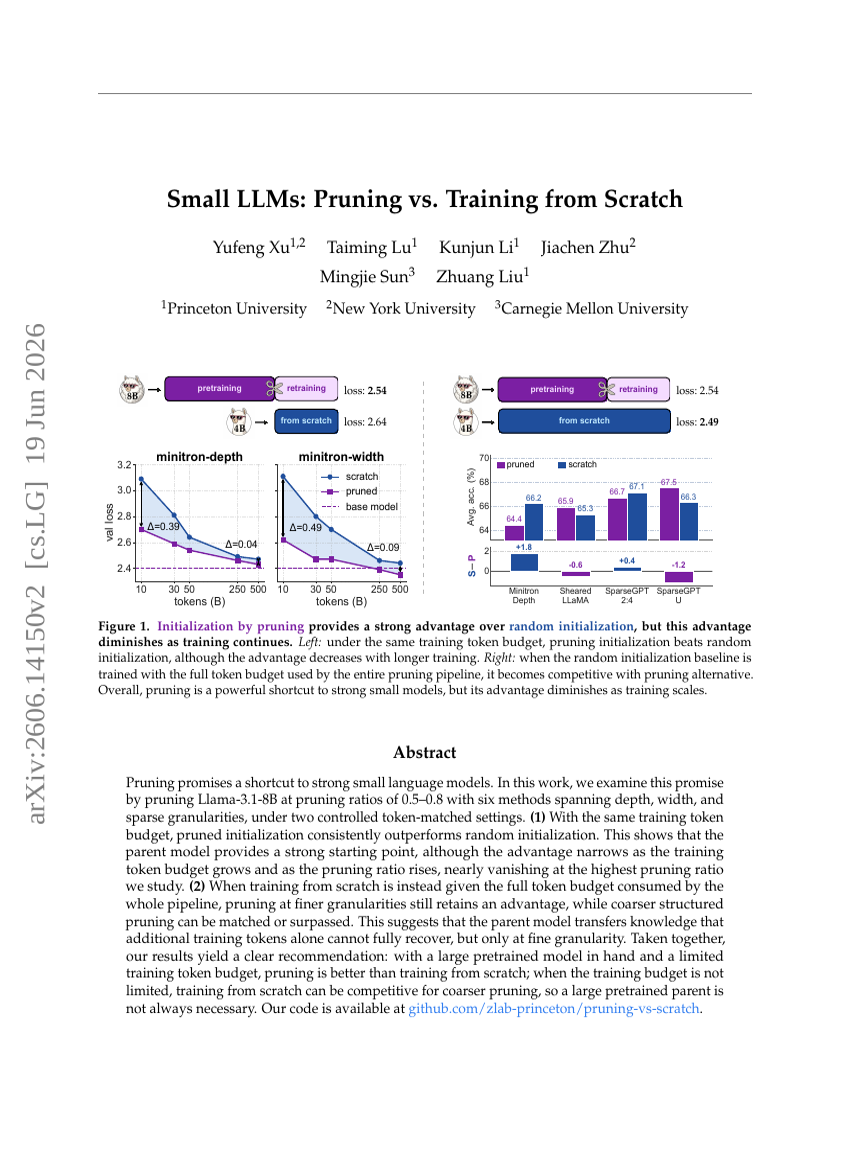
Small LLMs: Pruning vs. Training from Scratch
OpenThoughts-Agent: Data Recipes for Agentic Models
LingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
AOHP: An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction
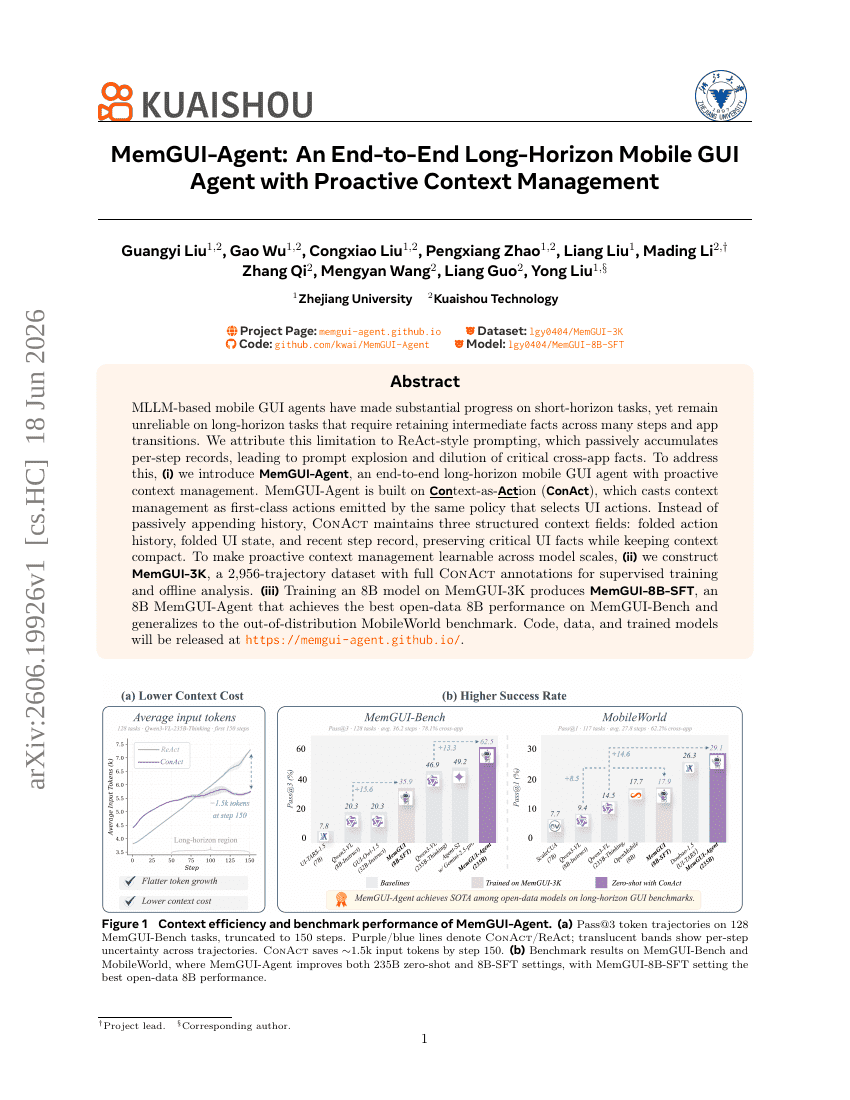
MemGUI-Agent: An End-to-End Long-Horizon Mobile GUI Agent with Proactive Context Management
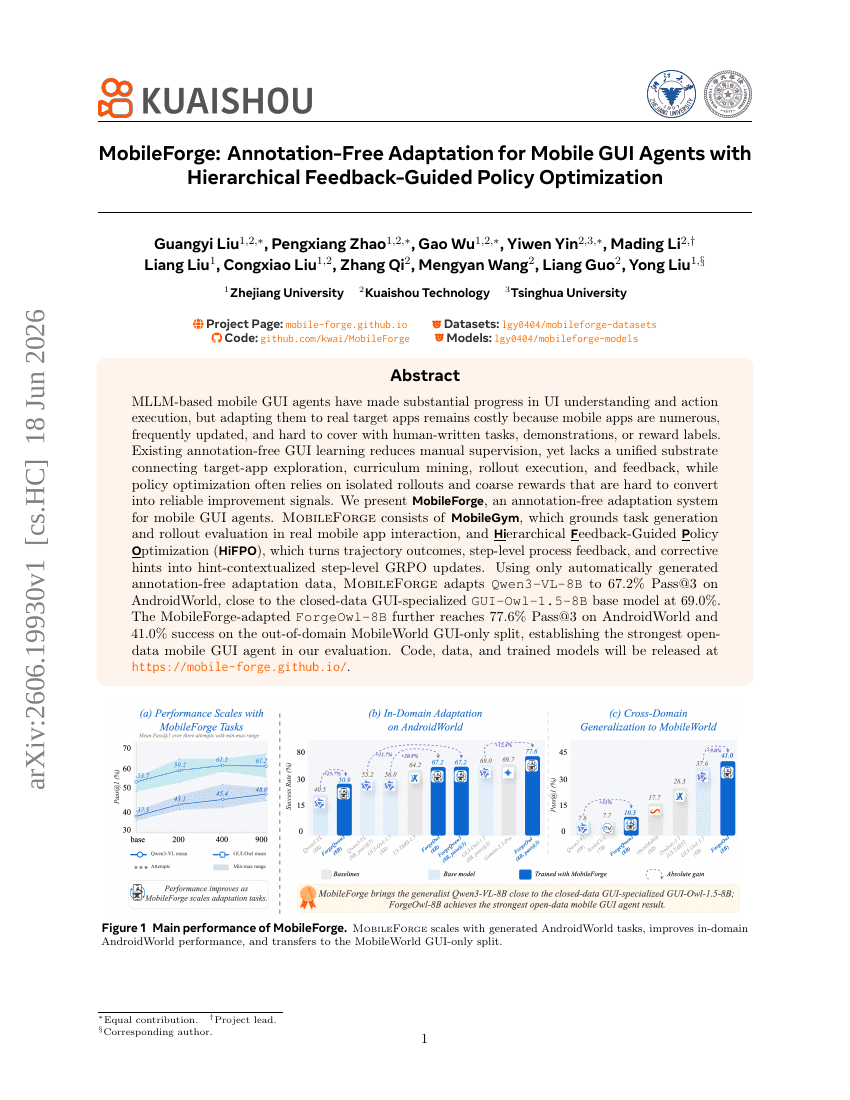
MobileForge: Annotation-Free Adaptation for Mobile GUI Agents with Hierarchical Feedback-Guided Policy Optimization
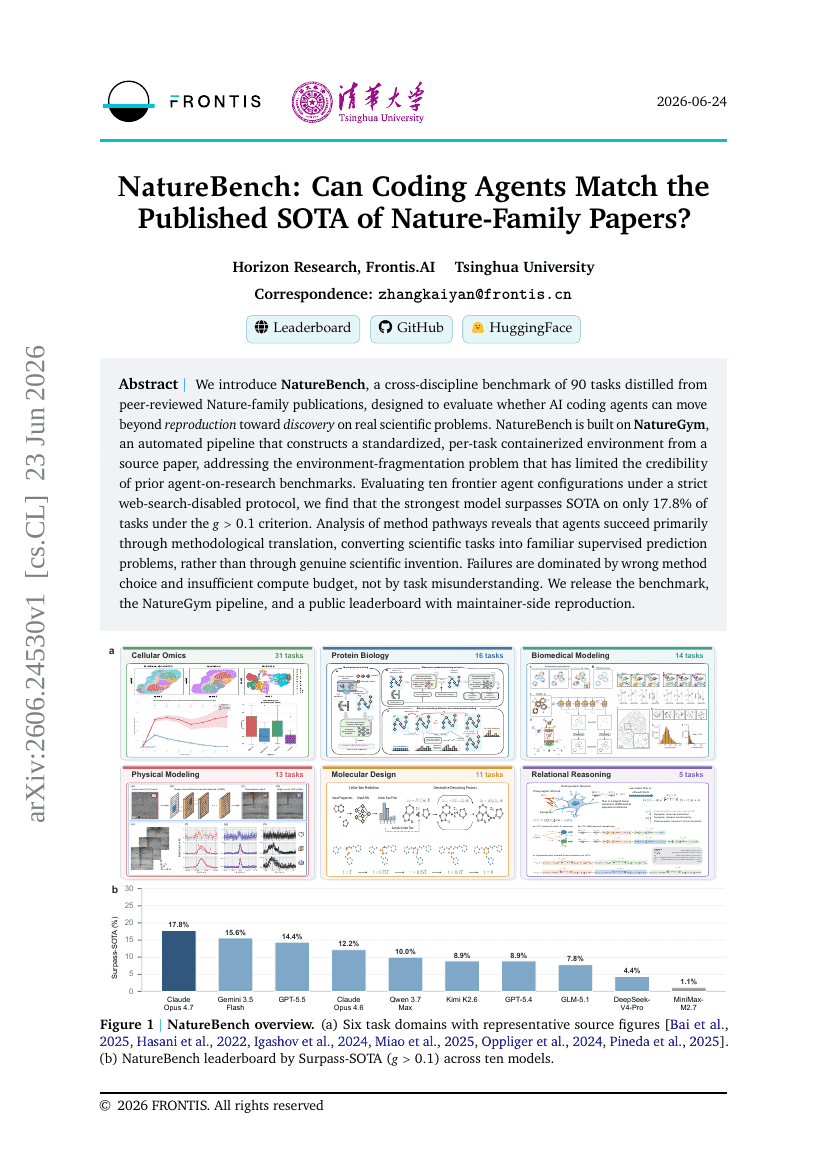
NatureBench: Can Coding Agents Match the Published SOTA of Nature-Family Papers?
Qwen-AgentWorld: Language World Models for General Agents
Rethinking Training Targets, Architectures and Data Quality for Universal Speech Enhancement
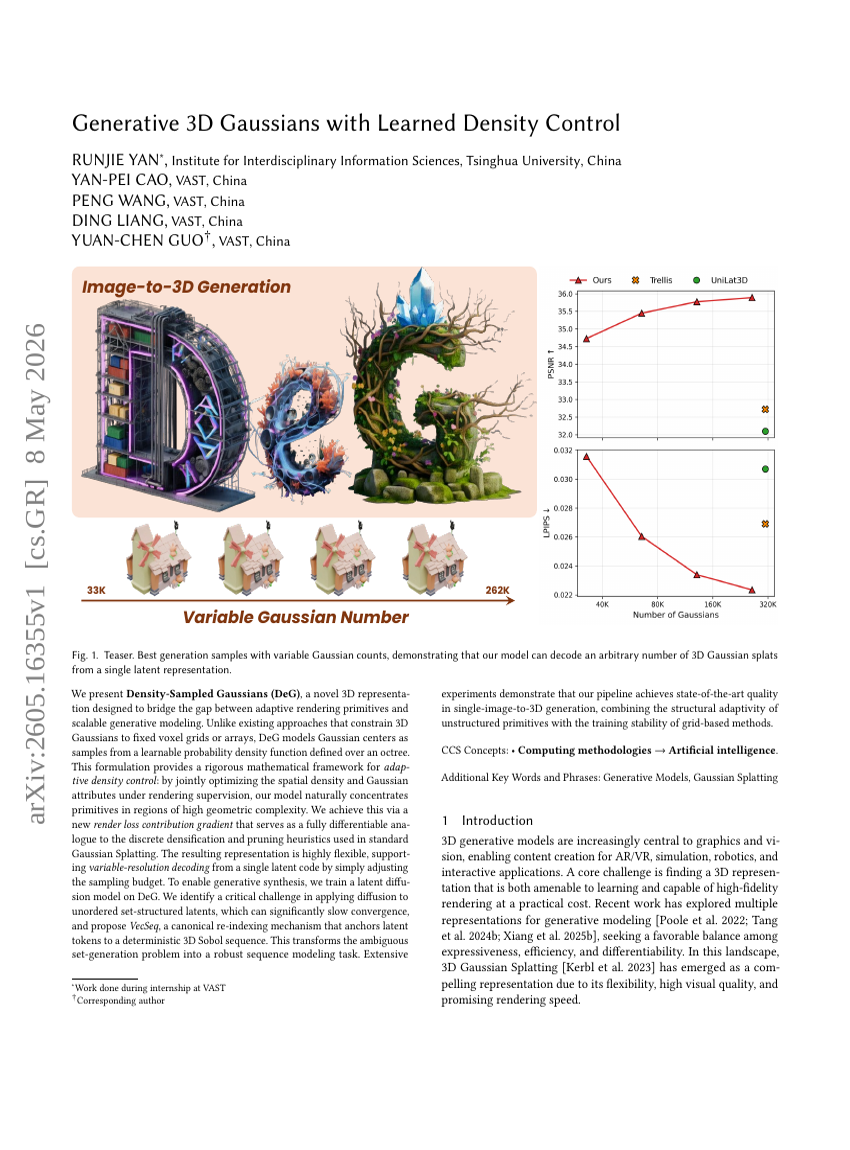
Generative 3D Gaussians with Learned Density Control
TADA: A Generative Framework for Speech Modeling via Text-Acoustic Dual Alignment
Beyond Isolated Words: Diffusion Brush for Handwritten Text-Line Generation
gsplat: An Open-Source Library for Gaussian Splatting
OmniVideo-100K: A Dataset for Audio-Visual Reasoning through Structured Scripts and Evidence Chains
OPEN-SWE-TRACES: Advancing Dual-Mode Multilingual Distillation for Software Engineering Agents
Credit Assignment with Resets in Language Model Reasoning
The Verification Horizon: No Silver Bullet for Coding Agent Rewards
Qwen-Image-Agent: Bridging the Context Gap in Real-World Image Generation
OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
In-Context World Modeling for Robotic Control
DanceOPD: On-Policy Generative Field Distillation
Autodata: An agentic data scientist to create high quality synthetic data
Improved Large Language Diffusion Models
How Robust is OCR-Reasoning? Evaluating OCR-Reasoning Robustness of Vision-Language Models under Visual Perturbations
RoboAtlas: Contextual Active SLAM
Learning Robot Visual Navigation in Crowds via Intention-Aware Scene Representations
Deep Reinforcement Learning-Enhanced Event-Triggered Data-Driven Predictive Control for a 3D Cable-Driven Soft Robotic Arm
Natural Ungrokking: Asymmetric Control of Which Rules Survive Pretraining
Every Nonnegative Integer Is a Sum of a Triangular, a Pentagonal, and a Heptagonal Number
Loop Engineering: The Anthropic Playbook for Designing Systems That Prompt Your Agents
Small LLMs: Pruning vs. Training from Scratch
OpenThoughts-Agent: Data Recipes for Agentic Models
LingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
AOHP: An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction
MemGUI-Agent: An End-to-End Long-Horizon Mobile GUI Agent with Proactive Context Management
MobileForge: Annotation-Free Adaptation for Mobile GUI Agents with Hierarchical Feedback-Guided Policy Optimization
NatureBench: Can Coding Agents Match the Published SOTA of Nature-Family Papers?
Qwen-AgentWorld: Language World Models for General Agents
Rethinking Training Targets, Architectures and Data Quality for Universal Speech Enhancement
Generative 3D Gaussians with Learned Density Control
TADA: A Generative Framework for Speech Modeling via Text-Acoustic Dual Alignment
Beyond Isolated Words: Diffusion Brush for Handwritten Text-Line Generation
gsplat: An Open-Source Library for Gaussian Splatting
OmniVideo-100K: A Dataset for Audio-Visual Reasoning through Structured Scripts and Evidence Chains
OPEN-SWE-TRACES: Advancing Dual-Mode Multilingual Distillation for Software Engineering Agents
Credit Assignment with Resets in Language Model Reasoning