HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Securing the AI Agent: A Unified Framework for Multi-Layer Agent Red Teaming

DataComp-VLM: Improved Open Datasets for Vision-Language Models

























Securing the AI Agent: A Unified Framework for Multi-Layer Agent Red Teaming
DataComp-VLM: Improved Open Datasets for Vision-Language Models
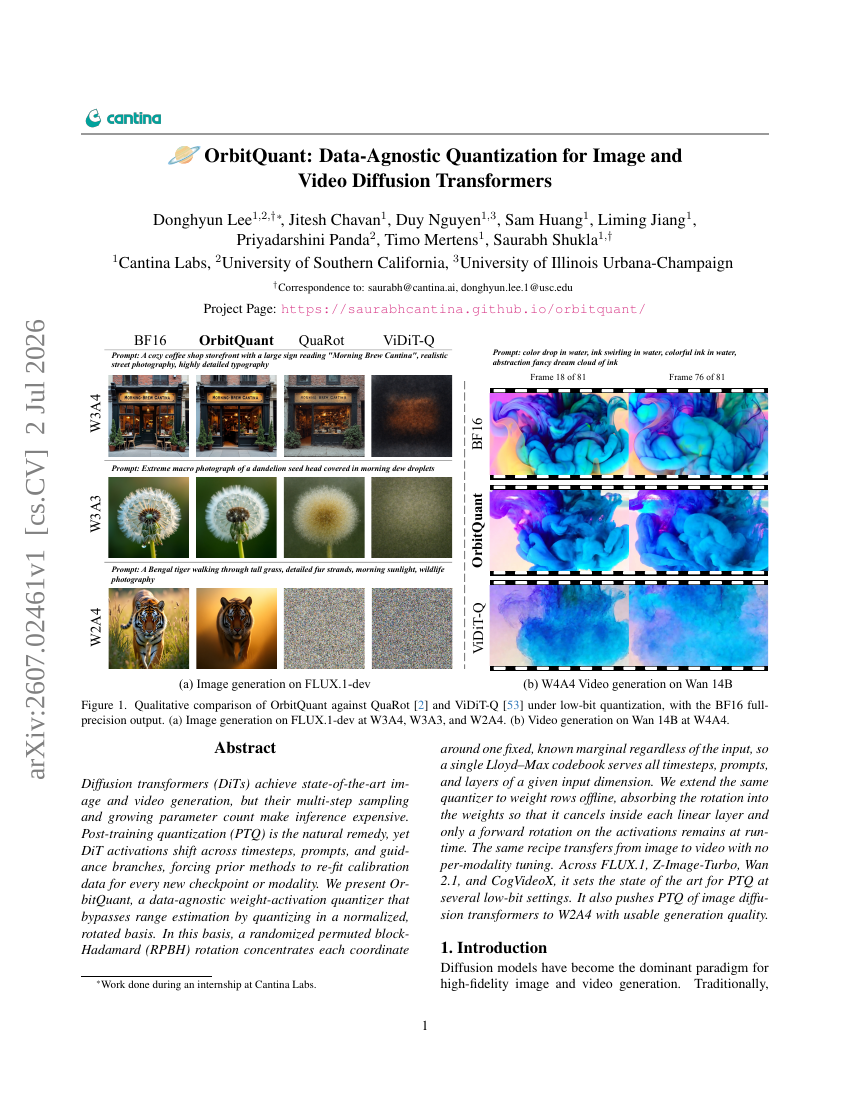
OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
VLA-Corrector: Lightweight Detect-and-Correct Inference for Adaptive Action Horizon
Embodied.cpp: A Portable Inference Runtime of Embodied AI Models on Heterogeneous Robots
The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
GeneBench-Pro: Evaluating Multistage Statistical Reasoning in Genomics, Quantitative Biology, and Translational Biomedicine
Position: AI/ML Deepfake Research is Misaligned with AI-Generated Non-Consensual Intimate Imagery (AIG-NCII)
To Grok Grokking: Provable Grokking in Ridge Regression
A Random Matrix Theory Perspective on the Consistency of Diffusion Models
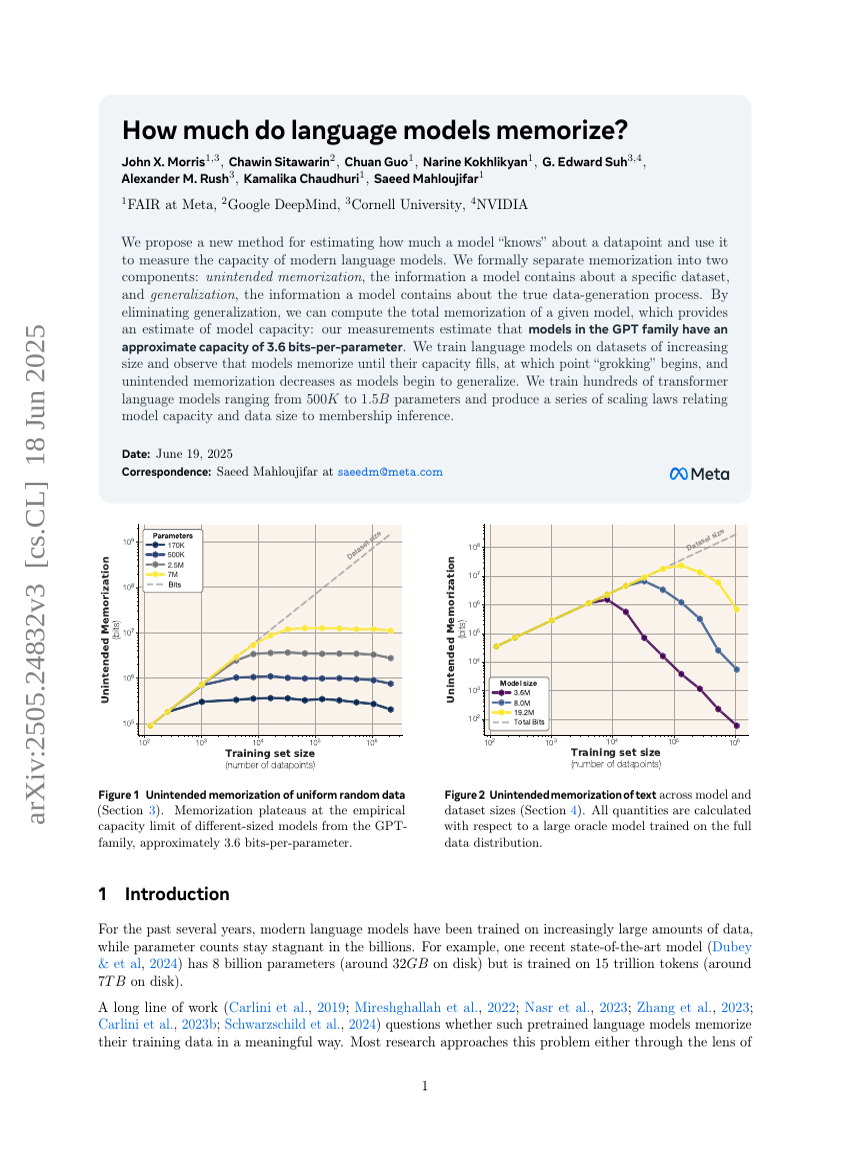
How much do language models memorize?
The Obfuscation Atlas: Mapping Where Honesty Emerges in RLVR with Deception Probes
Position: The Alignment Community is Unintentionally Building a Censor’s Toolkit
High-accuracy sampling for diffusion models and log-concave distributions
AgenticDataBench: A Comprehensive Benchmark for Data Agents
MULTI-RESOLUTION FLOW MATCHING: TRAINING-FREE DIFFUSION ACCELERATION VIA STAGED SAMPLING
Morphing into Hybrid Attention Models
EvoPolicyGym: Evaluating Autonomous Policy Evolution in Interactive Environments
AgenticSTS: A Bounded-Memory Testbed for Long-Horizon LLM Agents
Program-as-Weights: A Programming Paradigm for Fuzzy Functions
MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator
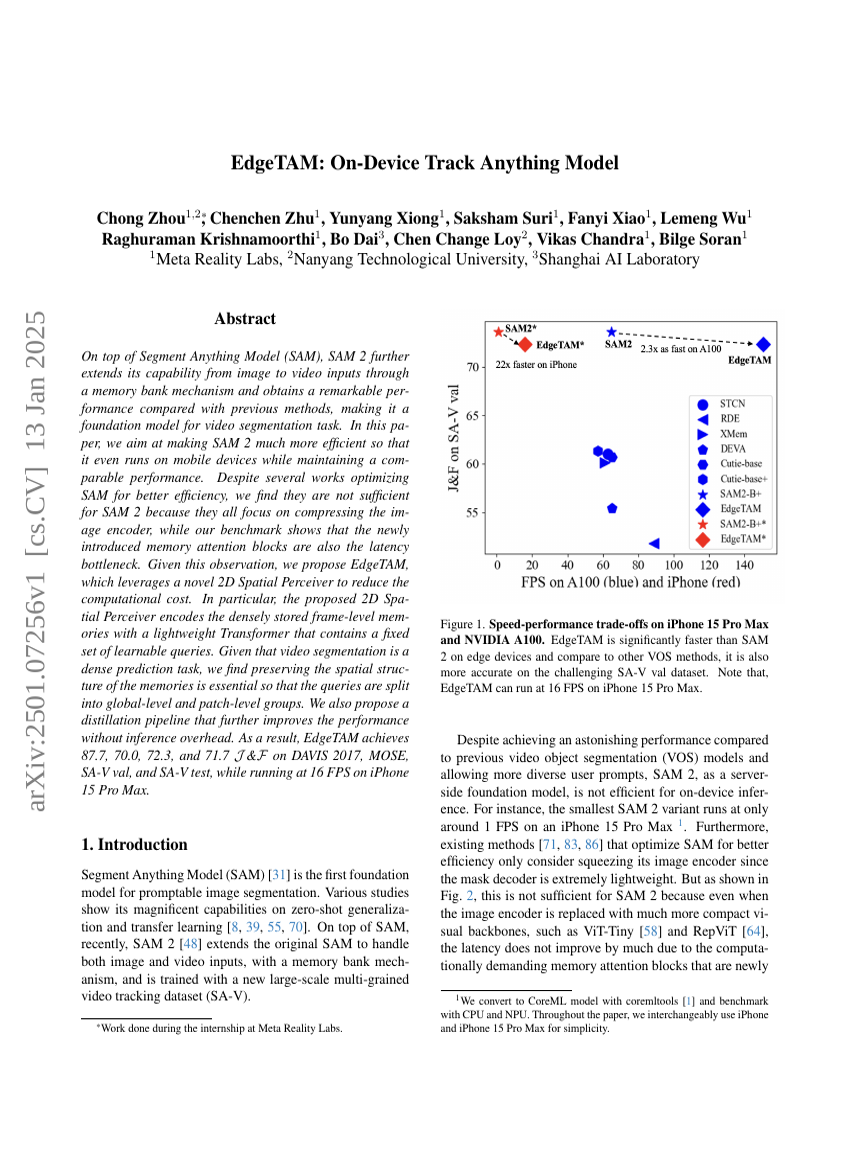
EdgeTAM: On-Device Track Anything Model
PixelRefer: A Unified Framework for Spatio-Temporal Object Referring with Arbitrary Granularity
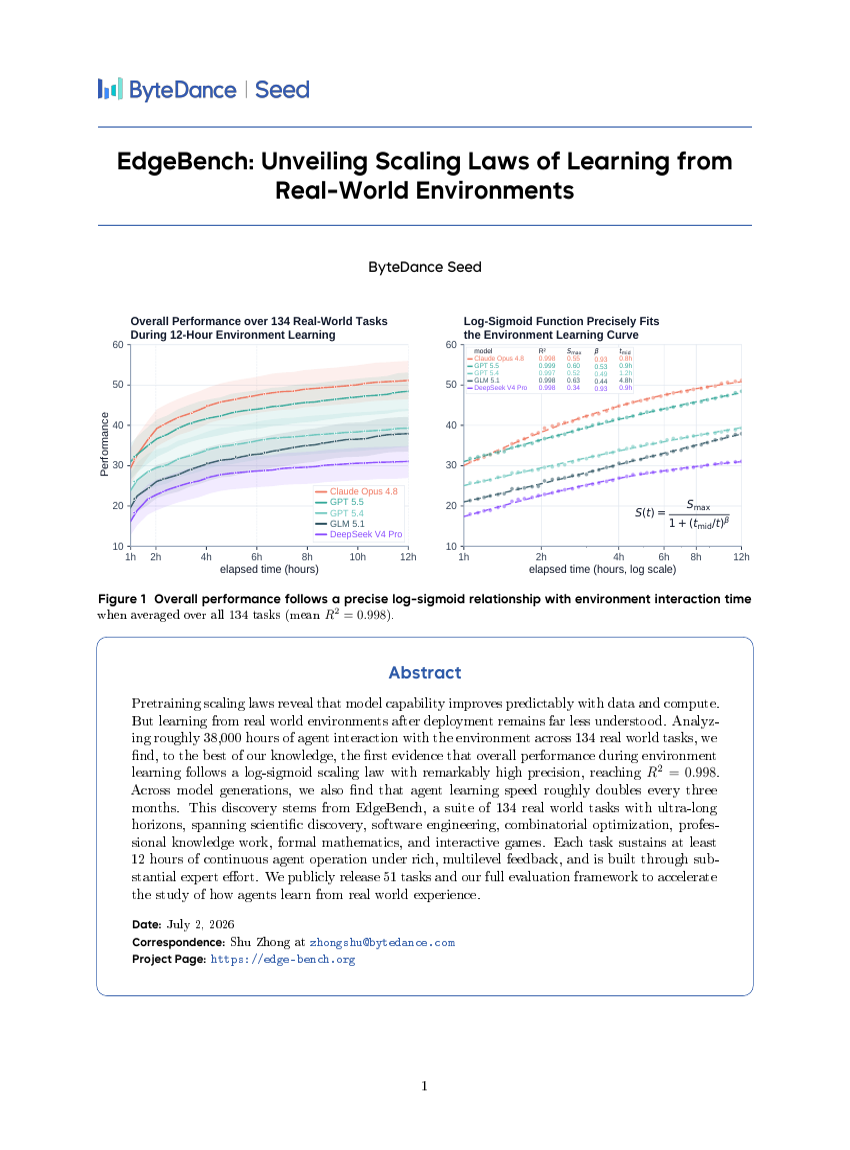
EdgeBench: Unveiling Scaling Laws of Learning from Real-World Environments
ASPIRE: Agentic /Skills Discovery for Robotics
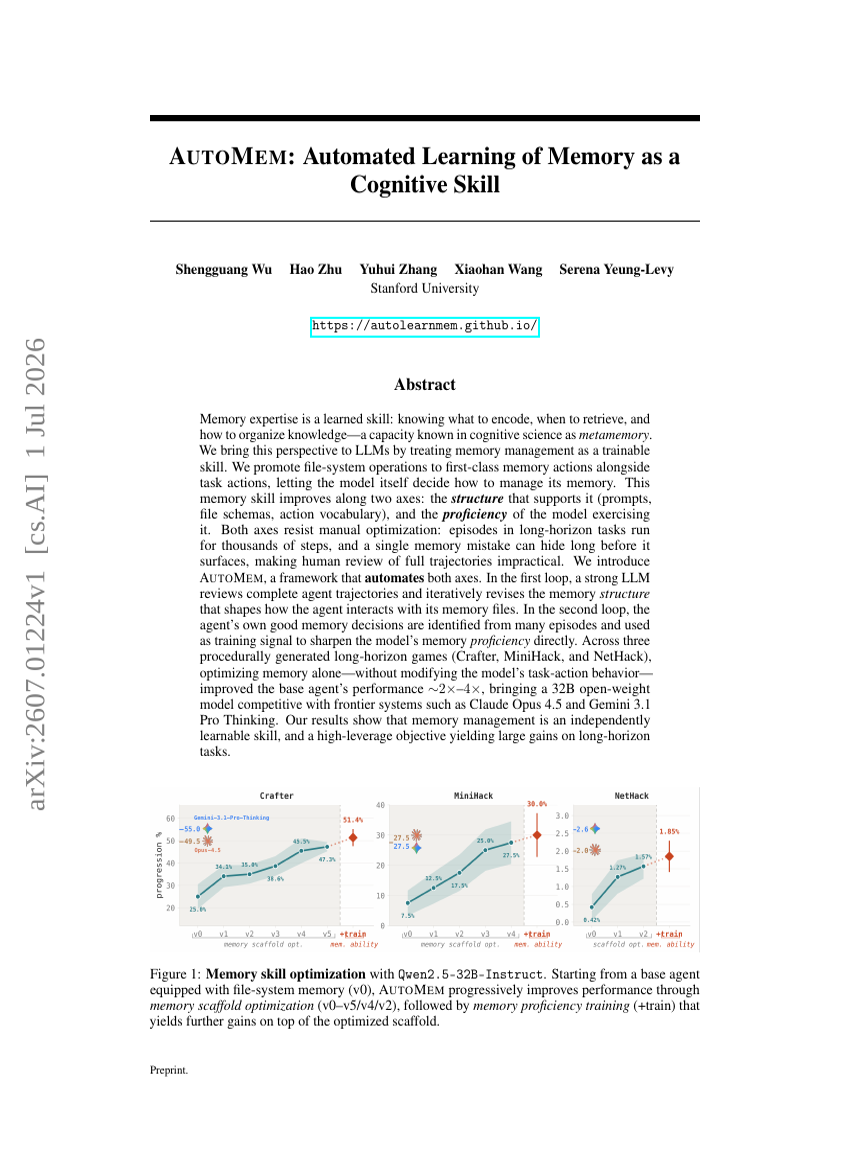
AUTOMEM: Automated Learning of Memory as a Cognitive Skill
The Decode-Work Law: Margin-Governed, Provably-Exact Spatial Joins over Compressed Geometry
Neural Certificate Pricing for Combinatorial Optimization Problems
Optimal Resource Utilization for Autonomous Laboratory Orchestrators
TERA: A Unified Taylor Model Enabled Reachability Analysis Framework
Perceive-to-Reason: Decoupling Perception and Reasoning for Fine-Grained Visual Reasoning
Trie-based Experiment Plans for Efficient IR Pipeline Experiments
OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
VLA-Corrector: Lightweight Detect-and-Correct Inference for Adaptive Action Horizon
Embodied.cpp: A Portable Inference Runtime of Embodied AI Models on Heterogeneous Robots
The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
GeneBench-Pro: Evaluating Multistage Statistical Reasoning in Genomics, Quantitative Biology, and Translational Biomedicine
Position: AI/ML Deepfake Research is Misaligned with AI-Generated Non-Consensual Intimate Imagery (AIG-NCII)
To Grok Grokking: Provable Grokking in Ridge Regression
A Random Matrix Theory Perspective on the Consistency of Diffusion Models
How much do language models memorize?
The Obfuscation Atlas: Mapping Where Honesty Emerges in RLVR with Deception Probes
Position: The Alignment Community is Unintentionally Building a Censor’s Toolkit
High-accuracy sampling for diffusion models and log-concave distributions
AgenticDataBench: A Comprehensive Benchmark for Data Agents
MULTI-RESOLUTION FLOW MATCHING: TRAINING-FREE DIFFUSION ACCELERATION VIA STAGED SAMPLING
Morphing into Hybrid Attention Models
EvoPolicyGym: Evaluating Autonomous Policy Evolution in Interactive Environments
AgenticSTS: A Bounded-Memory Testbed for Long-Horizon LLM Agents
Program-as-Weights: A Programming Paradigm for Fuzzy Functions
MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator
EdgeTAM: On-Device Track Anything Model
PixelRefer: A Unified Framework for Spatio-Temporal Object Referring with Arbitrary Granularity
EdgeBench: Unveiling Scaling Laws of Learning from Real-World Environments
ASPIRE: Agentic /Skills Discovery for Robotics
AUTOMEM: Automated Learning of Memory as a Cognitive Skill
The Decode-Work Law: Margin-Governed, Provably-Exact Spatial Joins over Compressed Geometry
Neural Certificate Pricing for Combinatorial Optimization Problems
Optimal Resource Utilization for Autonomous Laboratory Orchestrators
TERA: A Unified Taylor Model Enabled Reachability Analysis Framework
Perceive-to-Reason: Decoupling Perception and Reasoning for Fine-Grained Visual Reasoning
Trie-based Experiment Plans for Efficient IR Pipeline Experiments