Command Palette
Search for a command to run...
Geometrisches Aktionsmodell für das Roboter-Policy-Lernen
Geometrisches Aktionsmodell für das Roboter-Policy-Lernen
Jisang Han Seonghu Jeon Jaewoo Jung René Zurbrügg Honggyu An Tifanny Portela Marco Hutter Marc Pollefeys Seungryong Kim Sunghwan Hong
Zusammenfassung
Generalistische Roboter-Policies müssen Benutzeranweisungen befolgen und dabei die Interaktion von Objekten, Kameras und Roboteraktionen in der physischen 3D-Welt nachvollziehen. Aktuelle Vision-Language-Action-Modelle (VLAs) und Video-World-Action-Modelle (WAMs) übernehmen starke semantische oder zeitliche Priors aus großskaligen Foundation-Modellen, operieren jedoch weiterhin primär auf 2D-Bildrahmen oder 2D-abgeleiteten latenten Räumen, wodurch die für kontaktreiche Manipulation erforderliche 3D-Geometrie implizit bleibt. Wir präsentieren das Geometric Action Model (GAM), eine sprachkonditionierte Manipulations-Policy, die ein vortrainiertes geometrisches Foundation-Modell (GFM) direkt als gemeinsames Substrat für Wahrnehmung, zeitliche Vorhersage und Aktionsdekodierung wiederverwendet. GAM teilt das GFM an einer Zwischenschicht: Die flachen Schichten fungieren als Beobachtungsencoder, und ein kausaler Zukunftsprädiktor, der an der Trennstelle eingefügt wird, prognostiziert zukünftige latente tokens, konditioniert auf Sprache, Propriozeption und den Aktionsverlauf. Die vorhergesagten zukünftigen tokens werden anschließend durch die verbleibenden GFM-Blöcke geleitet, um die Merkmalsweitergabe und Dekodierung zu ermöglichen, sodass ein einzelner Backbone sowohl zukünftige Geometrie als auch Aktionen generieren kann. Dieses Design rüstet das GFM durch minimale architektonische Anpassungen mit einer sprachkonditionierten zeitlichen Weltmodellierung aus, wobei seine umfangreichen geometrischen Priors erhalten bleiben. In einer breiten Palette von Simulations- und Realroboter-Manipulations-Benchmarks schneidet das GAM genauer, robuster, schneller und leichter ab als aktuelle Baselines auf Foundation-Modell-Niveau.
One-sentence Summary
Researchers from KAIST and ETH Zurich propose the Geometric Action Model (GAM), a language-conditioned manipulation policy that repurposes a pretrained geometric foundation model by splitting it at an intermediate layer and inserting a causal future predictor to forecast latent tokens conditioned on language, proprioception, and action history, thereby enabling joint perception, temporal prediction, and action decoding while preserving 3D geometric priors and achieving superior accuracy, robustness, and efficiency across simulation and real-robot benchmarks.
Key Contributions
- The Geometric Action Model (GAM) is introduced as a language-conditioned manipulation policy that repurposes a pretrained geometric foundation model by splitting it into an observation encoder, a causal future predictor, and a decoder, allowing a single backbone to jointly produce future geometry and actions with minimal architectural changes.
- Action and geometry are predicted in a unified token space via a single autoregressive forward pass, with lightweight regression and depth heads decoding both action tokens and future scene tokens from the same backbone.
- Across diverse simulation and real-robot manipulation benchmarks, GAM achieves higher accuracy, greater robustness, faster inference, and lower model weight than existing foundation-model-scale baselines.
Introduction
Robot manipulation policies must reason about 3D scene geometry and temporal dynamics to act reliably in unstructured environments. Prior video world action models (WAMs) predict future latents and actions in 2D pixel space, missing explicit geometric structure, while geometry-aware vision-language-action models (VLAs) rely on passive feature distillation from an external geometric foundation model, creating a disconnected, multi-stage pipeline. The authors introduce the Geometric Action Model (GAM), a single shared-backbone architecture that unifies perception, geometry prediction, and action decoding. GAM autoregressively generates both action tokens and future depth tokens in a shared latent space, eliminating the need for external geometry modules and yielding a policy that is simultaneously more accurate, robust, faster, and lighter than existing foundation-model-scale alternatives.
Dataset
The authors pre-train GAM on a weighted mixture of three datasets, combining real-robot and simulated demonstrations to provide both broad embodiment coverage and clean geometric supervision.
-
Dataset composition and sampling ratios
- Open-X Embodiment (OXE): 72%
- MimicGen: 18%
- RoboCasa365: 10%
-
Key details for each subset
- OXE
Real-robot demonstrations across multiple embodiments and manipulation domains.
Only subsets whose actions can be mapped to the common control interface are kept; datasets incompatible with the action space are excluded.
Depth supervision uses teacher pseudo-depth. - MimicGen
Simulation demonstrations with clean geometric supervision.
Depth supervision uses re-rendered simulator depth. - RoboCasa365
Simulation demonstrations; only the manipulation-task subset is used.
Depth supervision uses re-rendered simulator depth. - Across all sources, the original task language is preserved without synthesizing additional instructions. The language encoder remains frozen during pre-training.
- OXE
-
How the data is used
- The three datasets are mixed with the above sampling ratios for pre-training.
- All data are converted to a common observation and action format before training.
- The model uses two RGB views when available: an external view and a wrist view, both resized to 224×224.
-
Processing and augmentations
- Standard image augmentations (random cropping, rotation, color jitter) are applied during training and disabled during evaluation.
- No additional metadata construction is performed beyond retaining the original language annotations.
Method
The authors propose the Geometric Action Model (GAM), a language-conditioned manipulation policy that directly repurposes a pretrained geometric foundation model (GFM) as a shared substrate for perception, temporal prediction, and action decoding. Unlike prior approaches that rely on 2D image priors or treat geometric models as frozen feature extractors, GAM splits the GFM at an intermediate layer. This design allows the model to jointly predict future 3D geometry and action chunks within a shared geometric backbone.
As shown in the figure below, the core idea involves transforming the GFM by inserting a causal future predictor. The shallow layers serve as an observation encoder, while the predictor forecasts future latent tokens conditioned on language, proprioception, and action history. These predicted tokens are then routed through the remaining deep GFM blocks to produce both future geometry and actions.
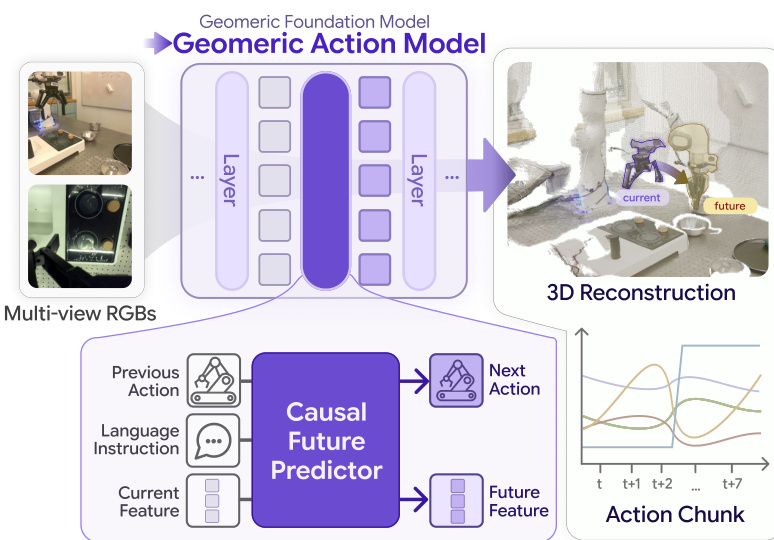
To understand the architectural advantage, it is helpful to contrast GAM with existing baselines. While Video World-Action Models (WAMs) predict future frames and Geometry-aware Vision-Language-Action Models (VLAs) often rely on distillation or separate heads, GAM integrates the prediction directly into the GFM latent space.
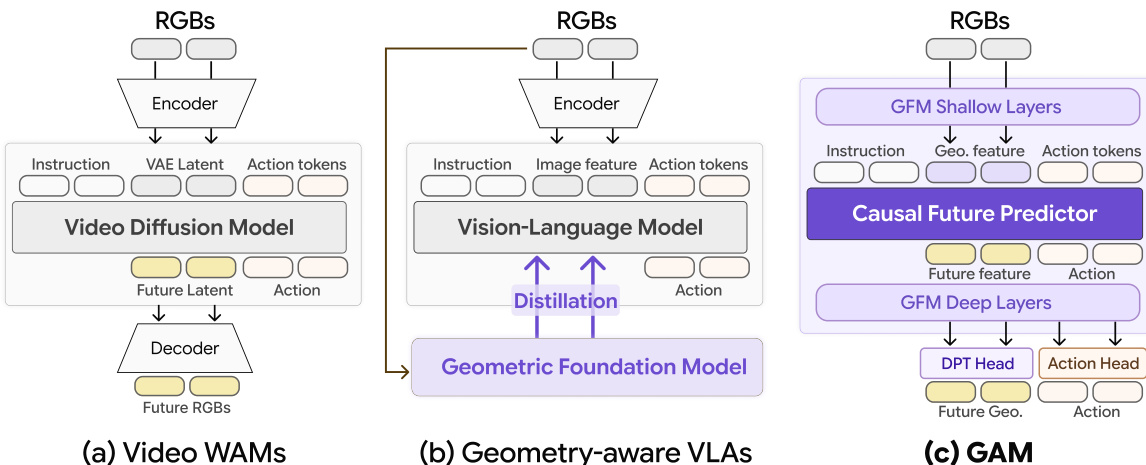
Refer to the framework diagram below, which highlights these structural differences. In the GAM architecture (panel c), the GFM shallow layers extract geometric features, which are fed into the Causal Future Predictor alongside instructions and action tokens. The output is then processed by the GFM deep layers to produce future geometry and actions simultaneously, avoiding the need for separate diffusion processes or frozen backbones.
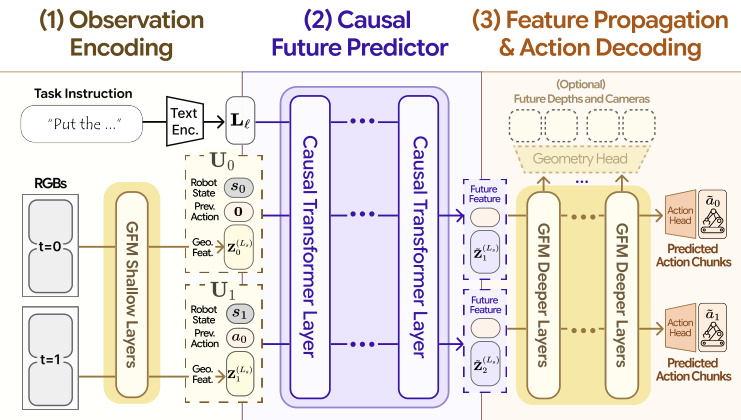
The framework operates in three sequential stages inside the GFM.
1. Observation Encoder The authors reuse the shallow layers of the pretrained GFM, denoted as E<Ls, where Ls is the split layer. For each timestep t′ in the context window, multi-view RGB observations are tokenized using the original GFM patch embedding. This produces a sequence of per-timestep geometric latent states {Zt−H+1(Ls),…,Zt(Ls)}. The split layer Ls is chosen to be deep enough to extract rich visual features but shallower than the layers used for geometry decoding, ensuring predicted states can be decoded into 3D structures.
2. Causal Future Predictor At the split layer Ls, the authors insert a causal future predictor gϕ. This module combines the encoded geometric features with proprioceptive states st′, previous actions at′−1, and language instructions ℓ. The inputs are embedded and concatenated into a sequence X.
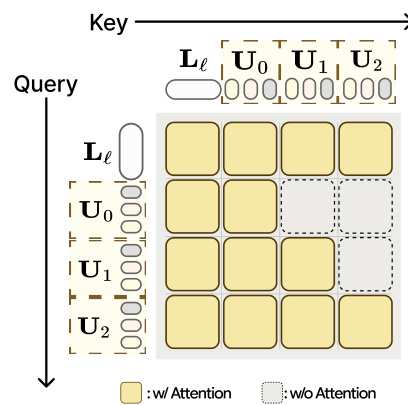
To process this sequence without future leakage, the model employs block-causal self-attention. As illustrated in the attention mask diagram below, the attention mechanism ensures that predictions for a specific timestep only attend to past and present contexts (yellow blocks), while ignoring future tokens (dashed blocks).
At the final layer of the predictor, the model forecasts the latent geometric tokens of the future frame Z~t′+1(Ls) and a predicted next action token a~t′. This joint forecasting ensures tight interaction between action and spatial representations.
3. Feature Propagation and Action Decoding The predicted action token is replicated for each view and concatenated with the geometry tokens. These are fed through the remaining deep GFM blocks D>Ls. The causal mask strategy is extended to these global attention layers to prevent leakage. Finally, two heads decode the output: a lightweight action head aggregates tokens to regress the executable action chunk a^t′, and the original GFM depth head decodes geometry tokens into future depth maps.
The detailed flow of these three stages is visualized in the pipeline diagram below.
Training Objective The policy is trained end-to-end by minimizing a multi-task objective: Ltotal=λactLact+λfeatLfeat+λdepthLdepth The action loss Lact is an ℓ1 regression between the decoded action chunk and expert actions. The future-feature loss Lfeat aligns predicted future tokens with actual next-frame tokens extracted from the frozen GFM: Lfeat=∑t′∈HZ~t′+1(Ls)−Zt′+1(Ls)1 The future-depth loss Ldepth supervises the decoded depth against ground-truth future depth using scale-invariant and gradient-matching penalties. At inference, the authors maintain historical context via key-value caching, allowing each step to process only the new observation and previous action in a single feed-forward pass.
Experiment
The evaluation spans simulation benchmarks (LIBERO and LIBERO-Plus), real-robot tasks, and an additional kitchen benchmark, comparing GAM against vision-language-action, world-action, and geometry-aware baselines. GAM matches or exceeds these methods while using substantially fewer parameters and achieving up to 55 times faster inference, with especially pronounced robustness under camera viewpoint perturbations. Ablations show that pretraining and the deep integration of geometric foundation model layers are critical for generalization, and that future depth and feature prediction losses help encode geometric dynamics. Real-world experiments confirm that GAM maintains high success rates under out-of-distribution camera shifts, validating its thorough exploitation of 3D geometric priors.
Theauthors evaluate their model on the original LIBERO benchmark across four distinct task suites covering spatial, object, goal, and long-horizon manipulation. The results indicate that the model achieves highly competitive success rates across nearly all individual tasks, reflecting strong performance on standard benchmarks where baseline performance is heavily saturated. The model demonstrates consistently high success rates across the majority of tasks in all four evaluation suites. Performance is robust across diverse manipulation scenarios, with only a small number of tasks exhibiting slightly lower success rates. The overall suite-level performance is exceptionally strong, establishing a solid baseline before assessing generalization to perturbed environments.
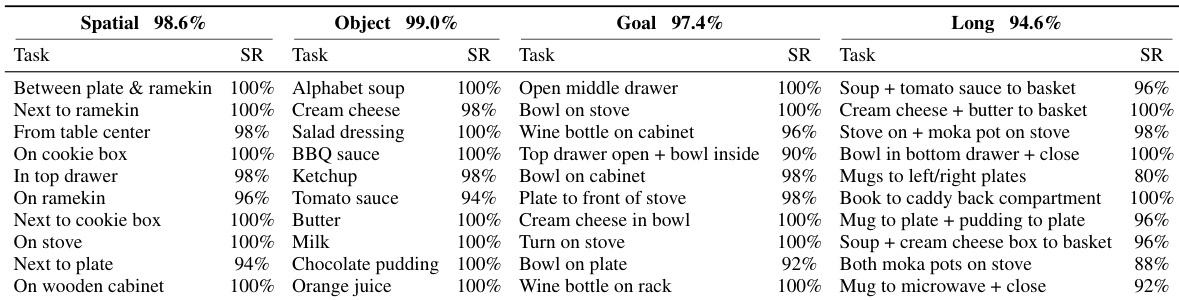
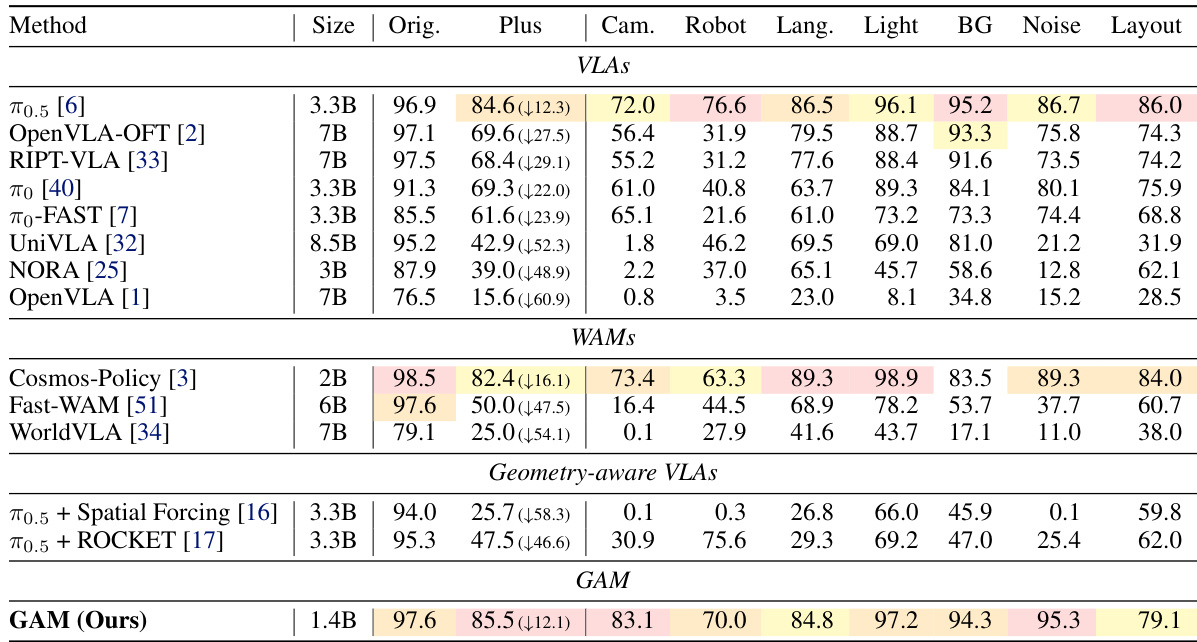
The authors evaluate their proposed Geometric Action Model against various vision-language-action models, world-action models, and geometry-aware baselines on standard and perturbed manipulation benchmarks. Results show that the proposed model achieves highly competitive performance on the standard benchmark while consistently outperforming competing methods on the more challenging perturbed benchmark, particularly under camera viewpoint changes. This demonstrates the advantage of integrating geometric world dynamics directly into the policy's predictive pathway. The proposed model achieves top-tier success rates across multiple perturbation categories, including camera viewpoint, lighting, and background changes, despite having a smaller model size than most baselines. The method demonstrates remarkable robustness in camera-perturbation settings, significantly outperforming existing geometry-aware vision-language-action models. The model maintains strong performance on the original benchmark while showing minimal performance drops when evaluated on the perturbed tasks.
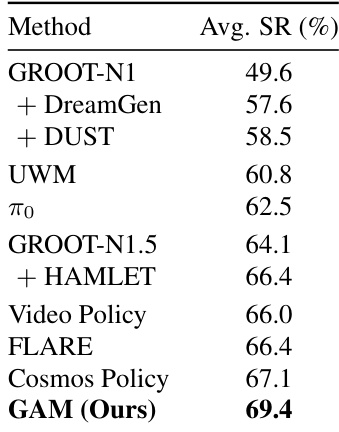
The authors evaluate their proposed Geometric Action Model against several baseline manipulation policies, including vision-language-action models and video world-action models. Results indicate that the proposed method achieves the highest average success rate among all compared approaches, demonstrating superior performance and robustness. The findings highlight the effectiveness of repurposing geometric foundation models for end-to-end policy learning. The proposed model outperforms all competing baselines, achieving the top average success rate in the evaluation. The method shows clear advantages over prior approaches like Cosmos Policy and GROOT variants. Integrating geometric world dynamics into the policy leads to consistently better manipulation performance.
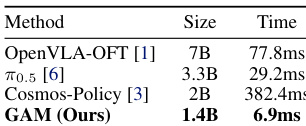
The authors evaluate the inference speed and model size of their proposed method against representative baselines. Results show that the proposed model achieves the lowest latency and the smallest parameter count, enabling significantly faster execution compared to diffusion-based and vision-language baselines. The proposed method has the smallest model size among all compared approaches. It achieves the fastest inference time, running substantially faster than the diffusion-based baseline. The compact architecture allows for efficient deployment without relying on large language or video generation backbones.
Theauthors evaluate the impact of passing action tokens through the deep geometric decoder by comparing their full model against a variant that applies action supervision directly to the causal future predictor. Results indicate that utilizing the remaining decoder layers improves performance, particularly in perturbed environments, suggesting these layers refine action representations for better robustness. The full model consistently outperforms the direct-action supervision variant across both original and perturbed benchmarks. The performance advantage of the full model is more significant in the perturbed setting, highlighting the benefit of deep geometric processing for robustness. Passing action tokens through the remaining decoder layers allows the model to better handle camera perturbations compared to direct supervision.

The experiments evaluate the model on both standard and perturbed manipulation benchmarks, showing that it achieves highly competitive success rates on original tasks while substantially outperforming existing methods under camera, lighting, and background perturbations. Integrating geometric world dynamics directly into the policy yields robust performance with minimal drops when moving from standard to perturbed settings, and the compact design enables the fastest inference and smallest model size among compared approaches. An ablation study further confirms that processing action tokens through the deep geometric decoder layers is essential for handling perturbations, validating the advantage of geometric processing for robust manipulation.