Command Palette
Search for a command to run...
Pretraining rekurrenter Netzwerke ohne Rekurrenz
Pretraining rekurrenter Netzwerke ohne Rekurrenz
Akarsh Kumar
Zusammenfassung
Das Training rekurrenter neuronaler Netze (RNNs) erfordert die Zurechnung von Kredits (Credit Assignment) über lange Berechnungssequenzen. Das herkömmliche Backpropagation Through Time (BPTT) löst dieses Problem unzureichend: Es ist sequenziell in der Zeit und damit in seiner Parallelisierbarkeit begrenzt; zudem leidet es unter verschwindenden oder explodierenden Gradienten, was das Erlernen langreichweitiger Abhängigkeiten erschwert.Wir schlagen das Supervised Memory Training (SMT) vor, ein Verfahren zum Training nichtlinearer RNNs, das die rekursive Kreditweitergabe vollständig umgeht, indem es das RNN-Training auf ein überwachtes Lernen an einstufigen Speicher-Übergangslabels (mt,xt+1)→mt+1 zurückführt. SMT gewinnt diese Speicherlabels, indem es einen Transformer-basierten Encoder auf ein prädiktives Zustandsziel trainiert – dabei wird ausschließlich die aus der Vergangenheit stammende Information beibehalten, die zur Vorhersage der Zukunft notwendig ist.Durch die Entkopplung dessen, was erinnert werden soll, von der Art und Weise, wie der Speicher aktualisiert wird, ermöglicht SMT ein zeitparallelisiertes Training von RNNs mit einem stabilen Gradientenpfad der Länge O(1) zwischen beliebigen zwei Tokens – und dies ohne jemals das RNN auszurollen (unrolling). Wir zeigen, dass SMT BPTT bei der Pretraining-Phase verschiedener RNN-Architekturen auf Aufgaben wie Language Modeling und der Modellierung von Pixelsequenzen übertrifft. SMT befähigt nichtlineare RNNs dazu, langreichweitige Abhängigkeiten besser zu erfassen und parallel zu trainieren, was das Scaling von Modellen potentialisiert, die zeitliche Abstraktionen vergangener Erfahrungen aufbauen.
One-sentence Summary
The authors propose Supervised Memory Training (SMT), a method for training nonlinear RNNs that sidesteps recurrent credit propagation by reducing training to supervised learning on one-step memory transition labels acquired via a Transformer-based encoder, decoupling what to remember from how to update memory to enable time-parallel training with stable O(1) gradient paths without unrolling while outperforming BPTT on language modeling and pixel sequence modeling tasks.
Key Contributions
- Supervised Memory Training (SMT) reduces RNN training to supervised learning on one-step memory transition labels (mt,xt+1)→mt+1. This approach sidesteps recurrent credit propagation by using a Transformer-based encoder to acquire memory labels, enabling time-parallel training without unrolling the RNN.
- Decoupling what to remember from how to update memory enables a stable O(1) length gradient path between any two tokens. This capability allows nonlinear RNNs to capture long-range dependencies more effectively than standard backpropagation through time.
- SMT outperforms backpropagation through time when pretraining various RNN architectures on tasks like language modeling and pixel sequence modeling. These findings support the potential for scaling models that build temporal abstractions of past experience.
Introduction
Recurrent Neural Networks offer fixed memory size ideal for unbounded sequences, yet training them via Backpropagation Through Time remains problematic due to sequential processing and unstable gradients. While Transformers enable parallel training, their memory requirements grow with sequence length, and linear RNN variants lack the expressivity needed for complex tasks. The authors propose Supervised Memory Training to decouple memory representation from dynamics by leveraging a Transformer encoder to generate optimal memory states in parallel. This allows the RNN to learn one-step updates without unrolling, achieving stable O(1) credit assignment and time-parallel training while maintaining nonlinear expressivity and fixed inference memory.
Dataset
The authors evaluate their model using a benchmark composed of synthetic algorithmic tasks and natural data modeling datasets.
Synthetic Algorithmic Tasks
- Retrieval: Tests gradient stability by requiring prediction of the token following a designated identifier, with occasional label corruption.
- String Copy: Measures memory capacity by requiring the model to reproduce a sequence in reverse order after a delimiter.
- Stack Operations: Evaluates state tracking capabilities through a sequence of push and pop operations.
- Keys and Values: Assesses associative recall by storing and retrieving key-value pairs.
- Modular Arithmetic: Probes in-context learning by inferring linear rules from in-context examples.
- Configuration: Sequence lengths and difficulty parameters vary across tasks to test stability and capacity.
Natural Data Modeling Tasks
- TinyStories: A curated collection of short stories generated by GPT-4. The authors use ASCII character-level tokenization resulting in a 256-token vocabulary. The training and test sets contain 1.9B and 19.2M tokens respectively.
- MNIST: Handwritten digit images flattened into 1D pixel sequences of length 784. Raw grayscale pixel intensities create a 256-token vocabulary. The training and test sets contain 47M and 7.8M tokens respectively.
- Sketchy: Human-drawn sketches resized to 64x64 and binarized. Non-overlapping 2x2 patches form a 16-token vocabulary for sequences of length 1024. The training and test sets contain 69.5M and 7.7M tokens respectively.
Method
The authors propose Supervised Memory Training (SMT) to address the limitations of Backpropagation Through Time (BPTT), such as sequential computation and vanishing gradients. The core methodology decouples the learning of memory representation from memory dynamics, enabling time-parallel training with stable gradient paths.
Framework Overview
Standard BPTT unrolls the recurrent computation graph sequentially, requiring gradients to propagate through the entire history of the sequence. In contrast, SMT sidesteps recurrent credit propagation by reducing RNN training to supervised learning on one-step memory transition labels.
Refer to the framework diagram which contrasts the sequential nature of BPTT with the parallel structure of SMT. In the BPTT approach (left side), the memory state is updated recurrently, and gradients must flow back through every timestep. In the SMT approach (right side), a Transformer-based encoder generates memory labels from the past context, and the RNN is trained to predict the next memory state from the current state and input. This creates a stable O(1) gradient path between any two tokens, as the long-range credit assignment is handled by the parallel encoder-decoder pair rather than the recurrent loop.
Model Architecture
The system consists of three primary components: a bidirectional encoder, a causal decoder, and the RNN updater.
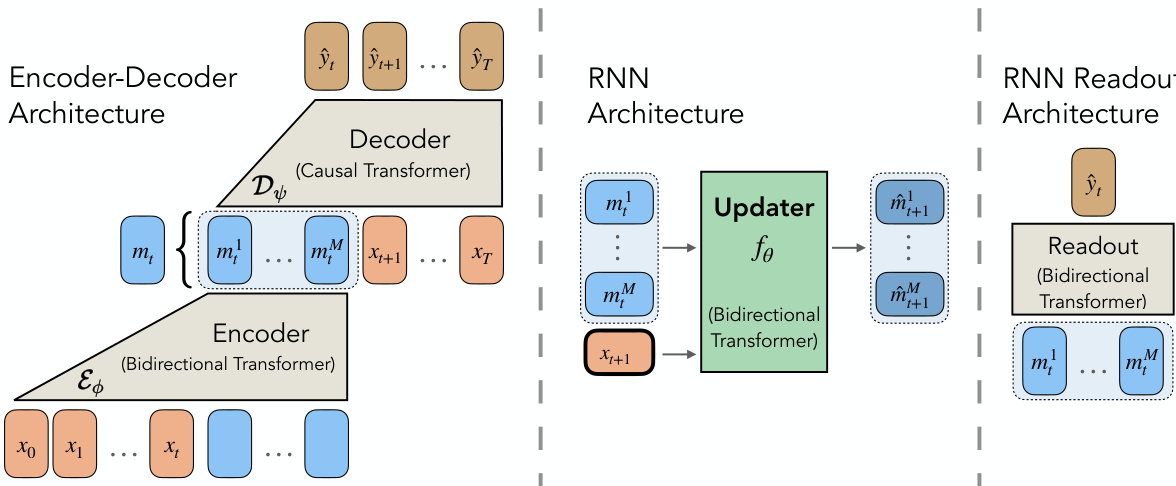
The Encoder-Decoder architecture is detailed in the middle diagram. The encoder Eϕ processes the past context xtctx to produce a compressed memory representation mt. This memory is then passed to the decoder Dψ, which predicts the future output sequence ytfut given the memory and future inputs xtfut. This setup forces the encoder to retain only information necessary for predicting the future.
The RNN architecture, shown in the center block, utilizes an Updater module fθ (implemented as a Bidirectional Transformer) to map the current memory tokens and the next input token to the next memory state m^t+1. Finally, the Readout Architecture (right block) processes the memory tokens through a Bidirectional Transformer to generate the output prediction y^t.
Training Objectives
The training process involves optimizing three distinct loss functions. First, a decoding loss Ldec ensures the memory representation is sufficient for the decoder to predict future tokens. Second, a dynamics loss Ldyn trains the RNN to mimic the encoder's memory transitions using Mean Squared Error:
Ltdyn=MSE(m^t+1,mt+1)This explicitly shapes the encoder memory representations to be Markovian, meaning mt+1 is predictable solely from (mt,xt+1). Third, a uniformity loss Lunif is added to prevent the memory space from collapsing into a single point.
DAgger Memory Training (DMT)
While SMT trains the RNN on encoder-generated labels, evaluation requires the RNN to unroll autoregressively using its own predicted memories. This creates a train-test mismatch where small prediction errors accumulate over time, causing the RNN trajectory to drift from the optimal encoder trajectory.
To correct this, the authors introduce DAgger Memory Training (DMT) as a fine-tuning phase. The visualization of SMT versus DMT trajectories illustrates this concept. In SMT, the RNN follows the encoder trajectory (green solid line) during training. In DMT, the RNN is unrolled to generate its own trajectory (green dashed line), and the loss is computed to pull these predicted states back toward the encoder states, effectively performing on-policy imitation learning to reduce drift δt.
Memory Space Properties
The method enables the RNN to learn structured memory spaces capable of handling complex dependencies. Visualizations of the memory space for retrieval tasks demonstrate how the model organizes information.
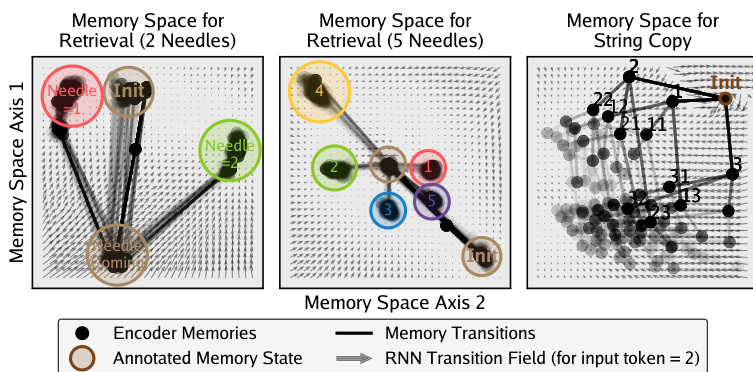
These plots show memory states clustering around specific "needles" of information or following transition paths for string copying tasks. The vector field indicates the RNN transition dynamics, showing how the model learns to navigate the memory space to retrieve relevant past information or maintain state over long sequences.
Experiment
The study evaluates Supervised Memory Training (SMT) combined with Dynamic Memory Training (DMT) against standard Backpropagation Through Time (BPTT) across synthetic benchmarks, natural language modeling, and pixel sequence modeling tasks. Qualitative results demonstrate that SMT stabilizes gradients by maintaining constant credit path lengths, enabling RNNs to capture long-range dependencies and perform state tracking more effectively than BPTT, which suffers from recency bias. Additionally, the method achieves higher sequential compute efficiency and smooth scaling behavior while allowing RNNs to generalize to sequence lengths beyond their training horizon better than Transformer baselines.
The authors analyze the computational complexity of their proposed SMT and DMT methods against standard BPTT and Transformer baselines. The data shows that SMT achieves constant credit path lengths and sequential operations during training, while BPTT scales linearly with sequence length. Furthermore, recurrent methods maintain constant inference costs, contrasting with Transformers whose inference complexity grows with sequence length. SMT training involves constant credit path length and sequential operations, unlike BPTT which scales linearly. Recurrent methods maintain constant memory and compute costs during inference, unlike Transformers which scale linearly. SMT allows for fully time-parallel training, significantly reducing sequential operations compared to the sequential processing required by BPTT.

The authors analyze the computational complexity of their proposed SMT and DMT methods against standard BPTT and Transformer baselines. The data shows that SMT achieves constant credit path lengths and inference costs, whereas BPTT and Transformers scale linearly with sequence length. Additionally, SMT allows for fully time-parallel training, significantly reducing sequential operations compared to the sequential processing required by BPTT.