Command Palette
Search for a command to run...
InCoder-32B-Thinking: Ein industrielles Code-World-Modell für das Thinking
InCoder-32B-Thinking: Ein industrielles Code-World-Modell für das Thinking
Zusammenfassung
Die industrielle Softwareentwicklung im Bereich Chip-Design, GPU-Optimierung und eingebetteter Systeme leidet unter einem Mangel an expertenbasierten Reasoning-Traces, die aufzeigen, wie Ingenieure Hardware-Einschränkungen und Timing-Semantik analysieren. In dieser Arbeit stellen wir InCoder-32B-Thinking vor, ein Modell, das auf Daten des Error-driven Chain-of-Thought (ECoT)-Synthese-Frameworks trainiert wurde und ein industrial code world model (ICWM) nutzt, um solche Reasoning-Traces zu generieren. Konkret erzeugt ECoT Reasoning-Chains, indem es Denkprozesse aus mehrstufigen Dialogen unter Einbeziehung von Umwelt-Fehler-Feedback synthetisiert und dabei den Fehlerkorrekturprozess explizit modelliert. Das ICWM wird auf domänenspezifischen Execution-Traces aus Verilog-Simulationen, GPU-Profiling und ähnlichen Quellen trainiert; es erlernt die kausalen Dynamiken, mit denen Code das Hardware-Verhalten beeinflusst, und ermöglicht eine Selbstvalidierung, indem es Ausführungsergebnisse bereits vor der tatsächlichen Kompilierung vorhersagt. Alle synthetisierten Reasoning-Traces werden durch domänenspezifische Toolchains validiert, wodurch Trainingsdaten entstehen, die der natürlichen Verteilung der Reasoning-Tiefe industrieller Aufgaben entsprechen. Die Evaluierung auf 14 allgemeinen Benchmarks (81,3 % auf LiveCodeBench v5) und 9 industriellen Benchmarks (84,0 % auf CAD-Coder und 38,0 % auf KernelBench) zeigt, dass InCoder-32B-Thinking in allen Domänen Ergebnisse auf Top-Niveau im Bereich Open Source erzielt. GPU-Optimierung.
One-sentence Summary
Researchers from Beihang University and IQest Research introduce InCoder-32B-Thinking, a model leveraging Error-driven Chain-of-Thought and an industrial code world model to generate expert reasoning traces for chip design and GPU optimization, achieving top-tier performance on general and specialized industrial benchmarks.
Key Contributions
- The paper introduces the Error-driven Chain-of-Thought (ECoT) synthesis framework, which generates reasoning traces by explicitly modeling the error-correction process through contrasting incorrect attempts with environmental feedback against correct solutions to capture iterative engineering refinement patterns.
- This work develops an Industrial Code World Model trained on domain-specific execution traces from Verilog simulation and GPU profiling to learn causal dynamics between code and hardware behavior, enabling self-verification and synthetic trace generation without expensive toolchain execution.
- The resulting InCoder-32B-Thinking model integrates ECoT-synthesized reasoning with world model predictions to achieve top-tier open-source results across 14 general and 9 industrial benchmarks, including 81.3% on LiveCodeBench v5 and 84.0% on CAD-Coder.
Introduction
Industrial software development in fields like chip design, GPU optimization, and embedded systems requires engineers to reason deeply about hardware constraints and timing semantics, yet existing datasets lack the expert reasoning traces needed to teach LLMs these complex skills. Prior approaches often focus on isolated sub-domains or rely on general web-scale corpora that fail to capture the specialized dynamics of industrial toolchains, leading to limited success in tasks like Verilog debugging or CUDA kernel optimization. To address this, the authors introduce InCoder-32B-Thinking, a model that combines an Error-driven Chain-of-Thought synthesis framework with a novel Industrial Code World Model to generate and validate reasoning traces using simulated hardware feedback.
Dataset
-
Dataset Composition and Sources The authors reuse the core data from InCoder-32B, which includes queries, unit tests, and execution environments. They package each task seed with its specific environmental context to create fully specified, reproducible execution pairs. For Verilog tasks, modules are bundled with testbenches and Yosys synthesis scripts, while STM32 firmware snippets are coupled with memory layouts, CMSIS headers, and linker scripts.
-
Key Details for Each Subset
- General Code Benchmarks: The suite covers code generation, reasoning, efficiency, text-to-SQL, agentic coding, and tool use using datasets like EvalPlus, BigCodeBench, FullStackBench, CRUXEval, LiveCodeBench, Mercury, Spider, BIRD, Terminal-Bench, SWE-bench Verified, Mind2Web, BFCL V3, and τ2-bench.
- Industrial Code Benchmarks: These focus on hardware and engineering-intensive tasks. Chip design benchmarks include VeriScope (568 problems), RealBench (60 module-level and 4 system-level subtasks), ArchXBench (51 designs), and the newly constructed VeriRepair (approx. 22,000 training and 300 test samples). GPU optimization uses KernelBench (250 PyTorch workloads) and TritonBench (184 real-world operators). Code optimization relies on EmbedCGen (500 embedded C problems) and SuperCoder (8,072 assembly programs). 3D modeling utilizes CAD-Coder, derived from Text2CAD with 110K triplets.
-
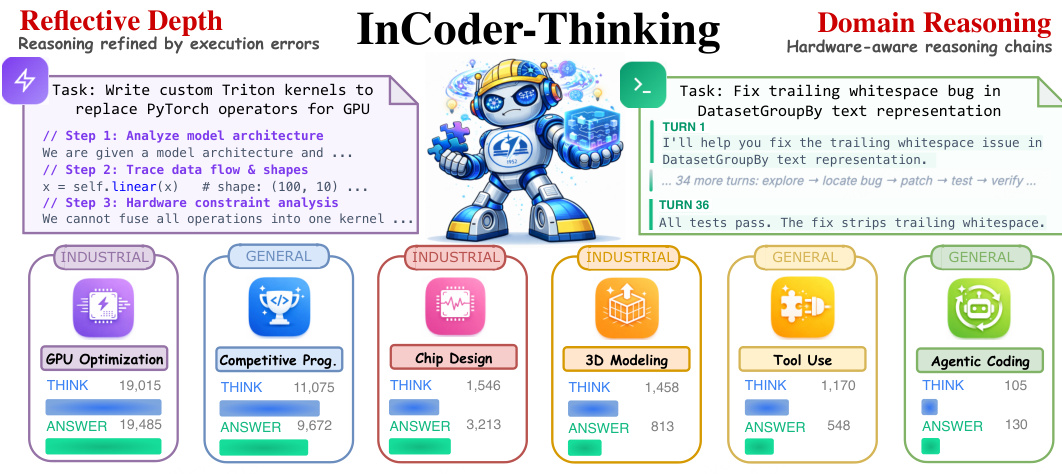
Model Usage and Training Strategy The training corpus is generated via an error-driven synthesis pipeline that creates reasoning traces based on real or simulated execution feedback rather than fixed templates. This process naturally produces a wide spectrum of thinking depths, ranging from 91 characters for agentic coding to 19,015 characters for GPU kernel optimization. The model learns to adaptively calibrate its reasoning effort, investing deep multi-step thinking for complex industrial backends while keeping traces succinct for tasks with short feedback loops.
-
Processing and Metadata Construction The authors construct task-environment pairs ⟨stask,senv⟩ to ensure every downstream step has a defined context. Verification pipelines are domain-specific, ranging from simulation and compilation checks for Verilog to cross-compilation and system-level simulation for embedded C. For benchmarks like VeriRepair, metadata includes buggy code, error categories, locations, corrected references, and testbenches. In CAD-Coder, data is stratified by quality into high, medium, and hard cases, with some samples annotated with chain-of-thought reasoning.
Method
The authors target a diverse set of industrial coding domains, ranging from GPU optimization and chip design to 3D modeling and agentic coding, as illustrated in the conceptual overview.
To address the complexity of these tasks, the authors leverage a two-phase data engine pipeline designed to synthesize error-driven thinking trajectories. This pipeline is detailed in the framework diagram below, which outlines the flow from task seeding to distributed execution and model training.
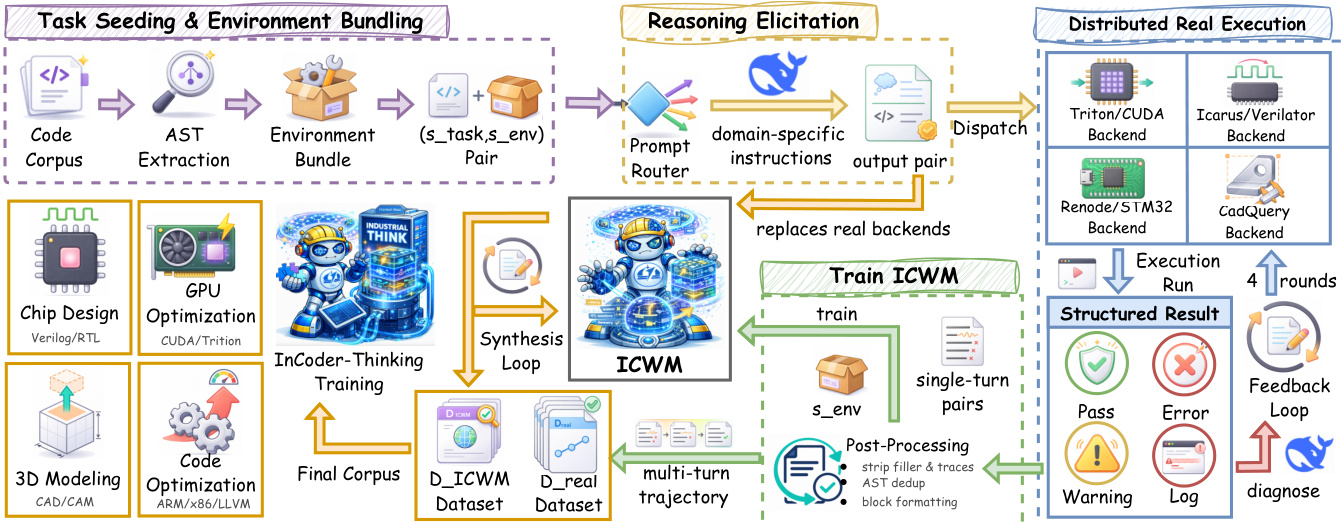
In the first phase, grounded collection, the authors begin with task seeding and environment bundling. Code corpora are processed to extract Abstract Syntax Trees (AST) and bundled with specific environment configurations. These pairs are passed to a reasoning elicitation module where a lightweight prompt router selects domain-specific instructions. For instance, GPU kernel tasks require reasoning about warp divergence, while RTL tasks focus on combinational path depth. The generator then produces an initial pair of reasoning content and code.
This candidate code is sent to distributed real execution backends such as Triton/CUDA, Renode, or CadQuery. Each backend returns a structured result containing an outcome label and diagnostic logs. When execution produces an error, the feedback is packaged as an observation and fed back to the generator for revision. This loop iterates for up to K correction rounds, yielding a multi-turn trajectory τ that captures the reasoning steps required to resolve failures.
To scale this process, the second phase employs ICWM driven data amplification. The collected real trajectories are used to train an Industrial Code World Model (ICWM), which serves as a learned proxy for the execution backends. The ICWM takes the environment bundle senv and a candidate program c(k) as input to predict the observable feedback o^(k). Once trained, the ICWM replaces the real backends in the feedback loop, enabling large-scale trajectory synthesis without the computational cost of repeated real execution. The final training corpus combines data from both real execution and ICWM simulation.
Experiment
- General and industrial code benchmarks validate that InCoder-32B-Thinking achieves superior code reasoning, outperforming larger open-weight models and proprietary systems in chip design and GPU optimization while remaining competitive in general generation tasks.
- Fidelity analysis confirms that the Industrial Code World Model reliably substitutes real execution backends for large-scale trajectory synthesis, with high accuracy in predicting outcomes and maintaining consistency across multi-turn error-correction sequences.
- Scaling experiments demonstrate that increasing thinking training data from 180M to 540M tokens consistently enhances deep reasoning capabilities and industrial coding skills, though specific complex optimization tasks may require targeted strategies beyond data volume alone.
- Overall conclusions indicate that combining error-driven chain-of-thought synthesis with a domain-specific world model effectively bridges general programming ability and the rigorous demands of hardware-aware industrial software development.