Command Palette
Search for a command to run...
Der latente Raum: Grundlagen, Evolution, Mechanismen, Fähigkeiten und Ausblick
Der latente Raum: Grundlagen, Evolution, Mechanismen, Fähigkeiten und Ausblick
Zusammenfassung
Der latente Raum entwickelt sich rasch zu einer nativen Substratplattform für sprachbasierte Modelle. Obwohl moderne Systeme nach wie vor häufig über eine explizite Token-Ebene-Generierung verstanden werden, zeigt eine wachsende Zahl von Studien, dass viele kritische interne Prozesse natürlicher im kontinuierlichen latenten Raum als in für Menschen lesbaren verbalen Spuren ablaufen. Dieser Wandel wird durch strukturelle Grenzen der explizit-räumlichen Berechnung vorangetrieben, darunter linguistische Redundanz, Diskretisierungsengpässe, sequenzielle Ineffizienz und semantischer Informationsverlust. Diese Übersichtsarbeit zielt darauf ab, ein einheitliches und aktuelles Bild des latenten Raums in sprachbasierten Modellen zu vermitteln. Wir gliedern die Übersichtsarbeit in fünf aufeinanderfolgende Perspektiven: Fundament, Evolution, Mechanismus, Fähigkeiten und Ausblick. Zunächst grenzen wir den Geltungsbereich des latenten Raums ab und unterscheiden ihn sowohl vom expliziten bzw. verbalen Raum als auch von den in generativen visuellen Modellen üblicherweise untersuchten latenten Räumen. Anschließend verfolgen wir die Entwicklung des Forschungsfelds von frühen explorativen Ansätzen bis hin zur derzeitigen großflächigen Expansion. Um die technische Landschaft zu strukturieren, betrachten wir bestehende Arbeiten durch die komplementären Perspektiven von Mechanismus und Fähigkeiten. Aus der Perspektive des Mechanismus identifizieren wir vier zentrale Entwicklungslinien: Architektur, Repräsentation, Berechnung und Optimierung. Aus der Perspektive der Fähigkeiten zeigen wir auf, wie der latente Raum ein breites Spektrum an Fähigkeiten unterstützt, das von Reasoning, Planning, Modeling, Perception, Memory, Collaboration bis hin zu Embodiment reicht. Über die Konsolidierung bestehender Erkenntnisse hinaus diskutieren wir wesentliche offene Herausforderungen und skizzieren vielversprechende Richtungen für zukünftige Forschung. Wir hoffen, dass diese Übersichtsarbeit nicht nur als Referenz für bestehende Arbeiten dient, sondern auch als Fundament für das Verständnis des latenten Raums als allgemeines Rechen- und Systemparadigma für die nächste Generation künstlicher Intelligenz.
One-sentence Summary
Researchers from National University of Singapore, Fudan University, Tsinghua University, and other leading institutions propose a unified survey on latent space in language-based models, introducing a two-dimensional taxonomy of mechanisms and abilities to consolidate fragmented literature and guide future research in reasoning, perception, and embodied AI.
Key Contributions
- The paper introduces a unified survey framework organized around five sequential perspectives—Foundation, Evolution, Mechanism, Ability, and Outlook—to consolidate fragmented literature on latent space in language-based models.
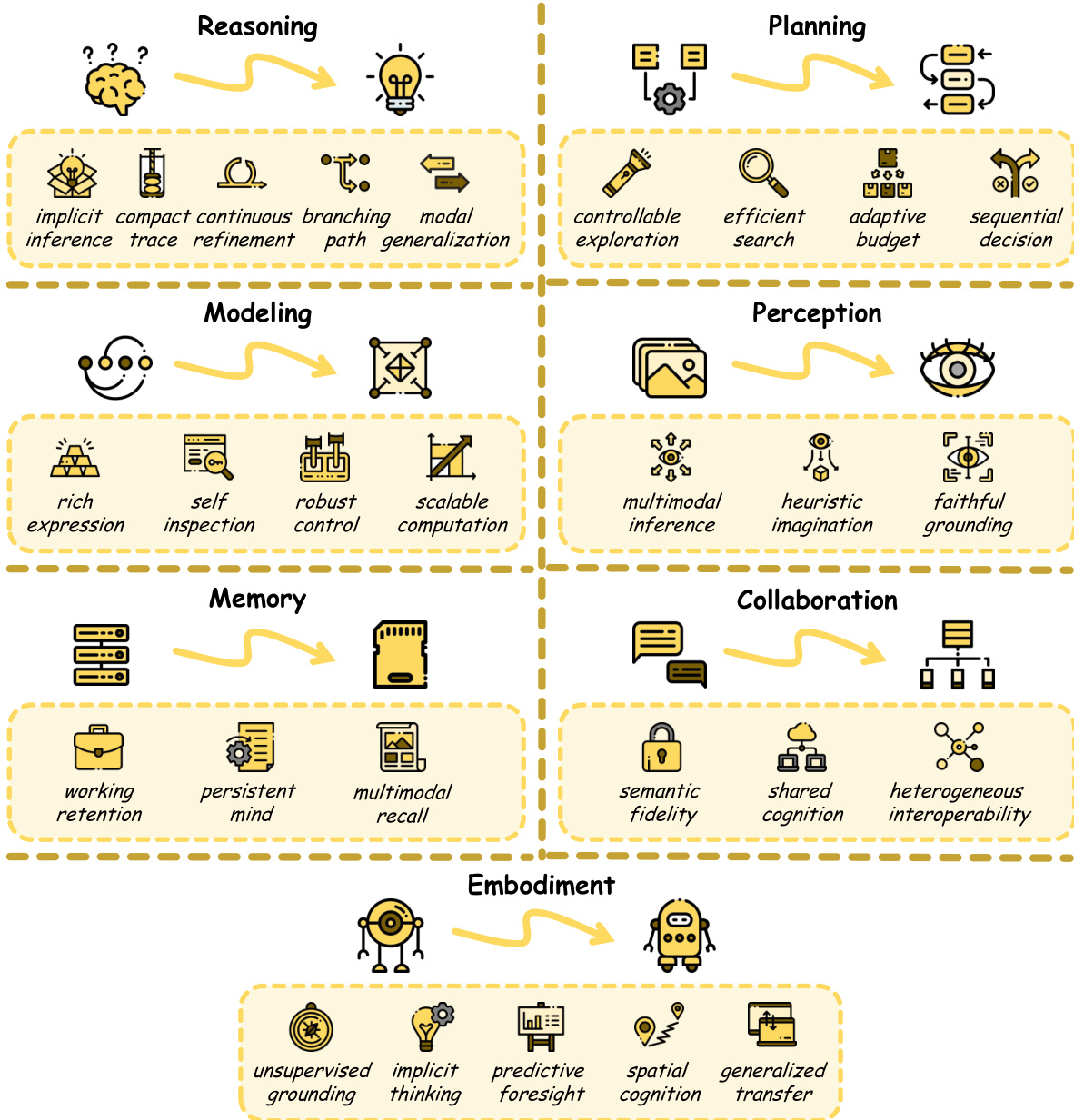
- This work presents a comprehensive technical taxonomy that classifies existing methods into four mechanism categories (Architecture, Representation, Computation, Optimization) and seven ability domains (Reasoning, Planning, Modeling, Perception, Memory, Collaboration, Embodiment).
- The study delineates the conceptual scope of latent space by distinguishing it from explicit token-level generation and visual generative models, while outlining open challenges and future research directions for next-generation intelligence.
Introduction
Language-based models are increasingly shifting from explicit token-level generation to continuous latent space as a native computational substrate, driven by the need to overcome linguistic redundancy, discretization bottlenecks, and sequential inefficiencies inherent in verbal traces. Prior research has largely remained fragmented across specific tasks like latent reasoning or visual understanding, lacking a unified framework to classify the diverse mechanisms and capabilities emerging in this field. The authors address this gap by providing a comprehensive survey that organizes the landscape into five sequential perspectives and introduces a two-dimensional taxonomy based on technical mechanisms and functional abilities to guide future research.
Method
The authors propose a unified framework to categorize how latent space is instantiated and operationalized within modern language-based systems. This mechanism-oriented taxonomy organizes diverse approaches along four complementary axes: Architecture, Representation, Computation, and Optimization. As illustrated in the framework diagram, these dimensions collectively define the design space for latent-space methods, clarifying how latent variables are constructed, processed, and refined.
The architectural axis characterizes the structural role of latent space in the model. Methods are classified into three categories based on where latent computation is embedded. First, Backbone-based approaches endow the main model with native latent capacity through recurrent, looping, or recursive structures, making latent operation a primitive of the architecture itself. Second, Component-based methods preserve the original backbone but augment it with functional modules that construct, transform, store, or retrieve latent representations. Third, Auxiliary Model-based paradigms utilize an extra model to provide supervision signals or intermediate features to guide or supplement the host model. The taxonomy of representative works across these architectural choices is detailed in the grid diagram.

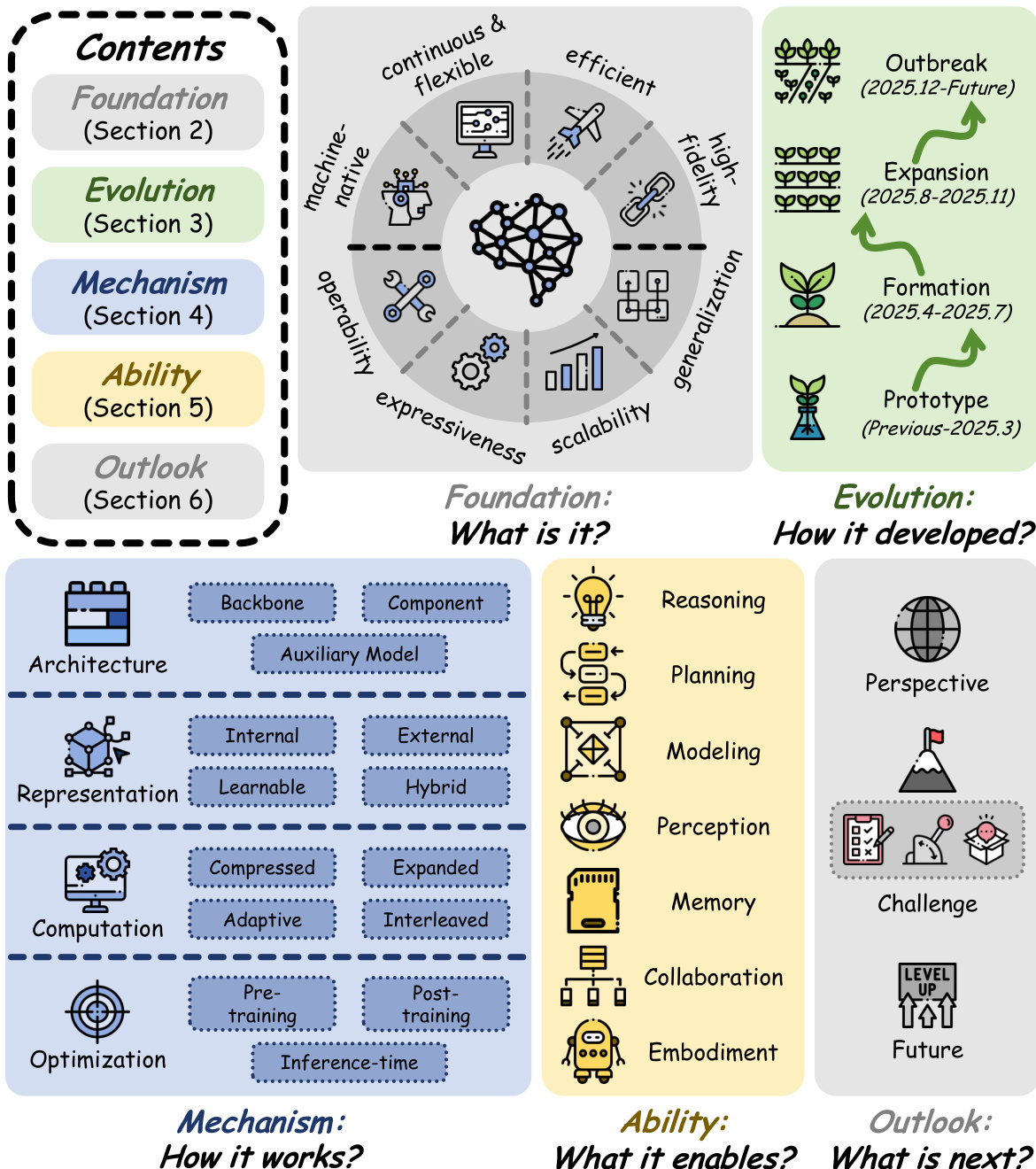
The representation axis describes the form of latent variables, distinguishing how information is encoded and integrated. Internal representations operate directly on activations produced during the backbone's forward pass, such as token embeddings or hidden states, without introducing additional parameters. External representations are derived from a structurally independent auxiliary system and injected into the backbone as conditioning inputs. Learnable representations are constructed by dedicated trainable modules embedded directly into the backbone and optimized end-to-end. Hybrid representations combine the Learnable and External paradigms by first using trainable modules to create specialized representations, then injecting them as exogenous signals. The schematic diagram illustrates these four sub-types and their data flow.
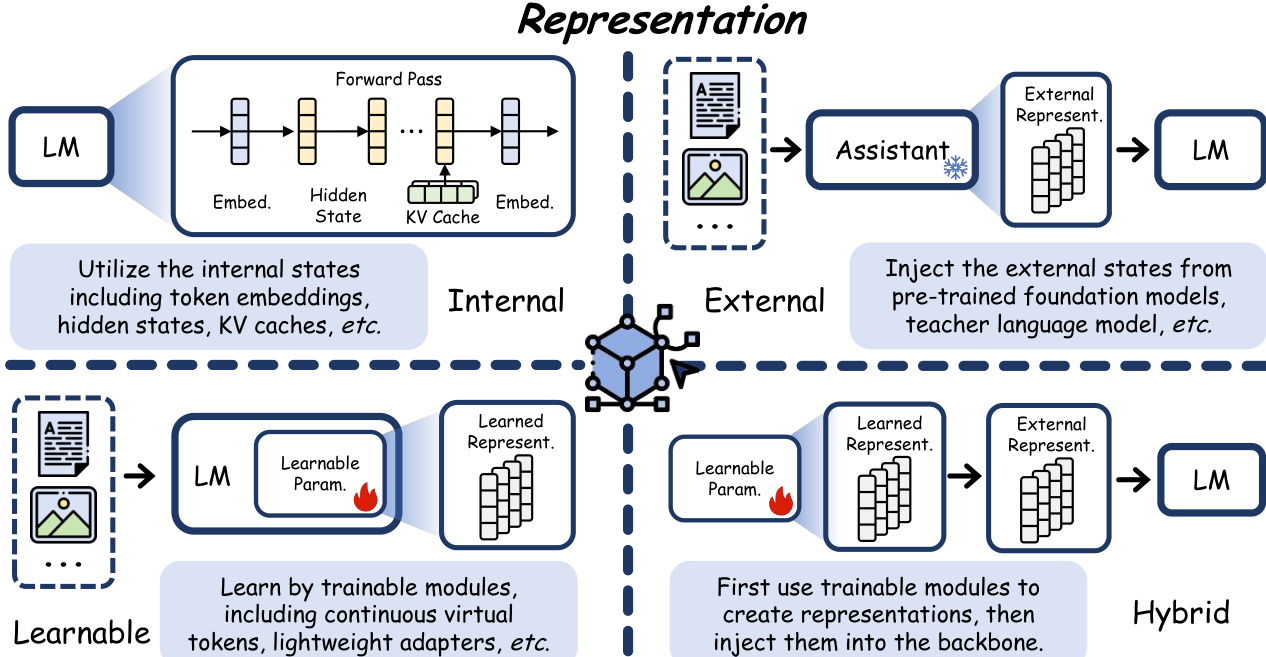
The computation axis captures how the latent space participates in information processing. Compressed computation reduces the volume of explicit traces or internal states to enhance efficiency while preserving expressiveness. Expanded computation increases effective capacity by extending latent processes along depth or width dimensions, such as through recurrent or parallel designs. Adaptive computation allocates resources dynamically based on input complexity, balancing capacity and efficiency flexibly. Interleaved computation bridges heterogeneous generation media, alternating between discrete tokens and continuous latents to combine explicit interpretability with implicit power. The corresponding schematic outlines these four computational strategies.
The optimization axis focuses on when and how latent space is induced, aligned, or refined. Pre-training methods start with a randomly initialized model and train it from scratch to enable native latent-level abilities. Post-training enhances the ability of pre-trained models using diverse supervision signals and objectives to learn the latent space. Inference-time methods focus on the manipulation of latent states during test time, allowing for dynamic adjustment without modifying model weights. The overview table summarizes the supervision, objective, and scenarios for each optimization stage.
Experiment
- A comparative analysis was conducted between the latent space and traditional explicit (verbal) space to clarify the unique characteristics of the latent representation.
- The experiment validates a paradigm shift in the representational properties and functional capabilities of language models when utilizing latent space versus explicit space.