Command Palette
Search for a command to run...
Gemma 4 31B Lässt Sich Mit Einem Klick Bereitstellen Und Bietet Bis Zu 256K Kontextinformationen. Die Leistungsfähigkeit Ist Vergleichbar Mit Der Von Qwen 3.5 397B.

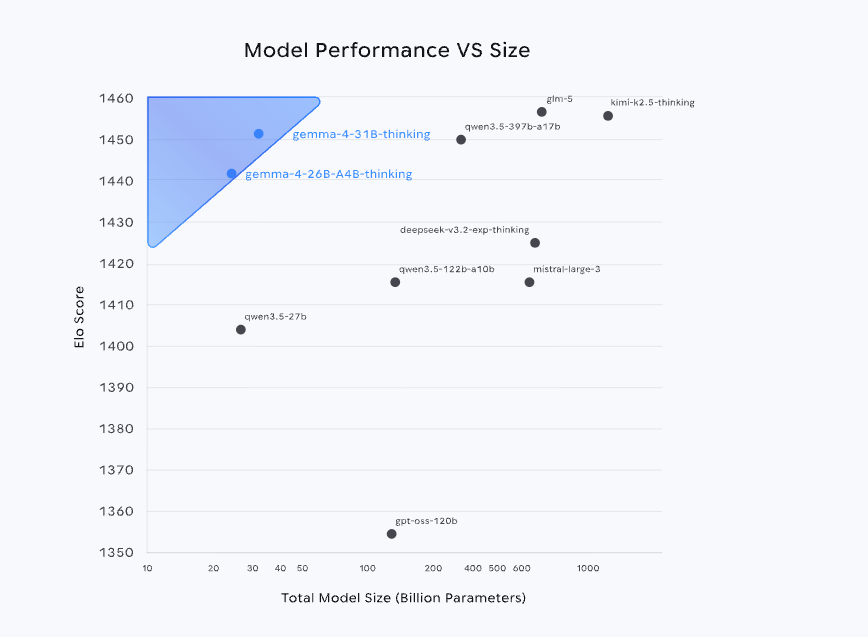
Kürzlich,Google DeepMind hat die Gemma 4-Modellreihe als Open Source veröffentlicht.Es nutzt dasselbe Technologiesystem wie Gemini 3 und zählt nicht nur zu den drei besten KI-Modellen weltweit in der Arena-Rangliste, sondern erzielt auch eine Leistung, die mit der größerer Modelle vergleichbar ist oder diese sogar übertrifft – und das mit einem deutlich kleineren Parameterumfang als die Konkurrenz. Darüber hinaus senkt die Open-Source-Strategie unter der Apache-2.0-Lizenz die Anwendungsschwelle weiter und erhöht so das Potenzial für den Einsatz in realen Produktionsumgebungen erheblich.
Aus der Perspektive der ProduktformGemma 4 ist kein einzelnes Modell, sondern ein System mit mehreren Größen, das E2B, E4B, 26B, A4B bis 31B umfasst.Diese Modelle sind für verschiedene Szenarien konzipiert, darunter mobile Geräte, lokale Bereitstellungen und Hochleistungsrechnerumgebungen. Der Kern dieses mehrschichtigen Designs besteht darin, Skalierbarkeit, Leistung und Kosten in Einklang zu bringen, um unterschiedlichen Anforderungen gerecht zu werden: Kleinere Modelle legen Wert auf geringen Ressourcenverbrauch und Echtzeitfähigkeit, während größere Modelle sich auf komplexe Inferenz- und hochpräzise Aufgaben konzentrieren.
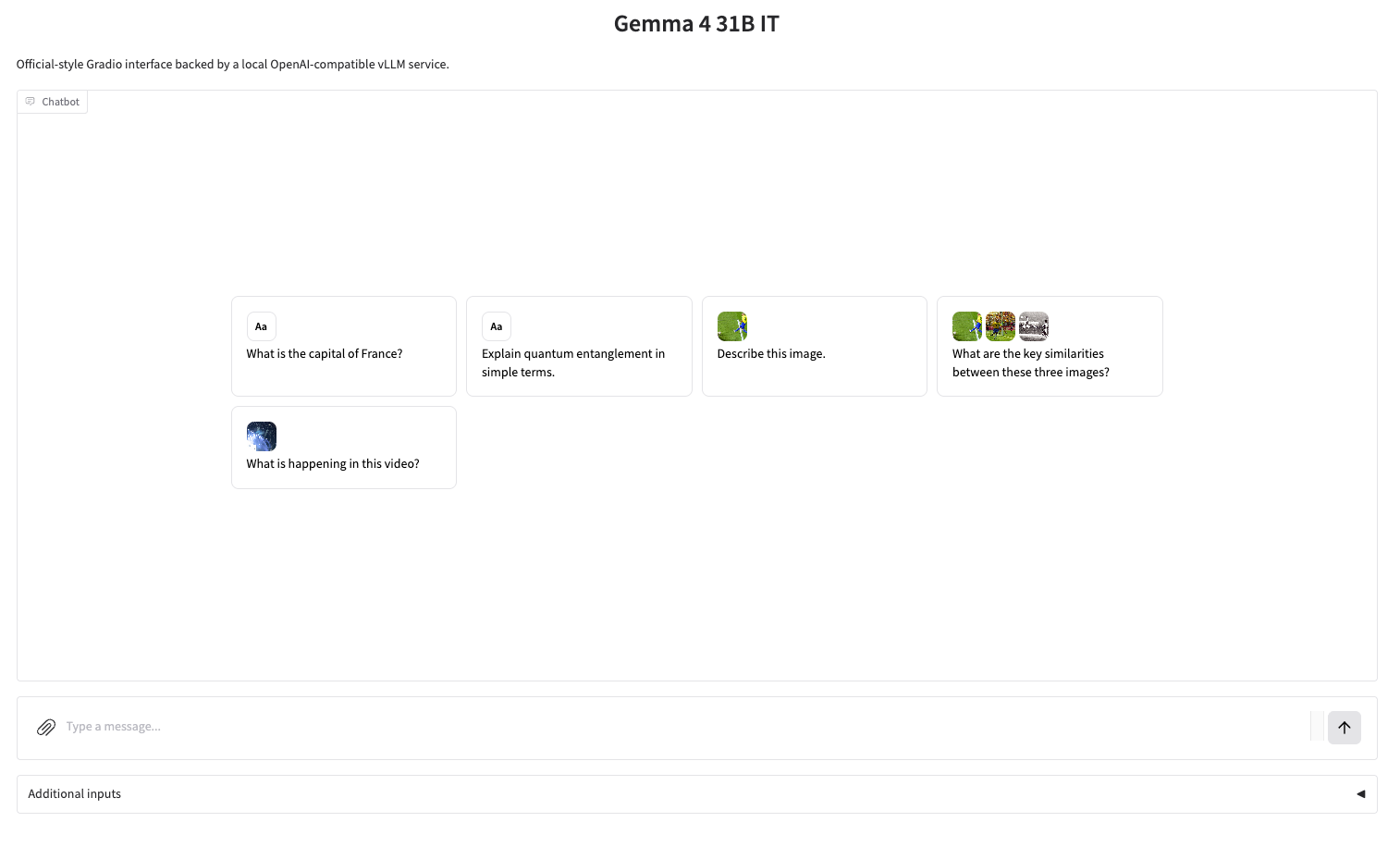
Die Version 31B, die als Leistungsmaximum der aktuellen Serie gilt, verfügt über vergleichbare Fähigkeiten wie Qwen 3.5 397B. Hinsichtlich der Anwendungsszenarien,Version 31B unterstützt Bild- und Texteingabe und -ausgabe, verfügt über ein Kontextfenster mit bis zu 256.000 Tokens und bietet native Unterstützung für Inferenz, Funktionsaufrufe und Systemeingabeaufforderungen. Zudem werden über 140 Sprachen unterstützt, wodurch sich die Software hervorragend für Anwendungsfälle wie hochwertige Fragebeantwortung, Codeunterstützung und Agentendienste eignet.
Aktuell bietet der Tutorial-Bereich der offiziellen Website von HyperAI (hyper.ai) das Projekt „One-click deployment of Gemma-4-31B-it“ an, um Entwicklern den Einstieg in fortgeschrittene Modelle zu erleichtern.
Online ausführen:
Demolauf
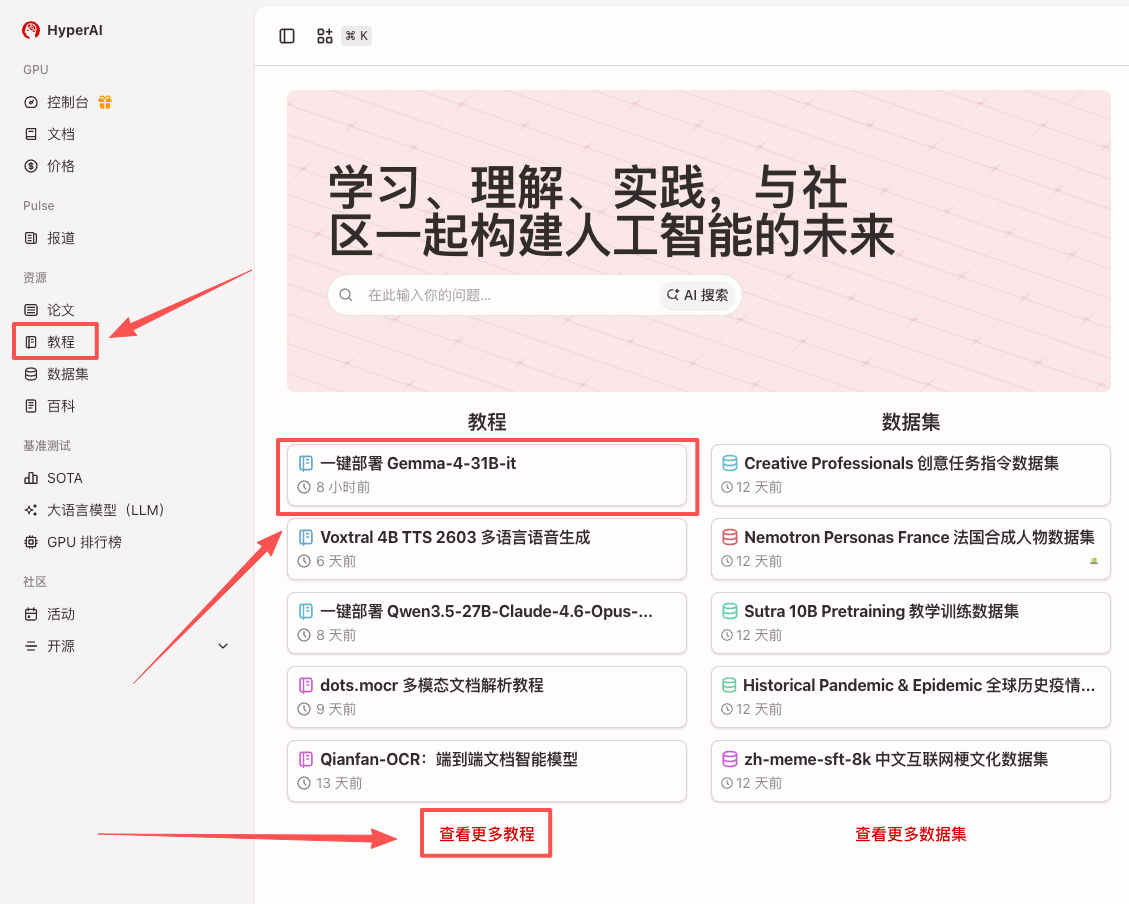
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „Ein-Klick-Bereitstellung von Gemma-4-31B-it“ aus und klicken Sie auf „Dieses Tutorial ausführen“.
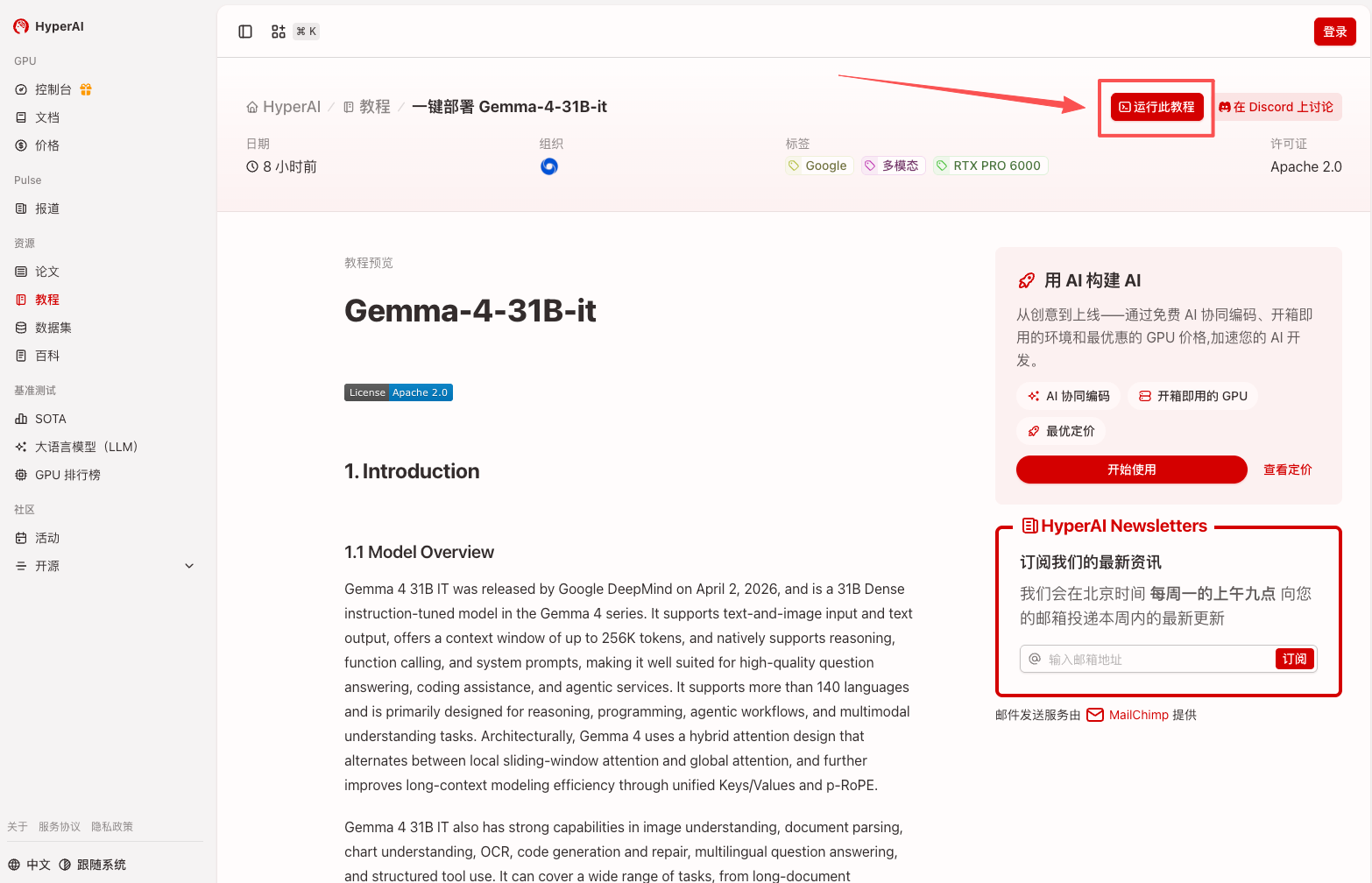
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
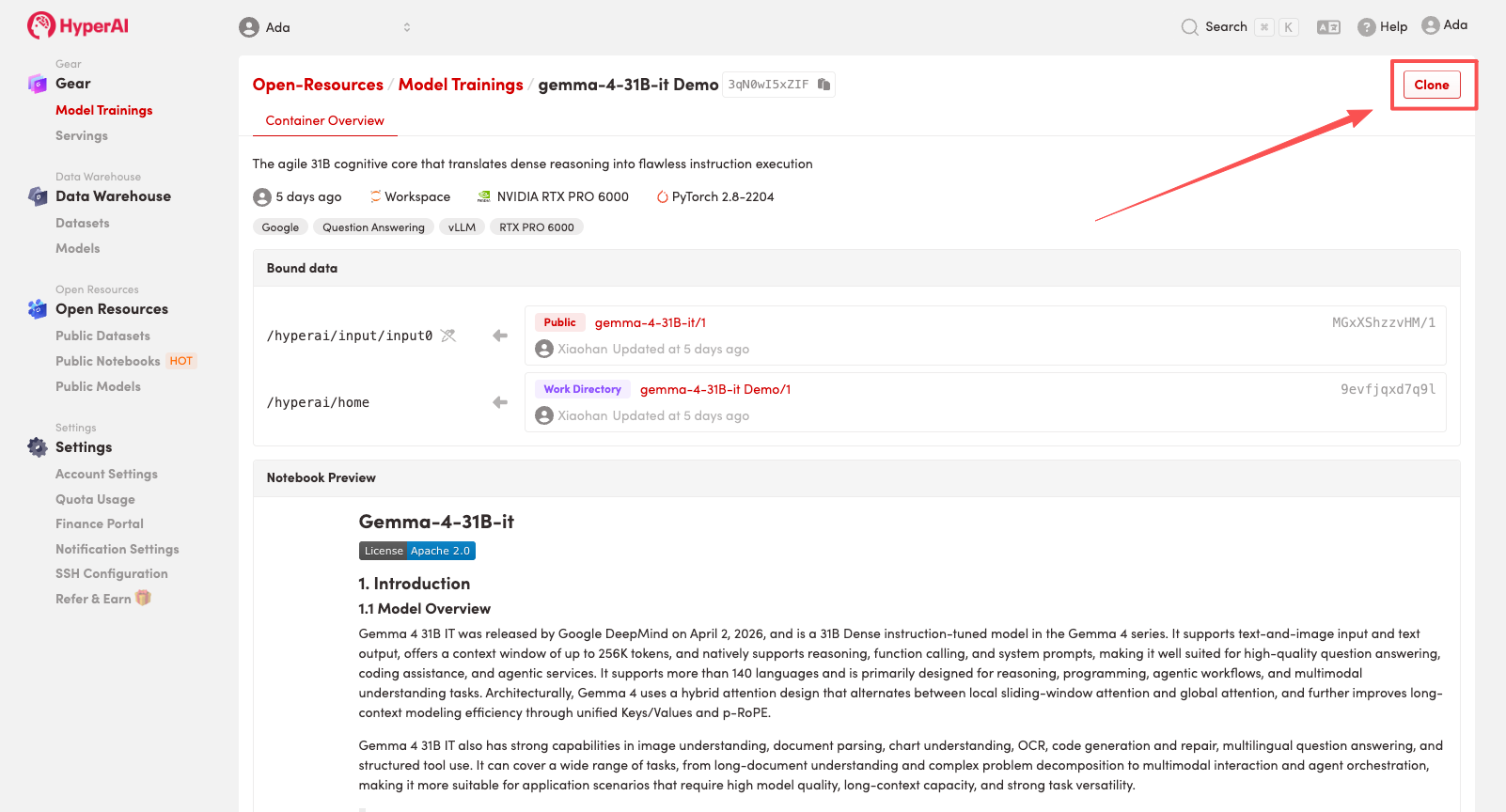
3. Wählen Sie die Images „NVIDIA RTX PRO 6000“ und „PyTorch“ aus und klicken Sie auf „Auftragsausführung fortsetzen“.
HyperAI bietet Neukunden einen Registrierungsbonus: Für nur $1 erhalten Sie 20 Stunden RTX 5090 Rechenleistung (ursprünglich $7), und die Ressourcen sind unbegrenzt gültig.
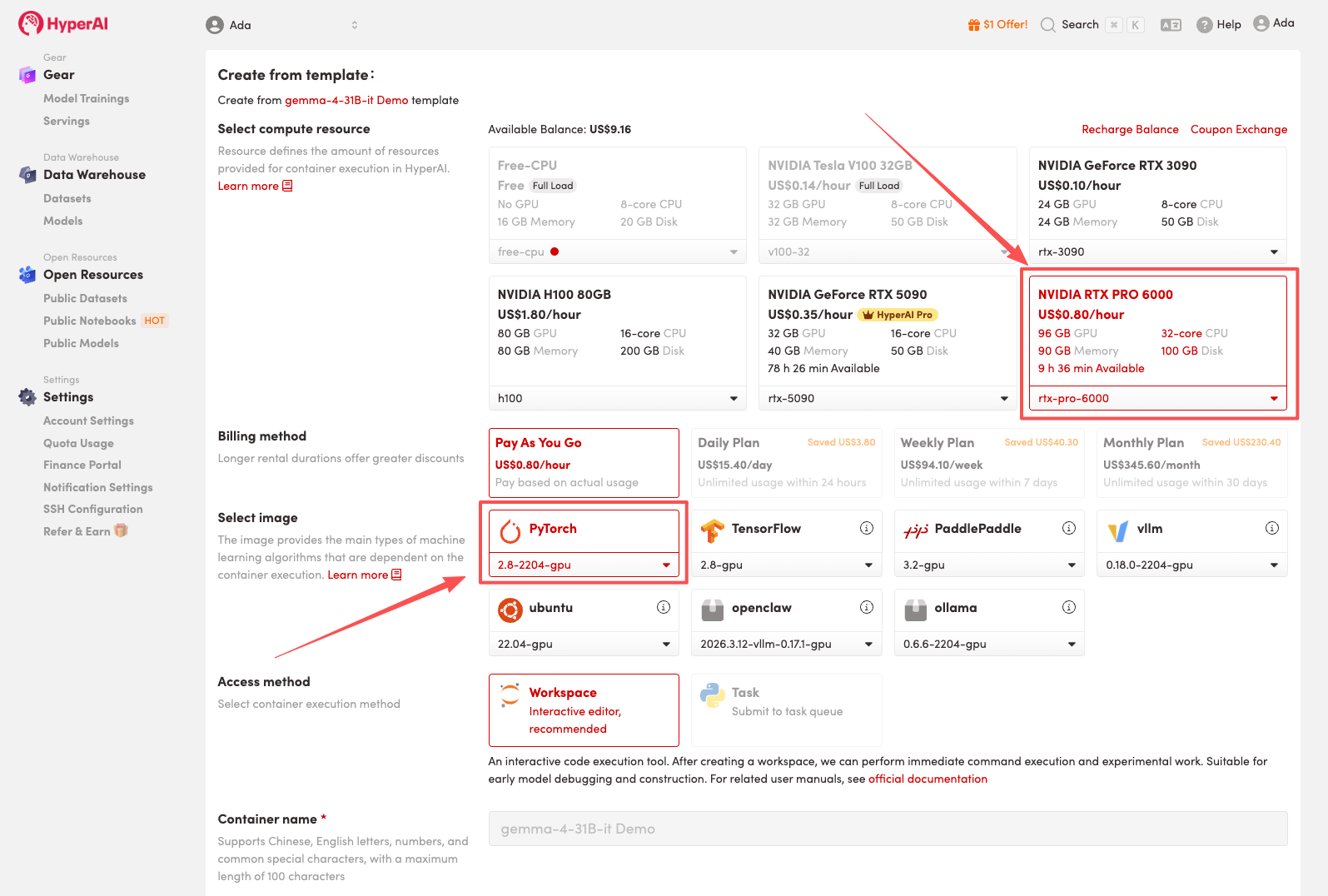
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
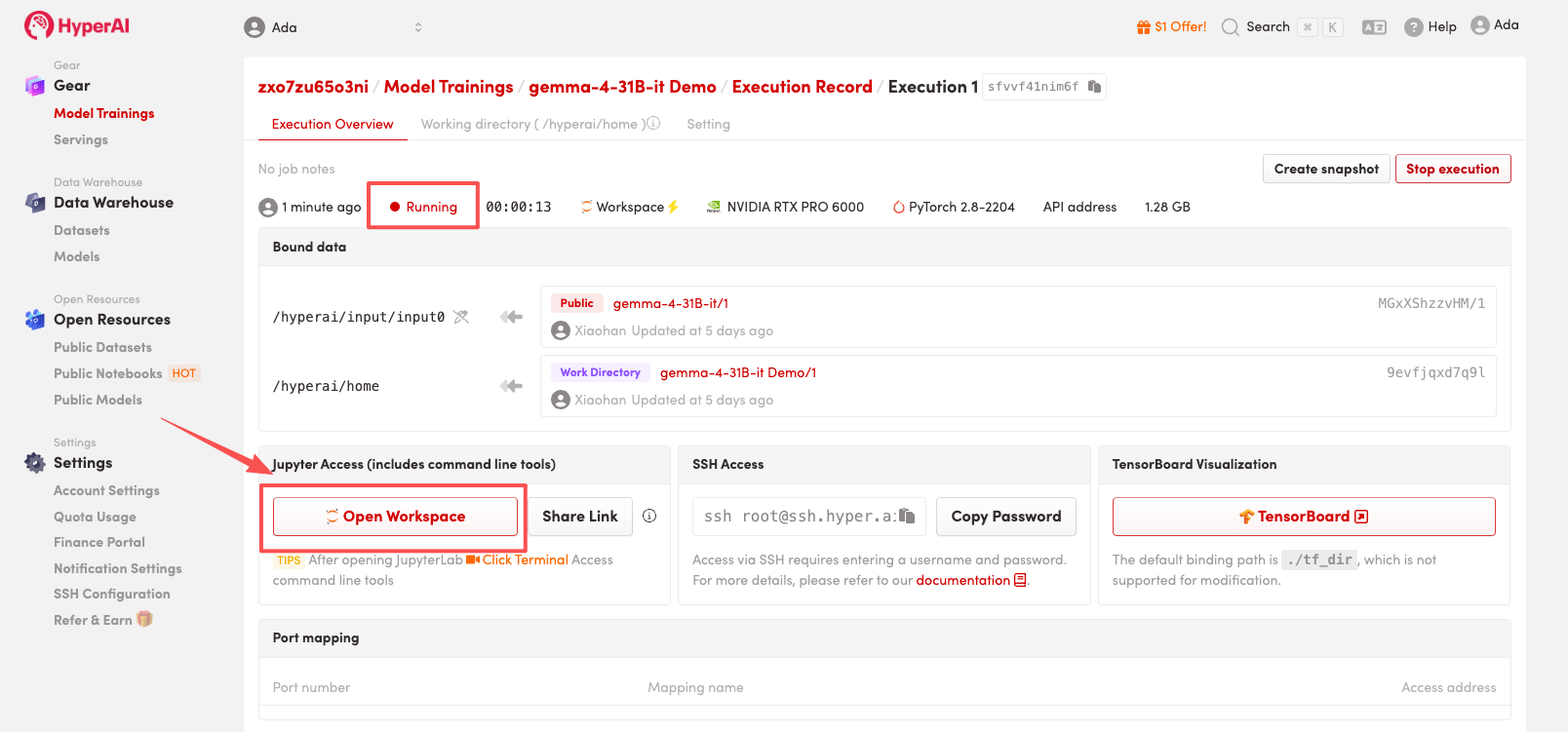
Effektanzeige
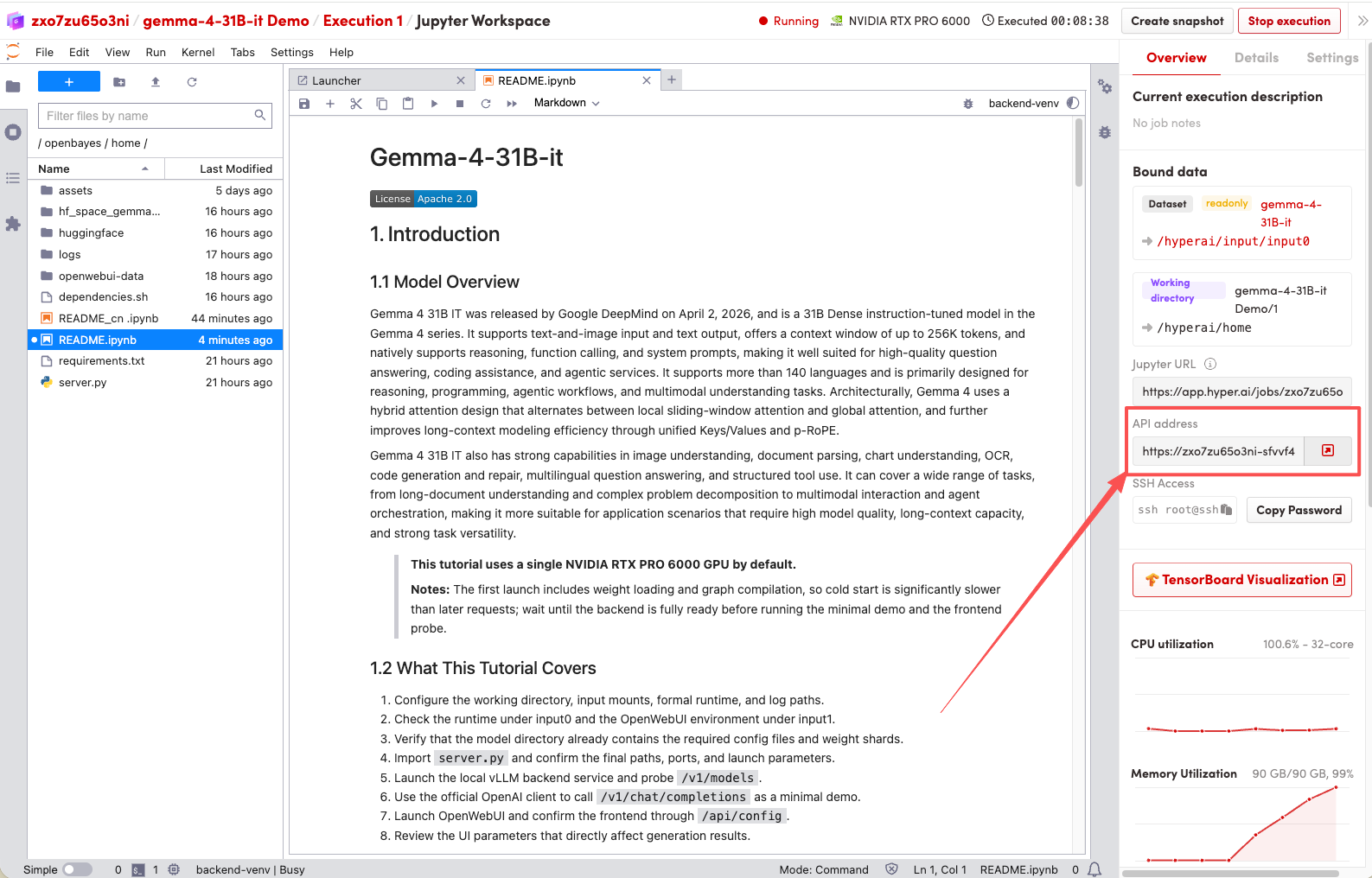
1. Nachdem die Seite weitergeleitet wurde, klicken Sie auf die README-Datei auf der linken Seite und anschließend oben auf Ausführen.
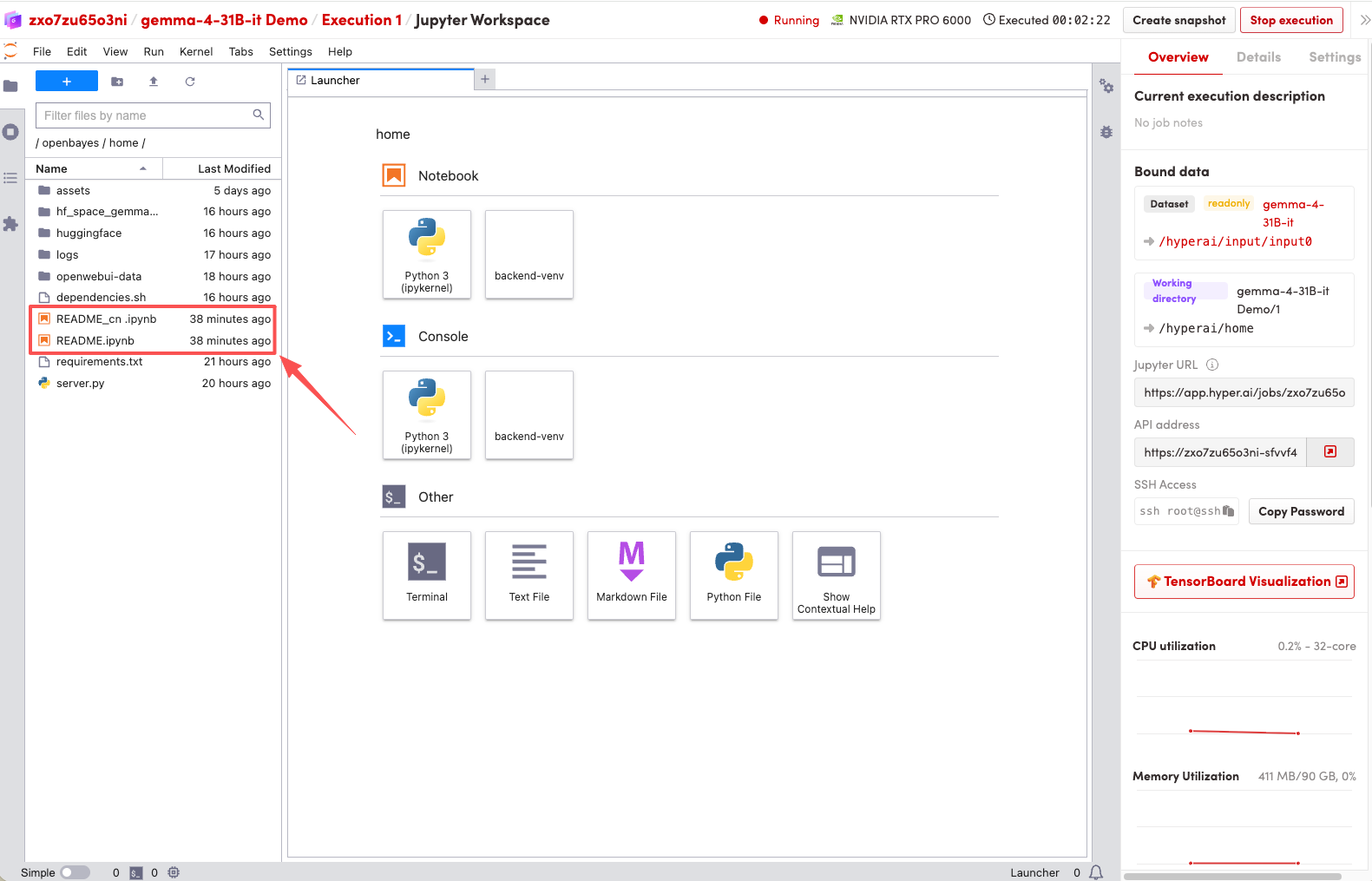
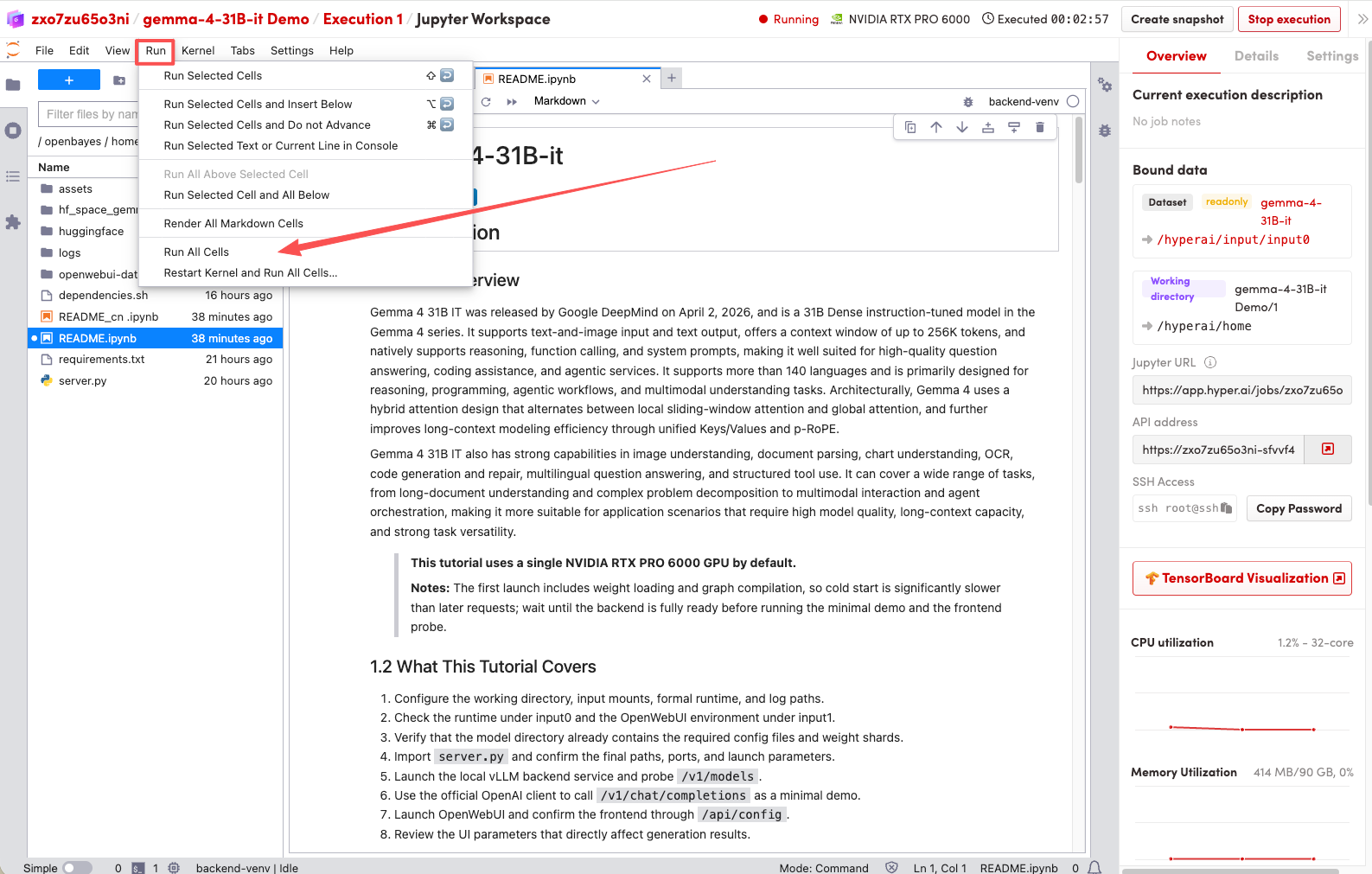
2. Sobald der Vorgang abgeschlossen ist, klicken Sie auf die API-Adresse rechts, um zur Demoseite zu gelangen.