Command Palette
Search for a command to run...
Online-Tutorial | Qwen 3.5 27B: Zusammenführung Der Inferenzfunktionen Von Claude 4.6 Opus – Balance Zwischen Hoher Ausgabequalität Und Einfacher Implementierung

In den letzten Jahren haben sich groß angelegte Modelle kontinuierlich weiterentwickelt und verfügen nun über leistungsfähigere und effizientere Schlussfolgerungsfähigkeiten. Die Frage, wie die Qualität der Lösung komplexer Probleme verbessert werden kann, ohne die Ausdruckskraft des Modells zu beeinträchtigen, ist zu einem zentralen Forschungsschwerpunkt geworden. Vor diesem Hintergrund etabliert sich eine neue Generation von Modellen, die hochwertige Schlussfolgerungsanalyse mit strukturierter Denkoptimierung verbinden, zunehmend als Hauptforschungsansatz.
März 2026Jackrong hat ein leistungsstarkes Inferenzmodell, Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled, als Open Source veröffentlicht.Aufbauend auf der Qwen3.5-27B-Infrastruktur integriert es fortschrittliche Schlussfolgerungsfähigkeiten, die aus Claude-4.6 und Opus abgeleitet wurden, und verbessert so die Leistung bei der Lösung komplexer Probleme und der Interaktion in mehrstufigen Dialogen erheblich, während gleichzeitig die ursprünglichen starken Sprachverständnis- und Ausdrucksfähigkeiten erhalten bleiben.
Auf der Ebene der KernkompetenzenDieses Modell erzielt eine umfassende Verbesserung der Denkfähigkeit durch die Einführung einer hochwertigen Technologie zur Destillation von Gedankenketten und eignet sich daher besonders für Anwendungsbereiche wie mathematische Ableitungen, logische Analysen, Planung und Entscheidungsfindung sowie die Zerlegung mehrstufiger Aufgaben. Im Vergleich zu herkömmlichen Modellen kann dieses System nicht nur Antworten generieren, sondern Probleme auch strukturiert Schritt für Schritt analysieren und komplexe Aufgaben in klare und ausführbare logische Schritte unterteilen. Dadurch werden die Stabilität des Denkprozesses und die Zuverlässigkeit der Ergebnisse insgesamt verbessert.
Im Hinblick auf das interaktive Erlebnis,Das Modell unterstützt einen tokenbasierten Mechanismus zur Generierung von Streaming-Dialogen, der eine nahezu Echtzeit-Ausgabe Wort für Wort ermöglicht und so ein natürlicheres und flüssigeres Dialogerlebnis gewährleistet. Gleichzeitig bietet das System flexible Steuerungsmöglichkeiten für Parameter wie Temperatur, Top-P und maximale Ausgabelänge. Entwickler können so den Generierungsstil und die Ausgabestrategie an verschiedene Anwendungsszenarien anpassen.
Im Hinblick auf die technische Umsetzung,Dieses Modell erzielt mit 27 Milliarden Parametern ein optimales Verhältnis zwischen Leistung und Effizienz und gewährleistet so sowohl eine hohe Ausgabequalität als auch eine einfache Implementierung. Darüber hinaus unterstützt es benutzerdefinierte Systemaufforderungen, mit denen Benutzer Rollen und Interaktionsstile individuell festlegen und dadurch ein hochgradig personalisiertes Anwendungserlebnis erzielen können. Gleichzeitig verfügt das System über umfassende Funktionen für das Sitzungsmanagement, die automatisch die Kontextkontinuität wahren und das Löschen und Neustarten von Gesprächen unterstützen. Dies verbessert die Stabilität bei längeren Unterhaltungen.
In praktischen AnwendungenDieses Modell bietet leistungsstarke, intelligente Dialogunterstützung in verschiedenen Anwendungsbereichen. Beispielsweise verfügt es über exzellente logische Analysefähigkeiten bei komplexen Denkaufgaben; es kann zur Interpretation von wissenschaftlichen Artikeln und zur Versuchsplanung in der Forschung eingesetzt werden; es unterstützt die Codegenerierung und gibt Debugging-Vorschläge in der Programmierung; und es kann zur Beantwortung tiefgehender Fragen und zur Wissensvermittlung in Bildungsszenarien verwendet werden.
derzeit,Der Tutorial-Bereich auf der HyperAI-Website (hyper.ai) enthält nun die Option „Ein-Klick-Bereitstellung von Qwen 3.5-27B-Claude-4.6-Opus-Reasoning-Distilled“.Erleben Sie unser leistungsstarkes Inferenzmodell!
Online ausführen:
Demolauf
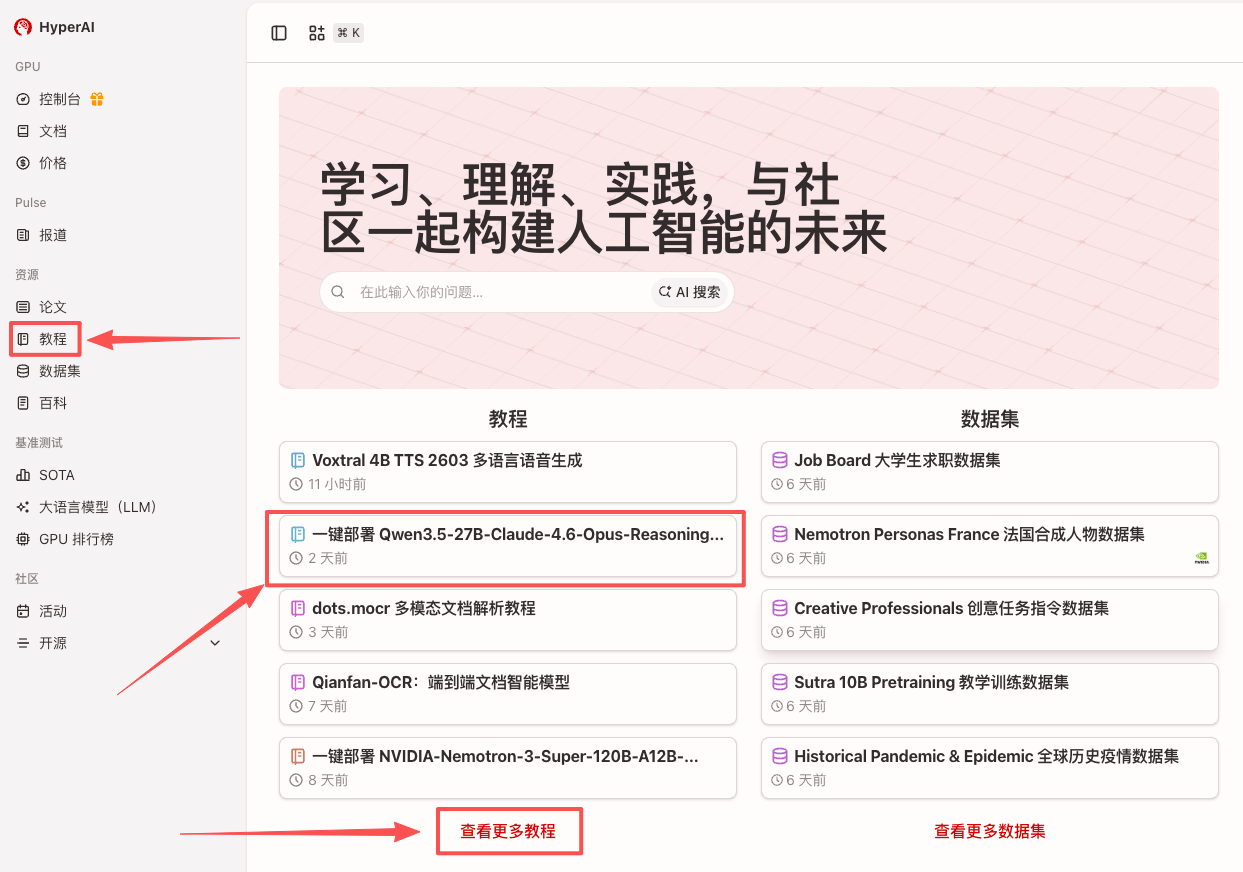
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „Ein-Klick-Bereitstellung von Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled“ aus und klicken Sie auf „Dieses Tutorial online ausführen“.
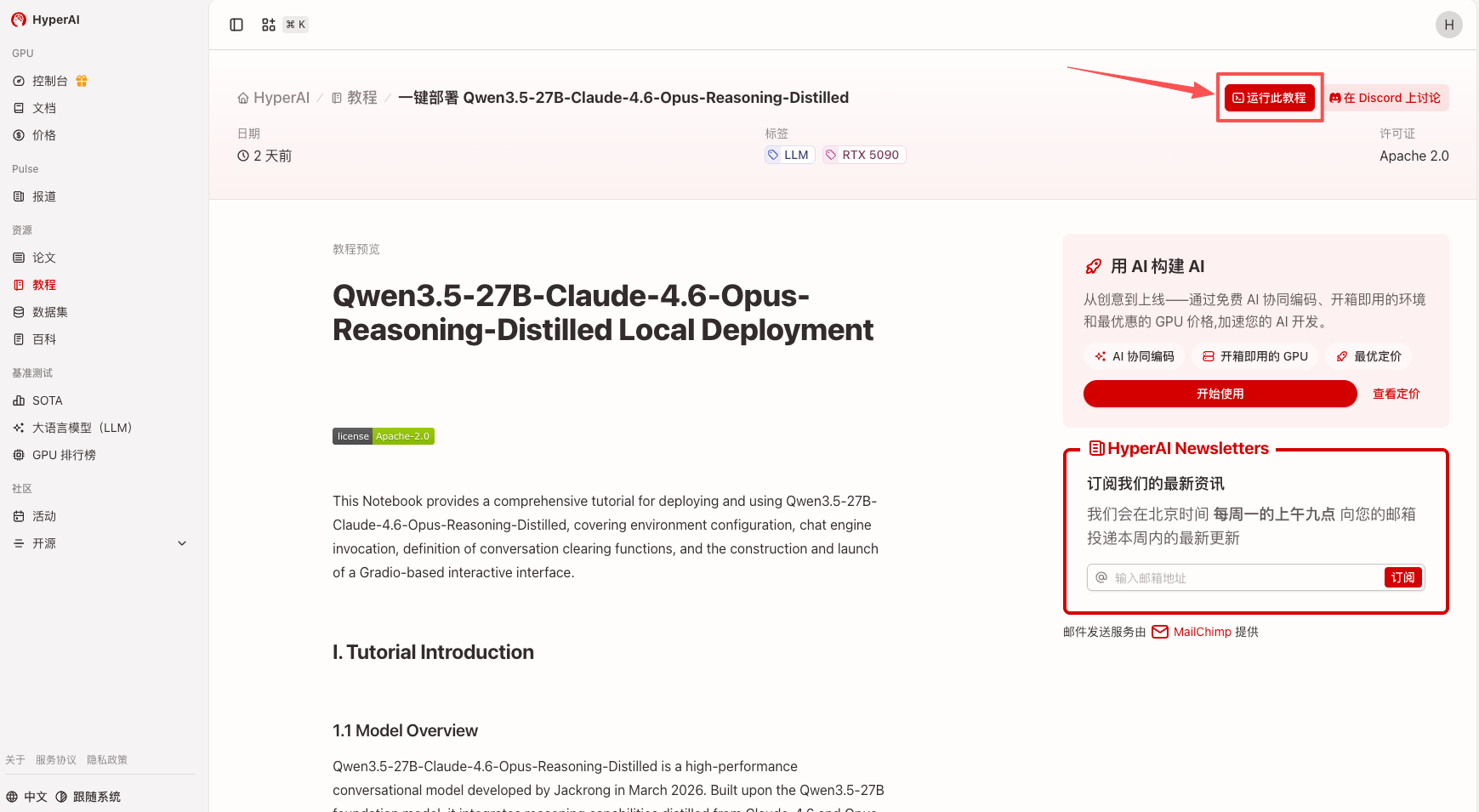
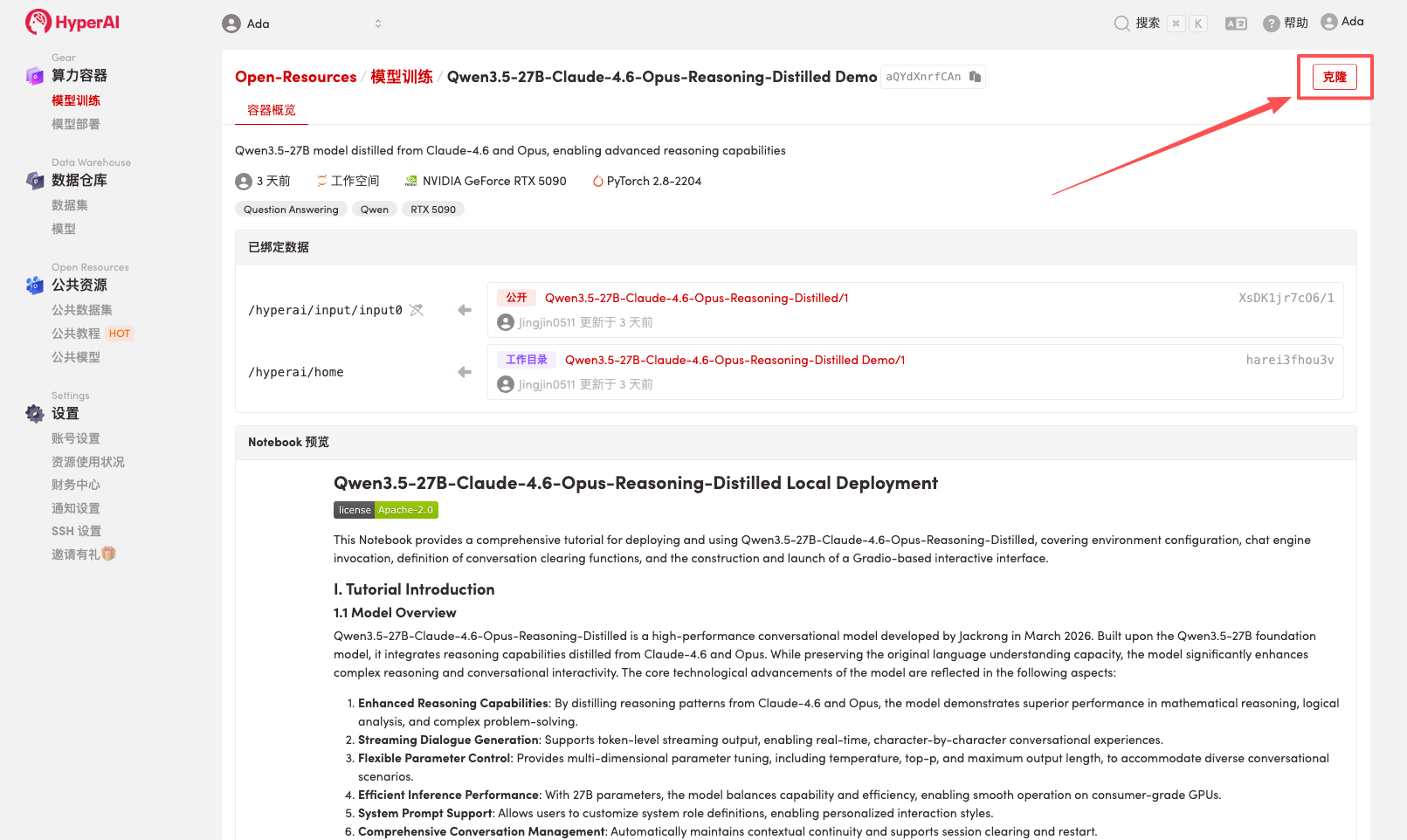
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
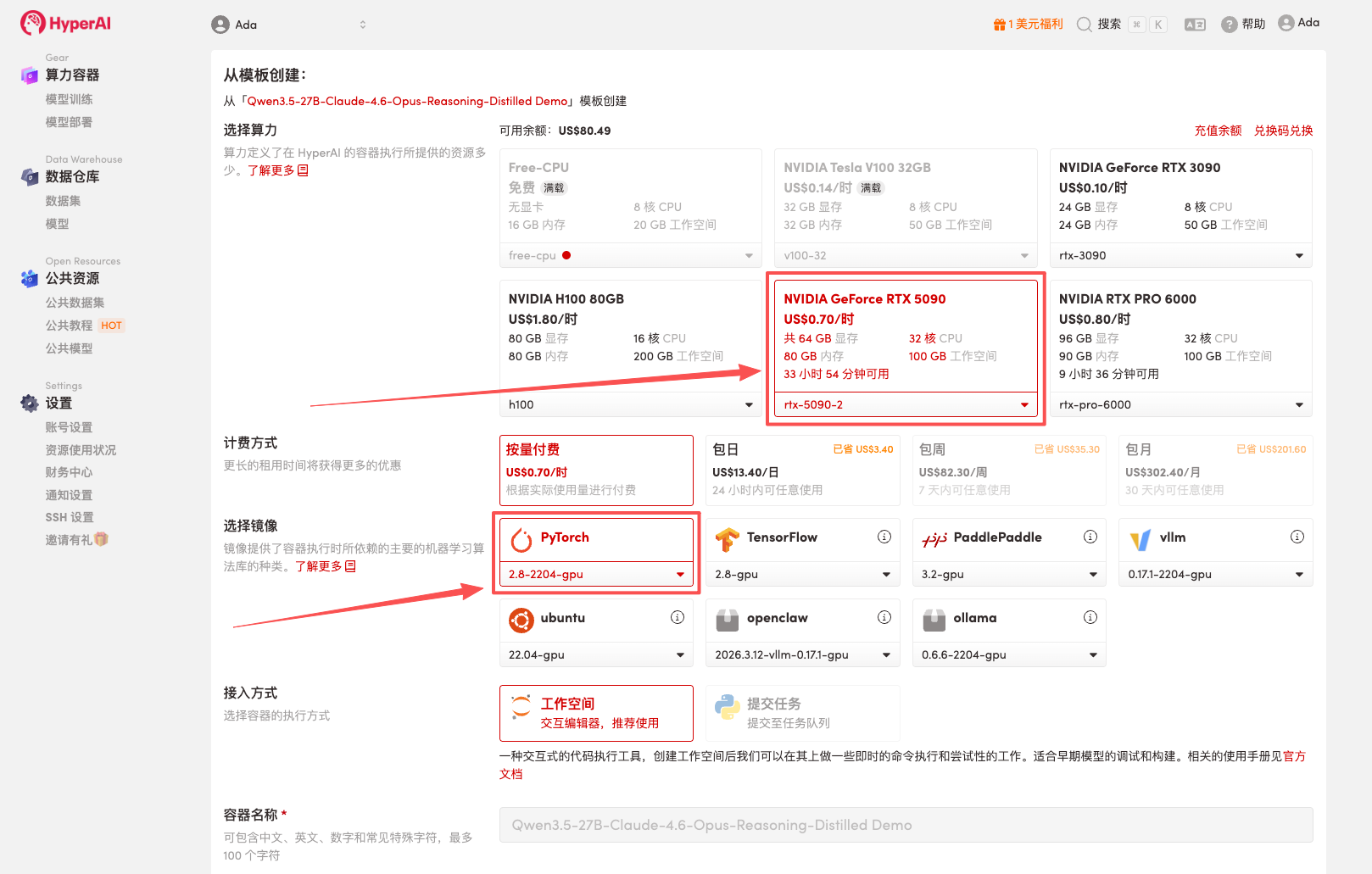
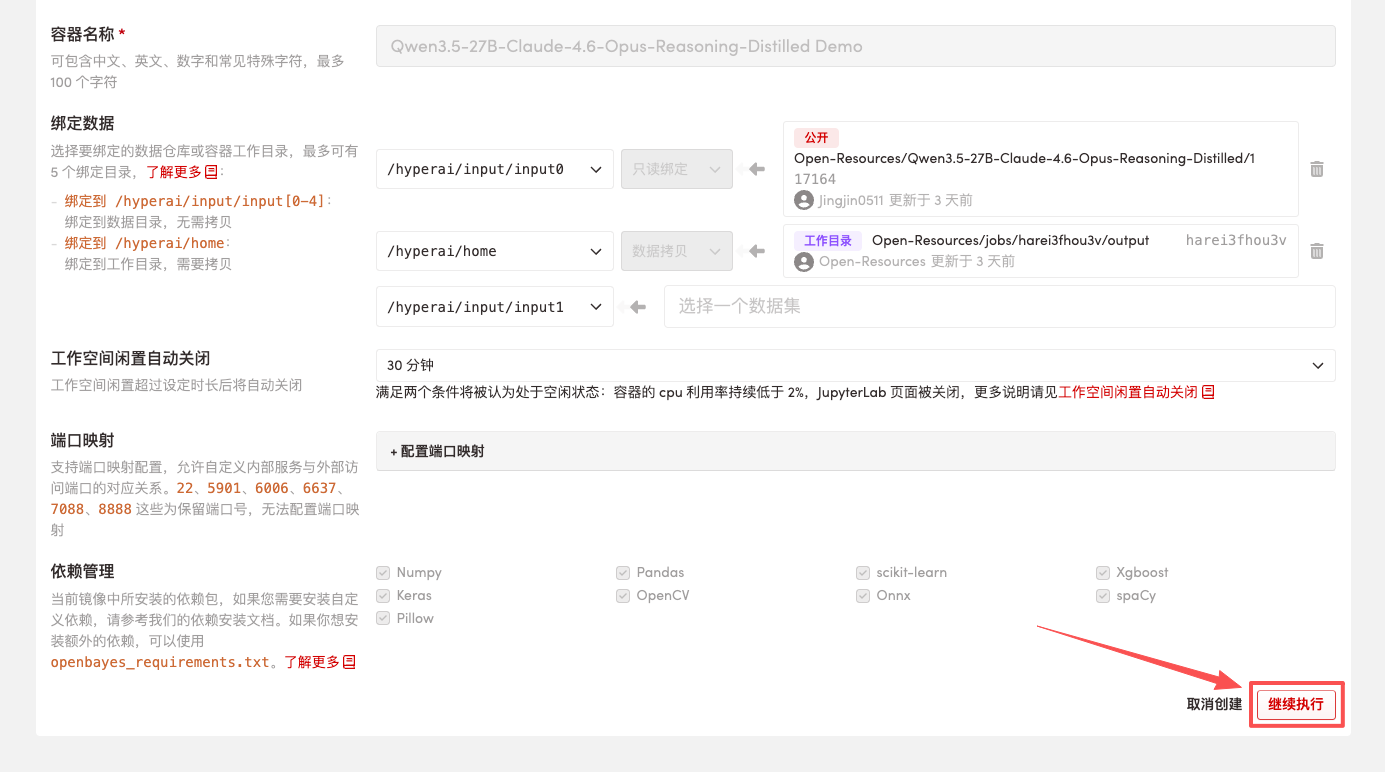
3. Wählen Sie die Images „NVIDIA RTX 5090“ und „PyTorch“ aus und klicken Sie auf „Auftragsausführung fortsetzen“.
HyperAI bietet Neukunden einen Registrierungsbonus: Für nur $1 erhalten Sie 20 Stunden RTX 5090 Rechenleistung (ursprünglich $7), und die Ressourcen sind unbegrenzt gültig.
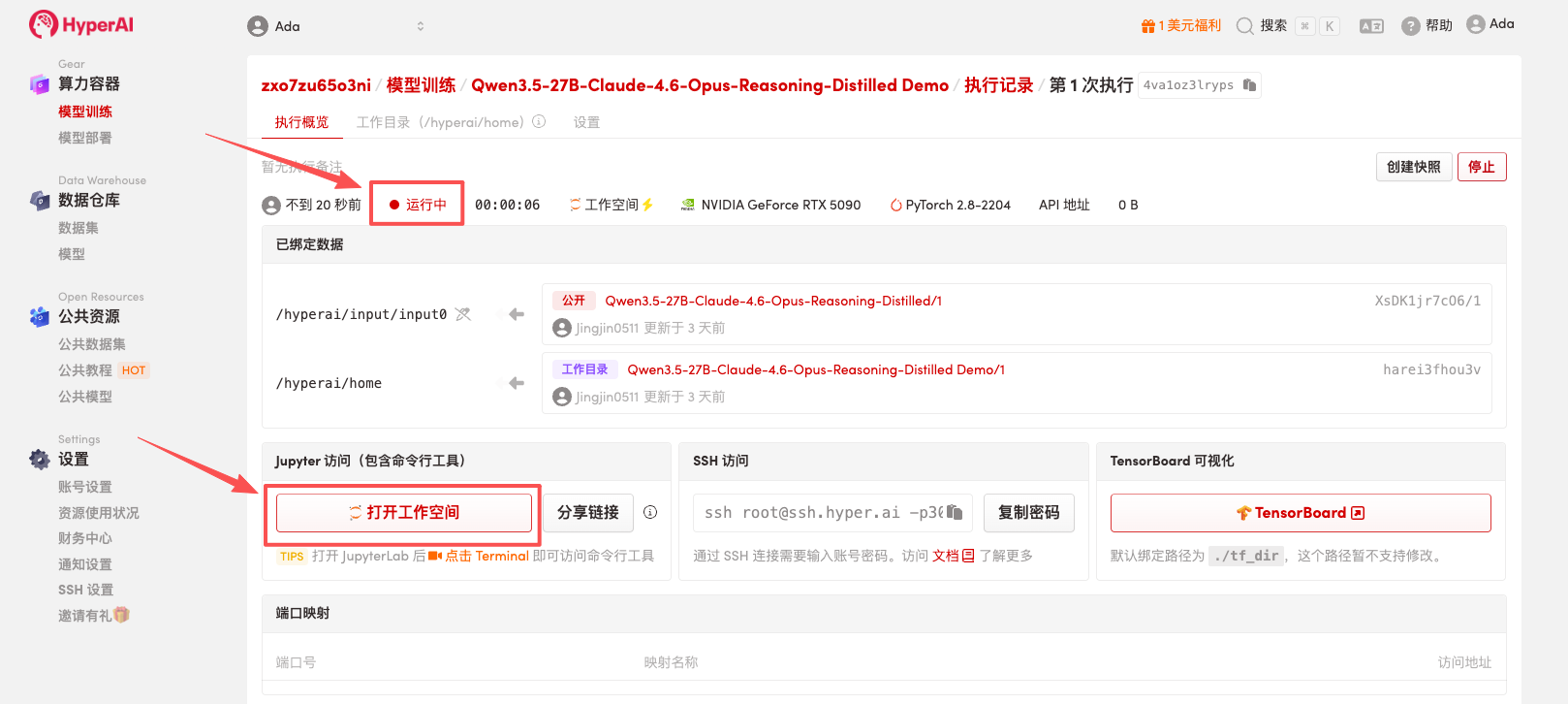
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
Effektanzeige
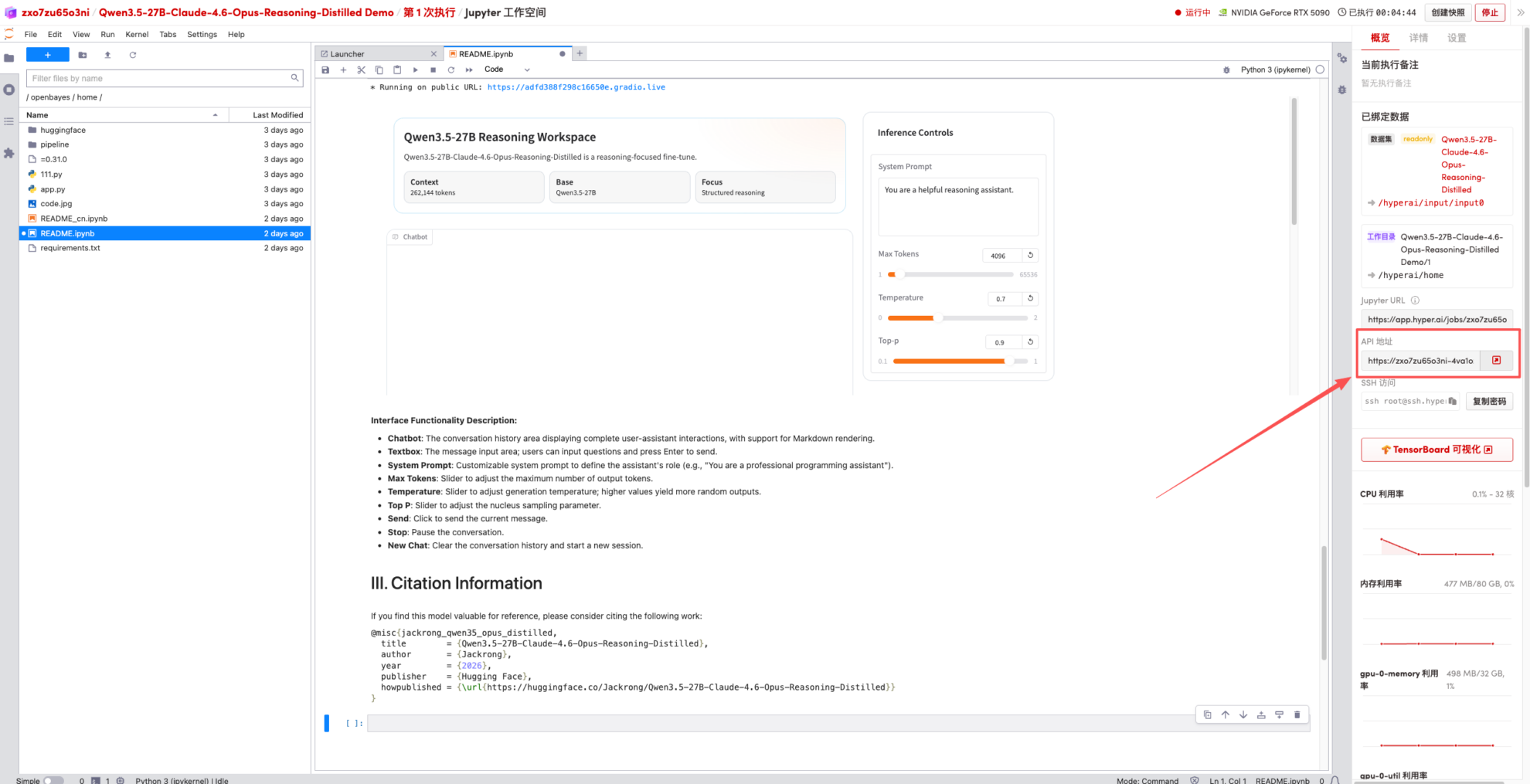
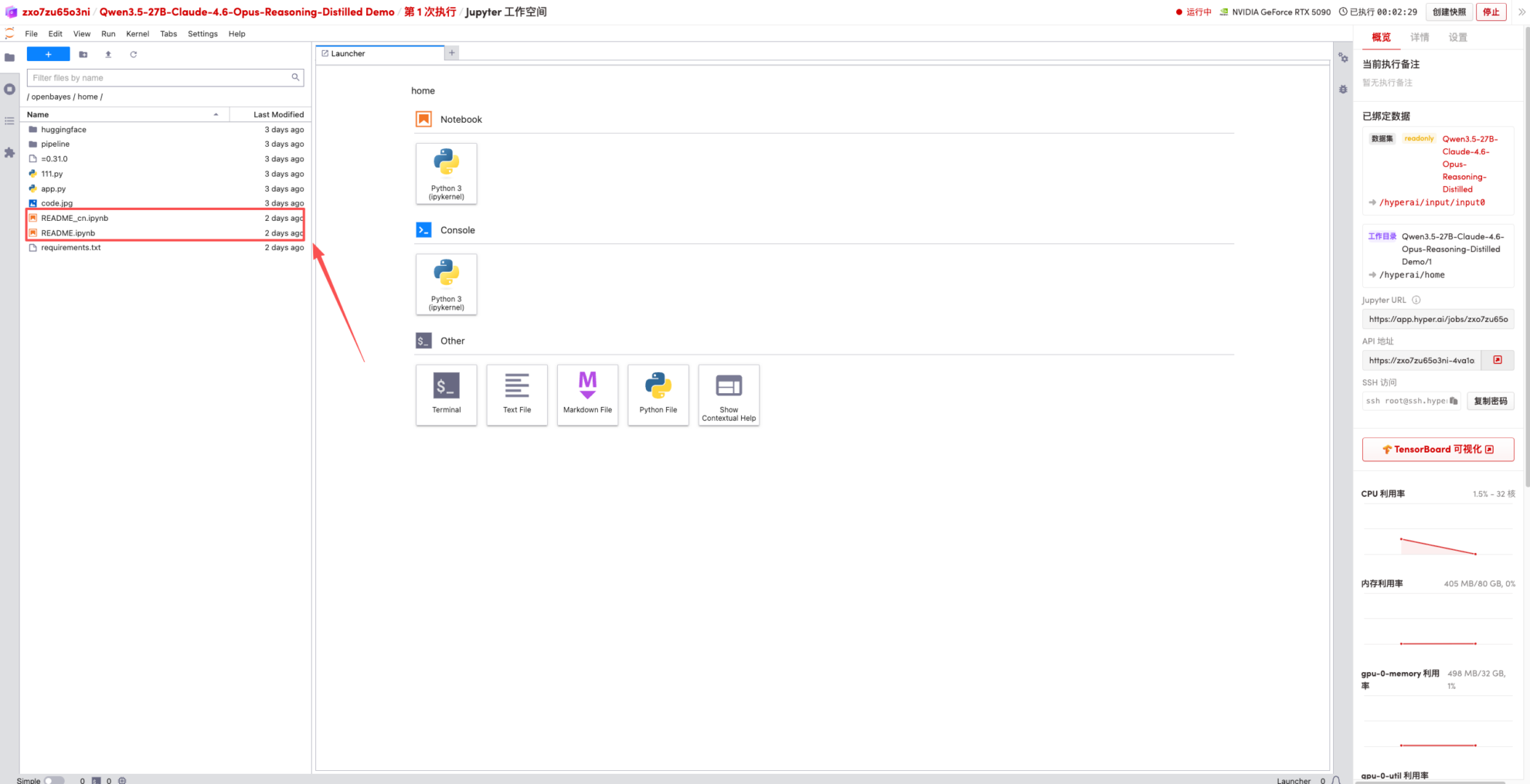
1. Nachdem die Seite weitergeleitet wurde, klicken Sie links auf die README-Seite und anschließend oben auf Ausführen.
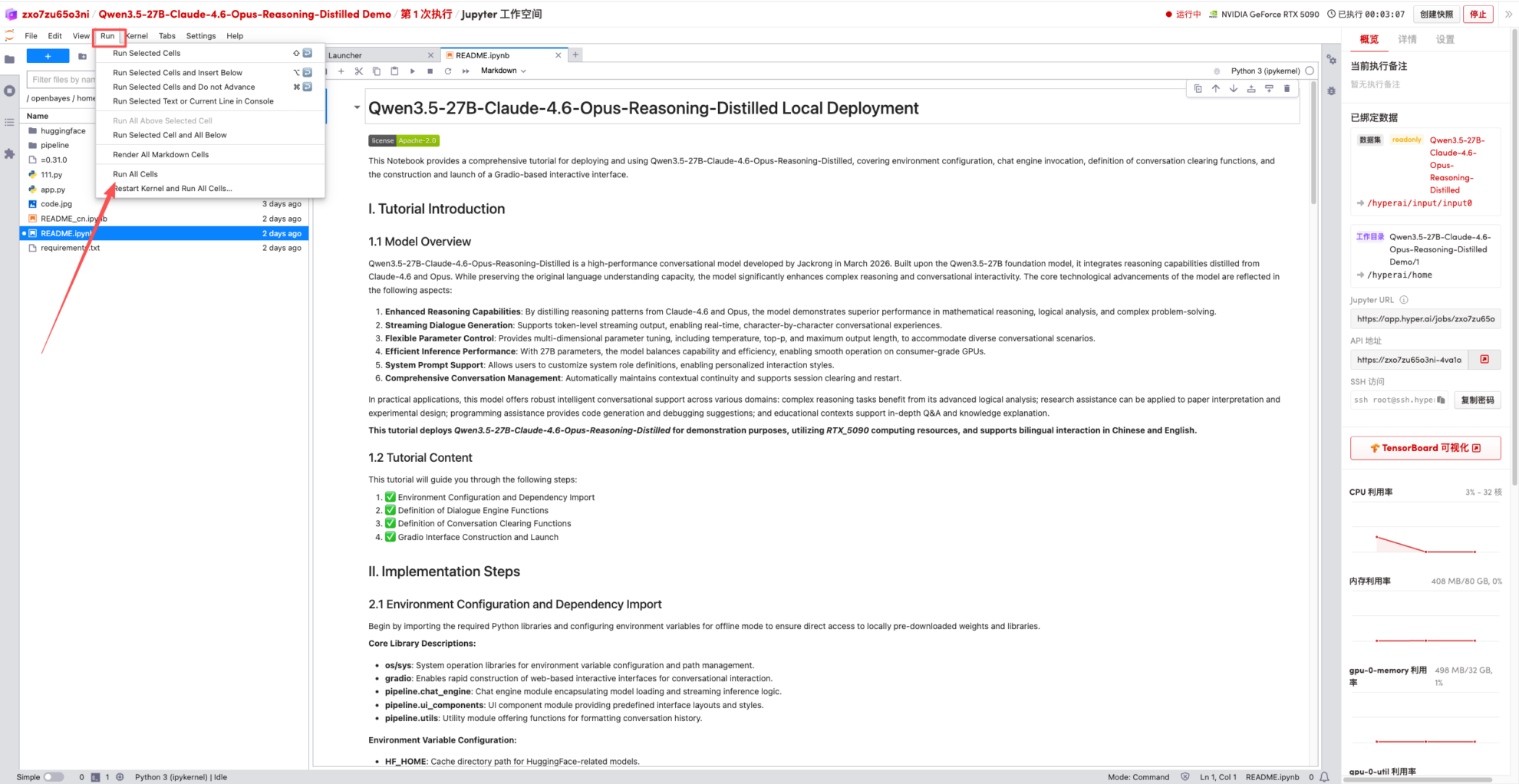
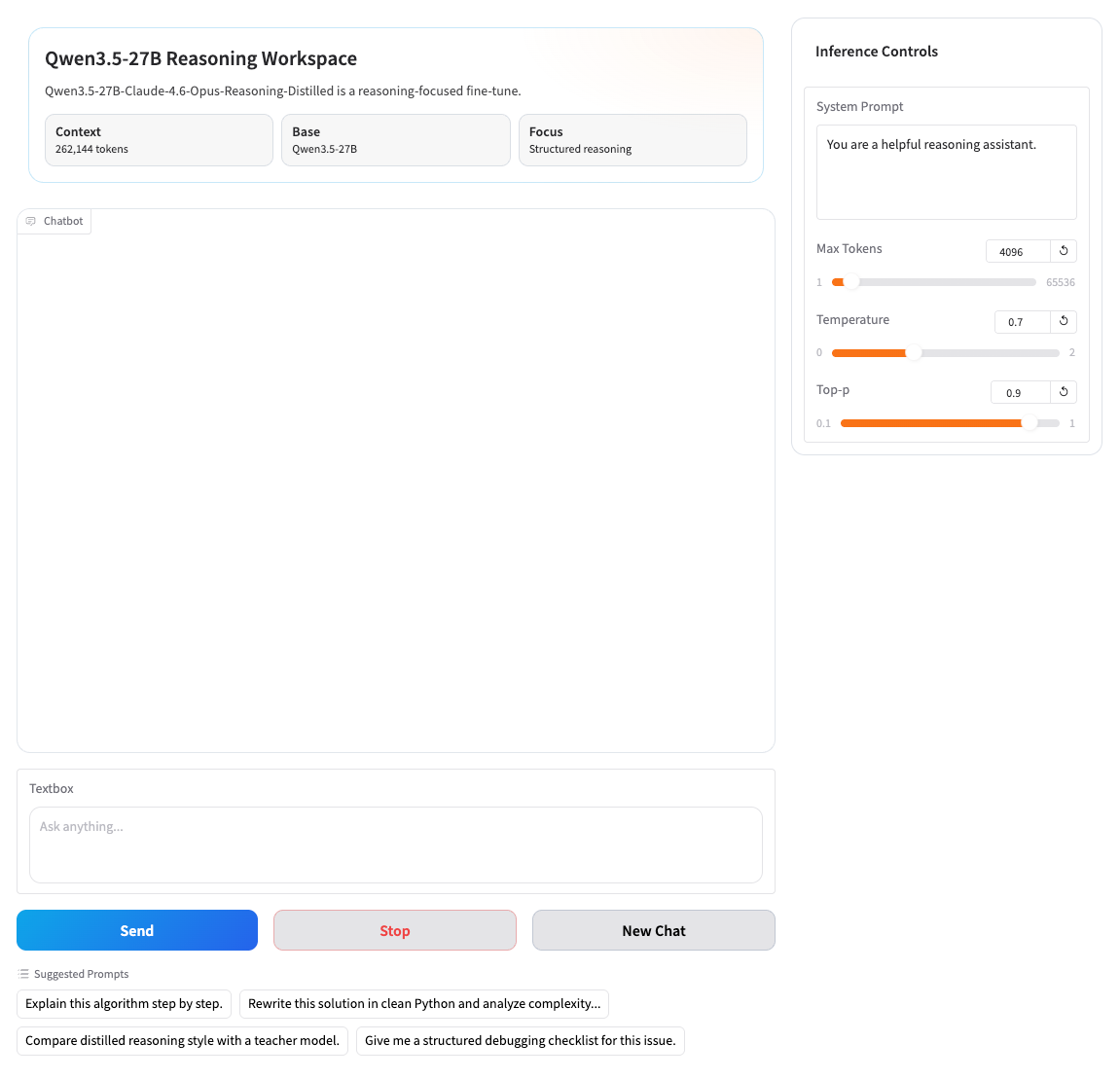
2. Sobald der Vorgang abgeschlossen ist, klicken Sie auf die API-Adresse rechts, um zur Demoseite zu gelangen.