Command Palette
Search for a command to run...
Schnell Und Präzise! Cohere Veröffentlicht Ein Open-Source-Transkriptionsmodell; Präzises Parsen Komplexer Szenarien: Das Visuelle Sprachmodell Chandra-ocr-2 Erzielt Eine Genaue OCR.

Im Zuge der beschleunigten globalen Digitalisierung haben sich Sprachdaten zu einer neuen Quelle geschäftlichen Mehrwerts für Unternehmen entwickelt. Wie sich jedoch die Engpässe bei den Inferenzkosten und der Verarbeitungsgeschwindigkeit überwinden lassen, während gleichzeitig eine hohe Transkriptionsgenauigkeit gewährleistet wird, stellt nach wie vor eine ungelöste Herausforderung dar. Cohere veröffentlichte im März 2026 ein Open-Source-Spracherkennungsmodell, Cohere-transcribe-03-2026.Dieses speziell entwickelte Transkriptionsmodell mit seinen 2 Milliarden Parametern ist ressourcenschonend, hochproduktiv und hochpräzise und setzt damit einen neuen technischen Standard für die „präzise Sprachverarbeitung“ im Zeitalter der großen Modelle.
Das herausragendste Merkmal von Cohere-transcribe ist seine extrem hohe Effizienz und Genauigkeit bei der Inferenz. Das Forschungs- und Entwicklungsteam setzte auf eine asymmetrische Encoder-Decoder-Architektur und konzentrierte über 901 TP3T Rechenleistung auf den Fast-Conformer-Encoder. Dadurch wird der Rechenaufwand für die autoregressive Inferenz durch einen vereinfachten Decoder deutlich reduziert, wodurch die Probleme hoher Implementierungskosten und langsamer Reaktionszeiten herkömmlicher ASR-Modelle gelöst werden.
Im Bereich der Datenverarbeitung stützt es sich auf 500.000 Stunden sorgfältig ausgewählter Sprachtranskriptionspaare.Durch die Kombination proprietärer Bereinigungsprozesse und der Anreicherung synthetischer Daten mittels mehrfacher Fehleranalyse hat das Modell ein außergewöhnliches Hörvermögen entwickelt, das selbst in störungsreichen Umgebungen präzise arbeitet. Es verfügt zudem über einen flexibel anpassbaren Mechanismus zur automatischen Interpunktion, der Satzzeichen hinzufügt oder das Format an die Bedürfnisse des Nutzers anpasst. Dies löst nicht nur das Problem fehlender Interpunktion in vielen Originaldaten, sondern sorgt auch für einen flüssigen und natürlichen Lesefluss des generierten Textes und vereint somit Geschwindigkeit und Genauigkeit.
Auf der HyperAI-Website wird jetzt das „Cohere Transcribe Open Source Lightweight Speech Model“ vorgestellt – probieren Sie es doch einmal aus!
Online-Nutzung:https://go.hyper.ai/DonpU
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 6. bis 12. April:
* Hochwertige öffentliche Datensätze: 4
* Eine Auswahl hochwertiger Tutorials: 9
* Analyse von Community-Artikeln: 2 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefristen im April: 3
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. ToolACE-Datensatz für komplexe Werkzeuglerndialoge
ToolACE ist ein Datensatz für automatisierte Agentenpipelines zum Erlernen von Werkzeugen. Er wurde 2024 von der Shanghai Jiao Tong University in Zusammenarbeit mit der University of Science and Technology of China, dem Huawei Noah's Ark Lab und weiteren Institutionen veröffentlicht. Ziel dieses Datensatzes ist die Generierung präziser, komplexer und vielfältiger Daten für das Werkzeuglernen, insbesondere zur Bewältigung praktischer Herausforderungen wie unzureichender Datenqualität und begrenzter Szenariovielfalt.
Direkte Verwendung:https://go.hyper.ai/RDx6d
2. CHOCLO Lateinamerikanischer Kultur-Benchmark-Datensatz
Der CHOCLO-Datensatz ist ein Benchmark-Datensatz zur Bewertung der Leistungsfähigkeit von Sprachmodellen bei Aufgaben, die lateinamerikanisches Kulturwissen beinhalten. Er zielt darauf ab, die Genauigkeit von Sprachmodellen bei der Repräsentation lateinamerikanischer Kultur zu beurteilen, mit besonderem Fokus auf reale Probleme beim Modelltraining und der Modellausgabe, wie z. B. Unterrepräsentation, Auslassungen und Verzerrungen im Zusammenhang mit der Kultur der Region.
Direkte Verwendung:https://go.hyper.ai/dnYtT
3. DRACO Cross-Disciplinary In-Depth Research Benchmark Dataset
DRACO (Cross-Domain Deep Research Accuracy, Completeness, and Objectivity Benchmark Dataset) ist ein vom Perplexity-Team veröffentlichter Datensatz zur Bewertung komplexer Forschungsaufgaben. Er umfasst 100 solcher Aufgaben aus 40 Ländern und Regionen auf fünf Kontinenten. Die Aufgaben decken zehn wichtige Anwendungsbereiche ab, darunter Finanzen, Produktvergleich, Wissenschaft und Technologie. Jede Aufgabe stellt ein mehrstufiges Informationsabfrage- und Analyseproblem mit mehreren Datenquellen dar und beinhaltet von 26 Fachexperten entwickelte und validierte Bewertungskriterien.
Direkte Verwendung:https://go.hyper.ai/SdAUn
4. COCO-2017-Vietnamesischer Datensatz zur Bilderkennung
COCO-2017-Vietnamese ist ein vietnamesischer Lokalisierungsdatensatz, der auf dem Microsoft Common Objects in Context (COCO) 2017-Datensatz basiert und von der AI Enthusiast Community sorgfältig gepflegt und veröffentlicht wird. Dieser Datensatz bietet hochwertige vietnamesische Übersetzungen englischer Bildunterschriften und stellt somit einen umfassenden zweisprachigen Benchmark-Datensatz dar, der sich für Aufgaben wie Bildbeschreibung und multimodales Lernen eignet.
Direkte Verwendung:https://go.hyper.ai/KSv2V
Ausgewählte öffentliche Tutorials
1. Cohere Transcribe: Ein quelloffenes, ressourcenschonendes Sprachmodell
Cohere Transcribe ist ein ressourcenschonendes Sprachmodell, das von Cohere im März 2026 als Open Source veröffentlicht wurde. Es verfügt über zwei Milliarden Parameter und wurde speziell für Edge-Geräte entwickelt, um die durch die Größe bisheriger Sprachmodelle verursachten Latenzprobleme zu beheben. Cohere Transcribe wurde mit 14 Sprachen trainiert, darunter Chinesisch, Japanisch, Französisch und Hebräisch.
Online ausführen:https://go.hyper.ai/DonpU
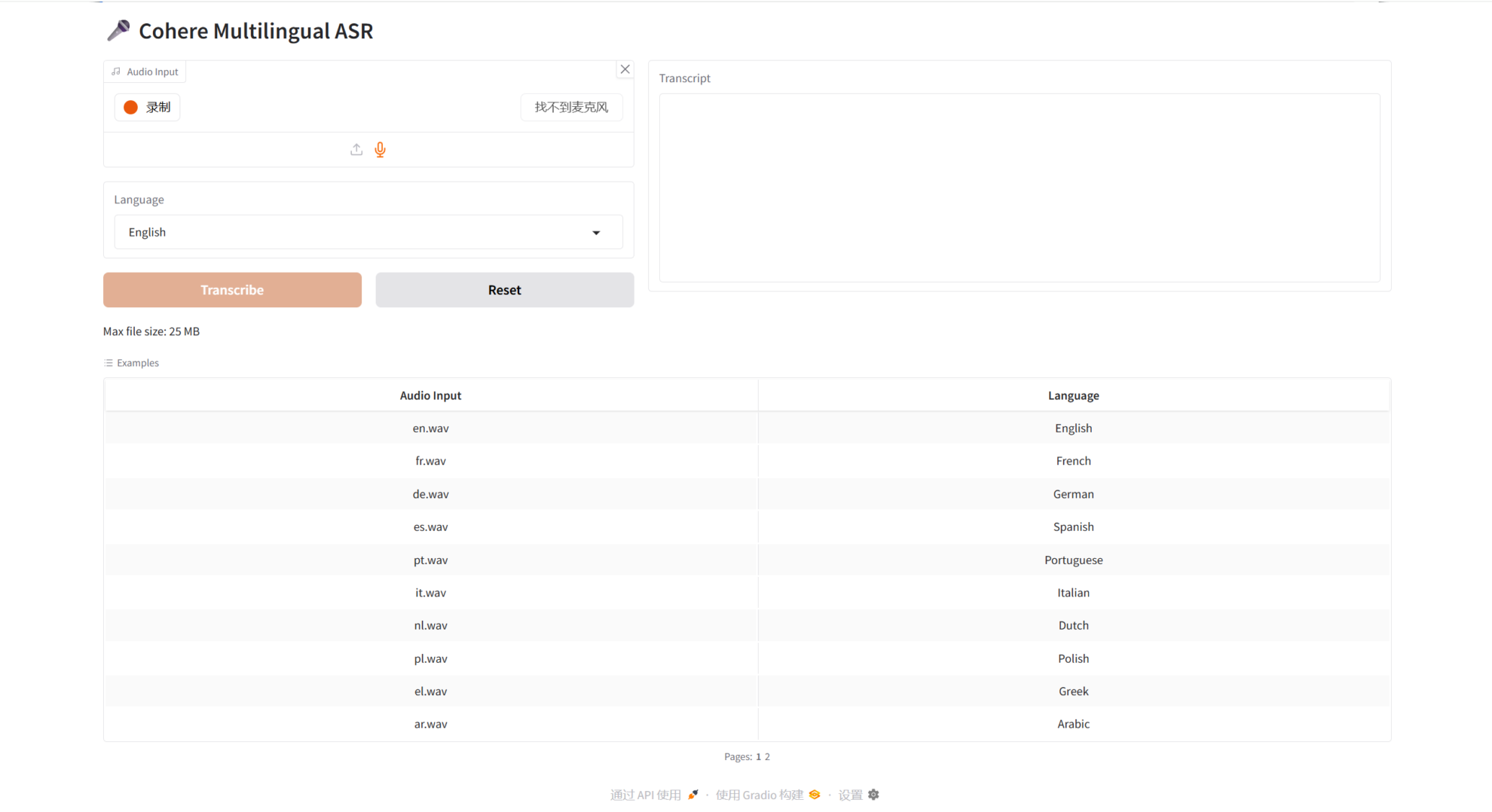
2. LTX-2.3-Turbo-Videogenerator
LTX-2.3-turbo ist ein Open-Source-Videogenerierungsmodell, das von Lightricks im März 2026 veröffentlicht wurde und die Grenzen der Open-Source-Videogenerierungsmöglichkeiten erweitern soll. Dieses Modell nutzt eine fortschrittliche Diffusionstransformator-Architektur und kombiniert diese mit multimodalen Analysefunktionen, um qualitativ hochwertige Videoinhalte in verschiedenen Auflösungen zu generieren.
Online ausführen:https://go.hyper.ai/tkiw4
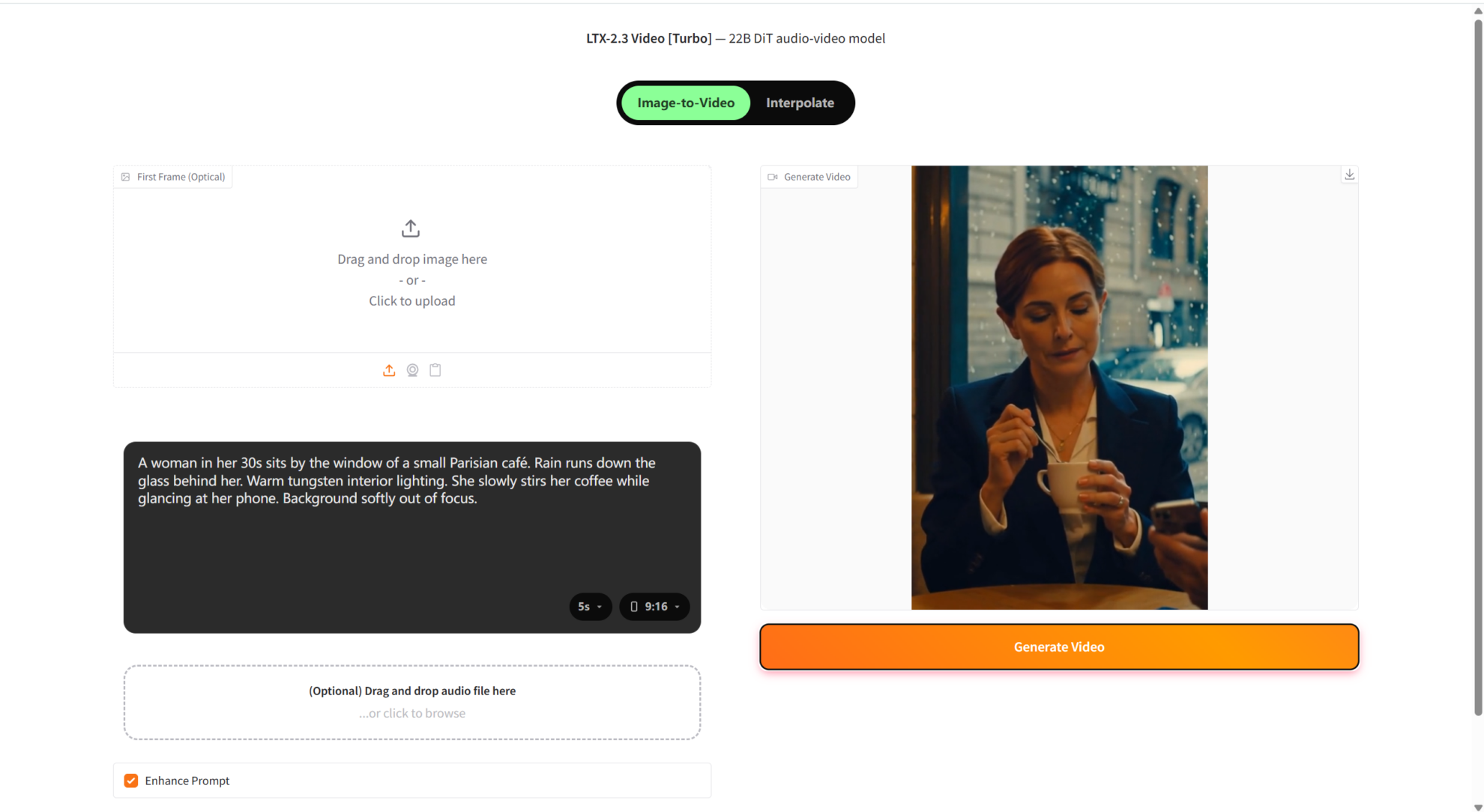
3. Bereitstellung von Gemma-4-31B-it mit einem Klick
Gemma 4 31B IT, veröffentlicht von Google DeepMind am 2. April 2026, ist ein 3,1 Milliarden Bit umfassendes, instruktionsintensives Modell der Gemma-4-Serie. Es unterstützt Text- und Bildeingabe sowie Textausgabe, bietet ein Kontextfenster von bis zu 256.000 Wörtern und unterstützt nativ Inferenz, Funktionsaufrufe und Systemhinweise. Dadurch eignet es sich ideal für hochwertige Fragebeantwortung, Unterstützung bei der Programmierung und Agentendienste. Es unterstützt über 140 Programmiersprachen und ist primär für Inferenz, Programmierung, Agenten-Workflows und multimodale Verständnisaufgaben konzipiert.
Online ausführen:https://go.hyper.ai/RLgK9
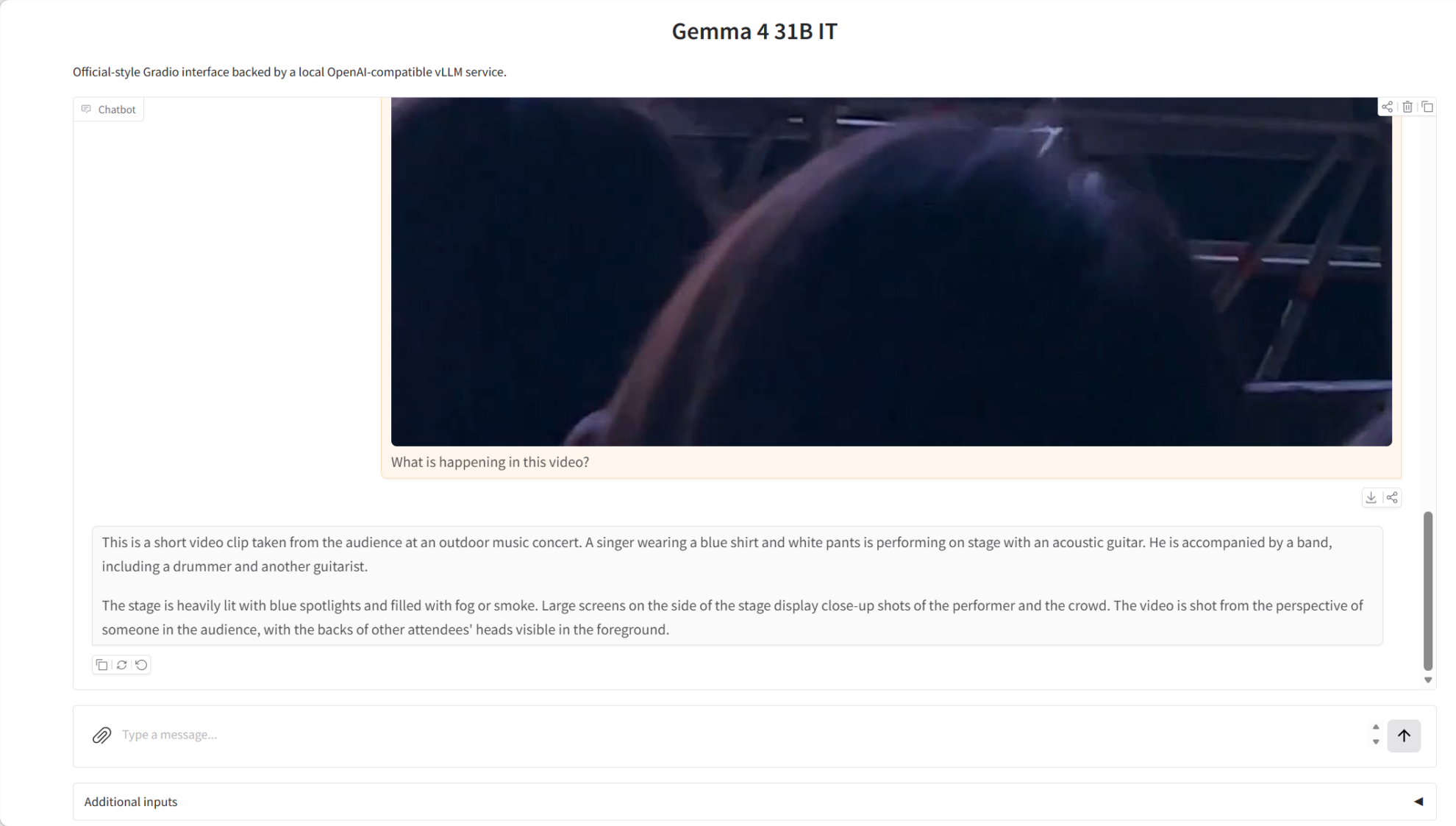
4. Bereitstellung von gemma-4-26B-A4B-it mit einem Klick
Gemma 4 26B A4B IT wurde am 2. April 2026 von Google DeepMind veröffentlicht. Es unterstützt Text- und Bildeingabe sowie Textausgabe mit einem Kontextfenster von bis zu 256.000 Wörtern. Dank nativer Unterstützung für Inferenz, Funktionsaufrufe und Systemhinweise eignet es sich ideal für hochwertige Fragebeantwortung, Unterstützung bei der Programmierung und Agentendienste. Es unterstützt über 140 Sprachen und ist primär für Inferenz, Programmierung, Agenten-Workflows und multimodale Verarbeitungsaufgaben konzipiert.
Online ausführen:https://go.hyper.ai/blUyh
5. OmniCoder-9B: Für Agentencodierungsaufgaben
OmniCoder-9B wurde im September 2025 von Teslatate veröffentlicht. Es handelt sich um ein 9B-Parameter-Codierungsproxy-Modell, das auf einer hybriden Qwen3.5-9B-Architektur basiert und als Open-Source-Codierungsassistent auf einer einzelnen GPU eingesetzt werden kann. OmniCoder-9B ist speziell für reale Softwareentwicklungs-Workflows optimiert und konzentriert sich auf kohärente, mehrstufige Inferenz, Terminaloperationen, Werkzeugnutzung und Codemodifikationsprozesse. Es eignet sich besonders für Codierungsaufgaben, die Verständnis, Modifikation und Verifizierung erfordern, anstatt für Aufgaben, die nur ein einmaliges Ergebnis liefern.
Online ausführen:https://go.hyper.ai/LfNz9
6. Fish Audio S2-Pro Natürliche Sprachsteuerung Sprachemotionen
Im März 2026 veröffentlichte Fish Audio FishAudio-S2-Pro, ein durchgängiges Dual-Autoregressives (Dual-AR) Text-to-Speech-Modell (TTS) mit 5 Milliarden Parametern (4 Milliarden langsame und 400 Millionen schnelle Autoregressive). Es ist optimal für Anwendungsfälle wie mehrsprachige Sprachsynthese, personalisiertes Sprachklonen und die Generierung emotionaler Sprache ausgelegt und wurde speziell für Sprachsyntheseaufgaben mit hoher Natürlichkeit und guter Kontrollierbarkeit entwickelt.
Online ausführen:https://go.hyper.ai/QEAJZ
7. Chandra-ocr-2 wandelt mathematische Inhalte, Tabellenkalkulationsinhalte und handschriftliche Inhalte präzise in strukturierte Inhalte um.
Chandra-ocr-2 ist ein optisches Zeichenerkennungssystem der nächsten Generation, das vom Datalab-Team im März 2026 vorgestellt wurde und sich auf Texterkennung und strukturierte Ausgabe in komplexen Szenarien konzentriert. Dieses Modell wurde mithilfe fortschrittlicher visueller Sprachvortrainingstechnologie feinabgestimmt und kann so hochgeladene Bildinhalte intelligent erkennen und formatierte Textergebnisse liefern.
Online ausführen:https://go.hyper.ai/3KobP
8. Crow-9B-HERETIC-4.6: Ein lokal aufgerufenes Dialogmodell
Crow-9B-HERETIC-4.6 wurde 2025 von Crownelius veröffentlicht. Das auf der Qwen-3.5-Architektur basierende Modell verfügt über neun Parameter und wird als Distilled LLM bereitgestellt. Es ist optimiert für Aufgaben wie qualitativ hochwertige allgemeine Dialoge, logisches Denken, das Schreiben längerer Texte, Unterstützung bei der Programmierung und mehrstufige Interaktionen. Als lokales großes Sprachmodell, das Direktheit, Vollständigkeit und strukturierte Ausdrucksweise in den Antworten betont, eignet sich Crow-9B-HERETIC-4.6 als allgemeiner intelligenter Assistent, Lernhilfe und Modell zur Textgenerierung.
Online ausführen:https://go.hyper.ai/DrpSp

9. Granite 4.0 1B Speech: Offline-Spracherkennung und Übersetzungsbereitstellung
IBM Granite veröffentlichte im März 2026 Granite 4.0 1B Speech. Es handelt sich um ein kompaktes Sprachmodell mit rund einer Milliarde Parametern, das für die mehrsprachige automatische Spracherkennung und bidirektionale Sprachübersetzung entwickelt wurde und zahlreiche Sprachen unterstützt, darunter Englisch, Französisch, Deutsch, Spanisch, Portugiesisch und Japanisch. Dieses Modell ist besonders für den Einsatz auf ressourcenbeschränkten Geräten geeignet und ideal für Offline-Service-Workflows, die auf lokalen gewichteten Verzeichnissen und standardisierten Serviceschnittstellen basieren.
Online ausführen:https://go.hyper.ai/kzFhl
Interpretation von Gemeinschaftsartikeln
1. Die Cornell University hat EMSeek entwickelt, eine Multiagenten-Plattform, die Elektronenmikroskopbilder in nur 2-5 Minuten in materialwissenschaftliche Erkenntnisse umwandeln kann.
Ein Forschungsteam der Cornell University hat EMSeek entwickelt, eine modulare Multiagenten-Plattform mit Quellverfolgungsfunktionen. Evaluierungsergebnisse an 20 Materialsystemen und fünf Aufgabenkategorien zeigen, dass EMSeek bei Segmentierungsaufgaben etwa doppelt so schnell und präzise wie Segment Anything ist. Darüber hinaus erreicht oder übertrifft EMSeek mit einer Kalibrierung anhand von nur etwa 2%-Datenpunkten die Leistung leistungsstarker Einzelexpertenmodelle bei drei Benchmarks zur Vorhersage von Materialeigenschaften. Eine vollständige Abfrage dauert nur 2 bis 5 Minuten pro Bild und ist damit etwa 50-mal schneller als ein Expertenworkflow.
Den vollständigen Bericht ansehen:https://go.hyper.ai/1OlNI
2. Um eine 1,4- bis 3,7-fache Beschleunigung der Inferenz zu erreichen, schlägt das MIT DRiffusion vor, um den Engpass der Abtastlatenz von Diffusionsmodellen zu überwinden.
Forscher am MIT haben das DRiffusion-Diffusionsmodell entwickelt, das die Vorteile systembiologischer und mathematischer Methoden vereint und so eine deutliche Beschleunigung ohne Qualitätseinbußen bei der Datengenerierung ermöglicht. Dies bietet eine neuartige Lösung für das Gleichgewicht zwischen hoher Wiedergabetreue und effizienter Abtastung in Diffusionsmodellen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/lbzzK
Beliebte Enzyklopädieartikel
1. Fähigkeiten
2. Unterpassen
3. Glitch-Token (ein Begriff zur Beschreibung eines mit einem Glitch zusammenhängenden Begriffs)
4. Wahrheitsgehalt
5. Reziproke Rangfusion
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








