Command Palette
Search for a command to run...
Tutorial-Zusammenfassung | Open-Source-Kleinmodelle Erreichen Eine Mit GPT-5 Vergleichbare Gesamtintelligenz; One-Stop-Evaluation Beliebter Modelle Wie Qwen 3.5/Gemma 4.

Am 14. April veröffentlichte die unabhängige Testorganisation Artificial Analysis einen Vergleichsbericht über Open-Source-Modelle mit weniger als 32 Bytes, der Folgendes zeigt: ...Die beiden kleinen Modelle Qwen3.5 27B und Gemma 4 31B haben hinsichtlich ihrer Gesamtintelligenz zu den entsprechenden GPT-5-Modellen aufgeschlossen.Unter ihnen erzielte Qwen3.5 27B (Inferenzversion) 42 Punkte auf dem Intelligenzindex, was mit GPT-5 (mittel) vergleichbar ist; Gemma 4 31B (Inferenzversion) erzielte 39 Punkte, was GPT-5 (niedrig) entspricht.
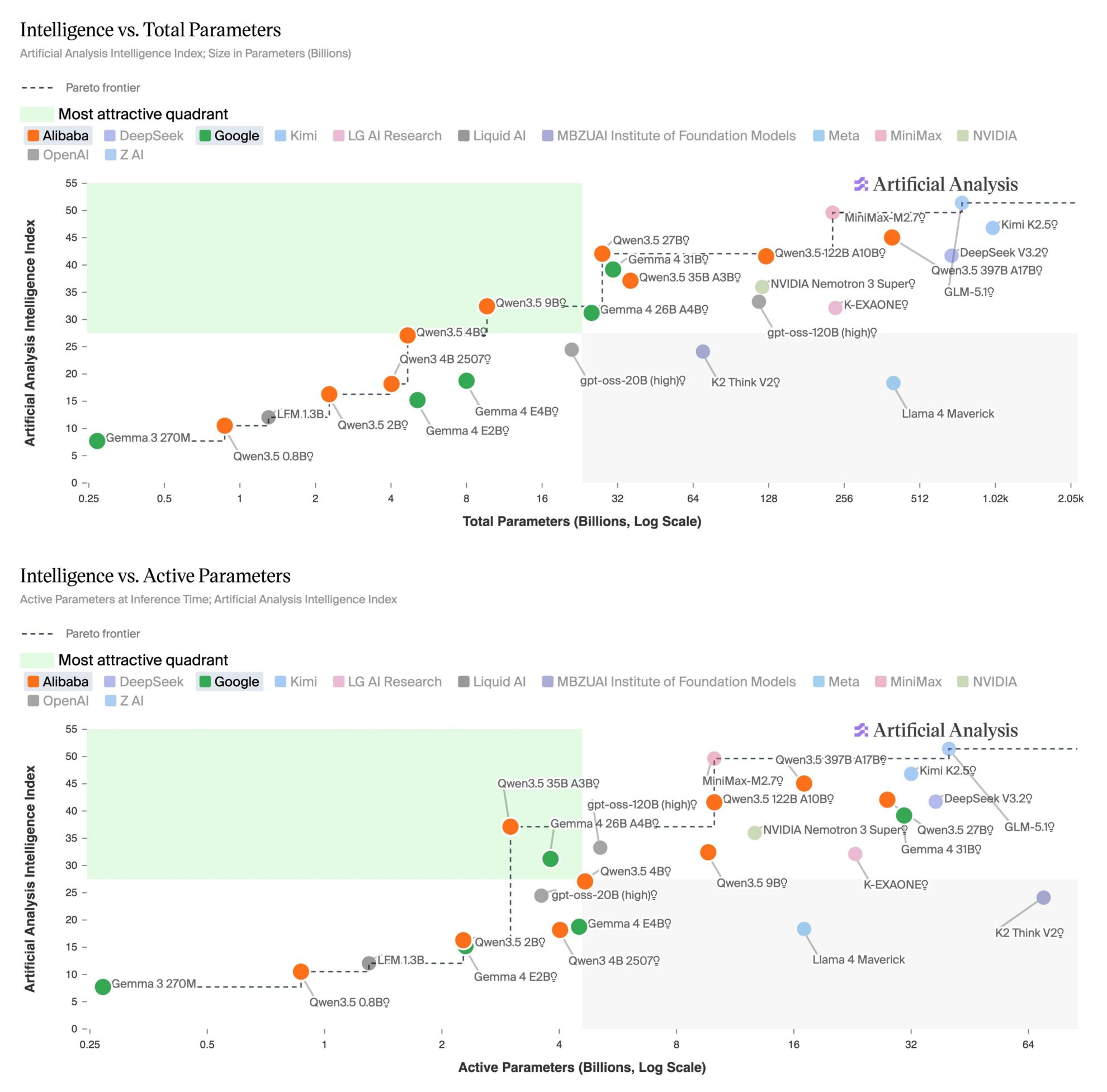
Der Bericht zeigt, dass diese Generation von 32B-Modellen deutliche Verbesserungen in Schlussfolgerungsfähigkeit und Agentenleistung aufweist. Qwen3.5 27B erreichte im Agentic Index 55 Punkte und übertraf damit GPT-5 (mittel) mit 46 Punkten. Gemma 4 31B schnitt bei komplexen Aufgaben wie TerminalBench Hard und HLE ebenfalls besser ab als GPT-5 (niedrig). Darüber hinaus unterstützen beide Modelle nativ multimodale Eingaben und gehören bei Aufgaben zum visuellen Verständnis wie MMMU-Pro zu den besten Open-Source-Modellen ihrer Klasse.
Das kleinere Modell hinkt jedoch hinsichtlich Wissensgenauigkeit und Illusionskontrolle weiterhin deutlich hinterher. Die beiden Modelle erreichen im AA-Omniscience-Index Werte von -42 bzw. -45, während die GPT-5-verwandte Version einen Wert von -10 erzielt. Dies verdeutlicht den anhaltenden Einfluss der Parametergröße auf die Wissensspeicherung.
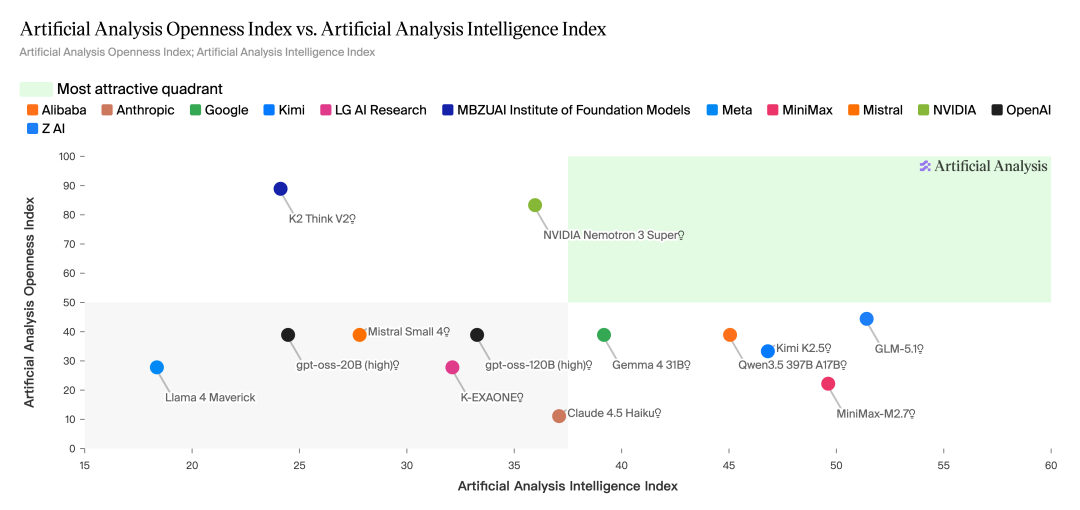
Auf der Ebene der praktischen Anwendung wurde die Anwendbarkeit dieser Modelle deutlich verbessert. Beide oben genannten Modelle laufen auf einer einzelnen NVIDIA H100 und können durch Quantisierung lokal auf persönlichen Geräten eingesetzt werden, was den Einstieg erleichtert. Gleichzeitig holt die Open-Source-Community für Gewichtungsalgorithmen rasant auf, und große Modelle wie GLM-5.1 verringern den Abstand auf unter zehn Prozent.
Die ganze Zeit,Um Entwicklern einen schnellen Einstieg zu ermöglichen und die neuesten Open-Source-Modelle zu validieren, aktualisiert HyperAI kontinuierlich die Online-Bereitstellungs-Notebooks für gängige Modelle im Abschnitt „Tutorials“ seiner offiziellen Website.Dieser Artikel fasst die im Bericht zur künstlichen Analyse erwähnten hochwertigen Open-Source-Modelle und ihre Anleitungen zur einfachen Bereitstellung zusammen. Erleben Sie selbst die hohe Leistungsfähigkeit, die der von proprietären Modellen sehr nahe kommt!
Weitere Online-Tutorials:
Besuchen Sie unsere offizielle Website für weitere Informationen:
NVIDIA-Nemotron-3-Super-120B
Der NVIDIA Nemotron 3 Super NVFP4 wurde von der NVIDIA Corporation im März 2026 veröffentlicht. Dieses Modell ist ein großes Sprachmodell mit insgesamt 120 Parametern und 12 Aktivierungsparametern, das eine LatentMoE-Hybridarchitektur verwendet und Kontexte mit bis zu 1 Million Token unterstützt.
Dieses Modell ist für Szenarien mit kontextbezogenem Schlussfolgern, Agenten-Workflows, Tool-Aufrufen, RAGs und hochperformanter Fragebeantwortung konzipiert. Hinsichtlich der Interaktion unterstützt das Modell sowohl das Aktivieren als auch das Deaktivieren eines Schlussfolgermodus und kann mithilfe standardisierter Chat-Vorlagenparameter zwischen normaler Fragebeantwortung und einem durch Schlussfolgern erweiterten Modus umschalten.
Online ausführen:

Qwen3.5-27B-Claude-4.6-Opus–Destilliertes Denken
Im März 2026 veröffentlichte Jackrong als Open Source ein leistungsstarkes Reasoning-Modell namens Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled. Es basiert auf der Architektur von Qwen3.5-27B und integriert fortschrittliche Reasoning-Funktionen, die aus Claude-4.6 und Opus extrahiert wurden. Neben den bewährten Fähigkeiten zum Sprachverständnis und zur Sprachexpression verbessert es die Leistung bei der Lösung komplexer Probleme und der Interaktion in mehrstufigen Dialogen deutlich.
Auf der Ebene der Kernfunktionen erzielt dieses Modell eine umfassende Verbesserung der Denkfähigkeit durch die Einführung einer hochwertigen Technologie zur Destillation von Gedankenketten. Dadurch eignet es sich besonders für Szenarien wie mathematische Ableitungen, logische Analysen, Planung und Entscheidungsfindung sowie die Zerlegung mehrstufiger Aufgaben. Im Vergleich zu herkömmlichen Modellen kann dieses System nicht nur Antworten generieren, sondern Probleme auch strukturiert Schritt für Schritt analysieren und komplexe Aufgaben in klare und ausführbare logische Schritte unterteilen. Dies verbessert die Stabilität der Denkprozesse und die Zuverlässigkeit der Ergebnisse insgesamt.
Online ausführen:
Gemma-4-31B-it
Die Open-Source-Modelle der Gemma 4-Serie von Google DeepMind, die auf dem gleichen Technologiesystem wie Gemini 3 basieren, zählten nicht nur zu den drei Besten in der Arena AI-Rangliste, sondern erreichten auch eine Leistung, die nahe an der von größeren Modellen lag oder diese sogar übertraf, und das bei einem Parameterbereich, der weit kleiner war als der der Konkurrenz.
Aus Produktperspektive handelt es sich bei Gemma 4 nicht um ein einzelnes Modell, sondern um ein System mit verschiedenen Größen, von E2B über E4B und 26B bis hin zu A4B und 31B, die unterschiedlichen Anwendungsszenarien wie mobilen Geräten, lokalen Installationen und Hochleistungsrechnerumgebungen gerecht werden. Die Version 31B, das leistungsstärkste Modell der aktuellen Serie, bietet eine Leistungsfähigkeit, die sogar mit der des Qwen 3.5 397B mithalten kann.
Hinsichtlich der Anwendungsszenarien unterstützt Version 31B Bild- und Texteingabe sowie Textausgabe, verfügt über ein Kontextfenster mit bis zu 256.000 Tokens und bietet native Unterstützung für Inferenz, Funktionsaufrufe und Systemeingabeaufforderungen. Zudem werden über 140 Sprachen unterstützt, wodurch sich die Software optimal für Szenarien wie hochwertige Fragebeantwortung, Codeunterstützung und Agentendienste eignet.
Online ausführen:
CPU-Bereitstellung Qwen3.5-9B-GGUF
Qwen3.5 ist eine neue Generation multimodaler Sprachmodelle für große Systeme, entwickelt vom Tongyi Qianwen-Team von Alibaba. Es unterstützt Text- und Bildeingabe und generiert Textausgabe. Ziel sind Aufgaben wie Dialogverarbeitung, logisches Schlussfolgern, Programmierung und visuelles Verständnis. Qwen3.5-9B ist die Version mit neun Parametern und bietet ein ausgewogenes Verhältnis zwischen Leistungsfähigkeit und Bereitstellungskosten. Es eignet sich für Edge- oder lokale Inferenzanwendungen in ressourcenbeschränkten Umgebungen.
In diesem Tutorial verwenden wir die von der Community bereitgestellten GGUF-Gewichte (Q4_K_M-quantisierte Version) und kombinieren sie mit einem visuellen Encoder (MMPROJ-GGUF-Datei). Wir starten einen mit der OpenAI-Schnittstelle kompatiblen Backend-Dienst über llama.cpp und verbinden uns mit OpenWebUI, um eine browserbasierte interaktive Oberfläche bereitzustellen.
Online ausführen:
Weitere beliebte Tutorials finden Sie hier:








