Command Palette
Search for a command to run...
Online-Tutorials | Schnelle Bereitstellung Mit Kostenlosen CPU-Ressourcen, Die Gängige Open-Source-Modelle Wie Qwen 3.5/DeepSeek-R1/Gemma 3/Llama 3.2 usw. abdecken.

Die Entwicklungsgeschwindigkeit von Open-Source-Modellen steigt rasant. Von Technologiekonzernen über Startups bis hin zu Forschungsteams – ständig entstehen in verschiedenen Benchmark-Tests neue Modelle. Doch in diesem schnelllebigen KI-Umfeld bestehen weiterhin Hürden für Entwickler, innovative Technologien zu nutzen.
Die Open-Source-Community entwickelt sich heute rasant zu einem äußerst aktiven Modell-Ökosystem. Vor diesem Hintergrund hoffen immer mehr Entwickler, neue Modelle einfacher und schneller bereitstellen und testen zu können, um deren Leistungsfähigkeit zu evaluieren und potenzielle Anwendungsszenarien zu erkunden. In der Praxis sieht es jedoch anders aus…Die hohen Kosten für GPU-Ressourcen, komplexe Umgebungskonfigurationen und hohe Hardwareanforderungen stellen für viele Entwickler weiterhin große Hindernisse beim Einsatz von Modellen dar.
Tatsächlich ist dies der kontinuierlichen Optimierung von Quantifizierungstechniken und Argumentationsrahmen zu verdanken.Viele gängige Open-Source-Modelle sind bereits in der Lage, grundlegende Inferenz und funktionale Verifikation in einer CPU-Umgebung durchzuführen.Dies eröffnet Entwicklern neue Möglichkeiten für Modellerfahrung und Prototypenentwicklung unter kostengünstigen Bedingungen.
Erwähnenswert ist, dass zur Erleichterung einer schnellen und unkomplizierten Projektumsetzung für globale Entwickler,HyperAI bietet kostenlose CPU-Kontingente an: Basic-Benutzer können eine einzelne Aufgabe bis zu 12 Stunden lang ununterbrochen ausführen, Pro-Benutzer sogar bis zu 24 Stunden.Gleichzeitig hat HyperAI im Bereich „Tutorials“ Online-Tutorials für die Ausführung gängiger Open-Source-Modelle wie Qwen, DeepSeek, Gemma, Llama und GLM auf der CPU veröffentlicht. Diese Tutorials bieten einen vollständigen Bereitstellungsprozess von der Umgebungsvorbereitung und dem Modell-Download bis hin zur Inferenz und Ausführung. So können Nutzer erste Erfahrungen mit Modellinferenz sammeln und grundlegende Entwicklungstests durchführen, ohne eine komplexe lokale Umgebung einrichten zu müssen.
Klicken Sie hier, um mehr über HyperAI Pro zu erfahren:Kostenlose CPU-Nutzung / 30 Stunden GPU-Nutzungsguthaben / 70 GB extragroßer Speicherplatz: HyperAI Pro ist offiziell erschienen!
CPU-Bereitstellung von Qwen3.5-9B-GGUF:
CPU-Bereitstellung von Qwen2.5-14B-Instruct-GGUF:
CPU-Bereitstellung von Qwen2.5-3B-Instruct-GGUF:
CPU-Bereitstellung von DeepSeek-R1-Distill-Qwen-1.5B-GGUF:
CPU-Bereitstellung DeepSeek-Coder-V2-Lite-Instruct-GGUF:
CPU-Bereitstellung von Gemma-3-1b-it-GGUF:
CPU-Bereitstellung von Llama-3.2-3B-Instruct-GGUF:
CPU-Bereitstellung von gpt-oss-20b-GGUF:
CPU-Bereitstellung von Phi-4-mini-instruct-GGUF:
CPU-Bereitstellung von GLM-4-9B-chat-GGUF:
In diesem Artikel wird das Tutorial anhand des Beispiels „Bereitstellung von Qwen3.5-9B-GGUF auf der CPU“ demonstriert.
Demolauf
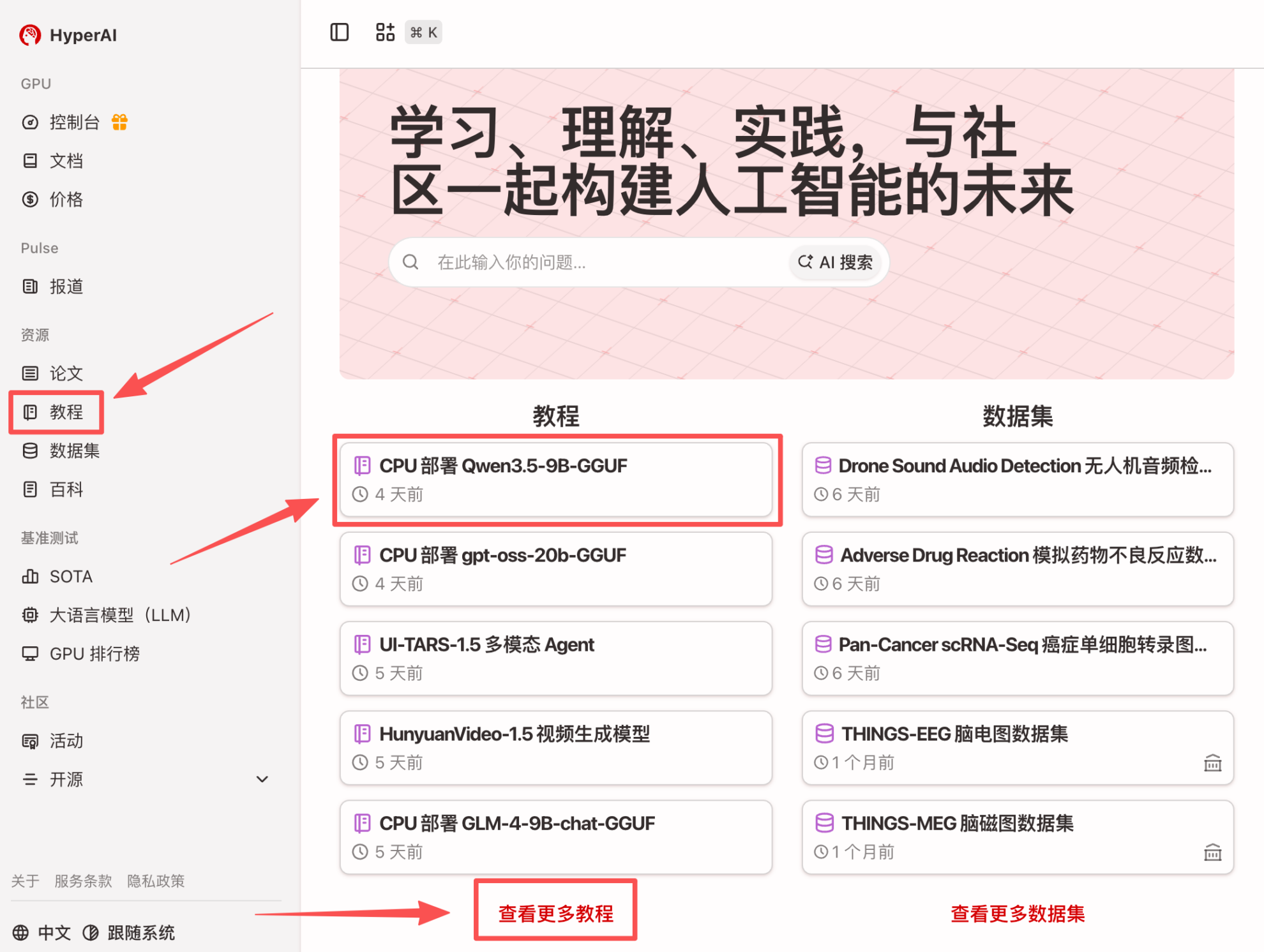
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „CPU Deployment Qwen3.5-9B-GGUF“ aus und klicken Sie auf „Dieses Tutorial online ausführen“.
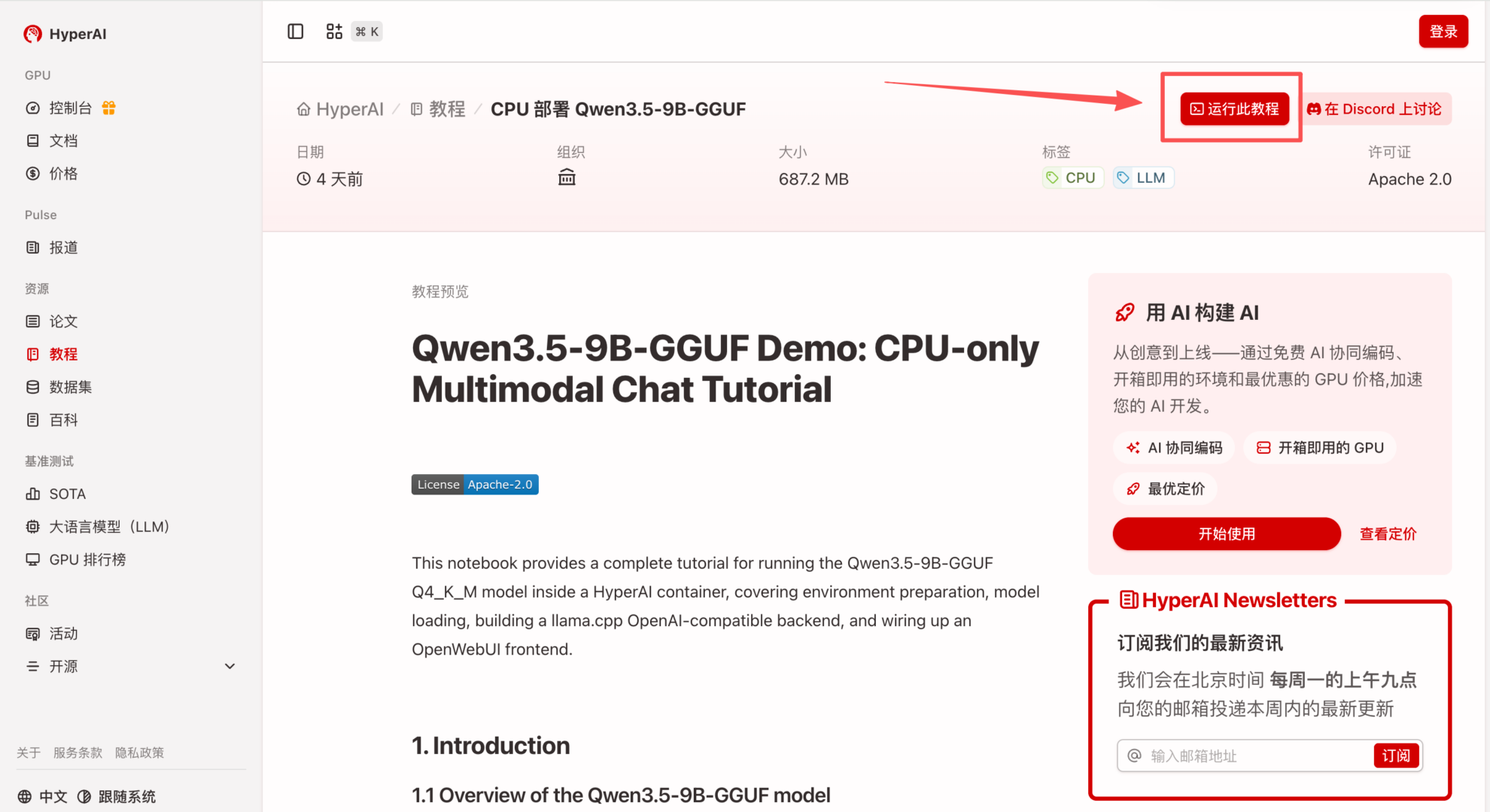
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
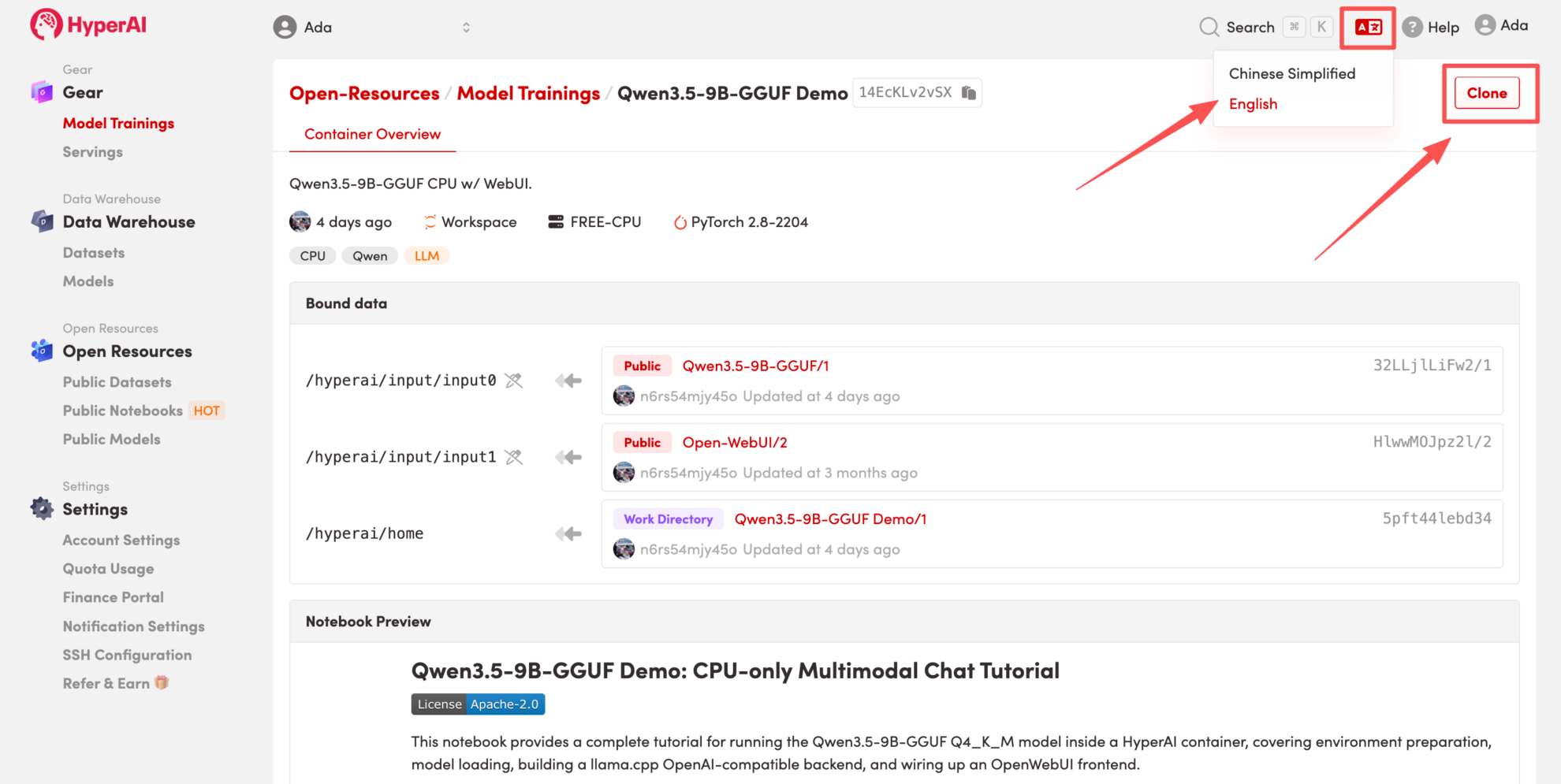
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
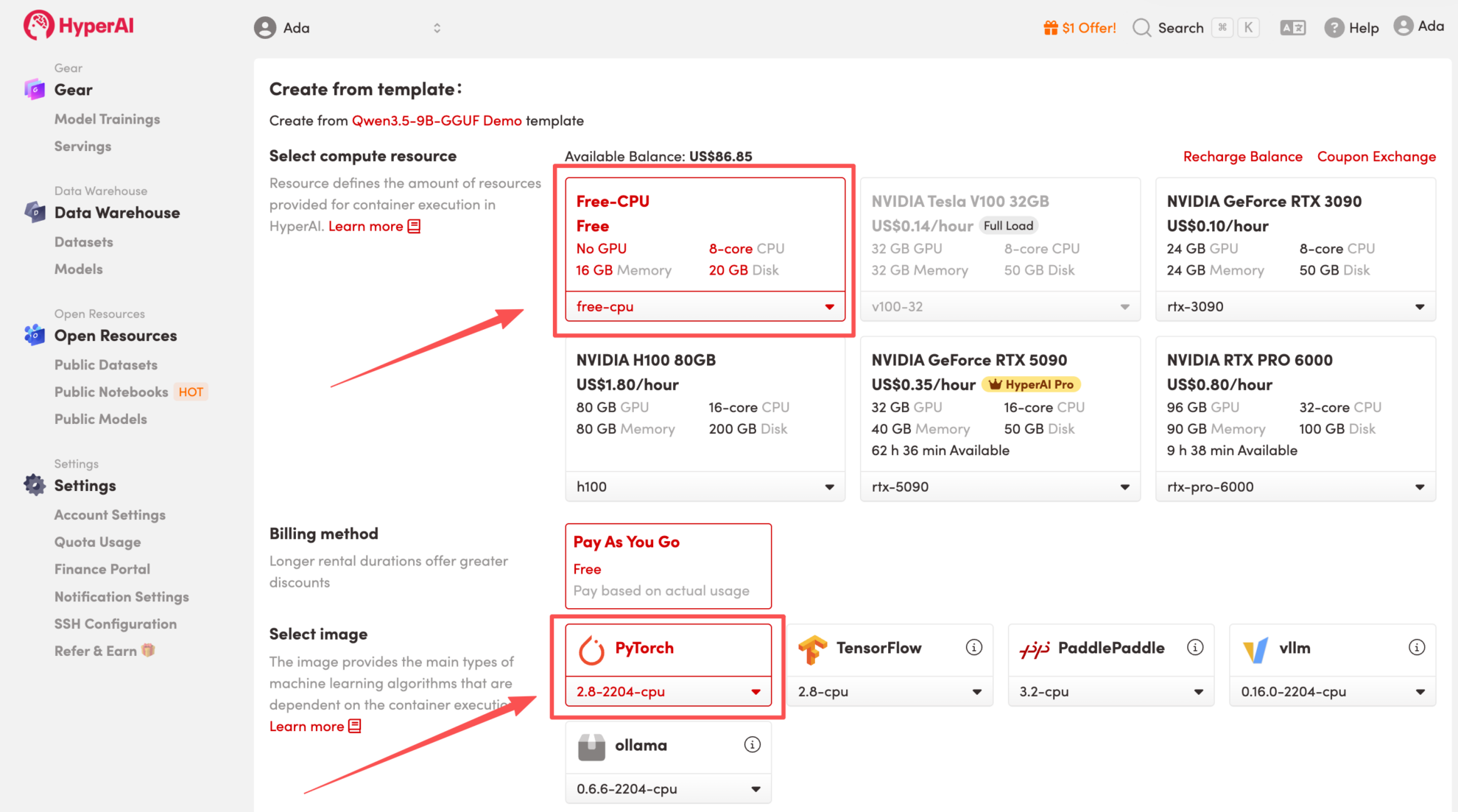
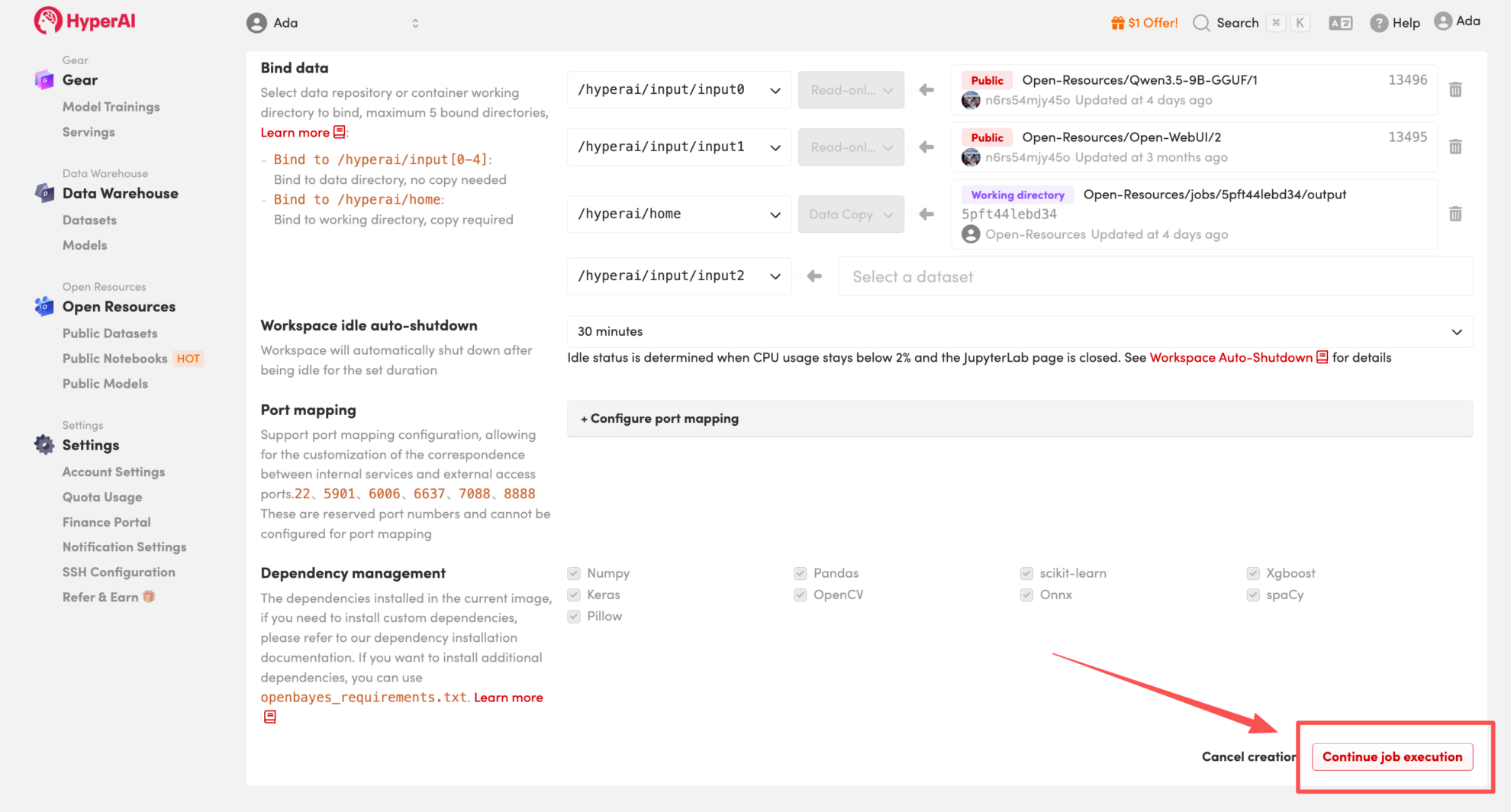
3. Wählen Sie die Images „Free-CPU“ und „PyTorch“ aus und klicken Sie auf „Jobausführung fortsetzen“.
HyperAI bietet Neukunden Registrierungsvorteile.Für nur $1 erhalten Sie 20 Stunden Rechenleistung einer RTX 5090 (ursprünglicher Preis $7).Die Ressource ist dauerhaft gültig.
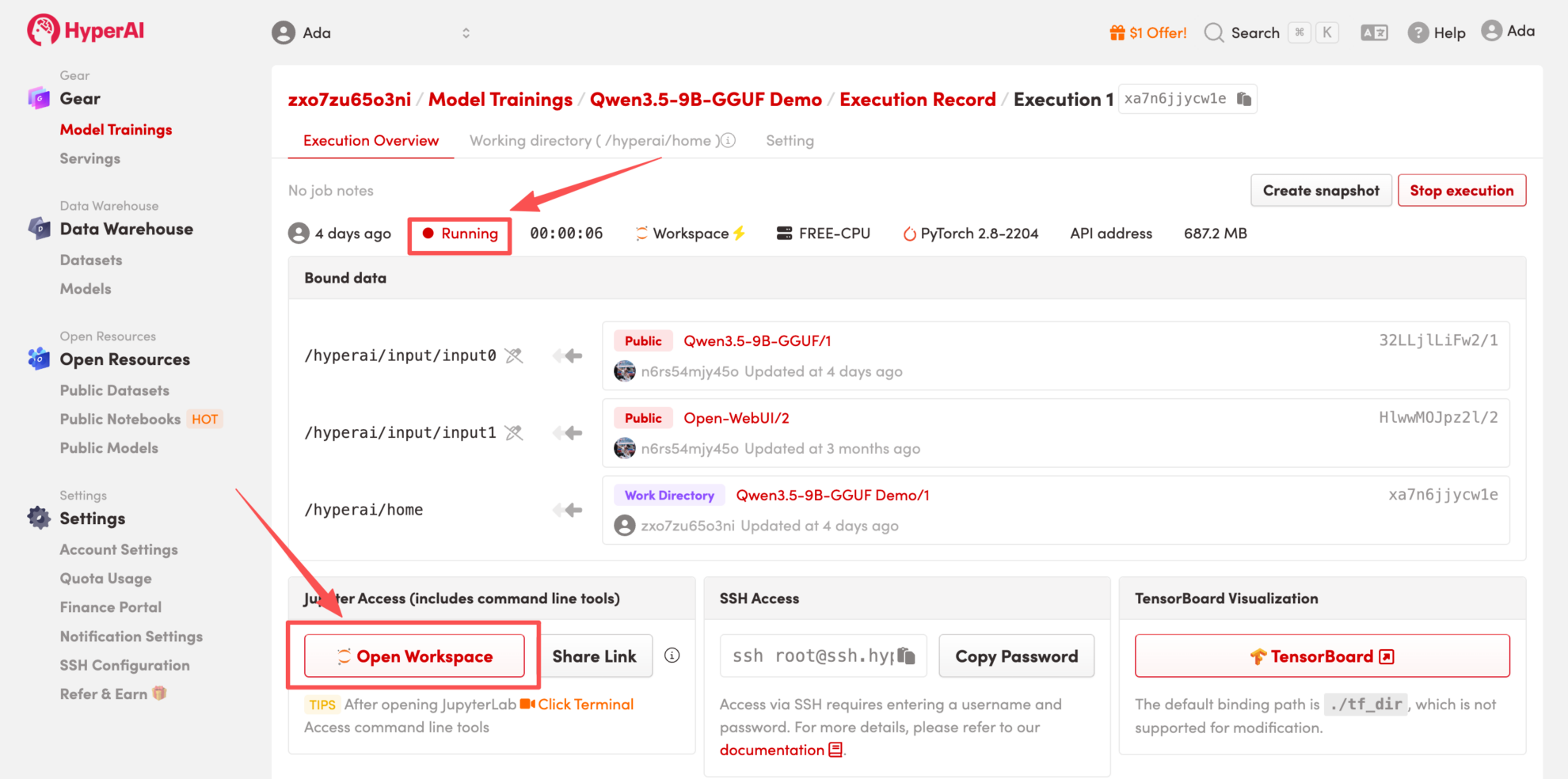
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
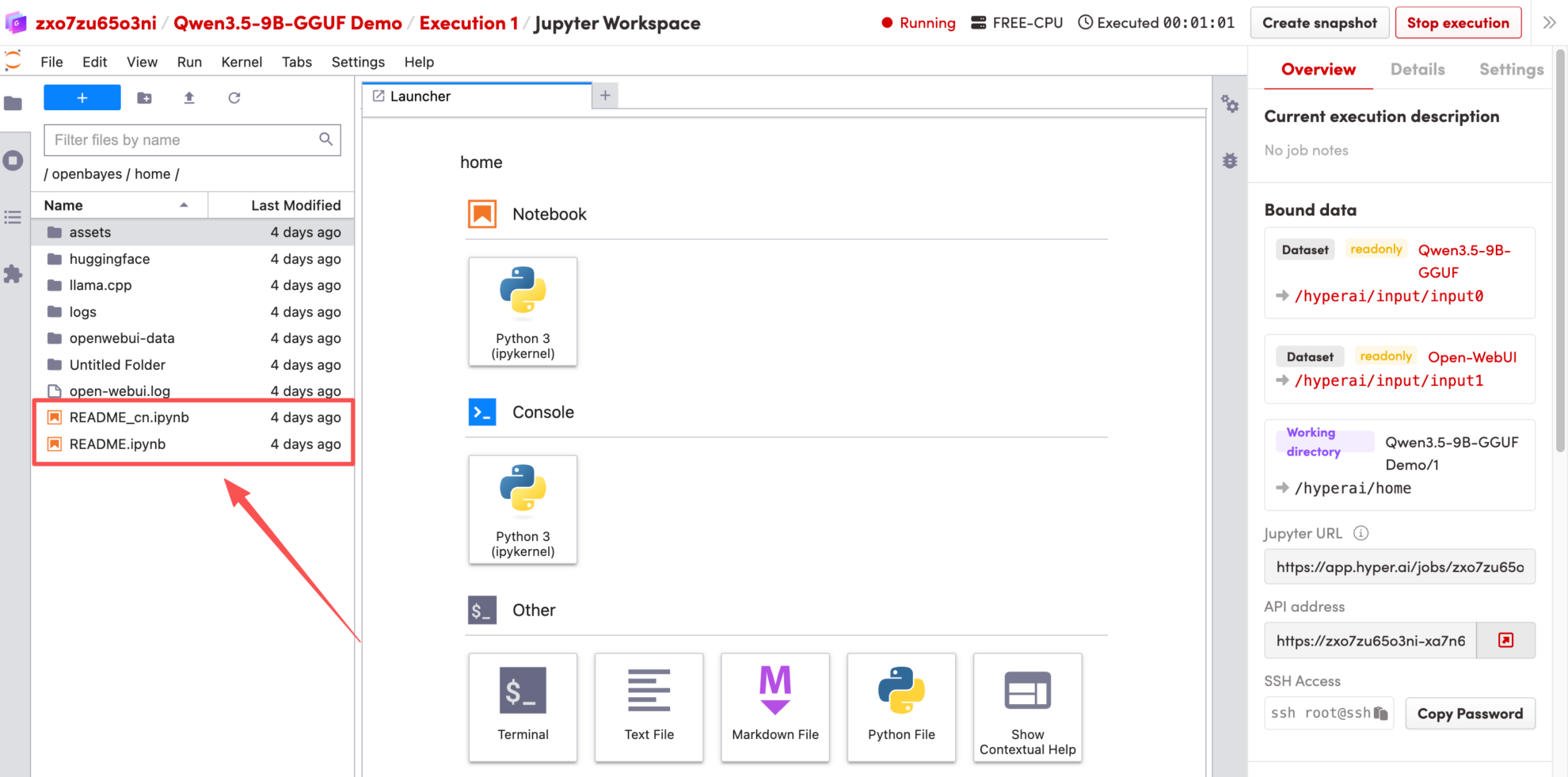
Effektdemonstration
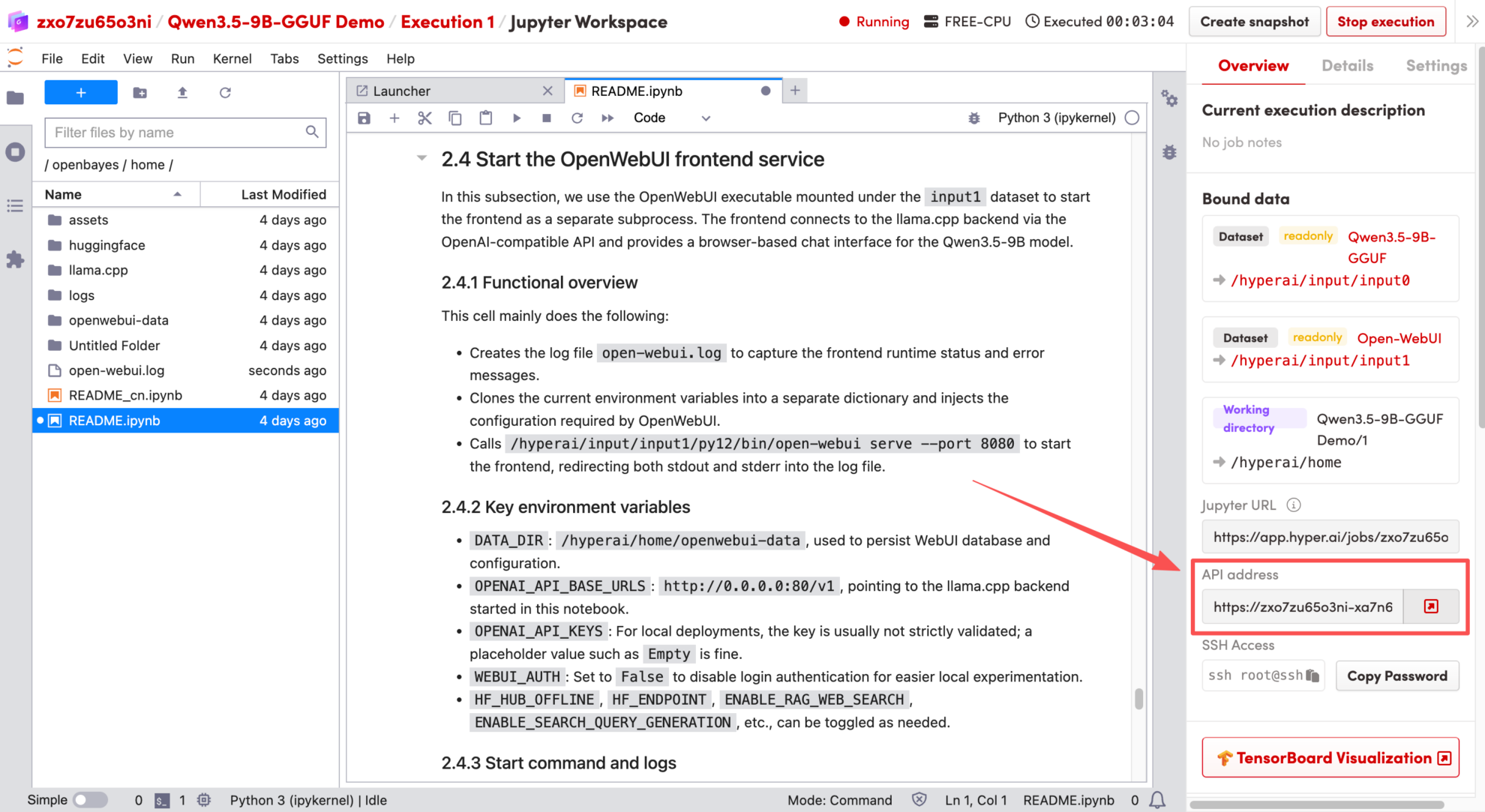
1. Nachdem die Seite weitergeleitet wurde, klicken Sie auf die README-Datei auf der linken Seite und anschließend oben auf der Seite auf Ausführen.
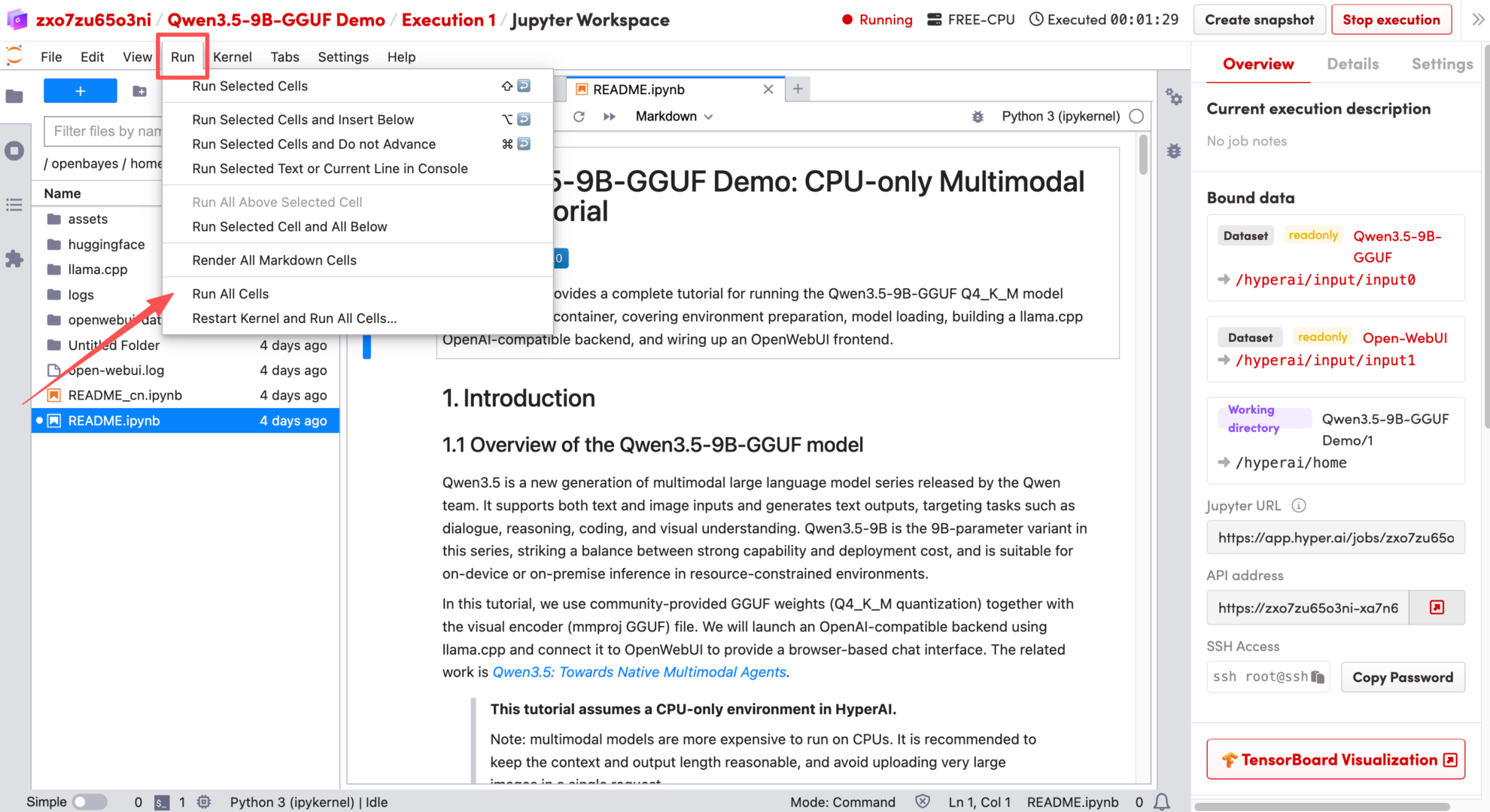
2. Sobald der Vorgang abgeschlossen ist, klicken Sie auf die API-Adresse rechts, um zur Demoseite zu gelangen.

Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!








