Command Palette
Search for a command to run...
Online-Tutorial | Basierend Auf 5 Millionen Stunden Sprachdaten Erreicht Qwen3-TTS Eine 3-Sekunden-Stimmklonierung Und -Feinabstimmung.

Wenn generative KI nicht mehr nur Texte generiert, sondern tatsächlich „spricht“, wandelt sich Sprache von einem reinen Informationskanal zu einem programmierbaren und formbaren Ausdrucksmittel. Von der mehrsprachigen Inhaltserstellung bis hin zu Echtzeit-Sprachassistenten, von virtuellen Ankern bis zu immersiven interaktiven Systemen – Text-to-Speech (TTS) wird zu einem Kernbestandteil multimodaler Modellsysteme.Um jedoch eine natürliche, stabile und kontrollierbare Sprachausgabe der Maschine zu erreichen und in Streaming-Szenarien eine Reaktionszeit im Millisekundenbereich zu gewährleisten, bedarf es nicht nur akustischer Modellierungsfähigkeiten, sondern auch umfassender Kompetenzen im Architekturdesign und in der Systemoptimierung.
Auf diesem technologischen Entwicklungspfad hat die neue Generation von Modellen begonnen, die Grenzen der traditionellen TTS zu überwinden – nicht nur durch das Streben nach höherer Wiedergabetreue, sondern auch durch die Betonung der mehrsprachigen Generalisierungsfähigkeit und der fein abgestuften Steuerungsfähigkeit.Qwen3-TTS, das kürzlich vom Qwen-Team als Open Source veröffentlicht wurde, basiert auf einer Dual-Track-Sprachmodellarchitektur (LM), die eine feingranulare Steuerung der Ausgabesprache bei gleichzeitiger Echtzeit-Sprachsynthese ermöglicht.
Qwen3-TTS unterstützt insbesondere die Klonung von 3-Sekunden-Stimmen und die sprachbasierte Steuerung mittels Beschreibungen. Es wurde mit über 5 Millionen Stunden Sprachdaten in 10 Sprachen trainiert und ist mit zwei Sprachtokenisierern ausgestattet.
* Qwen-TTS-Tokenizer-25Hz:Durch die Verwendung eines Single-Codebook-Codecs konzentriert er sich auf die semantische Inhaltsdarstellung, lässt sich nahtlos in Qwen-Audio integrieren und erreicht die Rekonstruktion von Streaming-Wellenformen durch blockweises DiT.
* Qwen-TTS-Tokenizer-12Hz:Durch die Erzielung einer extremen Bitratenkomprimierung und einer Streaming-Ausgabe mit extrem niedriger Latenz, basierend auf einem 12,5-Hz-Multi-Codebook-Design mit 16 Schichten und einem leichtgewichtigen Causal Convolutional Network (Causal ConvNet), kann die sofortige Ausgabe des ersten Pakets in 97 Millisekunden erreicht werden.
Umfangreiche experimentelle Ergebnisse zeigen, dass diese Modellreihe in zahlreichen objektiven und subjektiven Benchmark-Tests, einschließlich des mehrsprachigen TTS-Testsets und InstructTTSEval, eine Leistung auf dem neuesten Stand der Technik (SOTA) erzielt hat.
Aktuell ist die Demo „Qwen3-TTS: Hochwertige, steuerbare, mehrsprachige Sprachsynthese“ im Bereich „Tutorials“ der HyperAI-Website verfügbar. Erleben Sie Sprachklonierung in nur 3 Sekunden!
Online-Tutorials:
Lesen Sie das Dokument:
Demolauf
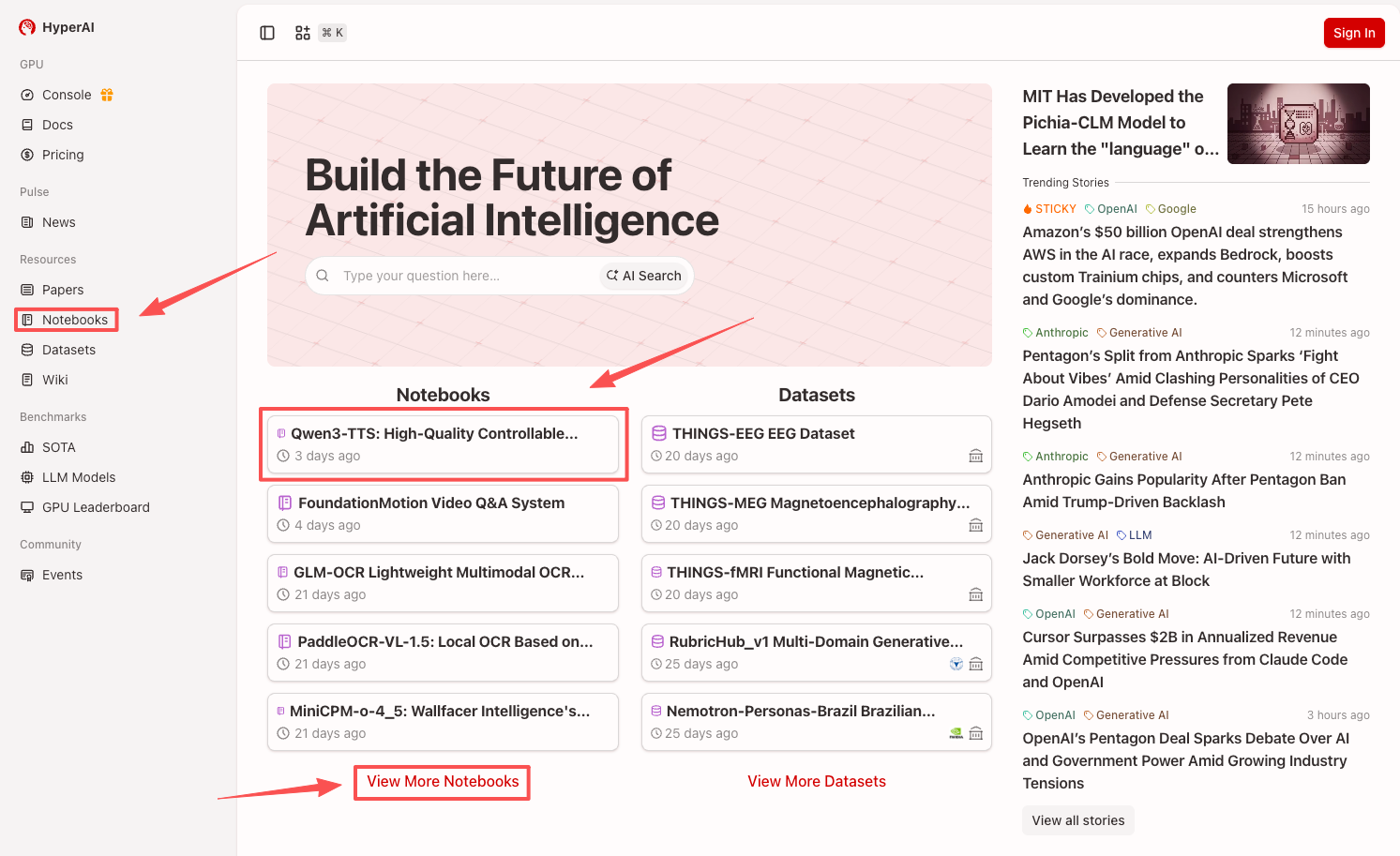
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „Qwen3-TTS: Hochwertige, steuerbare, mehrsprachige Sprachsynthese-Demo“ aus und klicken Sie auf „Dieses Tutorial online ausführen“.
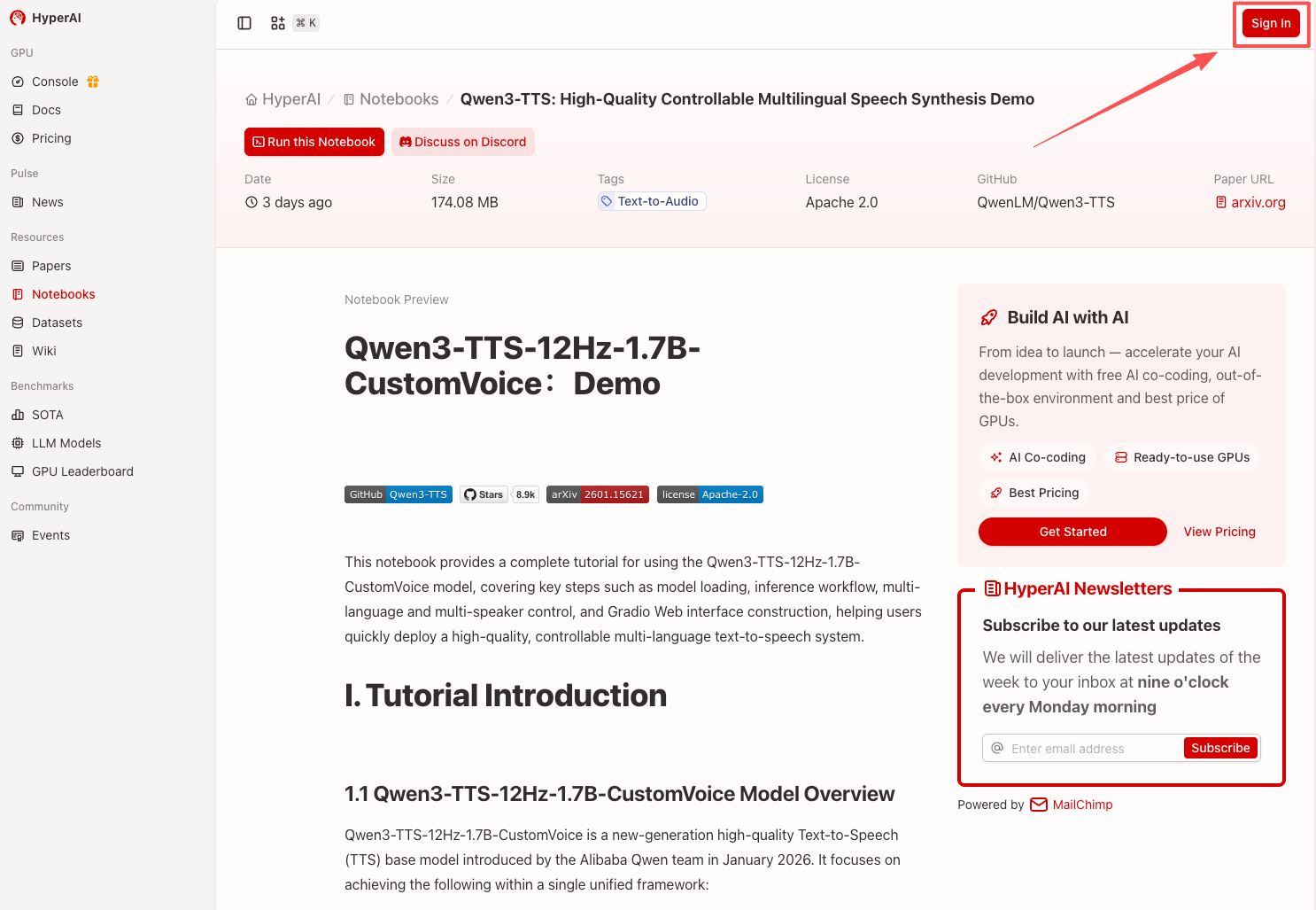
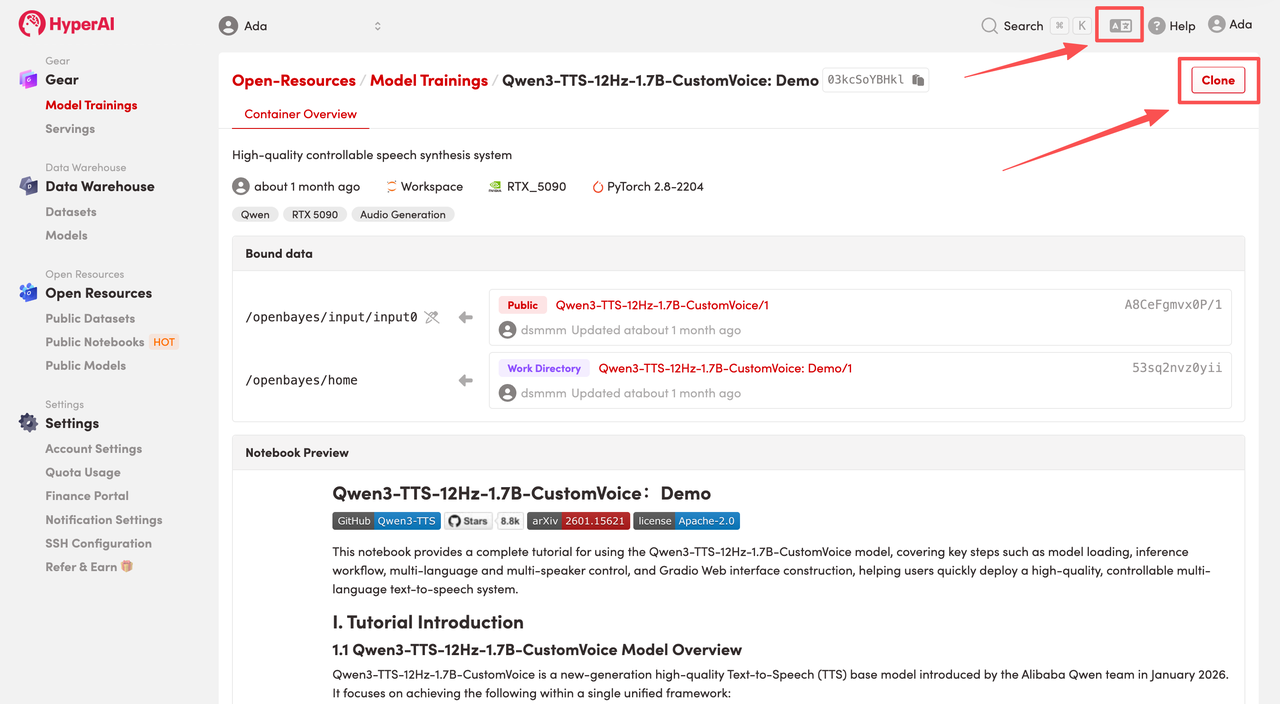
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
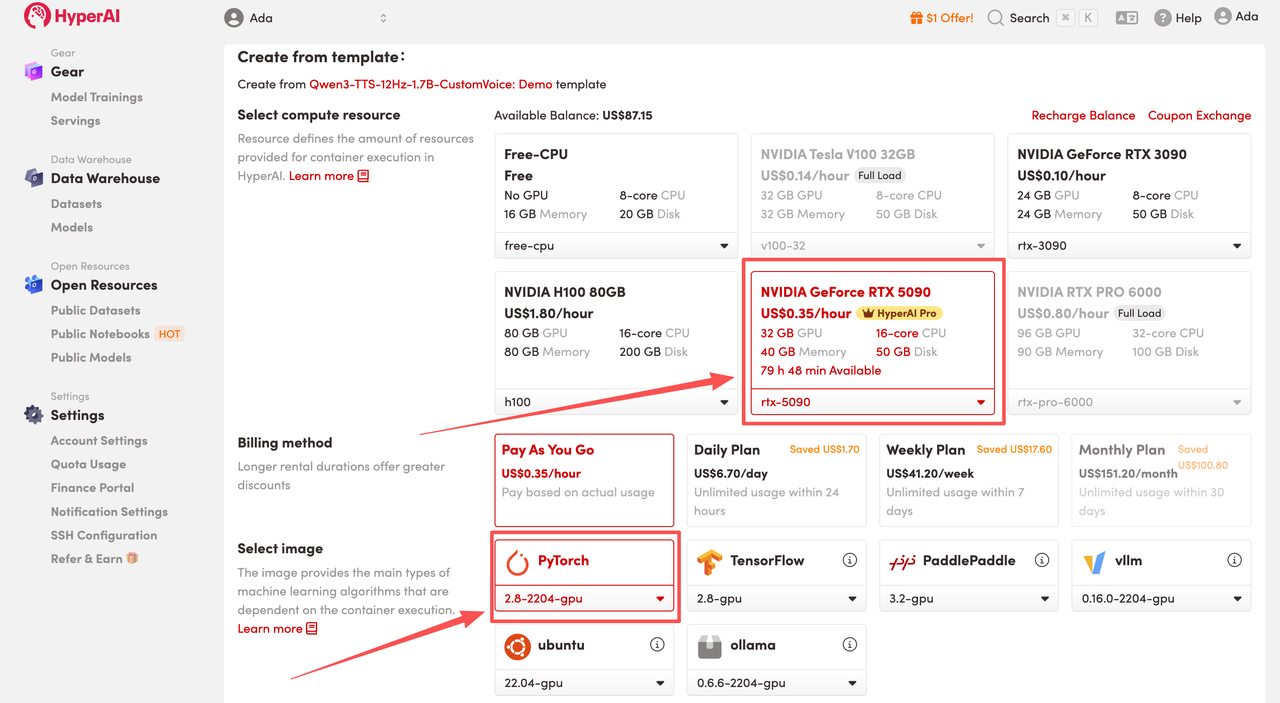
3. Wählen Sie die Images „NVIDIA GeForce RTX 5090“ und „PyTorch“ aus und wählen Sie je nach Bedarf „Pay As You Go“ oder „Tagesplan/Wochenplan/Monatsplan“. Klicken Sie anschließend auf „Auftragsausführung fortsetzen“.
HyperAI bietet Neukunden Registrierungsvorteile.Für nur $1 erhalten Sie 20 Stunden Rechenleistung einer RTX 5090 (ursprünglicher Preis $7).Die Ressource ist dauerhaft gültig.
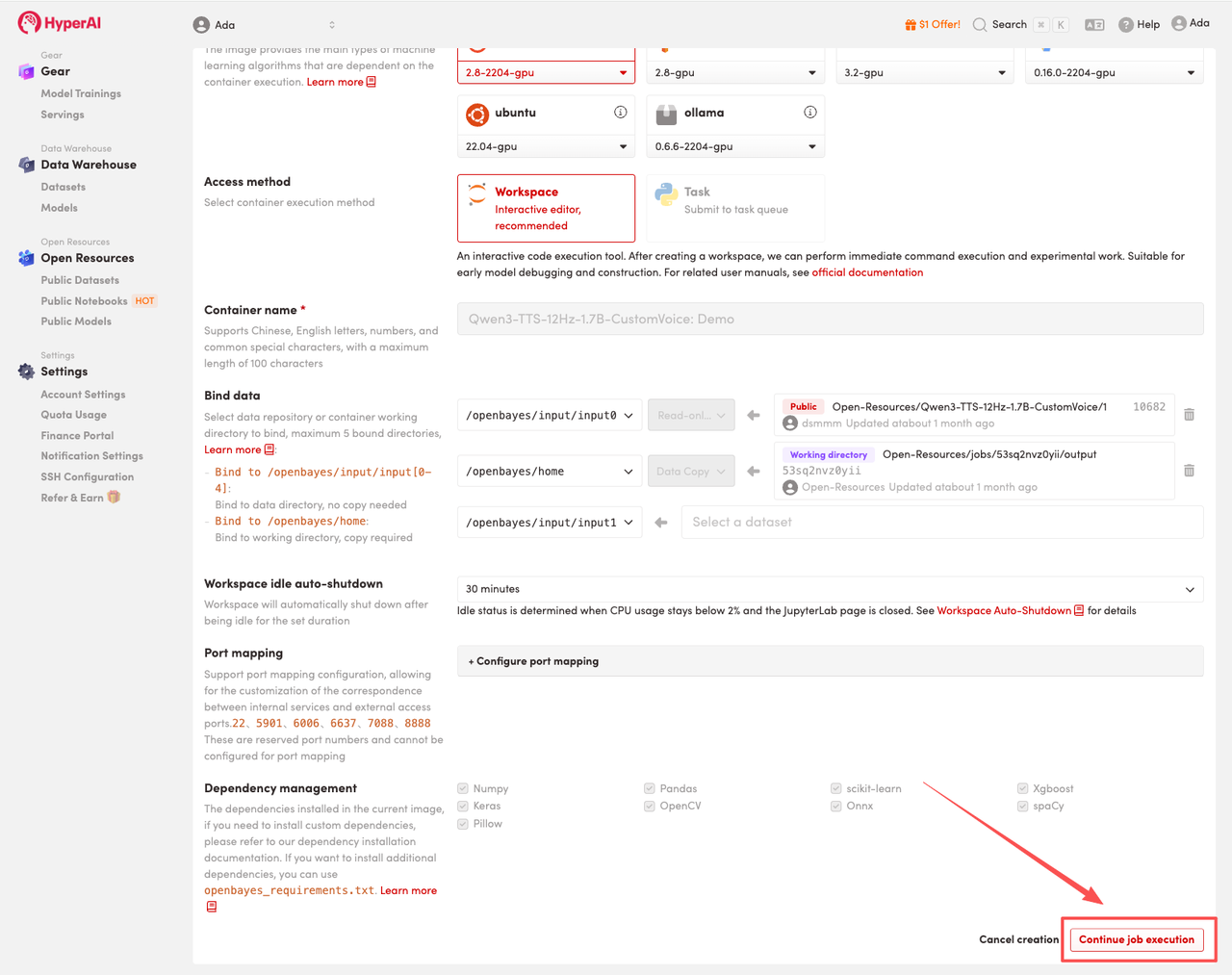
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
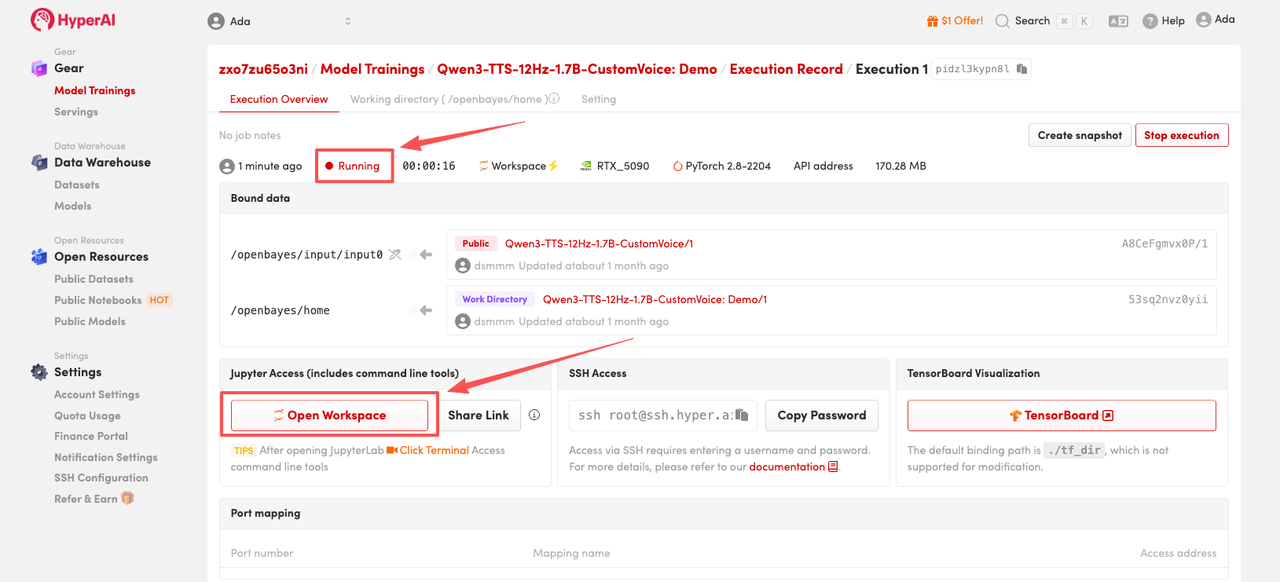
Effektdemonstration
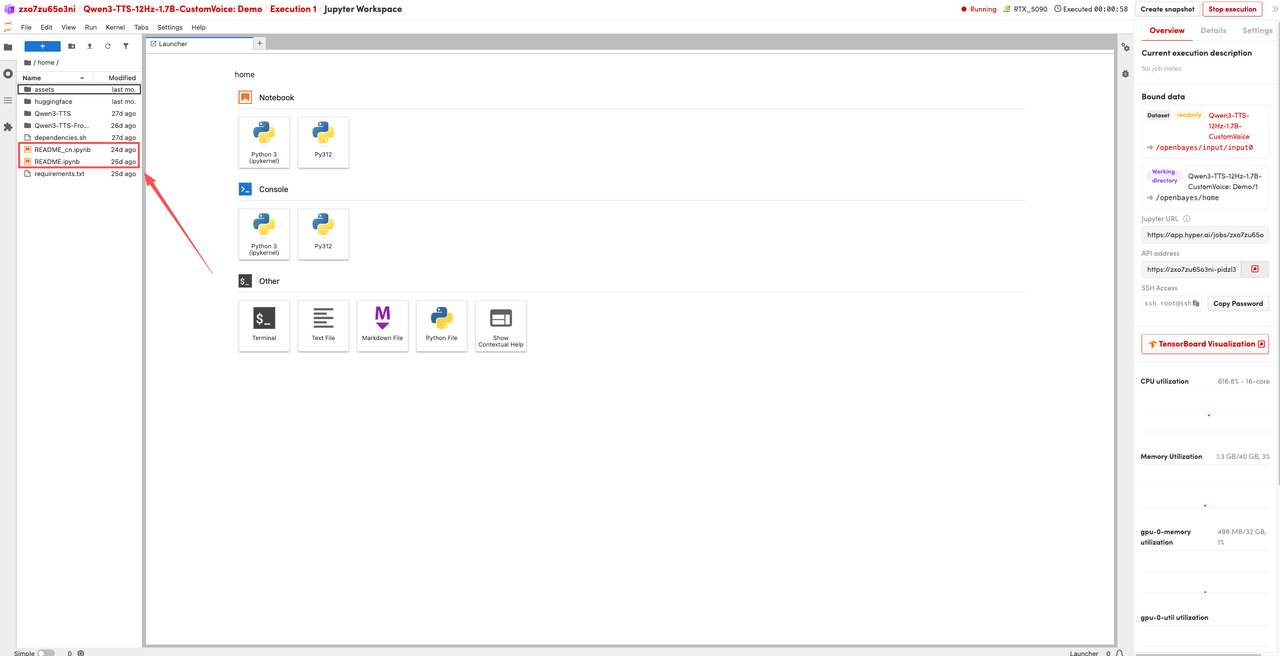
1. Nachdem die Seite weitergeleitet wurde, klicken Sie links auf die README-Seite und anschließend oben auf Ausführen.
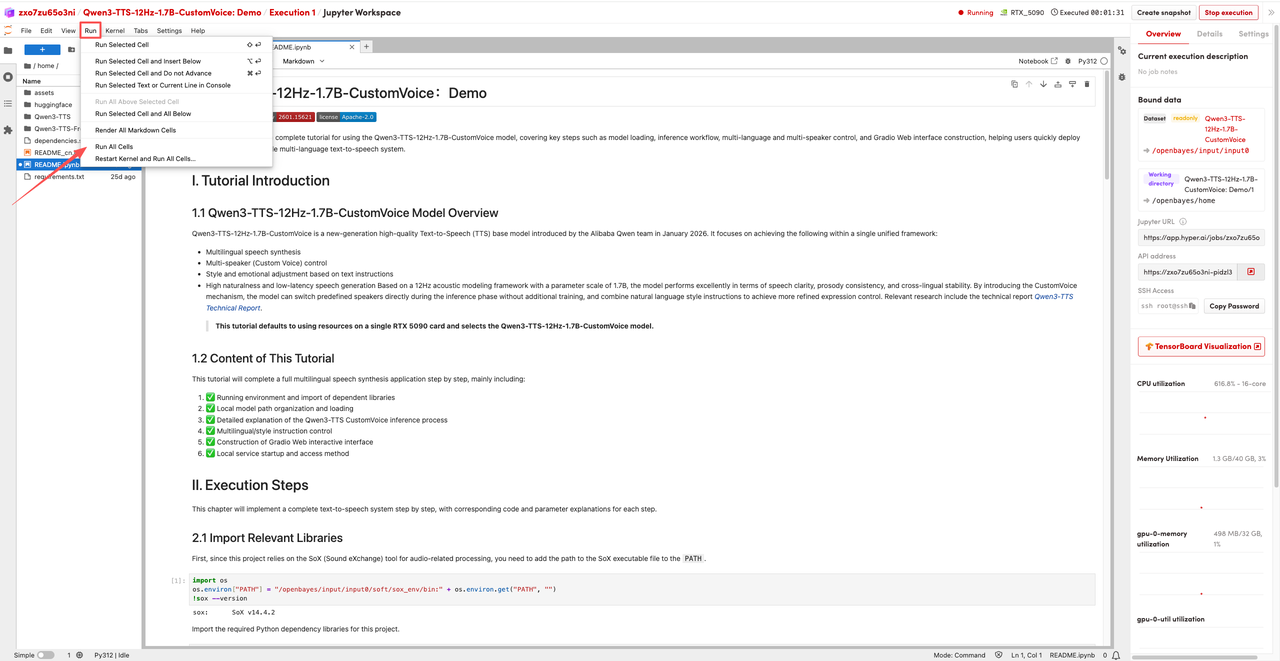
2. Sobald der Vorgang abgeschlossen ist, klicken Sie auf die API-Adresse rechts, um zur Demoseite zu gelangen.
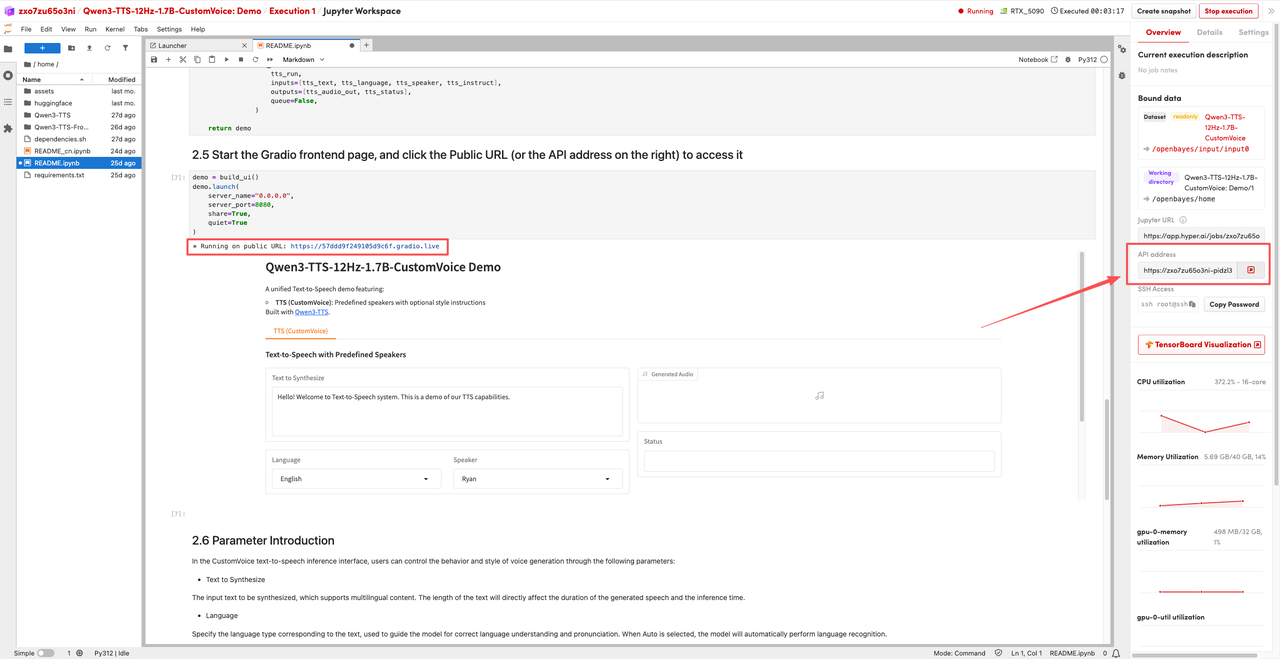
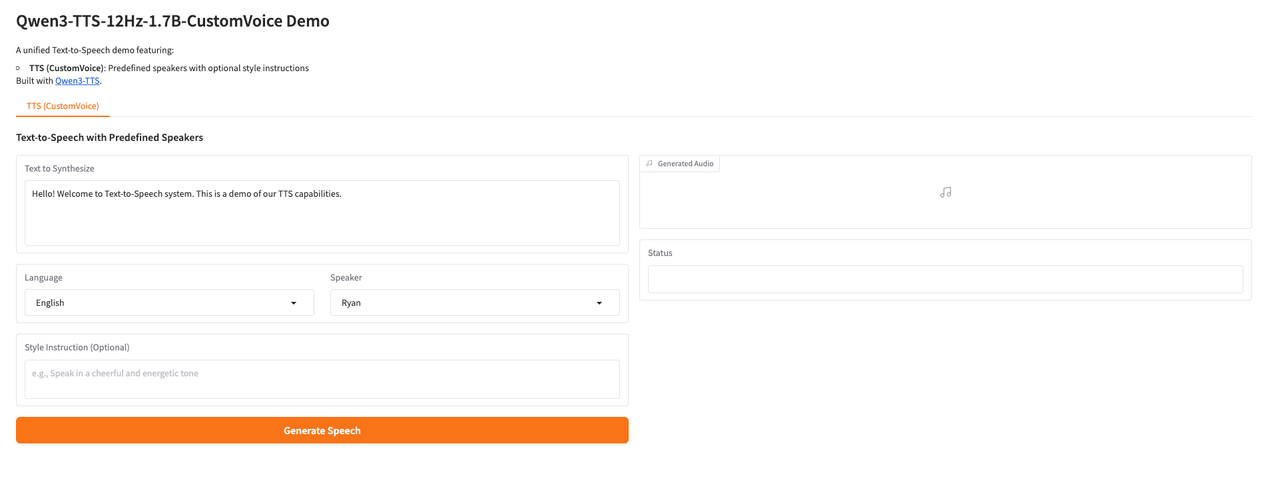
Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!
Link zum Tutorial:https://go.hyper.ai/1xEOr








