Command Palette
Search for a command to run...
Online-Tutorial | Ausführlicher Leitfaden Zu Befehlsverarbeitung/Inferenz/Codierung: Mistral Medium 3.5 Bringt Codierungsagenten in Die Cloud

Mit der Weiterentwicklung der Fähigkeiten von KI-Agenten wandeln sich groß angelegte Modelle schrittweise von „Dialogassistenten“ zu wirklich intelligenten Systemen, die Aufgaben selbstständig ausführen können. Mistral AIs Mistral Medium 3.5 hebt KI-Codierungsagenten nun auf ein neues Niveau. Im Vergleich zu herkömmlichen Programmierassistenten, die lediglich einfache Codevervollständigung bieten, kann Mistral Medium jetzt eigenständig in der Cloud laufen, Aufgaben parallel verarbeiten und komplexe Softwareentwicklungsprozesse kontinuierlich durchführen – von der Codegenerierung über das Debuggen und die Installation von Abhängigkeiten bis hin zur Testausführung und sogar dem Einreichen von Pull Requests.
Als neuestes Flaggschiffmodell von Mistral verfügt das Mistral Medium 3.5 über eine 128-Byte-Architektur, 256k Kontextfenster und integriert erstmals Befehlsverfolgung, Schlussfolgerungs- und Codierungsfunktionen in einem einzigen Modell.
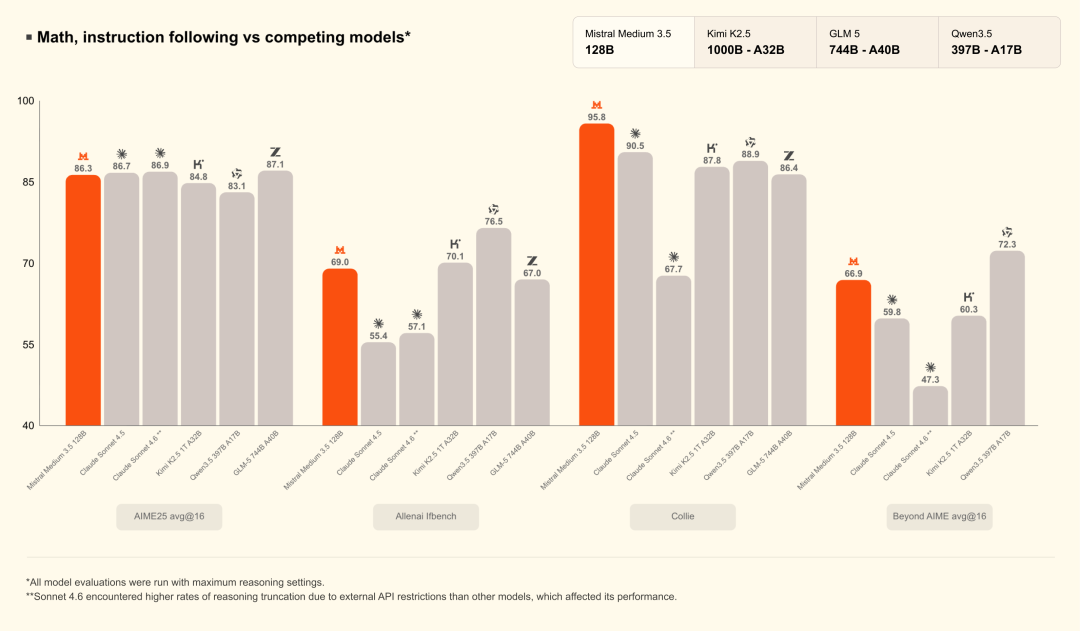
Im Gegensatz zu aktuellen großen Modellen, die stark auf der MoE-Architektur basieren, hat Mistral seinen Dense-Model-Ansatz weiterentwickelt und so die Verarbeitungskapazitäten für langlaufende Aufgaben verbessert, ohne die Stabilität der Inferenz zu beeinträchtigen. Offizielle Daten zeigen, dass Mistral Medium 3.5 im SWE-Bench Verified einen TP3T-Wert von 77,61 erreichte und damit Modelle wie Devstral 2 und Qwen3.5 397B A17B übertraf. Auch in Agentenfähigkeitstests wie τ³-Telecom zeigte es eine starke Leistung.
Neben dem Modell selbst ist die wichtigste Neuerung dieses Updates die umfassende Umstrukturierung des KI-Agenten-Workflows von Mistral. Dank Vibe Remote Agents können Entwickler asynchrone Coding-Sessions direkt in der Cloud ausführen, wodurch die Notwendigkeit entfällt, dass Aufgaben permanent lokal online bleiben müssen. Benutzer können Aufgaben über die CLI starten oder Cloud-Agenten direkt in Le Chat aufrufen. So kann das Modell kontinuierlich mehrstufige Coding-Aufgaben ausführen, darunter Modul-Refactoring, Testgenerierung, CI-Fehlerbehebung und Bugfixing. Gleichzeitig unterstützt der neu hinzugefügte Arbeitsmodus die toolübergreifende Zusammenarbeit und ermöglicht den Zugriff auf externe Systeme wie E-Mail, Kalender, Dokumente und Kollaborationsplattformen. Dadurch entwickelt sich Mistral schrittweise zu einem echten „ausführungsorientierten KI-Assistenten“.
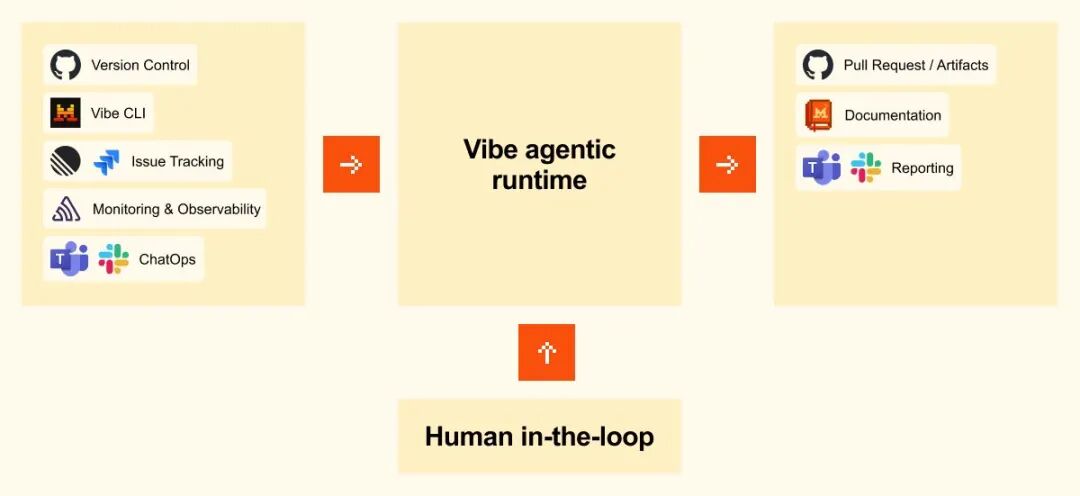
Mistral Medium 3.5 stellt in gewisser Hinsicht mehr als nur ein Modell-Upgrade dar; es markiert einen bedeutenden Wandel in der KI-Programmierung – vom „Copiloten“ zum „autonomen Agenten“. Während KI in der Vergangenheit primär als Hilfsgenerator für Code diente, sind Modelle nun zunehmend in der Lage, Aufgaben über längere Zeiträume auszuführen, Tools aufzurufen, Prozesse zu steuern und Ergebnisse zu liefern. Dank kontinuierlicher Verbesserungen hinsichtlich Kontextlänge, Inferenzstabilität und Agenten-Framework könnten sich zukünftige Softwareentwicklungsprozesse ebenfalls grundlegend verändern.
Aktuell bietet der Tutorial-Bereich der offiziellen Website von HyperAI (hyper.ai) das Projekt „Ein-Klick-Bereitstellung von Mistral-Medium-3.5-128B“ an, um die Umgebungskonfiguration abzuschließen und die Einstiegshürde für die Nutzung des Modells weiter zu senken.
Online ausführen:
Weitere Online-Tutorials:
Besuchen Sie unsere offizielle Website für weitere Informationen:
Demolauf
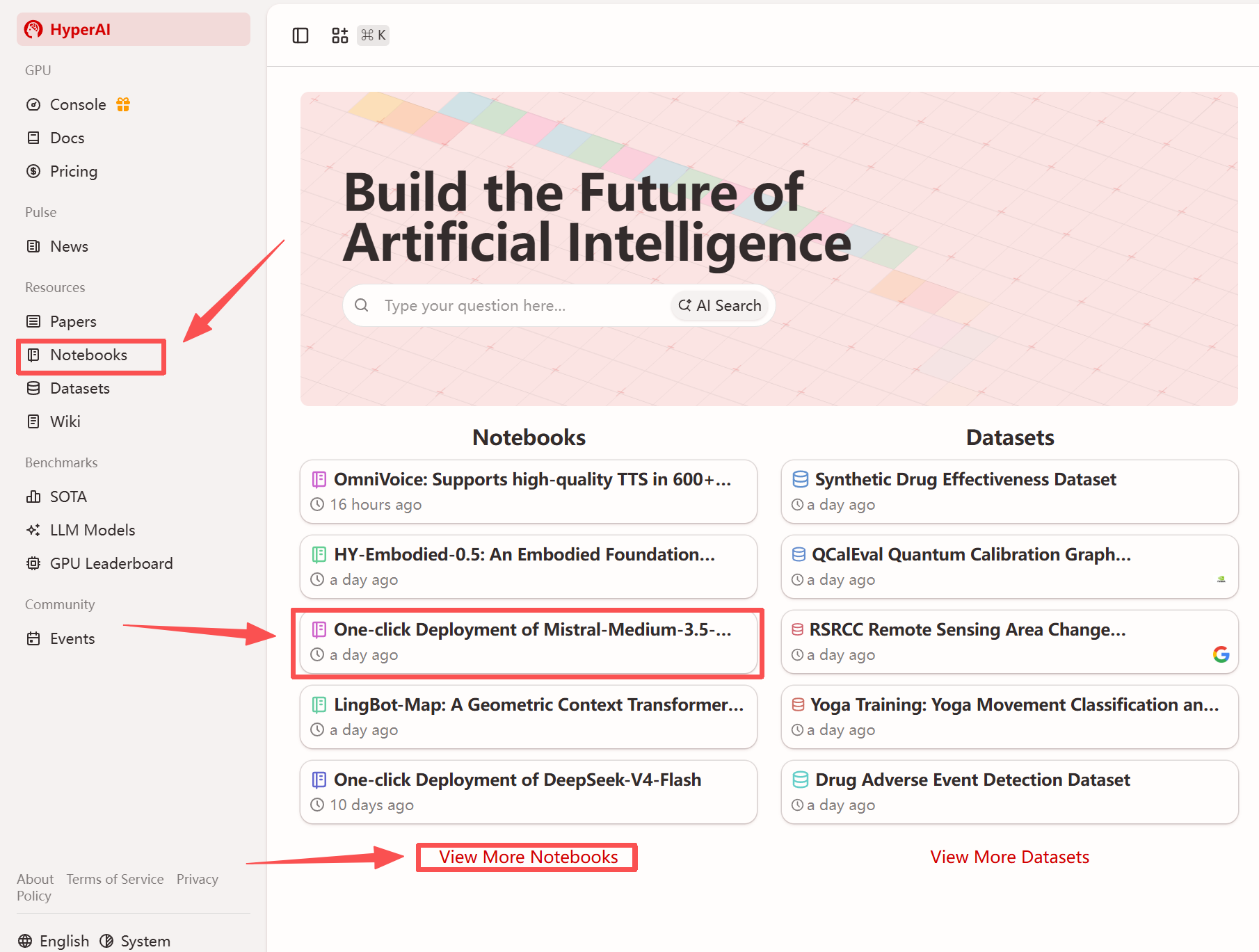
1. Nachdem Sie die Hyper.ai-Homepage aufgerufen haben, wählen Sie die Seite „Tutorials“ aus oder klicken Sie auf „Weitere Tutorials anzeigen“, wählen Sie „Ein-Klick-Bereitstellung von Mistral-Medium-3.5-128B“ aus und klicken Sie auf „Dieses Tutorial ausführen“.
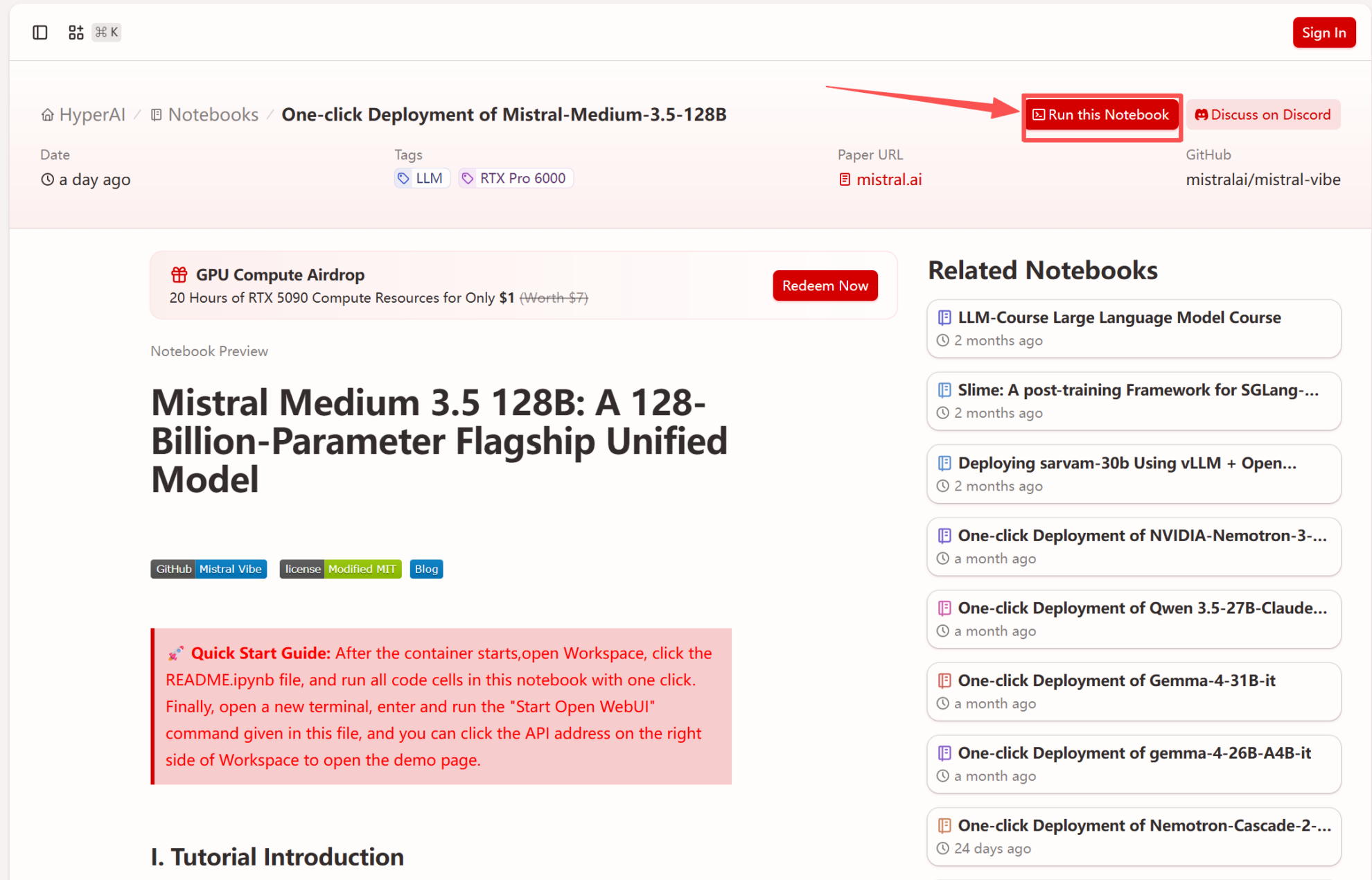
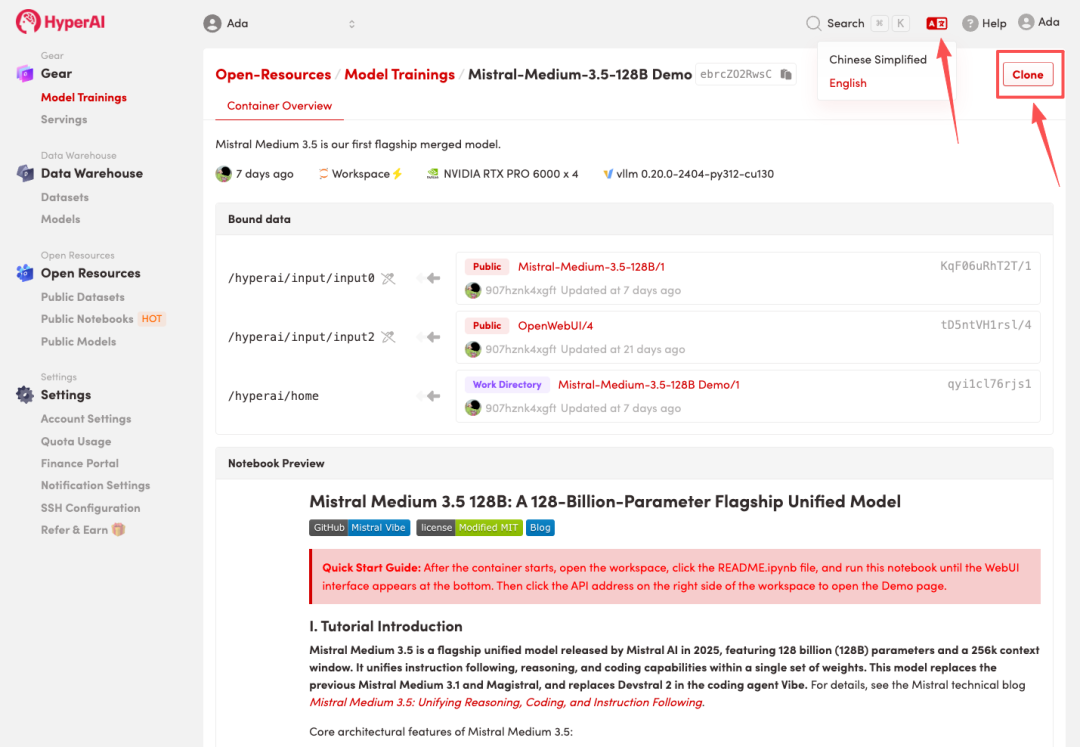
2. Nachdem die Seite weitergeleitet wurde, klicken Sie oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
Hinweis: Sie können die Sprache oben rechts auf der Seite ändern. Derzeit sind Chinesisch und Englisch verfügbar. Dieses Tutorial zeigt die Schritte auf Englisch.
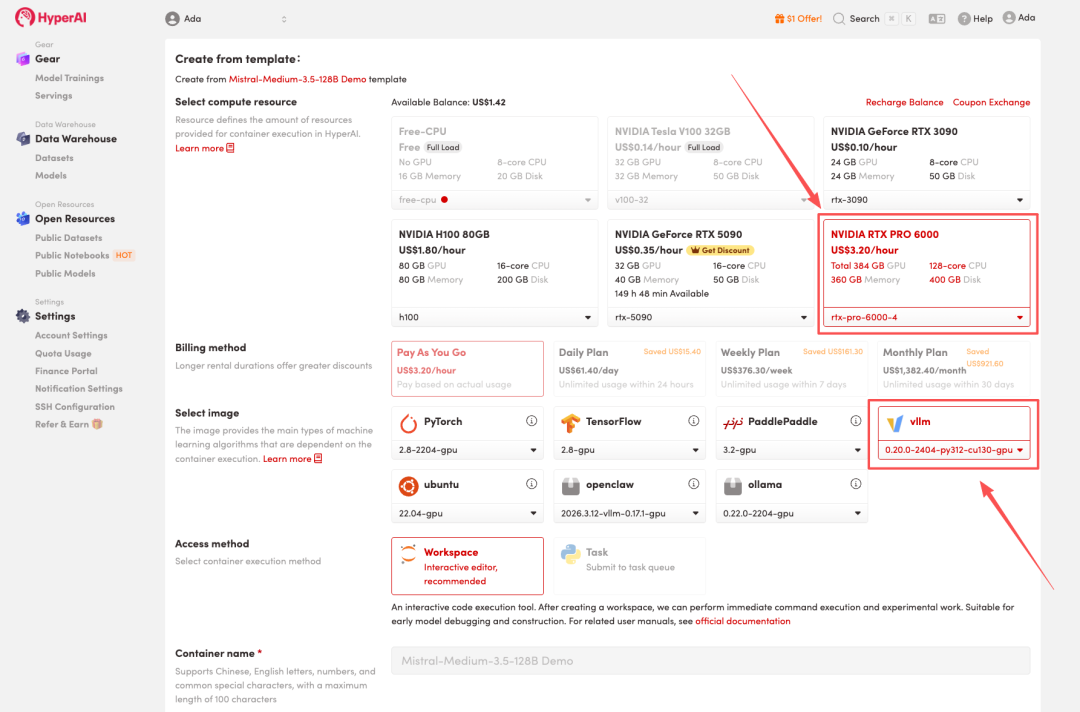
3. Wählen Sie die Images „NVIDIA RTX PRO 6000 -4“ und „vLLM“ aus und klicken Sie auf „Auftragsausführung fortsetzen“.
HyperAI bietet Neukunden einen Registrierungsbonus: Für nur $1 erhalten Sie 20 Stunden RTX 5090 Rechenleistung (ursprünglich $7), und die Ressourcen sind unbegrenzt gültig.
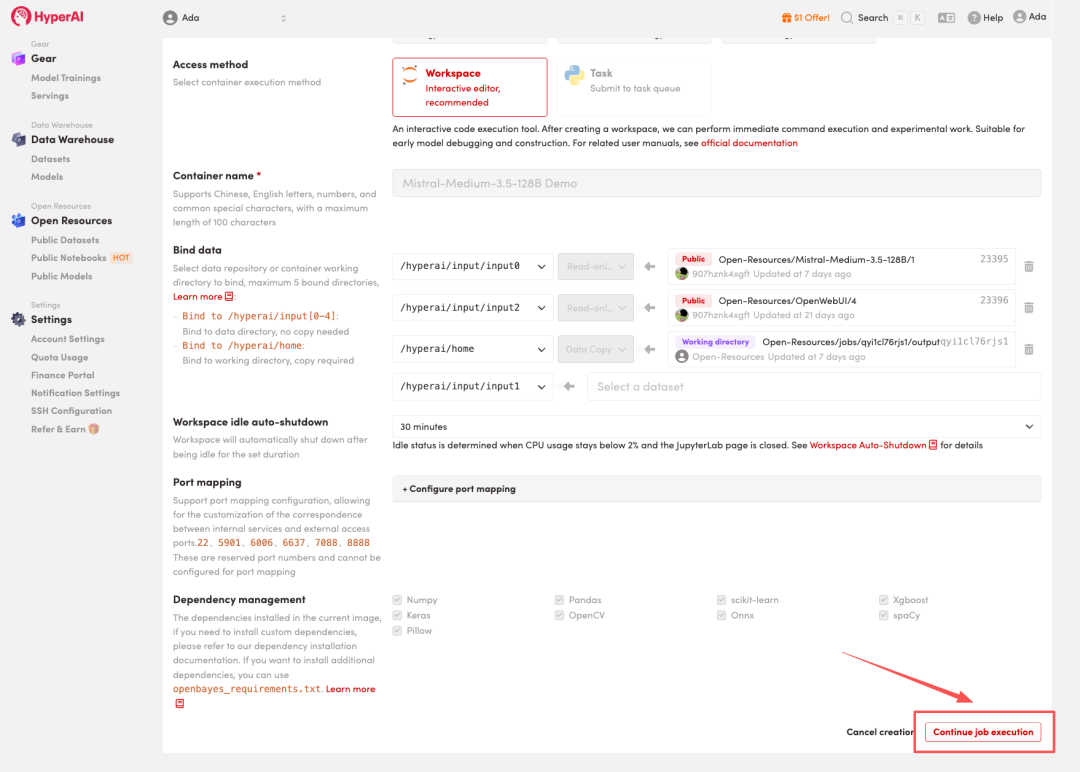
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Sobald sich der Status auf „Wird ausgeführt“ ändert, klicken Sie auf „Arbeitsbereich öffnen“, um den Jupyter-Arbeitsbereich zu betreten.
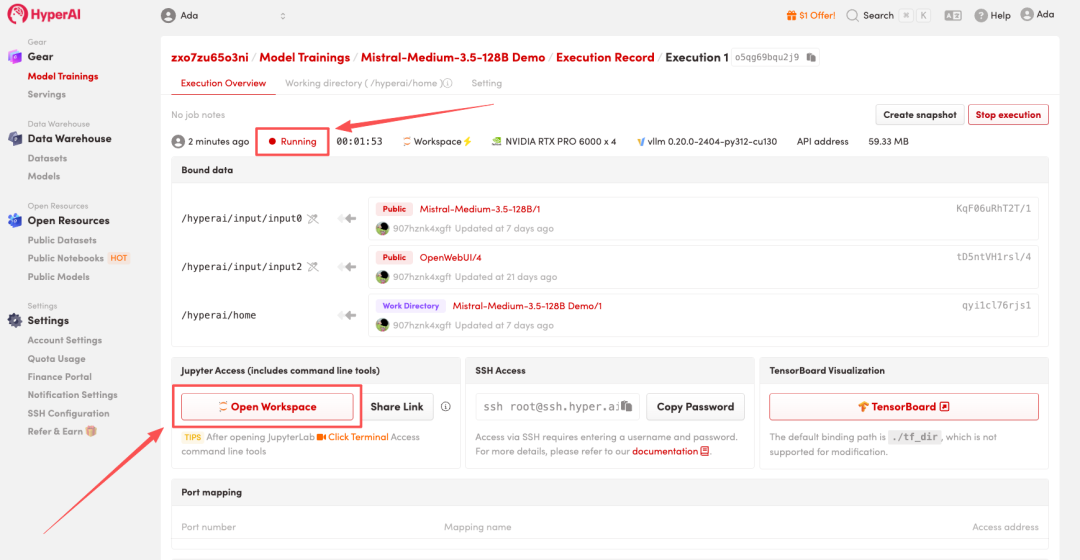
Effektanzeige
1. Nachdem die Seite weitergeleitet wurde, klicken Sie auf die README-Datei auf der linken Seite und anschließend oben auf Ausführen.
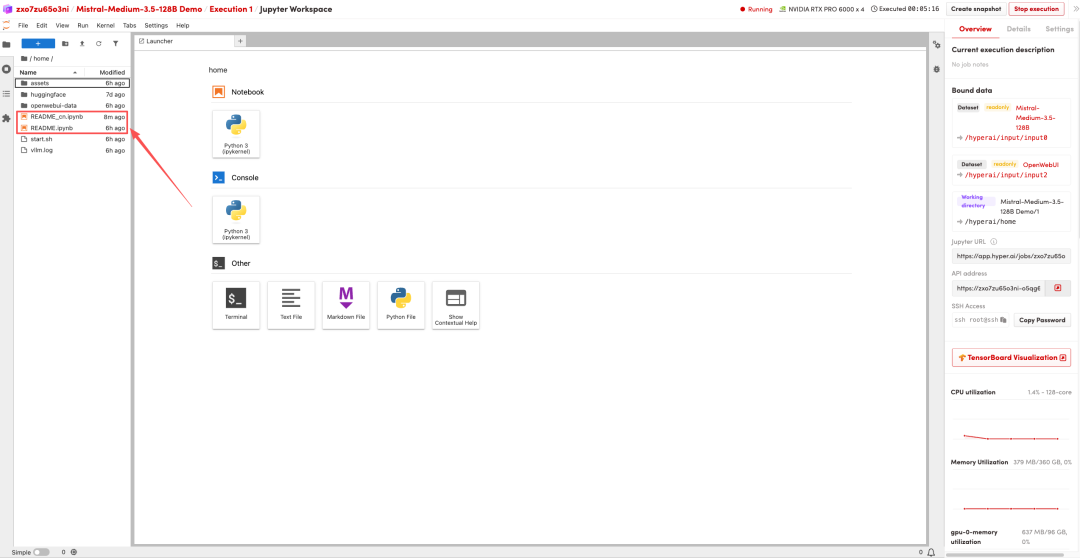
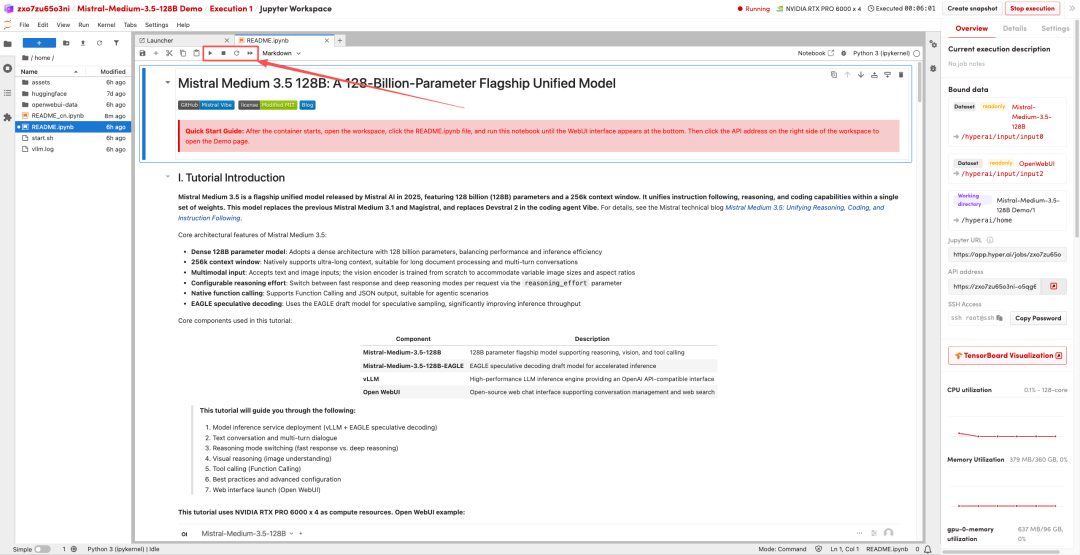
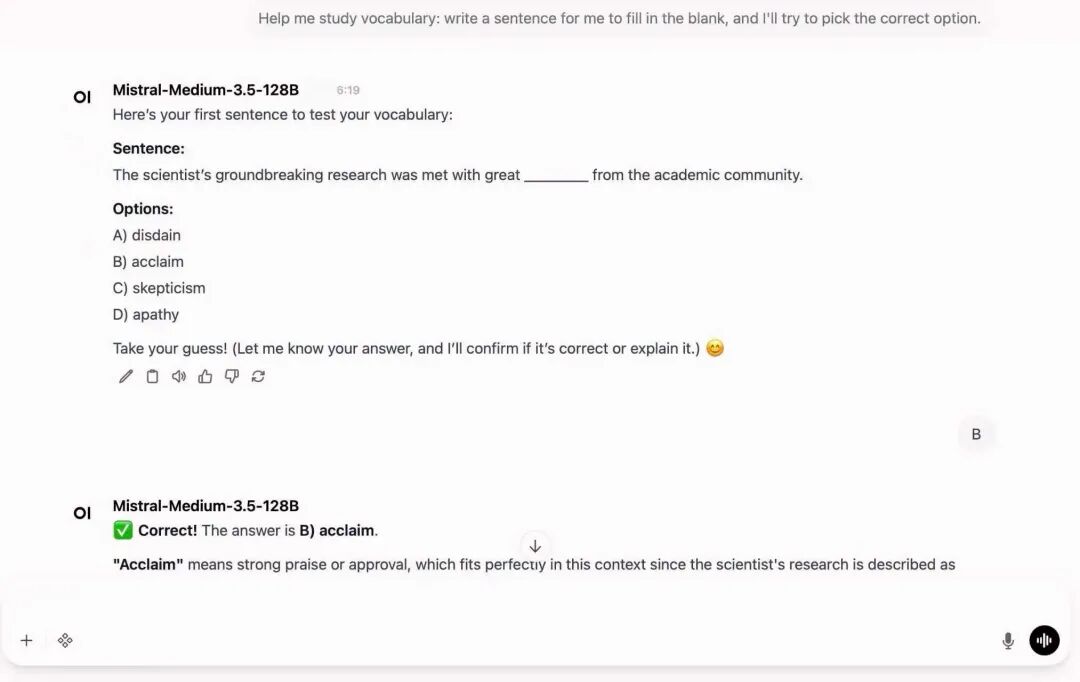
2. Sobald der Vorgang abgeschlossen ist, starten Sie Open WebUI gemäß den Anweisungen in der README-Datei. Der Startvorgang ist abgeschlossen, wenn Sie die ausgefüllten, quadratischen ASCII-Zeichen „OPENWEBUI“ sehen. Anschließend können Sie auf die API-Adresse rechts klicken, um zur Demoseite zu gelangen.