Command Palette
Search for a command to run...
NVIDIA Und Andere Haben Auf Basis Von Klimadaten Für 18.000 Jahre Die Methode Der Langzeitdestillation Entwickelt, Die Eine Langfristige Wettervorhersage Mit Nur Einem Einzigen Berechnungsschritt ermöglicht.

Die Genauigkeit und Vorwarnzeit von Wettervorhersagen haben direkten Einfluss auf Katastrophenschutz, landwirtschaftliche Produktion und die globale Ressourcenverteilung. Von kurzfristigen Warnungen bis hin zu saisonalen und sogar längerfristigen Klimaprognosen steigen die technologischen Herausforderungen mit jedem Fortschritt exponentiell an. Nach jahrelanger Entwicklung in der traditionellen numerischen Wettervorhersage hat die Künstliche Intelligenz (KI) diesem Bereich neue Dynamik verliehen. In den letzten Jahren haben KI-gestützte Wettervorhersagemodelle Durchbrüche bei mittelfristigen Vorhersagen erzielt und erreichen eine Leistungsfähigkeit, die mit fortschrittlichen traditionellen dynamischen Modellen vergleichbar ist oder diese sogar übertrifft.
Die meisten gängigen KI-Wettermodelle verwenden derzeit eine autoregressive Architektur. Diese arbeitet, indem sie iterativ historische Daten zu kurzfristigen atmosphärischen Schwankungen extrapoliert und daraus lernt, um die Bedingungen für die nächsten Stunden vorherzusagen. Dieser Modelltyp liefert gute Ergebnisse bei mittelfristigen Vorhersagen.Bei der Ausweitung auf langfristige Zeiträume wie den Übergang von sub-saisonalen zu saisonalen Zeiträumen (S2S) traten jedoch grundlegende Engpässe auf.
Langfristprognosen basieren auf Wahrscheinlichkeitsmethoden, während autoregressive Modelle nur durch wiederholte Iterationen Vorhersagen treffen können, was zu einer kontinuierlichen Fehlerakkumulation führt und die Kalibrierung erschwert. Der zentrale Widerspruch liegt darin:Ziel der Ausbildung ist es, kurzfristige Muster zu erlernen, während für langfristige Prognosen der Aufbau probabilistischer Modelle erforderlich ist, die die langsame Klimavariabilität charakterisieren können.
Um diese Einschränkung zu überwinden, begannen Forscher, neue Wege für die Einzelschrittvorhersage zu erkunden. Dabei traten jedoch neue Probleme auf: Beim Trainieren langfristiger Einzelschrittmodelle auf Basis vorhandener Reanalysedaten kann es aufgrund der geringen Datenmenge zu starkem Overfitting kommen, und die Zuverlässigkeit des Modells kann nicht gewährleistet werden.
In diesem ZusammenhangEin Forschungsteam von NVIDIA Research hat in Zusammenarbeit mit der University of Washington eine neue Methode zur Destillation über große Entfernungen entwickelt.Die Kernidee besteht darin, ein autoregressives Modell, das sich durch seine Fähigkeit zur realistischen Simulation atmosphärischer Variabilität auszeichnet, als „Lehrer“ zu nutzen, um durch kostengünstige und schnelle Simulation große Mengen synthetischer meteorologischer Daten zu generieren. Diese Daten dienen anschließend zum Trainieren eines probabilistischen „Schülermodells“. Das Schülermodell benötigt nur eine einzige Berechnung, um Langzeitprognosen zu erstellen, wodurch die Akkumulation von Iterationsfehlern vermieden und das komplexe Problem der Datenkalibrierung umgangen wird.
Dieser Ansatz weicht vom autoregressiven Modellierungsrahmen ab und komprimiert stattdessen großflächige Klimadaten in ein bedingtes generatives Modell. Dadurch werden die Einschränkungen begrenzter Trainingsdaten in früheren Studien überwunden. Die Forschung nutzte ein autoregressives gekoppeltes Modell, das ein Jahrhundert Klima stabil simulieren kann, als Lehrmodell und generierte Trainingsdaten, die den Umfang realer Aufzeichnungen weit übersteigen. Vorläufige Experimente zeigen, dass das auf diesem Modell basierende Schülermodell vergleichbare Ergebnisse wie das integrierte Vorhersagesystem des ECMWF in der S2S-Vorhersage liefert und sich seine Leistung mit zunehmendem Volumen synthetischer Daten kontinuierlich verbessert. Dies verspricht zuverlässigere und wirtschaftlichere Klimavorhersagen in der Zukunft.
Die zugehörigen Forschungsergebnisse mit dem Titel „Long-Range Distillation: Distilling 10,000 Years of Simulated Climate into Long Timestep AI Weather Models“ wurden auf arXiv veröffentlicht.
Forschungshighlights:
* Durchbrechen der zeitlichen Begrenzung realer Beobachtungsdaten, indem KI-gestützte meteorologische Modelle synthetische Klimadaten von mehr als 10.000 Jahren generieren, wodurch das Modell in die Lage versetzt wird, langsam veränderliche Klimamuster zu erlernen, die in tatsächlichen Beobachtungen nicht vollständig dargestellt wurden;
* Wir schlagen eine Methode zur Ferndestillation vor, die mit nur einem einzigen Berechnungsschritt ein langfristiges Wahrscheinlichkeitsprognosemodell ausgeben kann und so die Probleme der Fehlerakkumulation und Instabilität überwindet, die durch Hunderte von Iterationen im traditionellen autoregressiven Rahmen verursacht werden;
* Nach der Anpassung an reale Daten hat das Modell bei sub-saisonalen bis saisonalen Vorhersagen ein Niveau erreicht, das mit dem operationellen System des Europäischen Zentrums für mittelfristige Wettervorhersage vergleichbar ist.
Papieradresse:https://arxiv.org/abs/2512.22814 Folgen Sie unserem offiziellen WeChat-Konto und antworten Sie im Hintergrund mit „Ferndestillation“, um das vollständige PDF zu erhalten.
Weitere Artikel zu den Grenzen der KI: https://hyper.ai/papers
Datensätze: Ein Rahmenwerk für die Generierung, Klassifizierung und Bewertung synthetischer Klimadaten
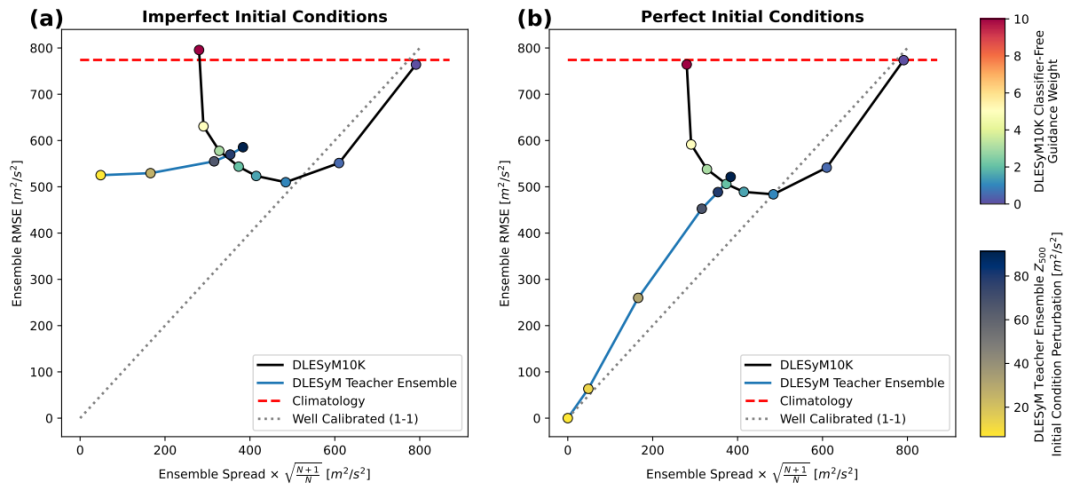
Zur Bewertung der zeitabhängigen integrierten Prognosefähigkeit des Ferndestillationsmodells wurde dieses in dieser Studie zunächst in kontrollierten idealen Modellversuchen validiert.Alle Auswertungsdaten stammen aus den Simulationsdaten, die vom autoregressiven Lehrermodell DLESyM (Deep Learning Earth System Model) gespeichert wurden.Diese Konfiguration wurde zudem nie während des Trainings des Destillationsmodells verwendet. Hauptzweck dieses Aufbaus war die Untersuchung der Leistungsfähigkeit des Langschritt-Destillationsmodells und des DLESyM-Lehrermodells bei der Vorhersage unbekannter simulierter Wetterbedingungen unter nicht vollständig festgelegten Anfangsbedingungen, um so die Objektivität der Bewertung zu gewährleisten.
Die Auswertung beschränkte sich nicht nur auf deterministische Metriken wie den Ensemble-Root-Mean-Square-Error (RMSE), sondern führte auch den Continuous Ranking Probability Score (CRPS) ein, ein probabilistisches Prognosebewertungsinstrument, um die Prognoseleistung umfassender zu messen. Die Forscher wählten drei Prognosemodelle mit unterschiedlichen Vorhersagemechanismen für die Tests aus:
* Mittelfristiger Zeitrahmen:
Für die 7-Tage-Tagesdurchschnittsprognose (Parameter N=28, M=4) wurden reservierte Daten vom 1. Januar 2017 bis zum 10. März 2019 (simuliertes Jahr) verwendet, wobei alle 2 Tage ein Startdatum ausgewählt wurde, was zu mehr als 400 Stichproben führte.
* S2S-Zeitrahmen:
Für die 4-Wochen-Wochenmittelprognose (Parameter N=112, M=28) wurden Daten vom 1. Januar 2017 bis zum 16. Mai 2021 (simuliertes Jahr) verwendet, wobei alle 4 Tage ein neues Startdatum gewählt wurde. Die Stichprobengröße überstieg ebenfalls 400.
* Saisonale Gültigkeit:
Für die 12-wöchige monatliche Durchschnittsprognose (Parameter N=336, M=112) wurden Daten vom 1. Januar 2017 bis zum 28. September 2025 (simuliertes Jahr) verwendet, wobei alle 8 Tage ein Startdatum ausgewählt wurde, was zu einer Stichprobengröße von etwa 400 führte.
Um Unabhängigkeit zu gewährleisten, teilten die Forscher die von DLESYM generierten synthetischen Klimasimulationsdaten über einen Zeitraum von etwa 15.000 Jahren anhand der Ensemblezugehörigkeit in einen Trainingsdatensatz (751 TP3T, ca. 11.000 Jahre) und einen Validierungsdatensatz (251 TP3T) auf und trainierten für jeden Vorhersagezeitraum unabhängige Destillationsmodelle. Die Generierung dieser synthetischen Daten erfolgte parallel: Zwischen dem 1. Januar 2008 und dem 31. Dezember 2016 wurden gleichmäßig 200 Starttermine ausgewählt, wobei jeder Starttermin einer 90-jährigen Simulation entsprach.Dies ergab Klimadaten, die sich über insgesamt 18.000 Jahre erstrecken.
Das übergeordnete Ziel dieser Forschung ist die Anwendung des trainierten Modells für langfristige Wettervorhersagen in der realen Welt. Es ist wichtig zu beachten, dass das durch den Langzeitbetrieb von DLESyM generierte „Modellklima“ vom realen Klima abweicht. Daher muss dieses Problem des „Domänentransfers“ bei der Übertragung des Modells auf reale Anwendungen als zentrales Anliegen behandelt werden.
Ferndestillation: Eine doppelte Innovation aus „Datendestillation“ und „probabilistischer Kalibrierung“
Die innovative Idee hinter Ferndestillationsverfahren liegt in...Es verwendet ein autoregressives Kurzzeitmodell, das über einen langen Zeitraum stabil laufen kann, als „Lehrer“, um ein „Schülermodell“ zu trainieren, das mit nur einem einzigen Berechnungsschritt Langzeitprognosen ausgeben kann.Dadurch wird das Problem der Fehlerakkumulation, das durch Hunderte von Iterationen im traditionellen autoregressiven Rahmen entsteht, grundsätzlich vermieden.
Konkret definieren die Forscher ein langfristiges Prognoseziel – den Durchschnittszustand über einen zukünftigen Zeitraum – anhand der langfristigen gleitenden Sequenz des Lehrermodells. Das Schülermodell lernt dann direkt die bedingte Wahrscheinlichkeitsverteilung vom Anfangszustand zu diesem langfristigen Ziel. Der Kernvorteil des Lehrermodells liegt in seiner Fähigkeit, effizient große Mengen synthetischer Daten zu generieren, die den Umfang der ursprünglichen Reanalysedaten weit übertreffen. Dadurch wird das Problem knapper Trainingsdaten für langfristige Prognosen gelöst.
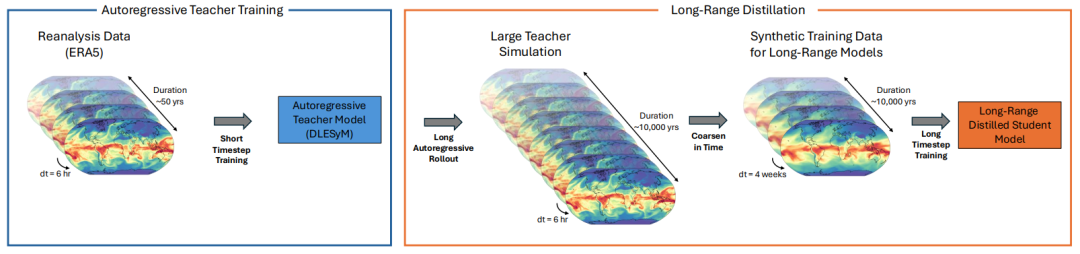
Um dieses Ziel zu erreichen,In dieser Studie wird das DLESyM-Modell als „Lehrer“ verwendet.Das Modell wird anhand von ERA5-Reanalysedaten initialisiert und prognostiziert wichtige Variablen wie Meeresoberflächentemperatur, Lufttemperatur und geopotentielle Höhe. Die Forscher entwickelten eine effiziente Datengenerierungsstrategie: 200 Startdaten wurden gleichmäßig zwischen 2008 und 2016 ausgewählt, und die Simulationen wurden parallel über einen Zeitraum von 90 Jahren durchgeführt. Dies ergab insgesamt 18.000 Jahre synthetischer Klimadaten. Dank leistungsstarker Rechenkapazitäten dauerte die Datengenerierung nur wenige Stunden und demonstrierte damit eindrucksvoll die Effizienzvorteile der KI-gestützten Klimasimulation. Nach der Qualitätsprüfung wurden etwa 15.000 Jahre valider Daten für das anschließende Training und die Validierung des Modells verwendet.
Das „Student“-Modell verwendet eine Architektur eines bedingten Diffusionsmodells und ist speziell für probabilistische Prognosen konzipiert.Ziel ist es, die komplexe Beziehung zwischen zukünftigen langfristigen Wetterbedingungen und Eingangsdaten (wie den durchschnittlichen Tageswerten der letzten vier Tage) zu modellieren. Die Modellarchitektur basiert auf einem verbesserten UNet-Netzwerk, das an das HEALPix-Grid angepasst wurde und die raumzeitlichen Abhängigkeiten des globalen Wetterfelds durch lernbare räumliche und periodische zeitliche Einbettungen effektiv erfasst. Während des Trainings verwendeten die Forscher eine spezielle Rauschplanungsstrategie, um sicherzustellen, dass das Modell Merkmale auf allen Skalen der Daten lernt.
Um die Unsicherheit von Wahrscheinlichkeitsvorhersagen präzise zu kalibrieren, führt diese Studie innovativ die „klassifikatorfreie Anleitung“ ein.Es ermöglicht die flexible Steuerung der Streuung des Vorhersageensembles durch Anpassung eines einfachen Gewichtungsparameters während der Modellinferenzphase.Dies ermöglicht ein optimales Gleichgewicht zwischen Prognosefehler und genauer Vorhersage und erleichtert somit die Erstellung gut kalibrierter Wahrscheinlichkeitsprognosen.
Um das Modell für reale Wettervorhersageaufgaben nutzbar zu machen, verfolgte diese Studie eine zweigleisige Strategie zur Bewältigung des Problems der „Domänenverschiebung“. Zunächst wurden Klimakorrekturen durchgeführt, um systematische Abweichungen zwischen simulierten Daten und realen Beobachtungen im mittleren Zustand zu beheben. Anschließend wurde das Modell mithilfe begrenzter ERA5-Reanalysedaten feinabgestimmt, wobei lediglich einige Schlüsselparameter im Netzwerk aktualisiert wurden. Dadurch konnte das Modell die aus umfangreichen synthetischen Daten gewonnenen Erkenntnisse beibehalten und sich gleichzeitig besser an die Eigenschaften der realen Atmosphäre anpassen. Abschließend wurde die Wettbewerbsfähigkeit des Modells in realen Szenarien durch einen Vergleich mit führenden operationellen Systemen wie dem Europäischen Zentrum für mittelfristige Wettervorhersage (ECMWF) evaluiert.
Bahnbrechende Innovationen in mehreren Dimensionen: skalierbare Daten, kalibrierbare Prognosen und Fähigkeiten, die mit erstklassigen Geschäftssystemen vergleichbar sind.
In dieser Studie wurden anhand einer Reihe von Experimenten die Leistungsfähigkeit und das Potenzial des Langstrecken-Destillationsmodells in vier Bereichen systematisch überprüft: der Einfluss des Trainingsdatenumfangs, die Kalibrierung der Vorhersageunsicherheit, die Vorhersagefähigkeiten für mehrere Zeitpunkte und der Vergleich mit operationellen Systemen.
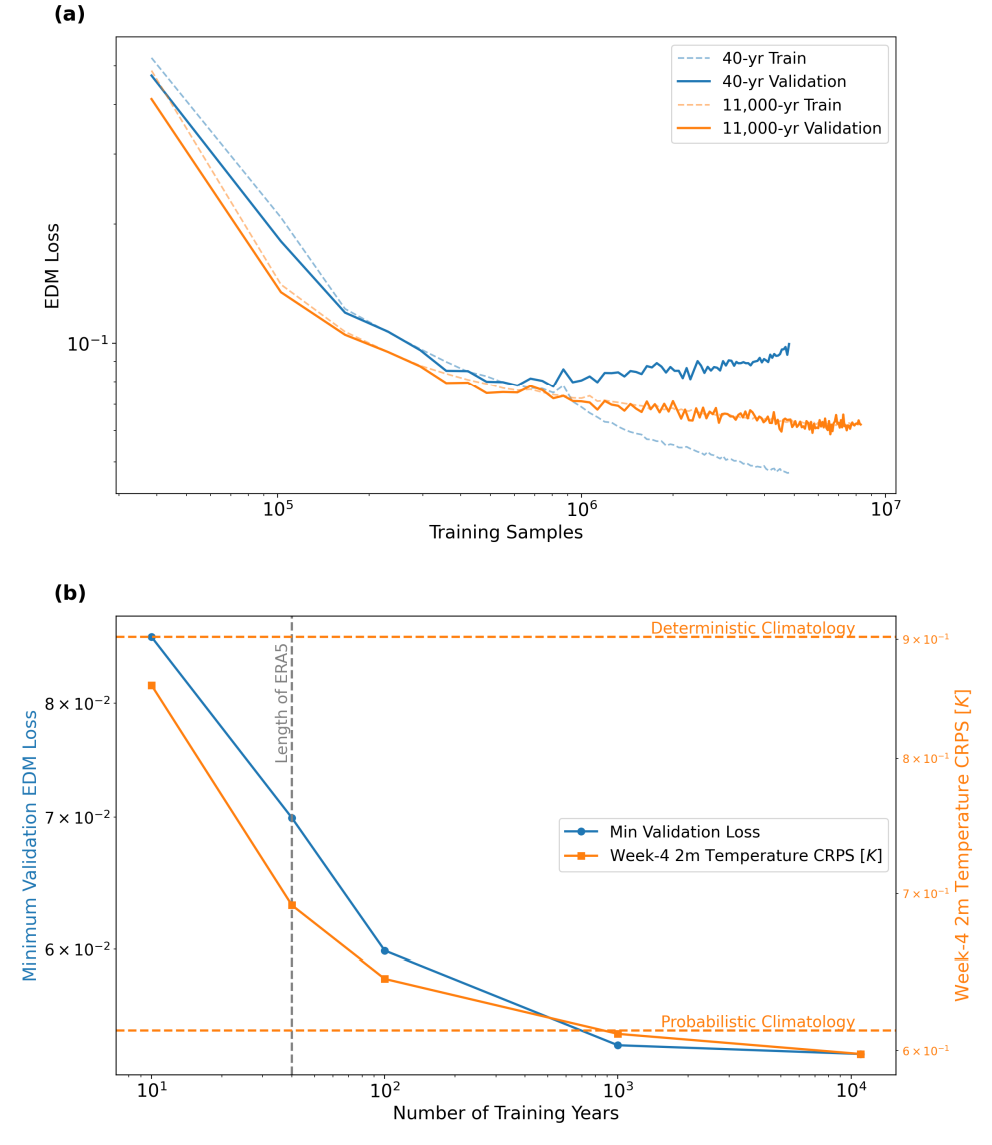
Zunächst bestätigte diese Studie die zentrale Hypothese: Eine Erhöhung der Menge an synthetischen Trainingsdaten kann die Vorhersagefähigkeit des Modells signifikant verbessern. Wie die Abbildung unten zeigt, überanpasste das Modell, das nur mit simulierten Daten aus 40 Jahren trainiert wurde, schnell, während das Modell, das mit synthetischen Daten aus etwa 11.000 Jahren trainiert wurde (DLESyM10K), eine stabile Lernkurve aufwies. Noch wichtiger ist jedoch, dass…Die Zunahme des Datenvolumens führt direkt zu einer Verbesserung der Prognosefähigkeiten:In der 4-Wochen-Temperaturvorhersage sank der CRPS-Wert um 14%. Dies beweist erstmals, dass die Verwendung autoregressiver Modelle zur Generierung umfangreicher synthetischer Daten effektiv robustere Langzeitvorhersagemodelle erstellen kann.
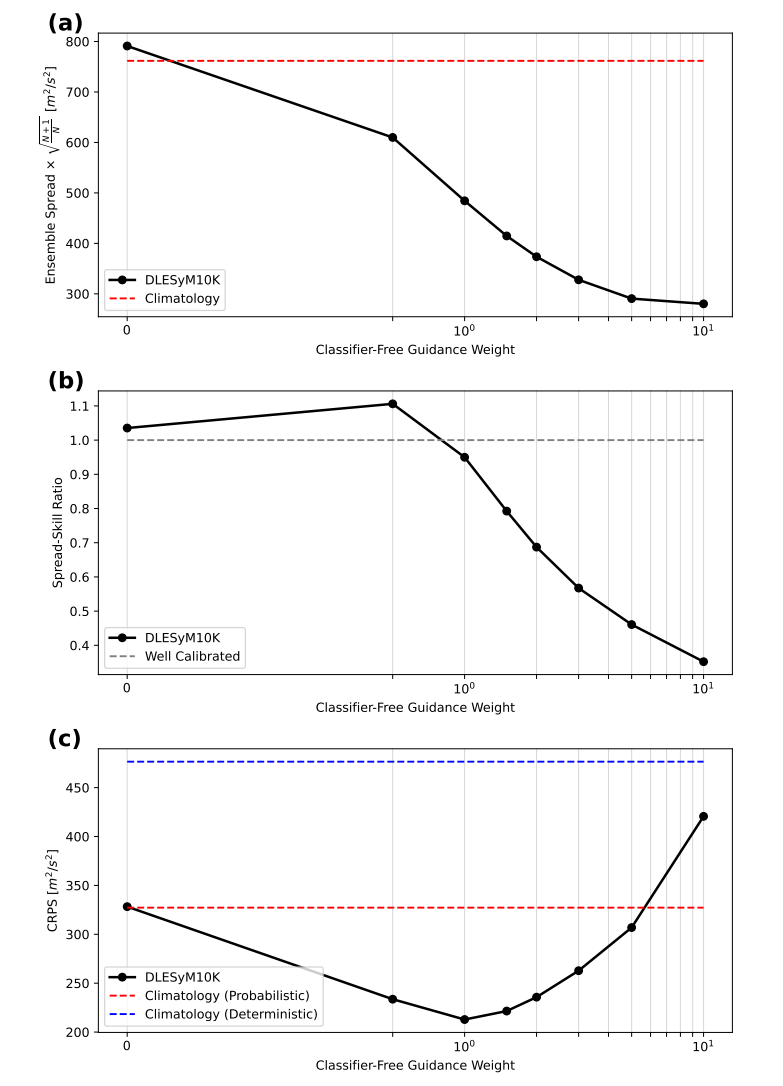
Diese Studie verwendet eine „klassifikatorfreie Guidance“-Technik zur Kalibrierung der Streuung probabilistischer Vorhersagen. Durch Anpassen der Guidance-Stärke lässt sich die Streuung des Vorhersageensembles steuern und ein optimales Gleichgewicht mit den Vorhersagefehlern erzielen. Experimente zeigen, dass…Wenn die Führungsstärke auf 1 eingestellt ist, kann das Modell automatisch eine gute Kalibrierung erreichen;Falls Anpassungen erforderlich sind, kann der Parameter während der Inferenzphase einfach verändert werden. Dies bietet eine effiziente und flexible Kalibrierungsmethode für probabilistische Prognosen.
Das Modell zeigt eine robuste Leistungsfähigkeit bei mittelfristigen, sub-saisonalen bis saisonalen (S2S) und saisonalen Prognosen.Bei mittelfristigen Vorhersagen zeigt das Modell eine hohe Robustheit gegenüber Anfangsfehlern, und seine probabilistischen Modellierungseigenschaften tragen dazu bei, Unsicherheiten in den Anfangsbedingungen zu mindern. Bei anspruchsvolleren S2S- und saisonalen Vorhersagen übertrifft DLESyM10K klimatologische Vergleichsmodelle deutlich, insbesondere in gut vorhersagbaren Regionen wie den Tropen und den Ozeanen.Es erreicht durch eine einzige Berechnungsschrittung ein Leistungsniveau, das mit dem eines autoregressiven Lehrermodells mit Hunderten von Iterationen vergleichbar ist.Dies beweist die Effizienz des Systems.
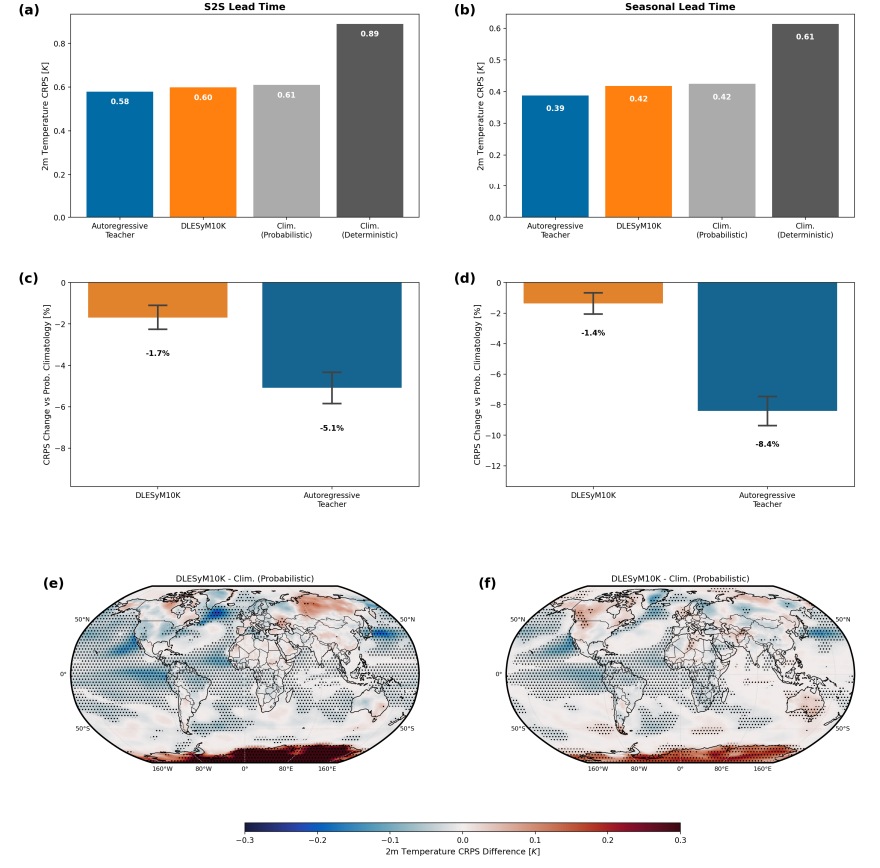
Bei der Übertragung des Modells auf reale Wettervorhersagen wurden durch Feinabstimmung und Bias-Korrektur die Diskrepanzen zwischen „Modellklima“ und tatsächlichem Klima behoben. Ein Vergleich mit dem operationellen System des Europäischen Zentrums für mittelfristige Wettervorhersage (ECMWF) zeigt:Nach der Feinabstimmung ist die 4-Wochen-Temperaturvorhersagegenauigkeit des DLESyM10K sehr nahe an der des ECMWF-Systems, und beide sind deutlich besser als der klimatologische Referenzwert.Die regionale Analyse zeigt, dass jedes Modell in unterschiedlichen geografischen Regionen seine Stärken hat; beispielsweise schneidet DLESyM10K in Teilen Amerikas und Zentralafrikas besser ab. Dies verdeutlicht das Potenzial des KI-Modells, mit fortschrittlichen Geschäftssystemen zu konkurrieren, und unterstreicht gleichzeitig seinen differenzierten Wert.
Zusammenfassend lässt sich sagen, dass die Methode der Langzeitdestillation durch eine Kombination aus Datenskalierung und einstufiger probabilistischer Modellierung ein bedingtes Diffusionsmodell trainiert, das langfristige probabilistische Prognosen in einem einzigen Schritt ausgeben kann, und durch die Einbeziehung klassifikatorfreier Steuerungstechniken eine flexible Unsicherheitskalibrierung erreicht. Experimente zeigen, dass…Mit dieser Methode wurde eine Leistung erzielt, die mit dem operationellen System des Europäischen Zentrums für mittelfristige Wettervorhersage (ECMWF) bei sub-saisonalen bis saisonalen Vorhersagen vergleichbar ist.Dieses Paradigma bietet nicht nur einen neuen Ansatz für die langfristige Wettervorhersage, sondern legt auch den Grundstein für den Aufbau eines allgemeinen generativen Modells, das der Erforschung des Klimas dient.
Die globale Zusammenarbeit zwischen Industrie, Hochschulen und Forschungseinrichtungen beschleunigt den Wandel der meteorologischen Technologie.
Der Einsatz von KI zur Generierung synthetischer Daten, um Datenengpässe in der Langzeitprognose zu beheben, entwickelt sich zu einem wichtigen Forschungsfeld für Wissenschaft und Industrie, um gemeinsam Innovationen in der Wettervorhersage voranzutreiben. Eine Reihe zukunftsweisender Forschungs- und Entwicklungsmethoden hat sich etabliert, die die Langzeitwettervorhersage kontinuierlich von der theoretischen Grundlagenforschung bis zur operativen Anwendung vorantreiben.
In der Wissenschaft gewinnt die interdisziplinäre Zusammenarbeit zunehmend an Bedeutung für die Bewältigung zentraler technologischer Herausforderungen. Zum Beispiel:Die „KI-Klimainitiative (AICE)“ der Universität ChicagoDiese Organisation, die Experten aus Klimawissenschaft, Informatik und Statistik vereint, hat sich zum Ziel gesetzt, den Rechenaufwand für Klimavorhersagen deutlich zu reduzieren. Ihre Technologie ermöglicht die Erstellung hochpräziser Vorhersagen mit herkömmlichen Laptops und soll dazu beitragen, die Unterschiede in den Wettervorhersagefähigkeiten verschiedener Regionen zu verringern.
Die Universität Cambridge hat in Zusammenarbeit mit dem Turing Institute, dem Europäischen Zentrum für mittelfristige Wettervorhersage und anderen Institutionen Aardvark Weather entwickelt, ein durchgängiges datengetriebenes Vorhersagesystem.Dieses System kann verschiedene Beobachtungsdaten integrieren und gleichzeitig globale Gittervorhersagen sowie lokale Stationsvorhersagen ausgeben. Seine Leistungsfähigkeit ist mit optimierten operationellen numerischen Modellen bei Vorhersagezeiträumen von 10 Tagen vergleichbar. Der durchgängige Modellierungsansatz entspricht weitgehend dem ursprünglichen Ziel, den Vorhersageprozess durch Fernfeldanalyse zu vereinfachen und bietet ein technisches Modell zur Verbesserung der Genauigkeit langfristiger Vorhersagen.
* Zum Anzeigen klicken Erdferkelwetter Detaillierte Analyse:Nature, die Universität Cambridge und andere haben das erste durchgängig datengesteuerte Wettervorhersagesystem veröffentlicht, das die Vorhersagegeschwindigkeit um ein Dutzend Mal erhöht
* Titel des Papers: Durchgängige datengestützte Wettervorhersage
* Papieradresse:
https://www.nature.com/articles/s41586-025-08897-0
In der Industrie konzentrieren sich innovative Praktiken stärker auf die technische Umsetzung und szenariobasierte Anwendung von Technologien. Technologieunternehmen erweitern kontinuierlich die technologischen Grenzen der KI-Meteorologie durch intensive Zusammenarbeit mit Industrie, Hochschulen und Forschungseinrichtungen sowie durch unabhängige Forschung und Entwicklung. Zum Beispiel:Microsoft, Google DeepMind und andere Organisationen waren maßgeblich an der Entwicklung des Aardvark-Wettersystems beteiligt.Die Stärken von Google DeepMind in der Verarbeitung großer Datenmengen und der Architektur von Deep Learning lassen sich in Verbesserungen der Effizienz und Genauigkeit meteorologischer Modelle umsetzen. Darüber hinaus liefert die Expertise von Google DeepMind in generativen Modellen und der Kalibrierung probabilistischer Vorhersagen wichtige Erkenntnisse zur Lösung von Problemen wie der Ensemble-Dispersionskontrolle bei der Fernfeld-Destillation.
Gleichzeitig fördern Unternehmen aktiv den Einsatz von KI-gestützter Wettertechnologie in spezifischen Anwendungsbereichen. Beispielsweise integrieren sie in Zusammenarbeit mit Parkverwaltungen und Rettungsdiensten präzise Langzeitprognosen in intelligente Katastrophenschutzsysteme. Durch die Simulation des gesamten Katastrophenverlaufs bieten sie maßgeschneiderte Prognosedienste für Bereiche wie Parksicherheit, Wassermanagement und Landwirtschaft an und stellen so sicher, dass die Langzeitwettervorhersagen den Endnutzern tatsächlich zugutekommen.
Diese Untersuchungen aus Wissenschaft und Industrie haben nicht nur die Machbarkeit technischer Ansätze wie Datendestillation und einstufige Modellierung bestätigt, sondern auch nach und nach einen positiven Kreislauf geschaffen, in dem „akademische Durchbrüche die Richtung vorgeben und technische Innovationen die Umsetzung vorantreiben“, wodurch gemeinsam die kontinuierliche Weiterentwicklung der globalen KI-Wettervorhersage hin zu einer genaueren, effizienteren und umfassenderen Richtung gefördert wird.
Referenzlinks:
1.https://climate.uchicago.edu/entities/aice-ai-for-climate/








