Command Palette
Search for a command to run...
TRELLIS.2: Nutzt Die O-Voxel-Technologie Zur Effizienten Generierung Komplexer 3D-Geometrien Und -Materialien; Datensatz Zur Vorhersage Von Patientenabbrüchen: Hilft Bei Der Identifizierung Von Patienten Mit Abbruchrisiko.

Die Erstellung nutzbarer 3D-Modelle aus Bildern ist derzeit noch zeitaufwändig und arbeitsintensiv, da traditionelle Verfahren stark auf die manuelle Arbeit professioneller Modellierer angewiesen sind. Selbst mit KI-UnterstützungBei komplexen Formen, transparenten Materialien oder offenen Oberflächen liefern die Modelle oft schlechte Ergebnisse oder anormale Strukturen, und es ist schwierig, fertige Produkte mit realistischen Materialien zu erzeugen, die direkt in Spielen und im E-Commerce eingesetzt werden können.
Vor diesem Hintergrund veröffentlichte das Microsoft-Team im Dezember 2025 TRELLIS.2, ein Open-Source-Projekt zur Generierung hochwertiger 3D-Assets und zur Durchführung von Texturierungsaufgaben aus einzelnen Bildern.Das Projekt bietet einen durchgängigen Prozess von den Eingangsbildern bis hin zu 3D-Formen und Materialien und beinhaltet eine interaktive Webdemo für einen schnellen Einblick und den Export von Assets. TRELLIS.2 konzentriert sich auf die Verbesserung geometrischer Details und Texturkonsistenz, unterstützt mehrere Auflösungen und kaskadierte Inferenzkonfigurationen und gleicht Geschwindigkeit und Qualität durch steuerbare Inferenzparameter aus, wodurch es sich für Szenarien wie die 3D-Inhaltsproduktion, schnelles Prototyping und kreative Erkundung eignet.
Auf der HyperAI-Website findet ihr jetzt die „TRELLIS.2 3D Generation Demo“ – schaut doch mal vorbei und probiert sie aus!
Online-Nutzung:https://go.hyper.ai/drI7I
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 19. bis 23. Januar:
* Hochwertige öffentliche Datensätze: 5
* Eine Auswahl hochwertiger Tutorials: 9
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefrist im Januar: 3
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Patientensegmentierungsdatensatz
Die Patientensegmentierung ist ein Datensatz zur Patientenklassifizierung für die Bereiche Gesundheitsanalyse und Marketing. Ziel ist es, Patienten anhand ihrer demografischen Daten, ihres Gesundheitszustands, ihrer Versicherungsart und ihres Inanspruchnahmeverhaltens im Gesundheitswesen in sinnvolle Gruppen zu segmentieren, um die Effektivität personalisierter Versorgung und gezielter Marketingmaßnahmen zu verbessern.
Direkte Verwendung:https://go.hyper.ai/Wp8LS
2. Datensatz zur Sturzerkennung bei Videoüberwachungsvorfällen
CCTV Incident ist ein offener, synthetischer Datensatz, der speziell für Sturzerkennung, Haltungsschätzung und Unfallüberwachung in der Computer Vision entwickelt wurde. Er analysiert Aufnahmen aus der Vogelperspektive von Überwachungskameras und ermöglicht es Modellen, menschliche Körperhaltungen zu verstehen und präzise zwischen stehenden und gestürzten Personen zu unterscheiden.
Direkte Verwendung:https://go.hyper.ai/q60Dm

3. Datensatz zur Vorhersage von Patientenabwanderung
Der Datensatz zur Vorhersage von Patientenabwanderung ist ein kategorischer Datensatz für den Gesundheitsbereich mit 2.000 Patientendatensätzen, der dazu beitragen soll, Patienten mit Abwanderungsrisiko zu identifizieren, damit im Voraus Maßnahmen zur Patientenbindung ergriffen werden können.
Direkte Verwendung:https://go.hyper.ai/QAeYw
4. RealTimeFaceSwap-10k Video Call Spoofing Dataset
Der RealTimeFaceSwap-10k-Datensatz zur Erkennung von Deepfake-Videos in Videokonferenzen dient der Erkennung solcher Videos. Er umfasst verschiedene Anwendungsszenarien und Datentypen und bietet eine solide Datengrundlage für die Erkennung von Video-Spoofing.
Direkte Verwendung:https://go.hyper.ai/SGZRO
5. TransPhy3D Transparent Reflection Synthesis Video Dataset
TransPhy3D ist ein synthetischer Videodatensatz, der von der Beijing Academy of Artificial Intelligence in Zusammenarbeit mit der University of Southern California, der Tsinghua-Universität und weiteren Institutionen entwickelt wurde und sich auf transparente und reflektierende Szenen konzentriert. Der Datensatz umfasst 11.000 Sequenzen, die mit Blender/Cycles gerendert wurden und hochwertige RGB-Bilder sowie physikalisch basierte Tiefen- und Normalenvektoren liefern.
Direkte Verwendung:https://go.hyper.ai/5ExjE
Ausgewählte öffentliche Tutorials
1.vLLM+WebUI öffnen Nemotron-3 Nano bereitstellen
Nemotron-3-Nano-30B-A3B-BF16 ist ein von NVIDIA von Grund auf trainiertes, umfangreiches Sprachmodell (LLM), das als einheitliches Modell für Aufgaben mit und ohne logisches Denken konzipiert wurde. Es eignet sich für Entwickler von KI-Agentensystemen, Chatbots, RAG-Systemen und anderen KI-Anwendungen.
Online ausführen:https://go.hyper.ai/VUuDA
2. MedGemma 1.5 Multimodales KI-Medizinmodell
MedGemma 1.5 ist ein Modell, das sich durch seine hervorragenden Leistungen bei multimodalen medizinischen Aufgaben auszeichnet. Es demonstriert herausragende Fähigkeiten in der Bildklassifizierung, der visuellen Beantwortung von Fragen und dem medizinischen Wissensschluss, wodurch es sich für verschiedene klinische Szenarien eignet und die medizinische Forschung und Praxis effektiv unterstützt. Dieses Modell basiert auf dem SigLIP-Bildencoder und einem leistungsstarken Sprachmodul und wurde anhand diverser Datensätze, darunter medizinische Bilder, Texte und Laborberichte, vortrainiert. Dies ermöglicht die effiziente Verarbeitung von Aufgaben wie der Analyse hochdimensionaler medizinischer Bilder, pathologischer Ganzschnittbilder, longitudinaler Bildanalyse, anatomischer Lokalisierung, dem Verständnis medizinischer Dokumente und der Auswertung elektronischer Patientenakten.
Online ausführen:https://go.hyper.ai/dZRn9
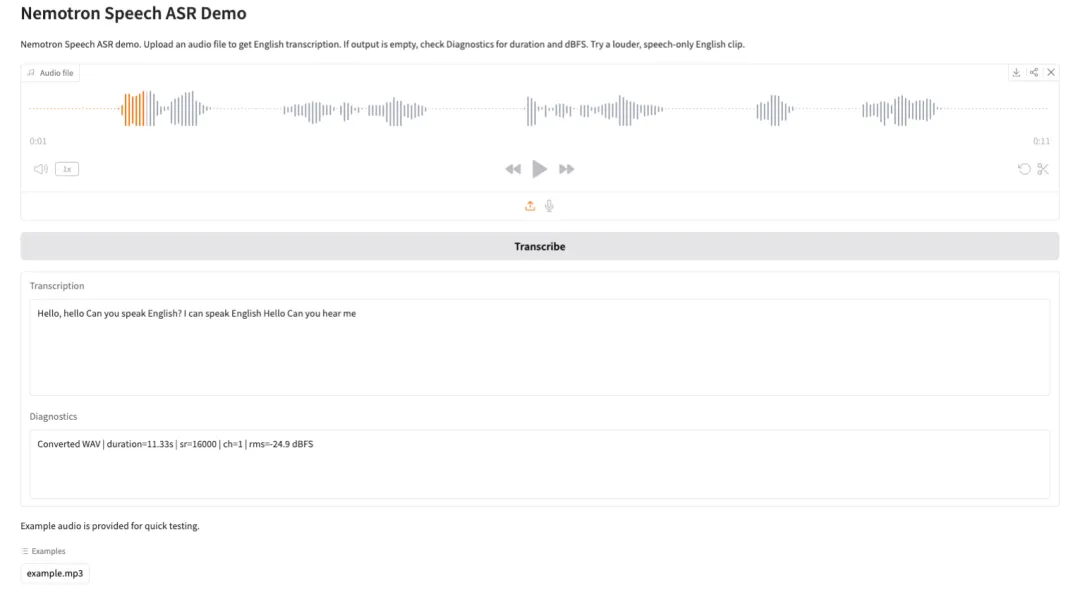
3. Nemotron-Speech-Streaming-ASR: Demo zur automatischen Spracherkennung
Nemotron Speech Streaming ASR ist ein Streaming-basiertes, automatisches Spracherkennungsmodell, das vom Nemotron Speech-Team bei NVIDIA entwickelt wurde. Es wurde für latenzarme Echtzeit-Spracherkennungsszenarien konzipiert und zeichnet sich zudem durch hohe Batch-Verarbeitungsraten aus. Dadurch eignet es sich für Anwendungen wie Sprachassistenten, Echtzeit-Untertitelung, Konferenztranskriptionen und dialogbasierte KI. Das Modell nutzt einen cache-fähigen FastConformer-Encoder und eine RNN-T-Decoder-Architektur. Dies ermöglicht die effiziente Verarbeitung kontinuierlicher Audiostreams bei gleichzeitig deutlich reduzierter End-to-End-Latenz und gleichbleibender Erkennungsgenauigkeit.
Online ausführen:https://go.hyper.ai/SDEBI
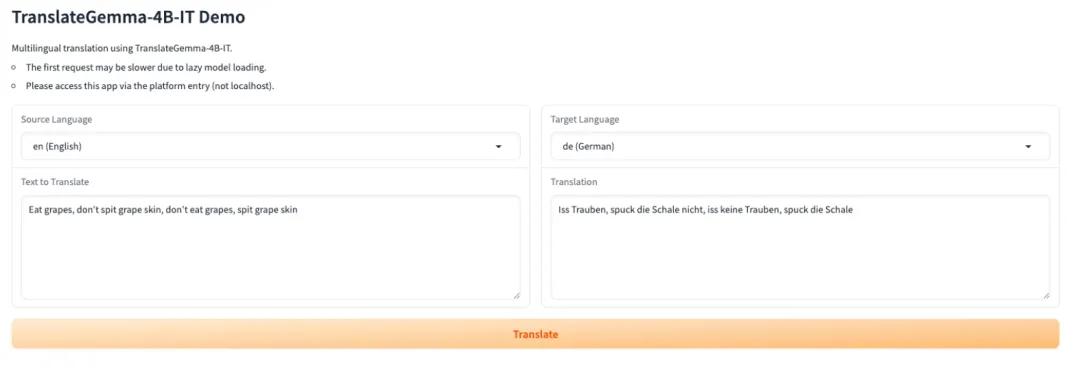
4. TranslateGemma-4B-IT: Eine Reihe von Open-Source-Übersetzungsmodellen von Google.
TranslateGemma ist eine schlanke Open-Source-Übersetzungsmodellfamilie des Google Translate-Teams. Sie basiert auf der Gemma-3-Modellfamilie und ist speziell für die mehrsprachige Textübersetzung und den Einsatz in realen Umgebungen konzipiert. Die Modellfamilie bietet stabile und nutzbare Übersetzungsfunktionen mit einem kompakten Parameterbereich und eignet sich daher ideal für das Laden und die Inferenz in Umgebungen mit begrenztem GPU-Speicher oder bei Bedarf an schneller Bereitstellung.
Online ausführen:https://go.hyper.ai/FRy35
5. GLM-Image: Ein hochpräzises Bildgenerierungsmodell mit genauer Semantik
GLM-Image ist ein Open-Source-Bildgenerierungsmodell von Zhipu AI, das autoregressive Dekodierung und Diffusionsdekodierung integriert. Es unterstützt sowohl die Text-zu-Bild- als auch die Bild-zu-Bild-Generierung und basiert auf einer einheitlichen visuellen Sprachrepräsentation. Dadurch kann das Modell sowohl Texteingaben als auch Bilder verstehen und mithilfe eines Diffusions-Transformer-basierten Netzwerks eine präzise Bildgenerierung durchführen.
Online ausführen:https://go.hyper.ai/2bcfV

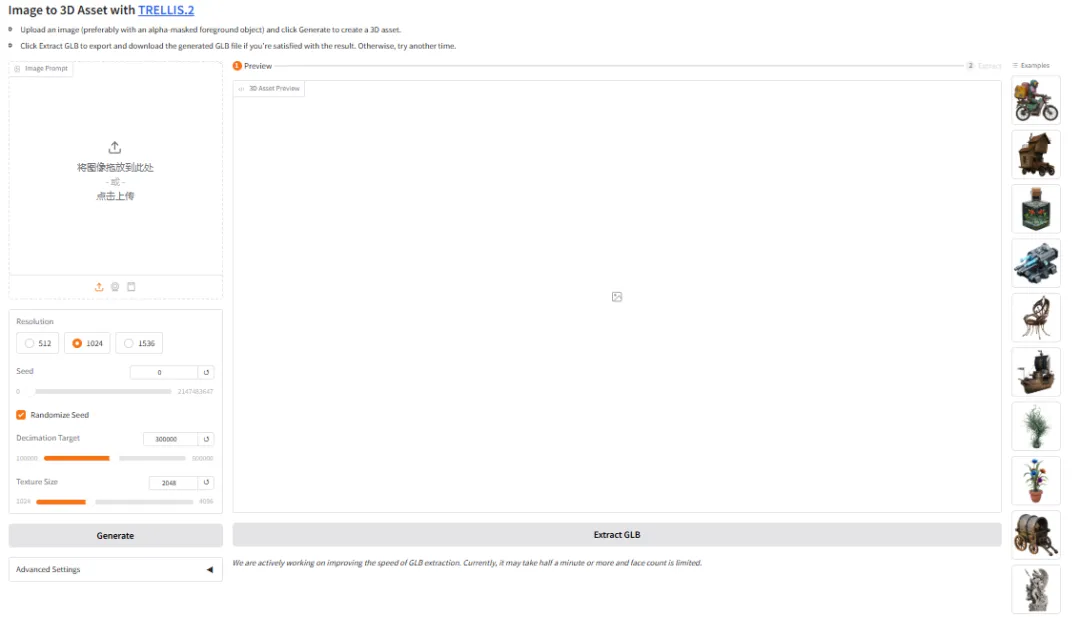
6. TRELLIS.2 3D-Demo-Generierung
TRELLIS.2 ist ein von Microsoft veröffentlichtes Open-Source-Projekt, ein umfangreiches Modell mit 4 Milliarden Parametern, das darauf abzielt, vollständig texturierte, sofort einsatzbereite 3D-Objekte direkt aus einem einzigen Bild zu generieren. Dieses Modell vereint hochwertige Geometrie- und Materialgenerierung und ermöglicht so eine präzise Geometrierekonstruktion und die Synthese volldimensionaler PBR-Materialien in einem einzigen Workflow.
Online ausführen:https://go.hyper.ai/drI7I
7.vLLM+Öffnen Sie die WebUI-BereitstellungsfunktionGemma-270m-it
FunctionGemma-270m-it ist ein schlankes, speziell für Funktionsaufrufe entwickeltes Modell von Google DeepMind mit 270 Millionen Parametern. Es basiert auf der Gemma 3 270M-Architektur und wurde mit denselben Forschungsmethoden wie die Gemini-Serie trainiert. Das Modell wurde speziell für Funktionsaufrufszenarien entwickelt und nutzt 6 TB Trainingsdaten bis August 2024, die öffentliche Tool-Definitionen und Interaktionsdaten zur Tool-Nutzung umfassen. FunctionGemma unterstützt eine maximale Kontextlänge von 32 KB und wurde strengen Inhaltsfiltern sowie einem verantwortungsvollen KI-Entwicklungsprozess unterzogen.
Online ausführen:https://go.hyper.ai/pdN7q

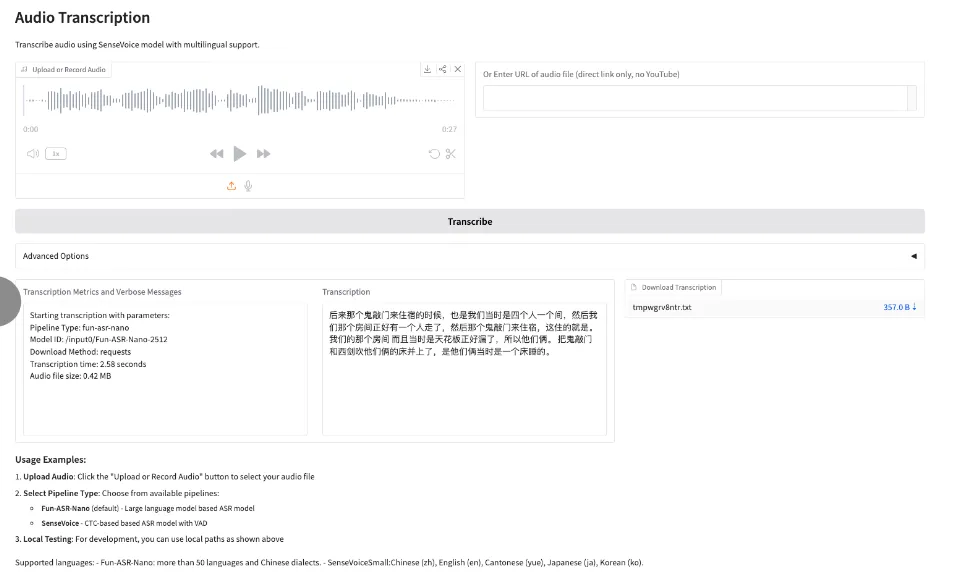
8. Fun-ASR-Nano: Ein groß angelegtes End-to-End-Spracherkennungsmodell
Fun-ASR-Nano ist eine umfassende Spracherkennungslösung für große Modelle von Alibaba Tongyi Labs und Teil der Fun-ASR-Serie. Die Lösung ist für Umgebungen mit geringer Rechenleistung konzipiert und zielt auf latenzarme Spracherkennung ab. Der Fokus liegt auf der Leistungsfähigkeit anhand realer Evaluierungsdatensätze. Zu den Funktionen gehören mehrsprachige freie Spracherkennung (freies Code-Switching), anpassbare Hotwords und Halluzinationsunterdrückung.
Online ausführen:https://go.hyper.ai/j7OdD
9. Fara-7B: Ein effizientes webbasiertes intelligentes Agentenmodell
Fara-7B ist das erste agentenbasierte SLM (Small Language Model) für den Computereinsatz, entwickelt von Microsoft Research. Mit nur 7 Milliarden Parametern (7B) erzielt es herausragende Ergebnisse bei realen Webseitenmanipulationsaufgaben, erreicht Bestleistungen in mehreren Web-Agent-Benchmarks und kommt bei einigen Aufgaben an größere Modelle heran oder übertrifft sie sogar.
Online ausführen:https://go.hyper.ai/2e5rp
Die Zeitungsempfehlung dieser Woche
1. Ansehen, Schlussfolgern und Suchen: Ein Benchmark für Videoanalyse im offenen Web für agentenbasiertes Video-Reasoning
Diese Arbeit stellt den ersten Benchmark für Video-Deep-Learning, VideoDR, vor. Dieser erfordert von Modellen die Extraktion visueller Anker aus Videos, interaktives Retrieval und Multi-Hop-Inferenz auf Basis von Daten aus verschiedenen Quellen. Die Evaluierung verschiedener großer Modelle zeigt, dass das Agentenparadigma dem Workflow-Paradigma nicht immer überlegen ist; seine Effektivität hängt von der Fähigkeit des Modells ab, die anfänglichen visuellen Anker in langen Retrieval-Ketten beizubehalten. Die Studie identifiziert Zielabweichung und Langzeitkonsistenz als zentrale Engpässe.
Link zum Artikel:https://go.hyper.ai/uB9jE
2. BabyVision: Visuelles Denken jenseits der Sprache
Diese Studie ergab, dass bestehende Modelle für maschinelles Lernen (MLLMs) übermäßig auf sprachliche Vorkenntnisse angewiesen sind und grundlegende visuelle Fähigkeiten von Kleinkindern vermissen lassen. Der BabyVision-Benchmark-Test des Forschungsteams zeigte, dass selbst die leistungsstärksten Modelle (wie z. B. Gemini mit 49,7 Punkten) deutlich niedrigere Werte als Erwachsene (94,1 Punkte) erzielten und sogar hinter 6-jährigen Kindern zurückblieben. Dies verdeutlicht ein grundlegendes Defizit im visuellen Grundverständnis. Ziel dieser Forschung ist es, MLLMs in Richtung einer visuellen Wahrnehmung und eines Denkens auf menschlichem Niveau weiterzuentwickeln.
Link zum Artikel:https://go.hyper.ai/cjtcE
3. Technischer Bericht STEP3-VL-10B
Diese Arbeit stellt STEP3-VL-10B als leistungsstarkes, quelloffenes, multimodales Basismodell vor. Durch einheitliches Vortraining, Reinforcement Learning und einen innovativen parallelen, koordinierten Inferenzmechanismus erzielt es mit nur 10 Milliarden Parametern herausragende Ergebnisse. In mehreren Benchmark-Tests konkurriert es mit 10- bis 20-mal größeren Modellen und führenden proprietären Modellen oder übertrifft diese sogar. Damit bietet es der Forschungsgemeinschaft einen leistungsstarken und effizienten Benchmark für visuelle Sprachintelligenz.
Link zum Artikel:https://go.hyper.ai/q6kmv
4. Denken mit Karte: Verstärkter paralleler kartengestützter Agent für die Geolokalisierung
Diese Arbeit schlägt vor, das Modell so zu programmieren, dass es „kartenbasiert denkt“. Durch Agent-Karten-Schleifen und zweistufige Optimierung werden Reinforcement Learning und parallele Testzeitskalierung eingesetzt, wodurch die Genauigkeit der Bildgeolokalisierung signifikant verbessert wird. Auf dem neu entwickelten Benchmark MAPBench für reale Bilder übertrifft diese Methode bestehende Open-Source- und proprietäre Modelle und steigert die Genauigkeit im Bereich von 500 Metern von 8,01 TP3T auf 22,11 TP3T.
Link zum Artikel:https://go.hyper.ai/Fn9XT
5. Urbane sozio-semantische Segmentierung mit Bild-Sprach-Analyse
Diese Studie stellt den SocioSeg-Datensatz und das SocioReasoner-Framework vor, das ein visuelles Sprachmodell für logisches Schließen nutzt, um die Herausforderung der Segmentierung sozialer semantischer Entitäten in Satellitenbildern zu bewältigen. Die Methode simuliert den menschlichen Annotationsprozess durch multimodale Erkennung und mehrstufiges Schließen und wird mithilfe von Reinforcement Learning optimiert. Experimentell übertrifft sie bestehende State-of-the-Art-Modelle und demonstriert starke Zero-Shot-Generalisierungsfähigkeiten.
Link zum Artikel:https://go.hyper.ai/PW7g4
Interpretation von Gemeinschaftsartikeln
1. Durch die Integration von Proteinsequenz-, 3D-Struktur- und Funktionscharakteristikadaten erstellte ein deutsches Team auf Basis von Metriklernen eine „Panoramaansicht“ der menschlichen E3-Ubiquitinligase.
In Organismen ist der zeitgerechte Abbau und die Erneuerung zellulärer Proteine entscheidend für die Aufrechterhaltung der Proteinhomöostase. Das Ubiquitin-Proteasom-System (UPS) ist ein zentraler Mechanismus zur Regulation der Signaltransduktion und des Proteinabbaus. Innerhalb dieses Systems fungieren E3-Ubiquitin-Ligasen als wichtige katalytische Einheiten, und bisher untersuchte E3-Ligasen weisen eine hohe Heterogenität auf. Vor diesem Hintergrund klassifizierte ein Forschungsteam der Goethe-Universität das „humane E3-Ligom“. Ihre Klassifizierungsmethode basiert auf einem Metrik-Lernparadigma und verwendet ein schwach überwachtes hierarchisches Framework, um die tatsächlichen Beziehungen zwischen der E3-Familie und ihren Unterfamilien zu erfassen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/zyM1F
2. Die Yale University hat MOSAIC vorgeschlagen, das ein Team von über 2.000 KI-Chemieexperten aufbaut und so eine effiziente Spezialisierung und Identifizierung optimaler Synthesewege ermöglicht.
Die moderne synthetische Chemie steht vor einem zentralen Widerspruch zwischen dem rasanten Wissenszuwachs und der Effizienz seiner Anwendung und Transformation. Derzeit wird die Entwicklung des Fachgebiets hauptsächlich durch zwei Faktoren eingeschränkt: Erstens stößt die Expertise von Fachleuten angesichts des stetig wachsenden Reaktionsraums an ihre Grenzen, was in interdisziplinären Syntheseaufgaben häufig zu hohen Kosten durch Versuch und Irrtum führt; zweitens ist die Zuverlässigkeit allgemeiner Modelle in der Chemie trotz der rasanten Entwicklung künstlicher Intelligenz nach wie vor unzureichend. Vor diesem Hintergrund hat ein Forschungsteam der Yale University kürzlich das MOSAIC-Modell vorgeschlagen, das ein allgemeines, großsprachiges Modell in ein kollaboratives System transformiert, das aus zahlreichen spezialisierten Chemieexperten besteht.
Den vollständigen Bericht ansehen:https://go.hyper.ai/oatBT
3. Online-Tutorial | GLM-Image: Anweisungen präzise verstehen und korrekten Text schreiben – basierend auf einer hybriden Architektur aus autoregressivem und Diffusionsdecoder
Im Bereich der Bildgenerierung haben sich Diffusionsmodelle aufgrund ihrer stabilen Trainings- und starken Generalisierungsfähigkeit zunehmend etabliert. Bei wissensintensiven Szenarien stoßen traditionelle Modelle jedoch an ihre Grenzen, wenn es darum geht, gleichzeitig das Verständnis von Anweisungen und die detaillierte Charakterisierung zu gewährleisten. Um dieses Problem zu lösen, hat Zhipu in Zusammenarbeit mit Huawei das Bildgenerierungsmodell GLM-Image als Open Source veröffentlicht. Dieses Modell wurde vollständig auf dem Ascend Atlas 800T A2 und dem MindSpore AI-Framework trainiert. Sein Kernmerkmal ist die innovative Hybridarchitektur aus autoregressivem Modell und Diffusionsdecoder (9-Bit-Autoregressionsmodell + 7-Bit-DiT-Decoder), die die Fähigkeiten von Sprachmodellen zum tiefen Verständnis mit den hochwertigen Generierungsfähigkeiten von Diffusionsmodellen kombiniert.
Den vollständigen Bericht ansehen:https://go.hyper.ai/LTojo
4. Neueste Erkenntnisse aus Nature von der Tsinghua-Universität und der Universität Chicago! Künstliche Intelligenz ermöglicht es Wissenschaftlern, 1,37 Jahre früher befördert zu werden und reduziert den Umfang der wissenschaftlichen Forschung um 4,631 TP3T.
Kürzlich veröffentlichte ein Forschungsteam der Tsinghua-Universität und der Universität Chicago seine neuesten Forschungsergebnisse in Nature mit dem Titel „Künstliche Intelligenz erweitert den Einfluss von Wissenschaftlern, aber verengt den Fokus der Wissenschaft“. Damit lieferte es der Branche beispiellose systematische Beweise, um die grundlegenden Auswirkungen von KI auf die Wissenschaft zu verstehen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/0NhLI
Beliebte Enzyklopädieartikel
1. Bilder pro Sekunde (FPS)
2. Reverse Sort Fusion RRF
3. Visuelles Sprachmodell (VLM)
4. Hypernetzwerke
5. Gesteuerte Aufmerksamkeit
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
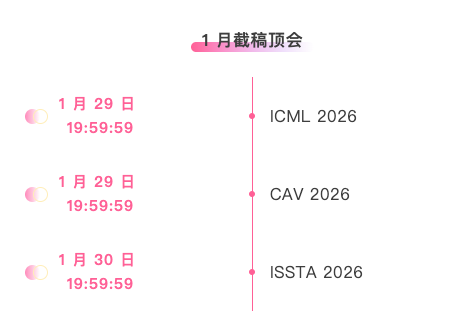
Eine zentrale Plattform zur Verfolgung der wichtigsten akademischen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








