Command Palette
Search for a command to run...
Eine Zusammenstellung Von Ressourcen Zum Thema Verkörperte Intelligenz: Datensätze Für Das Roboterlernen, Online-Erfahrungen Mit Weltmodellierungsmodellen Und Die Neuesten Forschungsarbeiten Von NVIDIA, ByteDance, Xiaomi Und anderen.

Wenn das Hauptschlachtfeld der künstlichen Intelligenz im letzten Jahrzehnt das „Verstehen der Welt“ und die „Generierung von Inhalten“ war, dann verschiebt sich die Kernfrage der nächsten Phase hin zu einer anspruchsvolleren Aufgabe:Wie kann KI tatsächlich in die physische Welt eintreten und in ihr handeln, lernen und sich weiterentwickeln?Der Begriff „verkörperte Intelligenz“ ist in verwandten Forschungsarbeiten und Diskussionen häufig aufgetaucht.
Wie der Name schon sagt, ist verkörperte Intelligenz kein herkömmlicher Roboter.Stattdessen wird betont, dass Intelligenz durch die Interaktion zwischen dem Akteur und seiner Umwelt in einem geschlossenen Kreislauf aus Wahrnehmung, Entscheidungsfindung und Handlung entsteht.Aus dieser Perspektive existiert Intelligenz nicht mehr allein in Modellparametern oder Denkfähigkeiten, sondern ist tief in Sensoren, Aktoren, Umweltrückkopplung und langfristigem Lernen verankert. Diskussionen über Robotik, autonomes Fahren, Agenten und sogar künstliche allgemeine Intelligenz (AGI) fließen in dieses Rahmenwerk ein.
Aus diesem Grund hat sich verkörperte Intelligenz in den letzten zwei Jahren zu einem Schwerpunkt der globalen Technologiekonzerne und führender Forschungseinrichtungen entwickelt. Tesla-CEO Elon Musk betonte wiederholt, dass der humanoide Roboter Optimus genauso bedeutend sei wie das autonome Fahren; Nvidia-Gründer Jensen Huang sieht in der physikalischen KI die nächste Stufe nach der generativen KI und investiert weiterhin massiv in Robotersimulations- und Trainingsplattformen; Fei-Fei Li, Yann LeCun und andere liefern kontinuierlich hochwertige, wegweisende Analysen und Ergebnisse in Teilbereichen wie räumlicher Intelligenz und Weltmodellen; OpenAI, Google DeepMind und Meta erforschen ebenfalls die Lernfähigkeiten intelligenter Agenten in realen oder nahezu realen Umgebungen mithilfe von Technologien wie multimodalen Modellen und Reinforcement Learning.
Vor diesem Hintergrund ist verkörperte Intelligenz nicht länger nur ein Problem einzelner Modelle oder Algorithmen, sondern hat sich schrittweise zu einem Forschungsökosystem entwickelt, das Datensätze, Simulationsumgebungen, Benchmark-Aufgaben und systematische Methoden umfasst. Um mehr Lesern ein schnelles Verständnis der wichtigsten Aspekte dieses Forschungsfelds zu ermöglichen,Dieser Artikel wird eine Reihe hochwertiger Datensätze, Online-Tutorials und wissenschaftlicher Arbeiten zum Thema verkörperte Intelligenz systematisch ordnen und empfehlen und somit eine Referenz für weiteres Lernen und Forschen bieten.
Datensatzempfehlung
1. BC-Z Roboter-Lerndatensatz
Geschätzte Größe:32,28 GB
Downloadadresse:https://go.hyper.ai/vkRel

Dies ist ein umfangreicher Datensatz für das Robotik-Lernen, der gemeinsam von Google, Everyday Robots, der UC Berkeley und der Stanford University entwickelt wurde. Er umfasst über 25.877 verschiedene Einsatzszenarien, die 100 diverse operative Aufgaben abdecken. Diese Aufgaben wurden durch Fernsteuerung auf Expertenniveau und gemeinsame autonome Prozesse mit 12 Robotern und 7 verschiedenen Bedienern erfasst, wobei insgesamt 125 Stunden Roboterbetriebszeit erreicht wurden. Der Datensatz ermöglicht das Training einer 7-DOF-Multitasking-Strategie, die anhand der verbalen Aufgabenbeschreibung oder von Videos der menschlichen Bedienung angepasst werden kann, um spezifische operative Aufgaben auszuführen.
2.DexGraspVLA Roboter-Greifdatensatz
Geschätzte Größe:7,29 GB
Downloadadresse:https://go.hyper.ai/G37zQ

Dieser vom Psi-Robot-Team erstellte Datensatz enthält 51 Demonstrationsdaten von Menschen, um das Datenformat zu verstehen, den Code auszuführen und den Trainingsprozess nachzuvollziehen. Die Forschung basiert auf dem Bedarf an hohen Erfolgsraten beim agilen Greifen in unübersichtlichen Umgebungen, insbesondere an einer Erfolgsrate von über 901 TP3T unter verschiedenen Kombinationen aus unsichtbaren Objekten, Beleuchtung und Hintergründen. Das Framework verwendet ein vortrainiertes visuelles Sprachmodell als übergeordneten Aufgabenplaner und lernt eine diffusionsbasierte Strategie als untergeordneten Aktionscontroller. Die Innovation besteht darin, das Basismodell für eine starke Generalisierungsfähigkeit zu nutzen und diffusionsbasiertes Imitationslernen zum Erlernen agiler Aktionen einzusetzen.
3.EgoThink: Ein Benchmark-Datensatz zur visuellen Beantwortung von Fragen aus der Ich-Perspektive
Geschätzte Größe:865,29 MB
Downloadadresse:https://go.hyper.ai/5PsDP

Dieser von der Tsinghua-Universität entwickelte Datensatz ist ein Benchmark-Datensatz für visuelle Fragebeantwortung aus der Ich-Perspektive. Er umfasst 700 Bilder, die sechs Kernkompetenzen abdecken und in zwölf Dimensionen unterteilt sind. Die Bilder stammen aus dem Ego4D-Videodatensatz für die Ich-Perspektive. Um die Datenvielfalt zu gewährleisten, wurden maximal zwei Bilder pro Video ausgewählt. Bei der Erstellung des Datensatzes wurden ausschließlich qualitativ hochwertige Bilder berücksichtigt, die das Denken aus der Ich-Perspektive deutlich veranschaulichen. EgoThink bietet vielfältige Anwendungsmöglichkeiten, insbesondere zur Evaluierung und Verbesserung der Leistung visueller Lernmodelle (VLMs) in Aufgaben aus der Ich-Perspektive. Der Datensatz stellt wertvolle Ressourcen für zukünftige Forschung im Bereich verkörperter künstlicher Intelligenz und Robotik dar.
4.EQA-Fragen-Antwort-Datensatz
Geschätzte Größe:839,6 KB
Downloadadresse:https://go.hyper.ai/8Uv1o
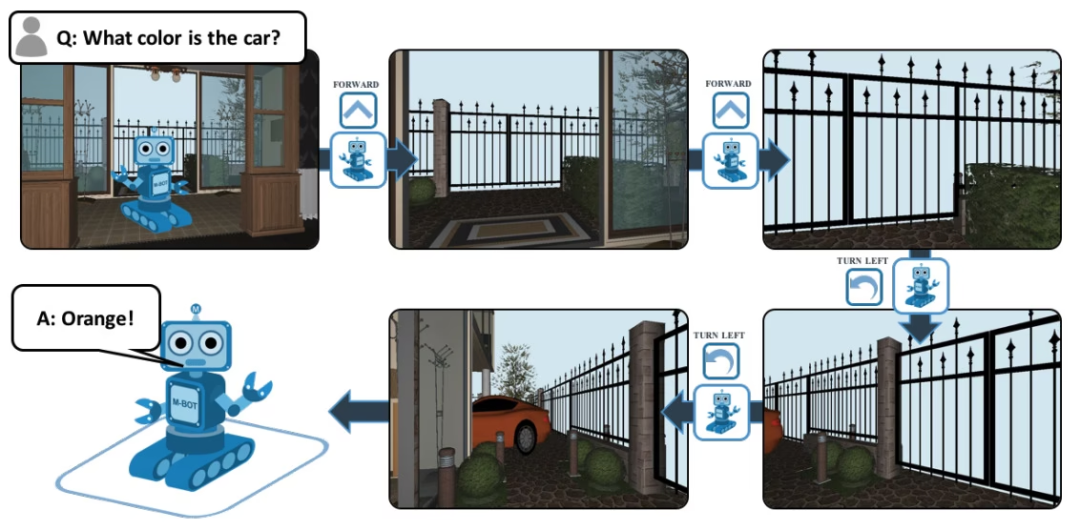
EQA, dessen vollständiger Name „Embodied Question Answering“ lautet, ist ein visueller Datensatz zur Beantwortung von Fragen und Antworten, der auf House3D basiert. Nach Erhalt einer Frage kann ein Agent an einem beliebigen Ort in der Umgebung nützliche Informationen in der Umgebung finden und die Frage beantworten. Zum Beispiel: F: Welche Farbe hat das Auto? Um diese Frage zu beantworten, muss der Agent zunächst die Umgebung durch intelligente Navigation erkunden, die erforderlichen visuellen Informationen aus der Ich-Perspektive sammeln und dann die Frage beantworten: Orange.
5. OmniRetarget Global Robot
Bewegungs-Remapping-Datensatz
Geschätzte Größe:349,61 MB
Downloadadresse:https://go.hyper.ai/IloBI

Dies ist ein hochwertiger Datensatz mit Bewegungstrajektorien für die Ganzkörper-Bewegungsmodellierung humanoider Roboter, der von Amazon in Zusammenarbeit mit dem MIT, der UC Berkeley und weiteren Institutionen veröffentlicht wurde. Er enthält die Bewegungstrajektorien des humanoiden Roboters G1 bei der Interaktion mit Objekten und komplexem Gelände und deckt drei Szenarien ab: das Tragen von Objekten, das Gehen im Gelände und die hybride Interaktion zwischen Objekt und Gelände. Aus lizenzrechtlichen Gründen ist in dem öffentlich verfügbaren Datensatz keine neu modellierte Version von LAFAN1 enthalten. Der Datensatz ist in drei Teilmengen unterteilt, die insgesamt etwa vier Stunden an Bewegungstrajektoriendaten umfassen:
* Roboter-Objekt: Die aus OMOMO 3.0-Daten abgeleitete Trajektorie des vom Roboter transportierten Objekts;
* Roboter-Gelände: Die Bewegungstrajektorie des Roboters auf komplexem Gelände, generiert durch interne MoCap-Datenerfassung, Dauer ca. 0,5 Stunden;
* robot-object-terrain: Hierbei handelt es sich um die Bewegungstrajektorie eines Objekts in Interaktion mit dem Gelände; die Dauer beträgt ungefähr 0,5 Stunden.
Darüber hinaus enthält der Datensatz auch ein Modellverzeichnis, das visuelle Modelldateien in den Formaten URDF, SDF und OBJ zur Anzeige und nicht zum Training bereitstellt.
Weitere hochwertige Datensätze ansehen:https://hyper.ai/datasets
Tutorial-Empfehlungen
Die Forschung im Bereich der verkörperten KI kombiniert häufig mehrere Modelle und Module, um Wahrnehmung, Verständnis, Planung und Handeln in der physischen Welt zu ermöglichen. Dazu gehören Weltmodelle und Denkmodelle. Dieser Artikel empfiehlt vorrangig die folgenden zwei aktuellen Open-Source-Modelle.
Weitere hochwertige Tutorials ansehen:https://hyper.ai/notebooks
1.HY-World 1.5: Framework für ein interaktives Weltmodellierungssystem
HY-World 1.5 (WorldPlay) ist das erste Open-Source-Echtzeit-Modell für interaktive Welten mit langfristiger geometrischer Konsistenz, entwickelt vom Hunyuan-Team von Tencent. Dieses Modell realisiert die Echtzeit-Modellierung interaktiver Welten durch Streaming-Video-Diffusionstechnologie und löst so den Zielkonflikt zwischen Geschwindigkeit und Speicherbedarf, der bei bisherigen Methoden besteht.
Online ausführen:https://go.hyper.ai/qsJVe
2.vLLM+Open WebUI-Bereitstellung Nemotron-3 Nano
Das Nemotron-3-Nano-30B-A3B-BF16 ist ein von NVIDIA von Grund auf trainiertes, groß angelegtes Sprachmodell (LLM). Es ist als einheitliches Modell konzipiert, das sowohl für Aufgaben mit als auch ohne logisches Denken geeignet ist und hauptsächlich zum Aufbau von KI-Agentensystemen, Chatbots, RAG-Systemen (Retrieval Augmented Generation) und anderen KI-Anwendungen verwendet wird.
Online ausführen:https://go.hyper.ai/6SK6n
Papierempfehlung
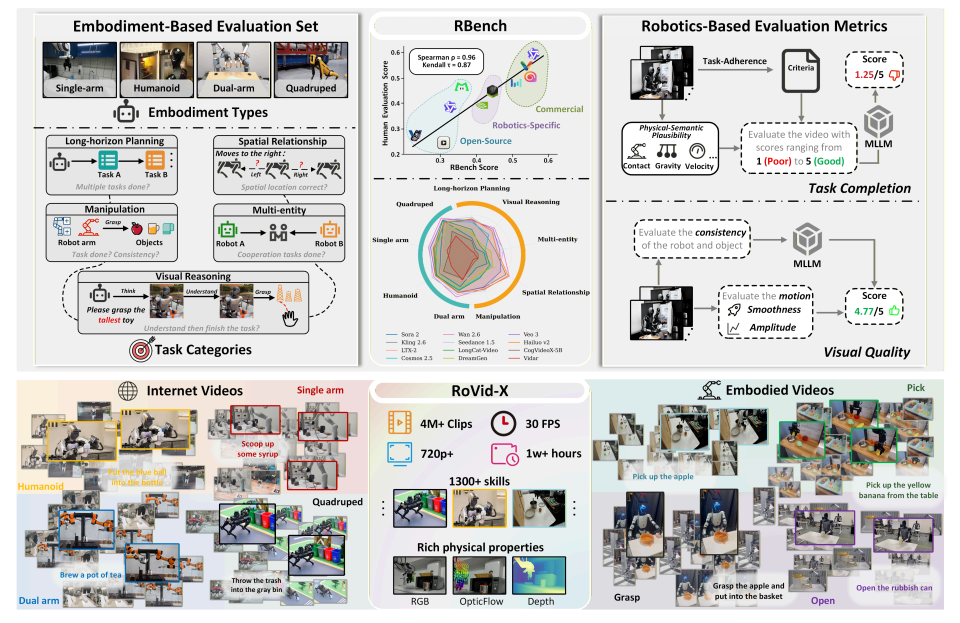
- RBench
Titel der Dissertation:Überdenken des Videogenerierungsmodells für die verkörperte Welt
Forschungsteam:Peking-Universität, ByteDance-Seed
Lesen Sie das Dokument:https://go.hyper.ai/k1oMT
Forschungszusammenfassung:
Das Team entwickelte mit RBench einen umfassenden Benchmark für die Roboter-Videogenerierung, der fünf Aufgabenbereiche und vier verschiedene Roboterformen abdeckt. Die Videogenerierung wird anhand zweier Dimensionen bewertet: Korrektheit auf Aufgabenebene und visuelle Wiedergabetreue. Hierfür werden reproduzierbare Subindikatoren verwendet, darunter strukturelle Konsistenz, physikalische Plausibilität und Vollständigkeit der Bewegungen. Die Auswertungsergebnisse von 25 repräsentativen Videogenerierungsmodellen zeigen, dass die aktuellen Methoden noch erhebliche Defizite bei der Generierung physikalisch realistischer Roboterbewegungen aufweisen. Darüber hinaus erreicht der Spearman-Korrelationskoeffizient zwischen RBench und der menschlichen Bewertung 0,96, was die Effektivität des Benchmarks bei der Messung der Modellqualität bestätigt.
Darüber hinaus wurde im Rahmen der Studie auch RoVid-X erstellt – der bisher größte Open-Source-Datensatz zur Roboter-Videogenerierung, der 4 Millionen annotierte Videoclips enthält, die Tausende von Aufgaben abdecken und durch umfassende Annotationen physikalischer Attribute ergänzt werden.
2. Being-H0.5
Titel des Artikels:Being-H0.5: Skalierung des menschenzentrierten Roboterlernens für die körperübergreifende Generalisierung
Forschungsteam:Jenseits des Seins
Lesen Sie das Dokument:https://go.hyper.ai/pW24B
Forschungszusammenfassung:
Das Team entwickelte mit Being-H0.5 ein grundlegendes Vision-Language-Action (VLA)-Modell, das auf hohe Generalisierungs- und Verkörperungsfähigkeiten auf verschiedenen Roboterplattformen ausgelegt ist. Bestehende VLA-Modelle stoßen häufig an ihre Grenzen, beispielsweise aufgrund signifikanter Unterschiede in der Robotermorphologie und mangelnder Datenverfügbarkeit. Um dieser Herausforderung zu begegnen, schlugen sie ein nutzerzentriertes Lernparadigma vor, das menschliche Interaktionsmuster als universelle „Muttersprache“ im Bereich der physischen Interaktion betrachtet.
Gleichzeitig veröffentlichte das Team UniHand-2.0, eine der bisher umfangreichsten Lösungen für verkörpertes Vortraining mit über 35.000 Stunden multimodaler Daten aus 30 verschiedenen Roboterformen. Methodisch schlugen sie einen einheitlichen Aktionsraum vor, der heterogene Steuerungsmethoden verschiedener Roboter semantisch ausgerichteten Aktionsfeldern zuordnet. Dadurch können ressourcenarme Roboter schnell Fähigkeiten von menschlichen Daten und leistungsstarken Plattformen übernehmen und erlernen.

3. Schnelles Denken und Handeln
Titel des Artikels:Schnelles Denken und Handeln: Effizientes Sehen-Sprache-Handlungs-Schlussfolgern durch verbalisierbare latente Planung
Forschungsteam:Nvidia
Lesen Sie das Dokument:https://go.hyper.ai/q1h7j
Forschungszusammenfassung:
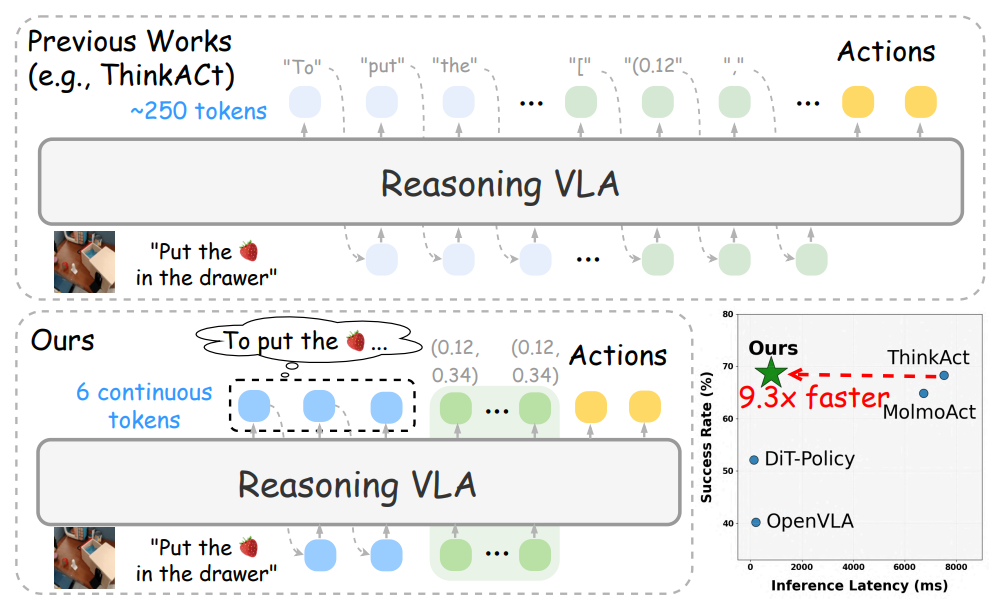
Das Team entwickelte Fast-ThinkAct, ein effizientes Framework für logisches Denken, das durch einen latenten linguistischen Denkmechanismus einen kompakteren Planungsprozess bei gleichbleibender Leistung ermöglicht. Fast-ThinkAct erlernt effiziente Denkfähigkeiten, indem es latente kognitive Verhaltensmuster (CoTs) aus Lehrermodellen extrahiert und Operationsabläufe anhand einer präferenzgesteuerten Zielfunktion ausrichtet. Dadurch werden sowohl linguistische als auch visuelle Planungsfähigkeiten in die verkörperte Steuerung integriert.
Umfangreiche experimentelle Ergebnisse, die verschiedene verkörperte Operationen und Inferenzaufgaben abdecken, zeigen, dass Fast-ThinkAct bei Beibehaltung der langfristigen Planungsfähigkeiten, der Anpassungsfähigkeit bei wenigen Stichproben und der Fähigkeiten zur Fehlerbehebung eine signifikante Leistungsverbesserung erzielt, indem die Inferenzlatenz im Vergleich zu den derzeit modernsten inferenzbasierten VLA-Modellen um bis zu 89,31 TP3T reduziert wird.
4. JudgeRLVR
Titel des Artikels:JudgeRLVR: Erst beurteilen, dann generieren für effizientes Schließen
Forschungsteam:Universität Peking, Xiaomi
Lesen Sie das Dokument:https://go.hyper.ai/2yCxp
Forschungszusammenfassung:
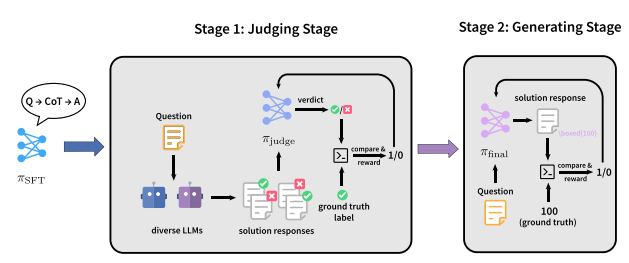
Das Team schlug ein zweistufiges Trainingsparadigma namens JudgeRLVR vor, das auf dem Prinzip „zuerst diskriminieren, dann generieren“ basiert. In der ersten Stufe trainiert das Team ein Modell, um Problemlösungsantworten anhand verifizierbarer Ergebnisse zu diskriminieren und zu bewerten. In der zweiten Stufe wird dasselbe Modell mithilfe des standardmäßigen generativen RLVR feinabgestimmt, wobei das diskriminative Modell als Initialisierung dient.
Im Vergleich zu Vanilla RLVR, das mit Trainingsdaten aus demselben mathematischen Bereich verwendet wird, erzielt JudgeRLVR auf Qwen3-30B-A3B einen besseren Kompromiss zwischen Qualität und Effizienz: Bei mathematischen Aufgaben innerhalb des Bereichs wird die durchschnittliche Genauigkeit um etwa 3,7 Prozentpunkte verbessert, während die durchschnittliche Generationslänge um 42% reduziert wird; bei Benchmarks außerhalb des Bereichs wird die durchschnittliche Genauigkeit um etwa 4,5 Prozentpunkte verbessert, was eine stärkere Generalisierungsfähigkeit demonstriert.
5. ACoT-VLA
Titel des Artikels:ACoT-VLA: Handlungskette für Vision-Sprache-Handlungs-Modelle
Forschungsteam:Universität für Luft- und Raumfahrt Peking, AgiBot
Lesen Sie das Dokument:https://go.hyper.ai/2jMmY
Forschungszusammenfassung:
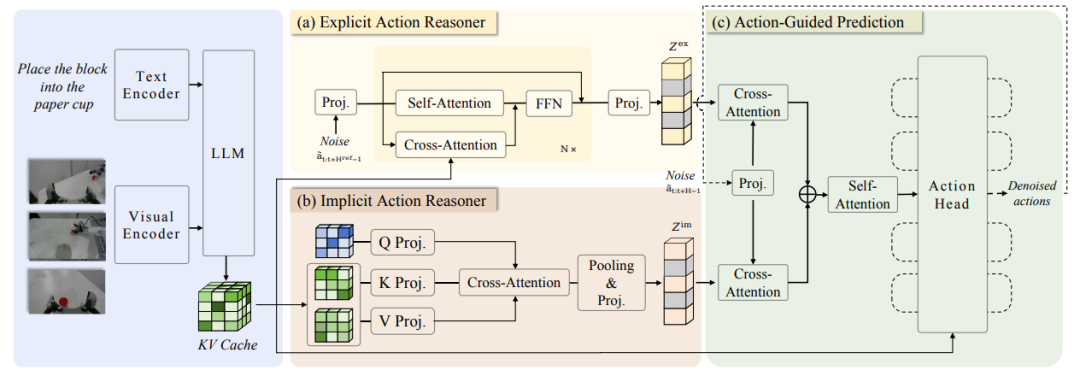
Das Team schlug zunächst die Handlungskette (Action Chain-of-Thought, ACoT) vor, die den Denkprozess selbst als eine Reihe strukturierter, grobkörniger Handlungsabsichten modelliert, um die finale Politikgenerierung zu steuern. Anschließend entwickelten sie ACoT-VLA, eine neuartige Modellarchitektur, die das ACoT-Paradigma konkretisiert.
Das spezifische Design führt zwei komplementäre Kernkomponenten ein: den Explicit Action Reasoner (EAR) und den Implicit Action Reasoner (IAR). Der EAR schlägt eine grobkörnige Referenztrajektorie in Form expliziter Handlungslogik-Schritte vor, während der IAR latente Handlungsprioritäten aus den internen Repräsentationen multimodaler Eingaben extrahiert. Zusammen bilden sie den ACoT und dienen als bedingte Eingaben für den nachgelagerten Aktionskopf, wodurch Policy-Learning mit Landing Constraints erreicht wird.
Umfangreiche experimentelle Ergebnisse sowohl in realen als auch in Simulationsumgebungen belegen die signifikanten Vorteile dieser Methode und erzielen Punktzahlen von 98,51 TP3T, 84,11 TP3T bzw. 47,41 TP3T auf den Benchmarks LIBERO, LIBEROPlus und VLABench.
Sehen Sie sich die neuesten Artikel an:https://hyper.ai/papers








