Command Palette
Search for a command to run...
Objekterkennung in Echtzeit Auf Dem Neuesten Stand Der Technik! YOLOv13 Erweitert Die Globalen Erkennungsfähigkeiten; UltraHR-100K Wurde Für Die NeurIPS 2025 Ausgewählt Und Ermöglicht Die Erfassung Von Texturbildern in Ultrahoher Auflösung.

Die Echtzeit-Objekterkennung zählt seit Langem zu den modernsten Forschungsgebieten der Computer Vision. Von der industriellen Objekterkennung bis zum autonomen Fahren – das Streben nach Geschwindigkeit und Genauigkeit ist in Wissenschaft und Industrie ungebrochen. Die YOLO-Modellreihe hat sich in diesem Bereich aufgrund ihres hervorragenden Verhältnisses von Inferenzgeschwindigkeit und Genauigkeit eine führende Position erarbeitet.
Jedoch,Von frühen Versionen von YOLO bis hin zu YOLOv11 und sogar YOLOv12, das einen Mechanismus zur regionalen Selbstaufmerksamkeit verwendet, stoßen alle bei der Bewältigung komplexer Szenarien an ihre Grenzen:Faltungsoperationen können Informationen nur innerhalb eines festen lokalen rezeptiven Feldes aggregieren, und ihre Modellierungsfähigkeit ist durch die Größe des Faltungskerns und die Netzwerktiefe begrenzt. Obwohl der Selbstaufmerksamkeitsmechanismus das rezeptive Feld erweitert, muss er dennoch den hohen Rechenaufwand für globale Modellierung und Wahrnehmung ausgleichen. Wichtiger noch: Selbstaufmerksamkeit kann im Wesentlichen nur binäre Korrelationen zwischen Pixeln modellieren.
Um diesen Herausforderungen zu begegnen, wurde die YOLO-Serie auf die neueste Version, YOLOv13, aktualisiert.Die neue Version führt einen hypergraphbasierten adaptiven Relevanzverbesserungsmechanismus (HyperACE) ein, der potenzielle Relevanzen höherer Ordnung adaptiv nutzt. Dadurch werden die Einschränkungen bisheriger Methoden, die auf paarweise Relevanzmodellierung mittels Hypergraphberechnung beschränkt waren, überwunden und eine effiziente globale Merkmalsfusion und -verbesserung über verschiedene Standorte und Skalen hinweg erreicht. Aufbauend auf den Vorteilen der Echtzeitdetektion der YOLO-Serie führt die neue Version zudem eine Reihe neuer Mechanismen ein, wie z. B. semantische Modellierung höherer Ordnung und ressourcenschonende Strukturrekonstruktion.Dies erweitert die traditionelle regionenbasierte Modellierung paarweiser Interaktionen auf die globale Assoziationsmodellierung höherer Ordnung.
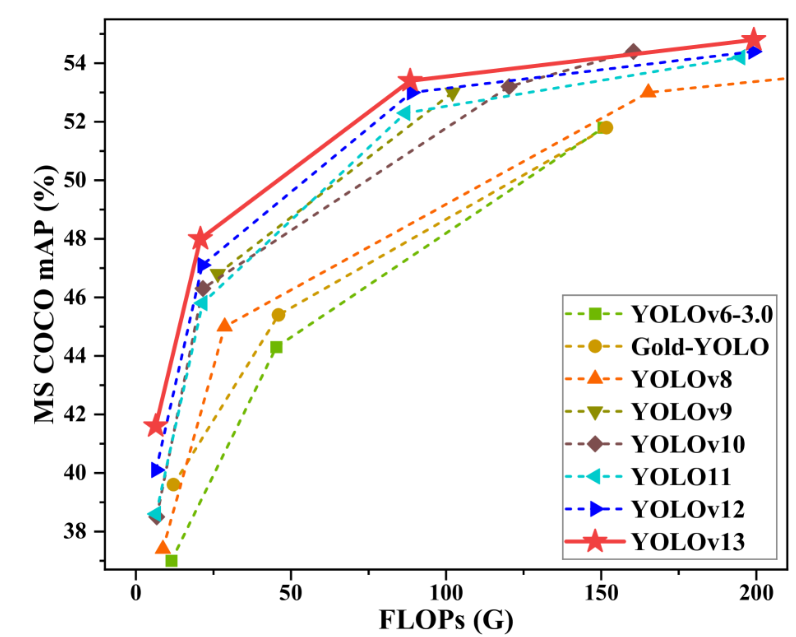
YOLOv13 hat eine umfassende Führungsposition bei gängigen Datensätzen wie MS COCO und Pascal VOC erreicht.Es weist eine höhere Generalisierungsfähigkeit und bessere Einsatzmöglichkeiten auf und bietet fortschrittlichere Leistungsoptionen für Anwendungen in komplexen Szenarien.
Die HyperAI-Website bietet jetzt eine Funktion zur Ein-Klick-Bereitstellung von Yolov13. Probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/PAcy1
Ein kurzer Überblick über die Aktualisierungen der hyper.ai-Website vom 3. bis 7. November:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 3
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefristen im November: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Datensatz zu Gesundheitsindikatoren für Diabetes
Diabetes Health Indicators ist ein umfassender Datensatz für Gesundheits- und medizinische Analysen, der die Vorhersage des Diabetesrisikos, die Forschung im Bereich der öffentlichen Gesundheit und die Modellierung mittels maschinellen Lernens unterstützt. Der Datensatz enthält 31 Merkmalsfelder zu Diabetes, die vier Hauptkategorien von Variablen abdecken: demografische Merkmale, Lebensstil, Krankengeschichte und klinische Indikatoren.
Direkte Verwendung:https://go.hyper.ai/nVnPo
2. Nemotron Personas USA: Ein Datensatz amerikanischer Persona-Datensätze.
Nemotron-Personas-USA ist ein von NVIDIA veröffentlichter, umfangreicher Datensatz synthetischer Benutzerprofile, der das Training und die Evaluierung großer Sprachmodelle (LLMs) und intelligenter Agentensysteme bei Aufgaben wie Dialoggenerierung, Rollensimulation, Benutzermodellierung und Analyse verschiedener Verhaltensweisen unterstützt.
Direkte Verwendung:https://go.hyper.ai/lMA6r
3. UltraHR-100K Ultrahochauflösender Bilddatensatz
UltraHR-100K ist ein umfangreicher, qualitativ hochwertiger Datensatz für die Text-zu-Bild-Konvertierung (T2I) mit ultrahoher Auflösung (UHR). Er wurde entwickelt, um die Leistungsfähigkeit von Diffusionsmodellen hinsichtlich der Synthese feinster Details, der Darstellung von Inhaltsdiversität und der visuellen Wiedergabetreue zu verbessern. Der Datensatz umfasst ca. 100.000 ultrahochauflösende Bilder aus verschiedenen Motiven, darunter Personen und Architektur. Jedes Bild hat eine Auflösung von über 3K und wird von hochwertigen Rich-Text-Beschreibungen begleitet.
Direkte Verwendung:https://go.hyper.ai/I3Fwl

4. Lifestyle-Daten
Lifestyle Data ist ein umfassender Datensatz zu Gesundheits- und Fitnessverhalten, der als hochwertige Datengrundlage für personalisierte Gesundheitsempfehlungssysteme, Trainingsanalysen und Modellierungen zur Lebensstilprognose dient. Dieser Datensatz integriert Informationen zu Einzelpersonen über verschiedene Dimensionen hinweg, darunter tägliche Ernährung, Bewegung, physiologische Indikatoren und Körperzusammensetzung, und wird in einem strukturierten Tabellenformat (CSV) mit vollständigen Feldern für mehrstufige Variablen wie individuelle Merkmale, Trainingsleistung, Ernährungsstruktur und Fitnessverhalten dargestellt.
Direkte Verwendung:https://go.hyper.ai/SGK9K
5. Globaler Datensatz zum Erdbeben- und Tsunami-Risiko
Die globale Erdbeben-Tsunami-Risikobewertung ist ein globaler Datensatz zur Bewertung des Erdbeben- und Tsunami-Risikos. Er dient als standardisierte und computergestützte Datengrundlage für die Tsunami-Risikovorhersage, die Analyse von Erdbebenereignissen und die Bewertung der Erdbebengefährdung.
Direkte Verwendung:https://go.hyper.ai/a9Nrz
6. ShiftySpeech-Datensatz zur Evaluierung der Sprachverteilung
ShiftySpeech ist ein umfangreicher Benchmark für die Erkennung synthetischer Sprache, der von der Johns Hopkins University veröffentlicht wurde. Ziel ist es, die Generalisierungsfähigkeit von Modellen zur Erkennung von Sprachsynthese in realen Situationen zu untersuchen, wenn diese mit „Verteilungsdrift“ (einschließlich Änderungen der Sprache, des Sprechers, des Generierungsmodells und der Aufnahmebedingungen) konfrontiert werden.
Direkte Verwendung:https://go.hyper.ai/YMKSP
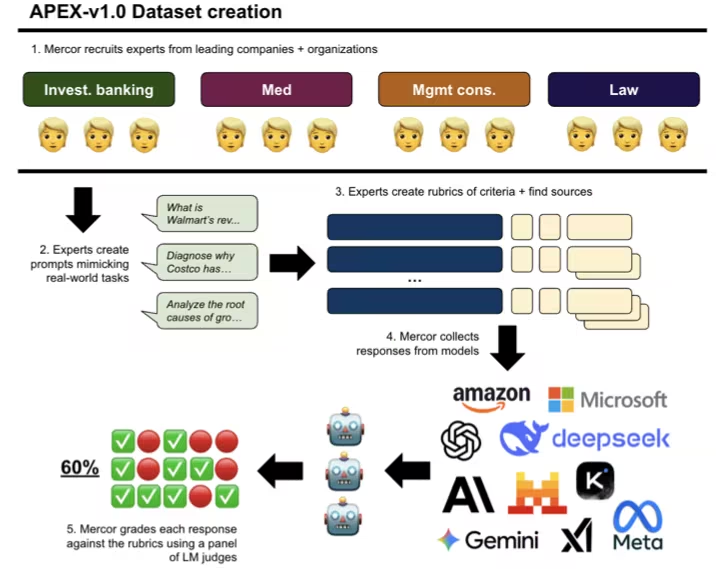
7. APEX AI Produktivitäts-Benchmark-Datensatz
APEX ist ein umfassender Benchmark-Datensatz, der vom Mercor-Forschungsteam in Zusammenarbeit mit der Harvard Law School und dem Scripps Research Institute entwickelt wurde. Er dient der Bewertung der Leistungsfähigkeit modernster KI-Modelle bei wissensintensiven Aufgaben mit hohem wirtschaftlichem Wert. Ziel ist es, die Leistungsfähigkeit dieser Modelle anhand realer wirtschaftlicher Fragestellungen zu messen und nicht nur abstrakte Schlussfolgerungen zu betrachten.
Direkte Verwendung:https://go.hyper.ai/3E2on
8. Multi-LMentry Multilingual Basic Task Benchmark Dataset
Multi-LMentry ist ein mehrsprachiger Benchmark-Datensatz, der die sprachübergreifende Generalisierungsfähigkeit großer Sprachmodelle (LLMs) für Aufgaben des grundlegenden Sprachverstehens und des logischen Denkens in mehrsprachigen Umgebungen systematisch evaluiert. Der Datensatz umfasst neun Sprachen, darunter Englisch und Deutsch. Die Aufgaben wurden von Muttersprachlern manuell überarbeitet und ähneln in ihrer Form dem ursprünglichen LMentry-Framework, wurden aber nicht direkt übersetzt, um Natürlichkeit und kulturelle Passung zu gewährleisten.
Direkte Verwendung:https://go.hyper.ai/o2uJC
9. Ditto-1M-Datensatz für anweisungsgesteuerte Videobearbeitung
Ditto-1M ist ein anweisungsbasierter Datensatz für Videobearbeitung, der von der Hong Kong University of Science and Technology in Zusammenarbeit mit der Ant Group, der Zhejiang University und weiteren Institutionen entwickelt wurde. Ziel ist es, die Entwicklung von Videobearbeitungsmodellen auf Basis von natürlichsprachlichen Anweisungen zu fördern und das Verständnis komplexer Anweisungen sowie die Genauigkeit der Videogenerierung durch umfangreiche, qualitativ hochwertige synthetische Beispiele zu verbessern.
Direkte Verwendung:https://go.hyper.ai/o2uJC

10. Leistungsdaten des Reac-Discovery-ChemiereaktorsSatz
Reac-Discovery, ein Datensatz der Jaume I Universität, dient der KI-gestützten Auslegung von Durchflussreaktoren und der Optimierung der Reaktionsleistung. Dieser Datensatz wird während Experimenten mit der eigens entwickelten Reac-Discovery-Plattform automatisch generiert, ohne auf externe, öffentlich zugängliche Datenquellen zurückzugreifen. Er umfasst drei Datenkategorien: Geometrie, Druckbarkeit und Reaktionsleistung, die den Funktionsmodulen Reac-Gen, Reac-Fab und Reac-Eval der Plattform entsprechen.
Direkte Verwendung:https://go.hyper.ai/bMxVY
Ausgewählte öffentliche Tutorials
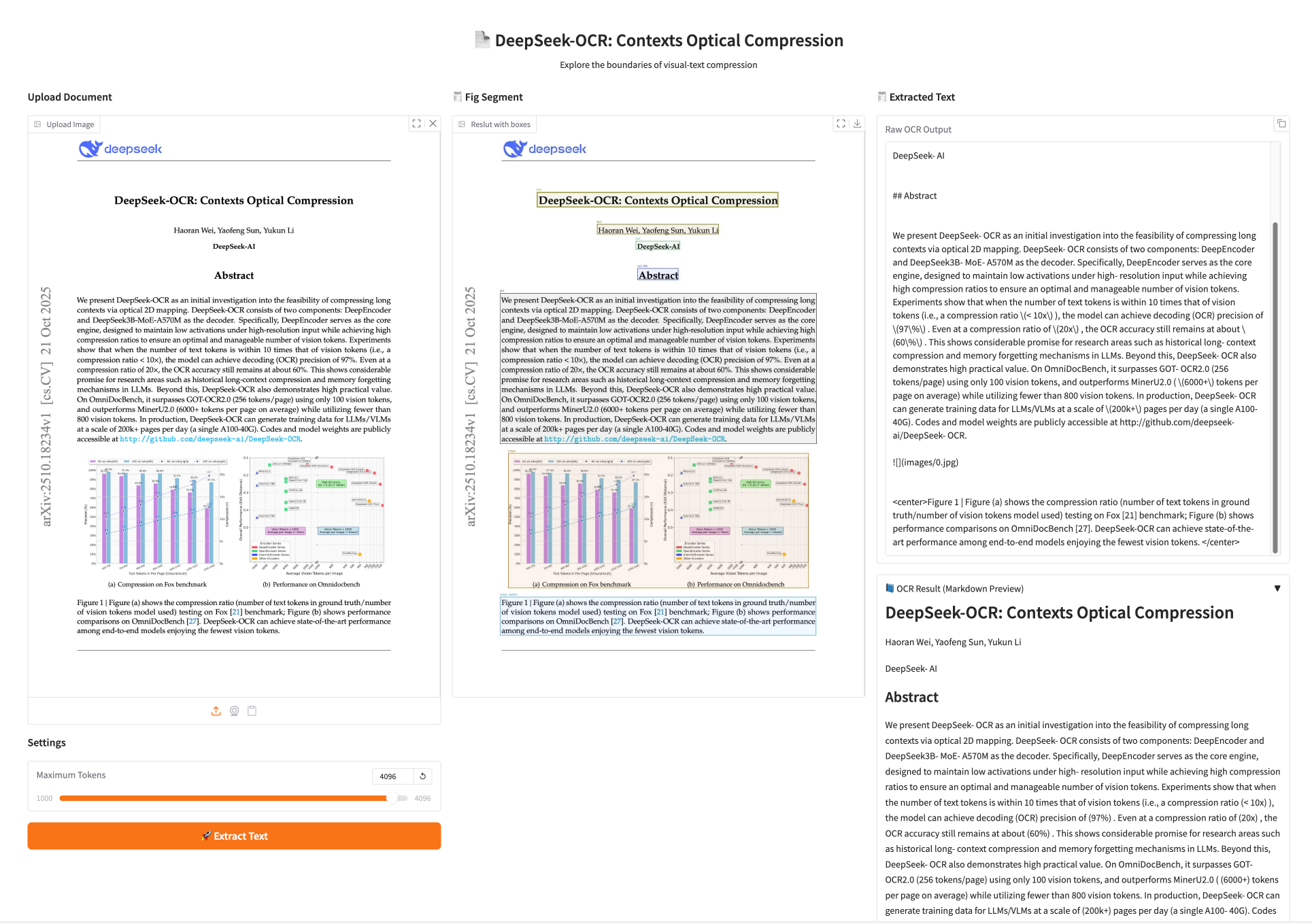
1. DeepSeek-OCR: „Visuelle Komprimierung“ ersetzt die traditionelle Zeichenerkennung
DeepSeek-OCR, veröffentlicht von DeepSeek Inc., ist eine Vorstudie zur Machbarkeit der Komprimierung langer Bildkontexte. Experimente zeigen, dass das Modell eine Dekodierungsgenauigkeit (OCR) von 971 TP3T erreicht, wenn die Anzahl der Text-Tokens das Zehnfache der Anzahl der Bild-Tokens nicht übersteigt (Kompressionsverhältnis < 10×). Selbst bei einem Kompressionsverhältnis von 20× liegt die OCR-Genauigkeit noch bei etwa 601 TP3T.
Online ausführen:https://go.hyper.ai/wmghV
2. Nanonets-OCR2-3B: Genauere Interpretation visueller Elemente in komplexen Dokumenten
Nanonets-OCR2-3B ist ein von Nanonets entwickeltes Bild-zu-Markdown-Modell. Es kann Dokumente nicht nur in strukturiertes Markdown umwandeln, sondern nutzt auch intelligente Inhaltserkennung, semantisches Tagging und kontextbezogene visuelle Fragebeantwortung, um ein tieferes Verständnis und eine präzisere Interpretation komplexer Dokumente zu ermöglichen.
Online ausführen: https://go.hyper.ai/3DWbb
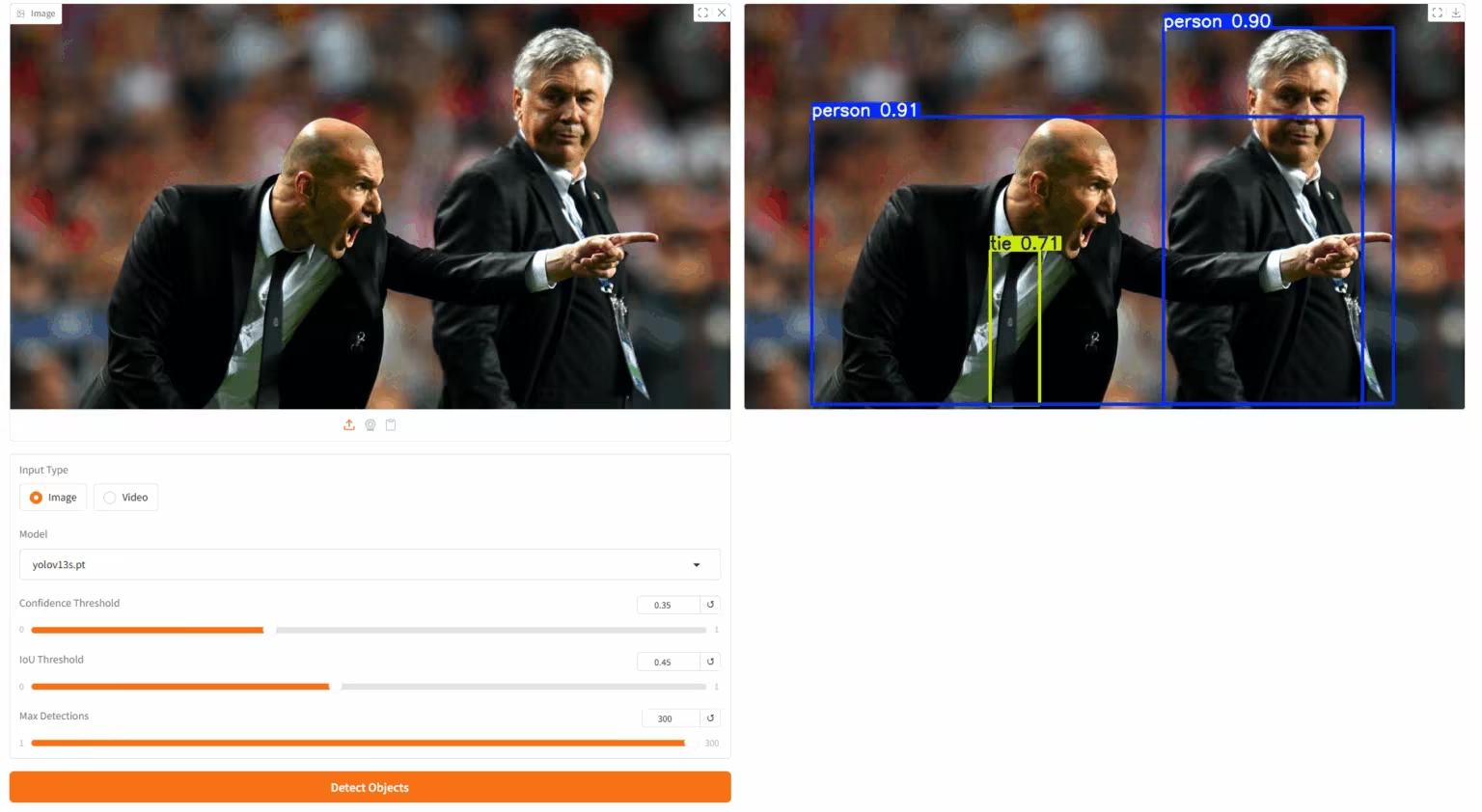
3. Bereitstellung von Yolov13 mit einem Klick
YOLOv13 ist ein Objekterkennungsmodell, das von einem gemeinsamen Forschungsteam der Tsinghua-Universität, der Technischen Universität Taiyuan, der Xi’an Jiaotong-Universität und weiterer Universitäten entwickelt wurde. Aufbauend auf den Vorteilen der Echtzeiterkennung der YOLO-Serie führt dieses Modell eine Reihe neuer Mechanismen ein, darunter Hypergraph-Erweiterung, semantische Modellierung höherer Ordnung und ressourcenschonende Strukturrekonstruktion. Es erzielt führende Ergebnisse auf gängigen Datensätzen wie MS COCO und Pascal VOC und beweist damit eine stärkere Generalisierungsfähigkeit und praktische Anwendbarkeit.
Online ausführen:https://go.hyper.ai/PAcy1
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. Jede Aktivierung verstärkt: Skalierung des allgemeinen Reasoners auf 1 Billion Open Language Foundation
Dieser Artikel stellt Ling 2.0 vor, ein Sprachgrundlagenmodell für serialisierte Schlussfolgerungsaufgaben, das auf dem Kernprinzip der „Verbesserung der Schlussfolgerungsfähigkeit mit jeder Aktivierung“ basiert. Unter einer einheitlichen Mixture-of-Experts (MoE)-Architektur kann dieses Modell von Milliarden auf Billionen Parameter skalieren, wobei hohe Sparsität, skalenübergreifende Konsistenz und Effizienz gemäß empirischen Skalierungsgesetzen im Vordergrund stehen.
Link zum Artikel:https://go.hyper.ai/O4pRV
2. ThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
In diesem Beitrag wird ThinkMorph vorgestellt – ein einheitliches Modell, das anhand von 24.000 hochwertigen, verschachtelten Schlussfolgerungstrajektorien feinabgestimmt wurde und eine Vielzahl von Aufgaben mit unterschiedlichem Grad an visueller Beteiligung abdeckt. Es ist in der Lage, schrittweise fortschreitende Graph-Text-Schlussfolgerungsschritte zu generieren und eine kohärente semantische Logik beizubehalten, während visuelle Inhalte manipuliert werden.
Link zum Artikel:https://go.hyper.ai/AGtSS
3. Lassen Sie sich nicht von der VLA blenden: Visuelle Darstellungen für die OOD-Generalisierung ausrichten
Diese Studie untersuchte systematisch die Erhaltung von Repräsentationen während der Feinabstimmung von Modellen der visuellen Sprache und Handlung (VLA-Modellen). Dabei zeigte sich, dass die direkte Feinabstimmung von Handlungen zu einer Verschlechterung der visuellen Repräsentationsleistung führt. Um diesen Effekt zu charakterisieren und zu messen, erforschten die Forschenden die verborgenen Repräsentationen von VLA-Modellen und analysierten deren Aufmerksamkeitskarten. Darüber hinaus wurden gezielte Aufgaben und Methoden entwickelt, um VLA-Modelle mit ihren entsprechenden VLM-Modellen zu vergleichen und so die durch die Feinabstimmung von Handlungen verursachten Veränderungen der visuellen Sprachfähigkeit zu isolieren.
Link zum Artikel:https://go.hyper.ai/xNU6P
4. OS-Sentinel: Auf dem Weg zu sichereren mobilen GUI-Agenten durch hybride Validierung in realistischen Arbeitsabläufen
In diesem Beitrag wird ein neuartiges hybrides Sicherheitserkennungsframework namens OS-Sentinel vorgestellt, das explizite Verstöße auf Systemebene mittels eines formalen Verifizierers erkennt und gleichzeitig Kontextrisiken und Stellvertreterverhalten mithilfe eines VLM-basierten Kontextbeurteilers bewertet.
Link zum Artikel:https://go.hyper.ai/bG6b5
5. VCode: Ein multimodaler Codierungs-Benchmark mit SVG als symbolischer visueller Darstellung
Diese Arbeit stellt VCode vor – ein Benchmark-Framework, das multimodales Verständnis in eine Codegenerierungsaufgabe umwandelt: Ausgehend von einem Bild muss das Modell SVG-Code generieren, der die symbolische Semantik für nachfolgende Inferenzprozesse bewahrt. Das Framework deckt drei Bereiche ab: allgemeines Alltagsverständnis (MM-Vet), fachspezifisches Wissen (MMMU) und Aufgaben mit Fokus auf visuelle Wahrnehmung (CV-Bench).
Link zum Artikel:https://go.hyper.ai/UNmqK
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Im Oktober 2025 zierte Demis Hassabis, CEO von Google DeepMind, das Cover der TIME 100-Liste des Time Magazine. Von AlphaGo bis AlphaFold hielt Hassabis an der wissenschaftlichen Ausrichtung von AI4S fest, doch mit der Integration von DeepMind in Google kritisierten zahlreiche Medien die kommerziellen Ambitionen und ethischen Kontroversen des Unternehmens.
Den vollständigen Bericht ansehen:https://go.hyper.ai/vSqZI
Neuphonics neuestes Open-Source-End-to-End-Sprachsynthesemodell NeuTTS-Air erzielt Bestleistungen unter den Open-Source-Modellen, insbesondere bei hyperrealistischer Synthese und Echtzeit-Inferenz. Es lässt sich zudem auf neue Anwendungsszenarien wie eingebettete Agenten und Stiltransfer übertragen, unterstützt das Klonen von 3-Sekunden-Audiosequenzen und generiert natürlich klingende Dialoge.
Den vollständigen Bericht ansehen:https://go.hyper.ai/5kAIi
Ein gemeinsames Team der ETH Zürich, des Caltech und der Universität Alberta hat ein Deep-Learning-Framework namens NOBLE entwickelt. Es ist das erste groß angelegte Deep-Learning-Framework, das seine Leistungsfähigkeit anhand experimenteller Daten aus der menschlichen Großhirnrinde validiert hat und erstmals die nichtlineare Dynamik von Neuronen direkt aus experimentellen Daten lernt. Dabei erreicht es Simulationsgeschwindigkeiten, die 4200-mal höher sind als bei herkömmlichen numerischen Lösern.
Den vollständigen Bericht ansehen:https://go.hyper.ai/oQ74B
Mercor wurde von drei Studienabbrechern im Alter von nur 22 Jahren gegründet und sammelte in weniger als drei Jahren 350 Millionen US-Dollar in einer Serie-C-Finanzierungsrunde ein, wodurch die Unternehmensbewertung auf 10 Milliarden US-Dollar stieg. Das Unternehmen reduziert die Effizienz herkömmlicher Rekrutierungsprozesse durch sein KI-gestütztes Rekrutierungsmodell auf wenige Sekunden und hat den APEX-Benchmark eingeführt, der einen neuen Standard zur Bewertung des wirtschaftlichen Werts von KI setzt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/kBj1w
Ein Forschungsteam unter der Leitung von Professor David Baker von der University of Washington hat ein Graph-Neuronales Netzwerk namens PLACER entwickelt, das die Strukturen verschiedener organischer kleiner Moleküle auf der Grundlage der atomaren Zusammensetzung und der Bindungsinformationen der kleinen Moleküle präzise generieren kann; und es kann, ausgehend von der makroskopischen Struktur von Proteinen, die detaillierten Strukturen kleiner Moleküle und Proteinseitenketten für Protein-Kleinmolekül-Docking-Aufgaben konstruieren.
Den vollständigen Bericht ansehen:https://go.hyper.ai/sisqO
Beliebte Enzyklopädieartikel
1. DALL-E
2. Hypernetzwerke
3. Pareto-Front
4. Bidirektionales Long Short-Term Memory (Bi-LSTM)
5. Reziproke Rangfusion
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Frist für den Gipfel im November
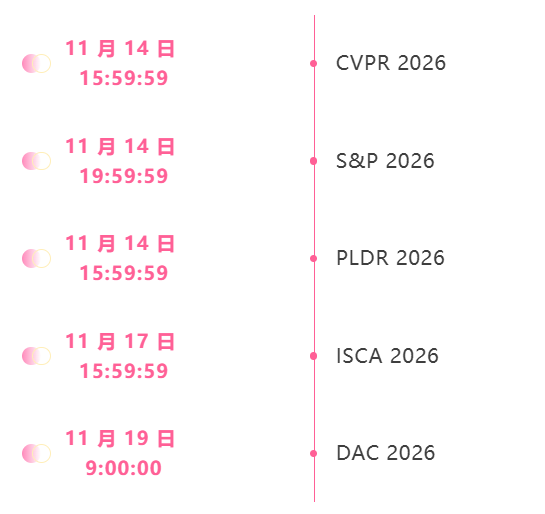
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








