Command Palette
Search for a command to run...
Ein Niedrigschwelliger Test Von Open-AutoGLM: Eine Intelligente Agentenerfahrung, Die Bildschirmverständnis Und Automatisierte Ausführung Kombiniert; Spatial-SSRL-81k: Aufbau Eines Selbstüberwachten Verbesserungspfads Für Räumliches Bewusstsein.

Während "Doubao Mobile" noch als Trend diskutiert wurde.Zhipu AI gab bekannt, dass es sein Framework für mobile intelligente Assistenten, Open-AutoGLM, als Open Source veröffentlicht hat.Es ermöglicht multimodales Verständnis und automatisierte Bedienung von Bildschirminhalten.
Im Gegensatz zu herkömmlichen mobilen AutomatisierungstoolsDer Telefonagent nutzt ein visuelles Sprachmodell, um ein tiefes semantisches Verständnis des Bildschirminhalts zu erreichen, und kombiniert dies mit intelligenten Planungsfunktionen, um Betriebsprozesse automatisch zu generieren und auszuführen.Das System steuert das Gerät über ADB (Android Debug Bridge). Nutzer müssen lediglich ihre Bedürfnisse in natürlicher Sprache beschreiben, z. B. „Xiaohongshu öffnen, um nach Essen zu suchen“, und der Telefonagent kann die Absicht automatisch analysieren, die aktuelle Benutzeroberfläche verstehen, die nächste Aktion planen und den gesamten Vorgang abschließen.
Das System ist hinsichtlich Sicherheit und Kontrollierbarkeit mit einem sensiblen Bestätigungsmechanismus ausgestattet und unterstützt die Benutzerübernahme in Szenarien, die manuelle Eingriffe erfordern, wie z. B. Anmeldung, Zahlung oder Verifizierungscodes. Dadurch wird eine sichere und zuverlässige Benutzererfahrung gewährleistet. Darüber hinaus verfügt der Phone Agent über Remote-ADB-Debugging-Funktionen und unterstützt Geräteverbindungen über WLAN oder Mobilfunknetze. Entwickler und fortgeschrittene Benutzer erhalten so flexible Fernsteuerungs- und Echtzeit-Debugging-Unterstützung.
derzeit,Open-AutoGLM, das auf diesem Framework basiert, wurde bereits in über 50 gängigen chinesischen Anwendungen eingesetzt, darunter WeChat, Taobao und Xiaohongshu.Es ist in der Lage, eine Vielzahl von alltäglichen Aufgaben zu bewältigen, von der sozialen Interaktion und dem Online-Shopping bis zum Durchsuchen von Inhalten, und entwickelt sich schrittweise zu einem intelligenten Assistenten, der alle Aspekte des Lebens der Nutzer abdeckt, einschließlich Kleidung, Essen, Wohnen und Transport.
Auf der HyperAI-Website wird jetzt „Open-AutoGLM: Ein intelligenter Assistent für mobile Geräte“ vorgestellt – schauen Sie doch mal vorbei und probieren Sie ihn aus!
Online-Nutzung:https://go.hyper.ai/QwvOU
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 8. bis 12. Dezember:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 5
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefristen im Januar: 11
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Envision Multi-Stage Event Visual Generation Dataset
Envision ist ein vom Shanghai Artificial Intelligence Laboratory veröffentlichter Datensatz aus mehreren Bild-Text-Paaren. Er dient dazu, die Fähigkeit eines Modells zu testen, kausale Zusammenhänge zu verstehen und mehrstufige Erzählungen zu realen Ereignissen zu generieren. Der Datensatz umfasst 1.000 Ereignissequenzen und 4.000 vierstufige Textvorlagen aus sechs Hauptbereichen: Naturwissenschaften und Geisteswissenschaften/Geschichte. Die Ereignismaterialien stammen aus Lehrbüchern und Online-Ressourcen, wurden von Experten ausgewählt und von GPT-4o generiert und verfeinert, um Erzählvorlagen mit klaren Kausalketten und sich schrittweise entfaltenden Phasen zu erstellen.
Direkte Verwendung:https://go.hyper.ai/xD4j6
2. DetectiumFire – Multimodaler Datensatz zur Branderkennung
DetectiumFire, ein von der Tulane University in Zusammenarbeit mit der Aalto University entwickelter Datensatz, dient der Flammenerkennung, dem visuellen Schließen und der multimodalen Datengenerierung. Er wurde in den NeurIPS 2025 Datasets and Benchmarks Track aufgenommen und soll eine einheitliche Ressource für das Training und die Evaluierung von Brandszenen in Computer-Vision- und Bildverarbeitungsmodellen bereitstellen. Der Datensatz umfasst über 145.000 hochwertige, realitätsnahe Bilder von Bränden und 25.000 Videos zum Thema Feuer.
Direkte Verwendung:https://go.hyper.ai/7Z92Z

3. Care-PD Parkinson's 3D Ganganalyse-Datensatz
CARE-PD, ein von der Universität Toronto in Zusammenarbeit mit dem Vector Institute, dem KITE Research Institute–UHN und weiteren Institutionen veröffentlichter Datensatz, ist derzeit der größte öffentlich verfügbare 3D-Gangmodelldatensatz für Parkinson-Patienten. Er wurde für die NeurIPS 2025 Datasets and Benchmarks ausgewählt und soll eine hochwertige Datengrundlage für die Vorhersage klinischer Scores, das Lernen von Gangmodellen bei Parkinson und eine einheitliche, institutionsübergreifende Analyse bieten. Der Datensatz umfasst Gangaufzeichnungen von 362 Probanden aus neun unabhängigen Kohorten an acht klinischen Einrichtungen. Alle Gangvideos und Bewegungsdaten wurden einheitlich verarbeitet und in anonymisierte SMPL-3D-Gangmodelle konvertiert.
Direkte Verwendung:https://go.hyper.ai/CH7Oi
4. PolyMath Multilingual Mathematical Inference Benchmark Dataset
PolyMath ist ein mehrsprachiger Datensatz zur Evaluierung mathematischer Argumentation, der vom Qianwen-Team von Alibaba in Zusammenarbeit mit der Shanghai Jiao Tong University entwickelt wurde. Er wurde für die NeurIPS 2025 Datasets and Benchmarks ausgewählt und zielt darauf ab, das mathematische Verständnis, die Argumentationstiefe und die sprachübergreifende Konsistenz großer Sprachmodelle unter mehrsprachigen Bedingungen systematisch zu evaluieren.
Direkte Verwendung:https://go.hyper.ai/VM5XK
5. VOccl3D 3D-Videodatensatz zur menschlichen Verdeckung
VOccl3D ist ein umfangreicher, synthetischer Datensatz der University of California, der sich auf das dreidimensionale Verständnis von Menschen in komplexen, verdeckten Szenen konzentriert. Er soll einen realistischeren Vergleichsmaßstab für die Schätzung und Rekonstruktion der menschlichen Körperhaltung sowie für multimodale Wahrnehmungsaufgaben bieten. Der Datensatz umfasst über 250.000 Bilder und etwa 400 Videosequenzen, die aus Hintergrundszenen, menschlichen Aktionen und verschiedenen Texturen zusammengesetzt sind.
Direkte Verwendung:https://go.hyper.ai/vBFc2

6. Spatial-SSRL-81k Spatial Aware Self-Supervised Dataset
Spatial-SSRL-81k ist ein selbstüberwachter Datensatz für Bild- und Sprachverarbeitung zur Förderung des räumlichen Verständnisses und räumlichen Denkens. Er wurde vom Shanghai Artificial Intelligence Laboratory in Zusammenarbeit mit der Shanghai Jiao Tong University, der Chinese University of Hong Kong und weiteren Institutionen veröffentlicht. Ziel ist es, großen Modellen räumliches Bewusstsein ohne manuelle Annotation zu verleihen und so deren Denk- und Generalisierungsleistung in multimodalen Szenarien zu verbessern.
Direkte Verwendung:https://go.hyper.ai/AfHSW

7. WenetSpeech-Chuan (Sichuan-Chongqing Dialekt-Sprachdatensatz)
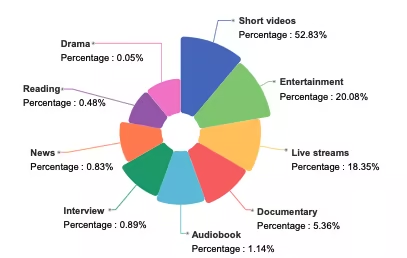
WenetSpeech-Chuan ist ein umfangreicher Sprachdatensatz mit Dialekten aus Sichuan und Chongqing, der von der Northwestern Polytechnical University in Zusammenarbeit mit Hillbeike, dem China Telecom Artificial Intelligence Research Institute und weiteren Institutionen veröffentlicht wurde. Der Datensatz umfasst neun reale Szenarien, wobei Kurzvideos 52.831 TP3T ausmachen. Die restlichen Inhalte umfassen Unterhaltung, Live-Streaming, Hörbücher, Dokumentationen, Interviews, Nachrichten, Lesungen und Hörspiele und bieten so eine äußerst vielfältige und realistische Sprachverteilung.
Direkte Verwendung:https://go.hyper.ai/dFlE2
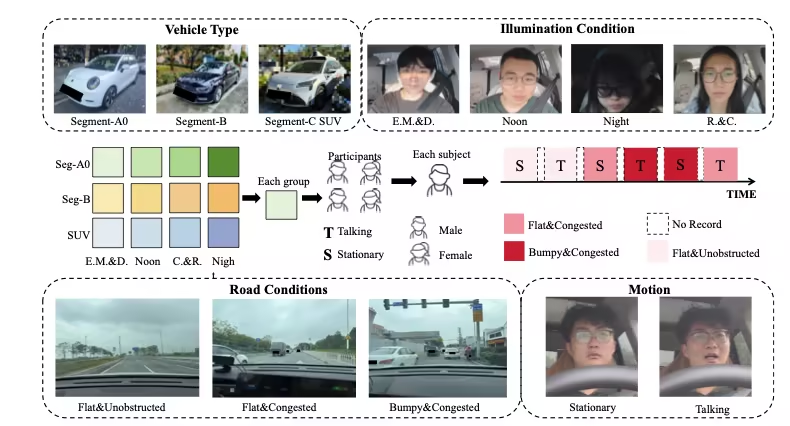
8. PhysDriver Physiologischer Testdatensatz
PhysDrive ist der erste umfangreiche multimodale Datensatz für berührungslose physiologische Messungen im Fahrzeug unter realen Fahrbedingungen. Er wurde von Institutionen wie der Hong Kong University of Science and Technology (Guangzhou), der Hong Kong University of Science and Technology und der Tsinghua-Universität veröffentlicht. PhysDrive wurde für die NeurIPS 2025 Datasets and Benchmarks ausgewählt und soll die Forschung und Evaluierung von Fahrerzustandsüberwachung, intelligenten Cockpitsystemen und multimodalen physiologischen Erfassungsmethoden unterstützen.
Direkte Verwendung:https://go.hyper.ai/4qz9T
9. MMSVGBench Multimodal Vector Graphics Generation Benchmark Dataset
MMSVG-Bench ist ein umfassender Benchmark für multimodale SVG-Generierungsaufgaben, der von der Fudan-Universität und StepFun gemeinsam entwickelt wurde. Er wurde für die NeurIPS 2025 Datasets and Benchmarks ausgewählt und soll die Lücke im Bereich der Vektorgrafikgenerierung schließen, der es an einem einheitlichen, offenen und standardisierten Testset mangelt.
Direkte Verwendung:https://go.hyper.ai/WiZCR
10. PolypSense3D Polyp Size-Aware Dataset
PolypSense3D ist ein aus verschiedenen Quellen stammender Benchmark-Datensatz, der speziell für die Tiefenmessung von Polypengrößen entwickelt wurde. Er wurde von der Hangzhou Normal University in Zusammenarbeit mit der Technischen Universität Dänemark, der Hohai University und weiteren Institutionen veröffentlicht. PolypSense3D wurde für die NeurIPS 2025 ausgewählt und soll hochwertige Trainings- und Evaluierungsressourcen für die Polypendetektion, Tiefenschätzung, Größenmessung und das Transferlernen von Simulationen in die reale Welt bereitstellen.
Direkte Verwendung:https://go.hyper.ai/SZnu6
Ausgewählte öffentliche Tutorials
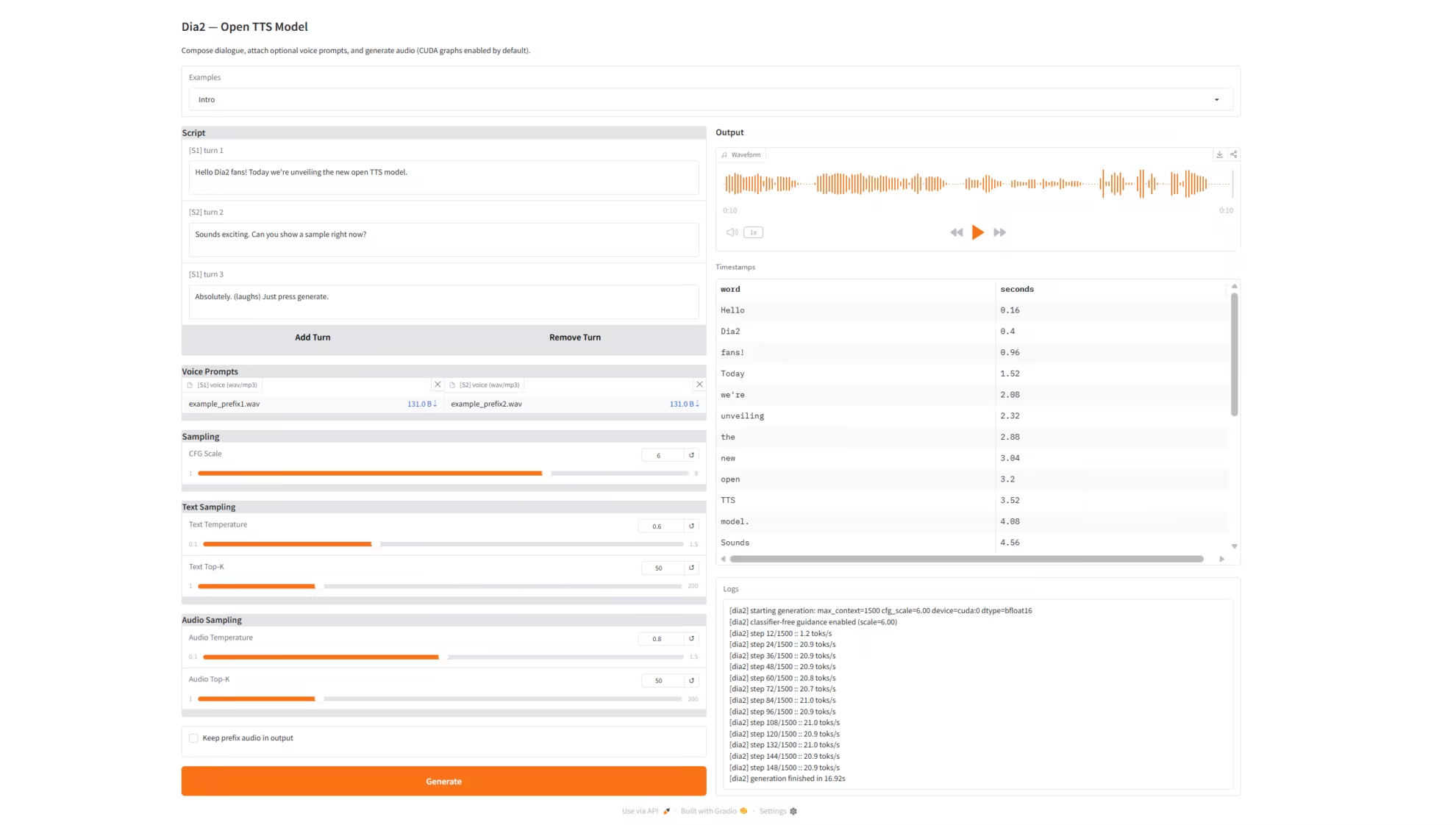
1. Dia2-TTS: Echtzeit-Sprachsynthesedienst
Dia2-TTS ist ein Echtzeit-Sprachsynthesedienst, der auf dem von nari-labs entwickelten, umfangreichen Sprachgenerierungsmodell Dia2 (Dia2-2B) basiert. Er unterstützt die Eingabe von mehrteiligen Dialogskripten, Sprachansagen mit doppelter Funktion (Präfix-Stimme) und die Steuerung des Samplings über mehrere Parameter. Über Grado bietet er eine vollständig webbasierte, interaktive Benutzeroberfläche für die hochwertige Sprachsynthese von Konversationen. Das Modell kann direkt aufeinanderfolgende, mehrteilige Dialogskripte verarbeiten und daraus natürliche, kohärente und konsistente Sprache in hoher Qualität generieren. Es eignet sich für Anwendungen wie virtuellen Kundenservice, Sprachassistenten, KI-Synchronisation und die Erstellung von Kurzfilmen.
Online ausführen:https://go.hyper.ai/Qbfni
2. Open-AutoGLM: Intelligenter Assistent für mobile Geräte
Open-AutoGLM ist ein von Zhipu AI entwickeltes Framework für intelligente mobile Assistenten, das auf AutoGLM aufbaut. Es kann Bildschirminhalte multimodal erfassen und Nutzern durch automatisierte Abläufe bei der Aufgabenerledigung helfen. Im Gegensatz zu herkömmlichen Automatisierungstools für Mobilgeräte verwendet Phone Agent ein visuelles Sprachmodell zur Bildschirmerkennung in Kombination mit intelligenten Planungsfunktionen, um Betriebsprozesse automatisch zu generieren und auszuführen.
Online ausführen:https://go.hyper.ai/QwvOU
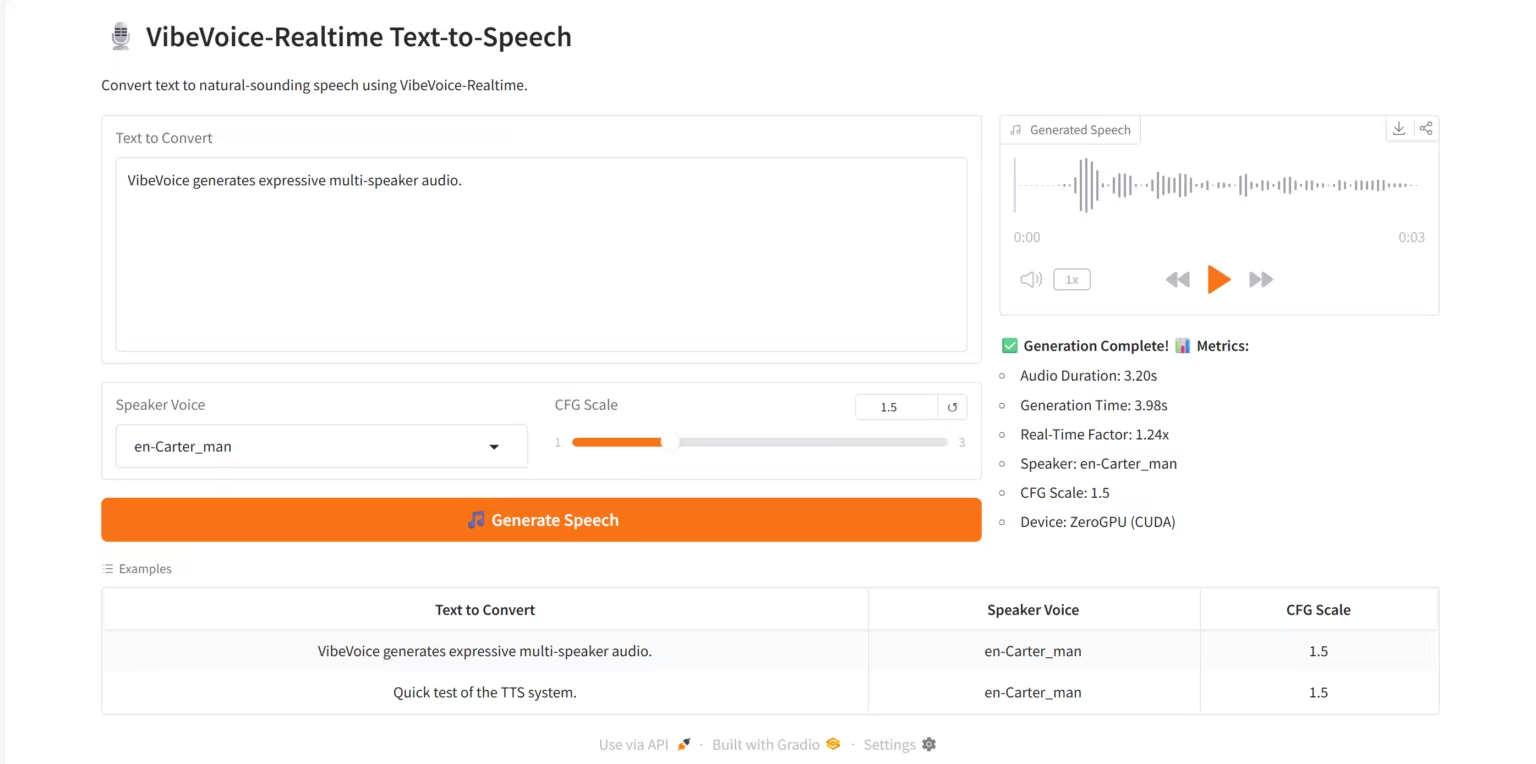
3. VibeVoice-Realtime TTS: Echtzeit-Sprachsynthesedienst
VibeVoice-Realtime TTS ist ein hochwertiges Echtzeit-Text-to-Speech-System (TTS), das auf dem von Microsoft Research entwickelten Streaming-Sprachsynthesemodell VibeVoice-Realtime-0.5B basiert. Das System unterstützt die Sprachgenerierung mit mehreren Sprechern, latenzarme Echtzeit-Inferenz und interaktive Visualisierungen auf der Grado-Webplattform.
Online ausführen:https://go.hyper.ai/RviLs
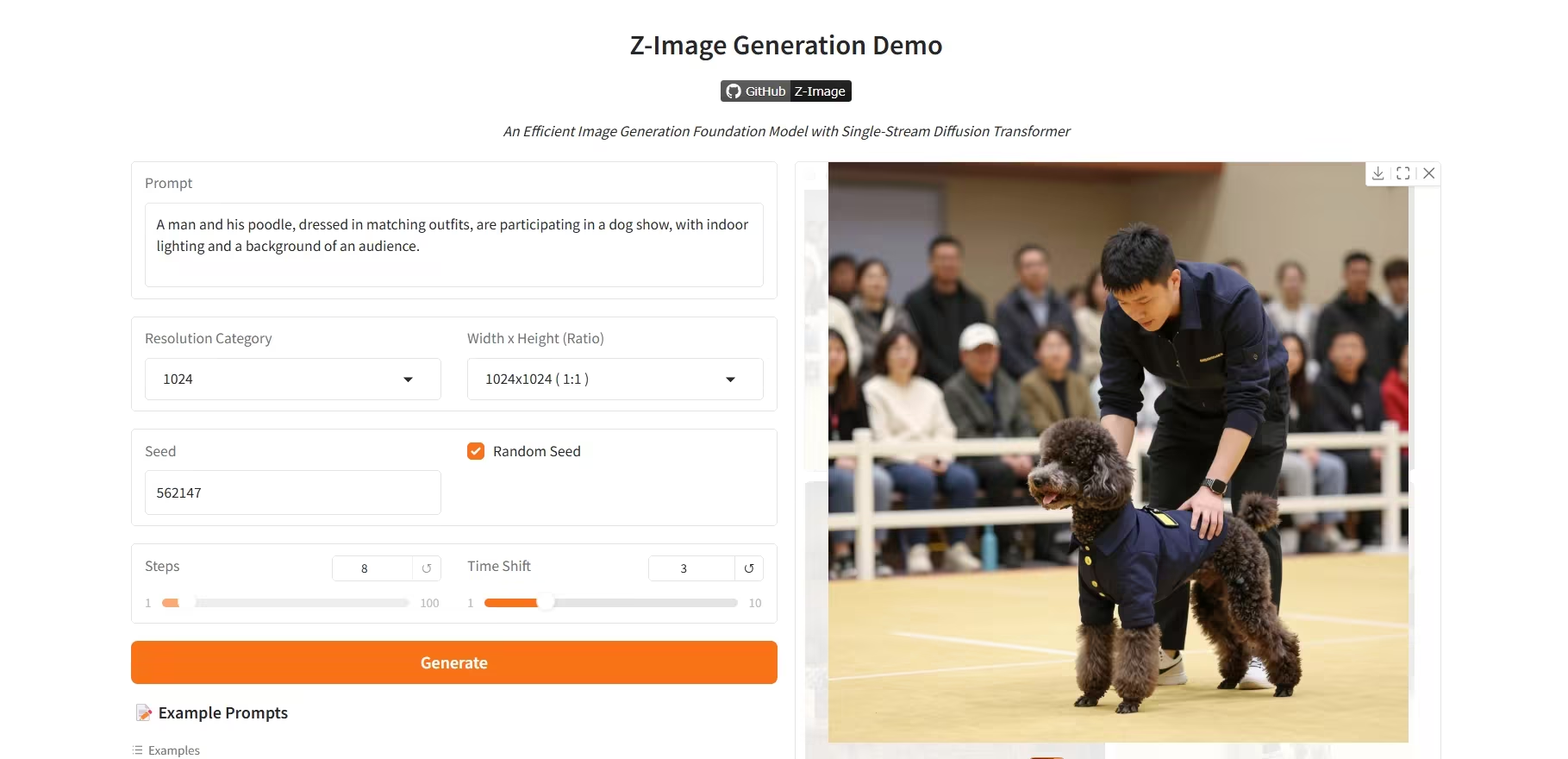
4. Z-Image-Turbo: Ein hocheffizientes 6B-Parameter-Bildgenerierungsmodell
Z-Image-Turbo ist ein hocheffizientes Bildgenerierungsmodell der neuen Generation, entwickelt vom Tongyi-Qianwen-Team von Alibaba. Mit nur 6 Byte Parametern erzielt dieses Modell eine vergleichbare Leistung wie führende proprietäre Modelle mit über 20 Byte Parametern und eignet sich besonders gut zur Erzeugung fotorealistischer Porträts in hoher Qualität.
Online ausführen:https://go.hyper.ai/R8BJF
5. Ovis-Image: Ein hochwertiges Bildgenerierungsmodell
Ovis-Image ist ein hochwertiges System zur Text-zu-Bild-Generierung (T2I), das auf dem vom AIDC-AI-Team entwickelten, hochpräzisen Text-zu-Bild-Generierungsmodell Ovis-Image-7B basiert. Das System verwendet einen Multi-Scale-Transformer-Encoder und eine autoregressive generative Architektur und erzielt herausragende Ergebnisse bei der Generierung hochauflösender Bilder, der detailgetreuen Darstellung und der Anpassung an verschiedene Bildstile.
Online ausführen:https://go.hyper.ai/NoaDw

Die Zeitungsempfehlung dieser Woche
1. Wan-Move: Bewegungsgesteuerte Videogenerierung mittels latenter Trajektorienführung
Diese Arbeit stellt Wan-Move vor, ein einfaches und skalierbares Framework, das Videogenerierungsmodelle um Bewegungssteuerung erweitert. Bisherige Methoden zur Bewegungssteuerung weisen häufig eine grobkörnige Steuerung und begrenzte Skalierbarkeit auf, was zu Ergebnissen führt, die den Anforderungen praktischer Anwendungen nicht genügen. Um diese Lücke zu schließen, ermöglicht Wan-Move eine hochpräzise und qualitativ hochwertige Bewegungssteuerung. Der Kerngedanke besteht darin, die ursprünglichen bedingten Merkmale direkt mit Bewegungserkennungsfunktionen auszustatten, um die Videogenerierung zu steuern.
Link zum Artikel:https://go.hyper.ai/h3uaG
2. Visionär: Die weltweite Modell-Fluggesellschaft, basierend auf einer WebGPU-gestützten Gaussian-Splatting-Plattform
Dieser Artikel stellt Visionary vor, eine Open-Source-Plattform für webbasierte Echtzeit-Rendering-Anwendungen, die das Echtzeit-Rendering verschiedener Gaußscher Raster- und Netztypen unterstützt. Basierend auf einer leistungsstarken WebGPU-Rendering-Engine und kombiniert mit einem pro Frame ausgeführten ONNX-Inferenzmechanismus, ermöglicht die Plattform dynamische neuronale Verarbeitung bei gleichzeitig schlankem Design und einer intuitiven Browser-Nutzung („Click-to-Run“).
Link zum Artikel:https://go.hyper.ai/NaBv3
3. Nativer paralleler Denker: Paralleles Denken durch selbstentwickeltes bestärkendes Lernen
Diese Arbeit stellt den Native Parallel Reasoner (NPR) vor, ein lehrerfreies Framework, das es großen Sprachmodellen (LLMs) ermöglicht, selbstständig echte parallele Schlussfolgerungsfähigkeiten zu entwickeln. In acht Benchmark-Tests zur Schlussfolgerungsleistung erzielt der auf dem Qwen3-4B-Modell trainierte NPR eine Leistungsverbesserung von bis zu 24,51 TP3T und eine maximale Steigerung der Inferenzgeschwindigkeit um das 4,6-Fache.
Link zum Artikel:https://go.hyper.ai/KWiZQ
4. TwinFlow: Realisierung der Ein-Schritt-Generierung auf großen Modellen mit selbstadversariellen Flows
Diese Arbeit stellt TwinFlow vor, ein Framework für das Training generativer Modelle. Im Gegensatz zu herkömmlichen adversariellen Netzwerken, die während des Trainings auf ein festes, vortrainiertes Lehrermodell verzichten, eignet sich TwinFlow besonders für die Entwicklung umfangreicher und hocheffizienter generativer Modelle. Bei der Text-zu-Bild-Generierung erzielt das Framework einen GenEval-Wert von 0,83 mit nur einer Funktionsauswertung erster Ordnung (1-NFE) und übertrifft damit deutlich starke Basismodelle wie SANA-Sprint (ein Framework basierend auf GAN-Verlustfunktionen) und RCGM (ein Framework basierend auf Konsistenzmechanismen).
Link zum Artikel:https://go.hyper.ai/l1nUp
5. Jenseits der Realität: Imaginäre Erweiterung von Rotationspositionseinbettungen für Langzeit-LLMs
Rotational Positional Encoding (RoPE), bei dem die Abfrage- und Schlüsselvektoren in der komplexen Ebene rotiert werden, hat sich als Standardmethode zur Kodierung der Sequenzreihenfolge in großen Sprachmodellen (LLMs) etabliert. Bestehende Standardimplementierungen verwenden jedoch lediglich den Realteil des komplexen Skalarprodukts zur Berechnung von Aufmerksamkeitswerten und ignorieren den Imaginärteil, der wichtige Phaseninformationen enthält. Dies kann zum Verlust entscheidender Details relativer Beziehungen bei der Modellierung von Abhängigkeiten über größere Distanzen führen. In diesem Beitrag wird eine Erweiterungsmethode vorgeschlagen, die die zuvor vernachlässigten Informationen des Imaginärteils wieder einbezieht. Diese Methode nutzt die vollständige komplexe Repräsentation, um einen zweikomponentigen Aufmerksamkeitswert zu konstruieren.
Link zum Artikel:https://go.hyper.ai/iGTw6
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
1. Ein 20-Milliarden-Dollar-Glücksspiel! xAI setzt Musks massives Kapital auf OpenAI, wobei die zukünftige kommerzielle Tragfähigkeit die größte Unbekannte bleibt.
Im Jahr 2025 erlebte xAI dank Musks starker Initiative einen beispiellosen Kapitalzuwachs, doch die Kommerzialisierung blieb stark von den Ökosystemen von X und Tesla abhängig, wobei Cashflow und regulatorischer Druck gleichzeitig stiegen. Groks Strategie der „schwachen Ausrichtung“ erwies sich angesichts immer strengerer globaler Regulierungen als zunehmend riskant, und die enge Verflechtung mit X schwächte zudem das unabhängige Wachstumspotenzial. Angesichts von Kostenungleichgewichten, begrenzten Geschäftsmodellen und regulatorischen Hürden schwankt die Zukunft von xAI weiterhin zwischen den Strategien der Branchenriesen, politischen Veränderungen und Musks persönlichem Willen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/NmLi4
2. Vollständiges Programm | Shanghai Innovation Lab, TileAI, Huawei, Advanced Compiler Lab und AI9Stars treffen sich in Shanghai zu einer eingehenden Analyse des gesamten Prozesses der Betreiberoptimierung.
Der achte Meet AI Compiler Technical Salon findet am 27. Dezember in der Shanghai Innovation Academy statt. Experten der Shanghai Innovation Academy, der TileAI Community, von Huawei HiSilicon, des Advanced Compiler Lab und der AI9Stars Community präsentieren Einblicke entlang der gesamten Technologiekette – vom Software-Stack-Design und der Operatorentwicklung bis hin zur Leistungsoptimierung. Zu den Themen gehören die ökosystemübergreifende Interoperabilität von TVM, die Optimierung der Fusionsoperatoren von PyPTO, latenzarme Systeme mit TileRT, wichtige Optimierungstechniken für Triton auf verschiedenen Architekturen sowie die Operatoroptimierung für AutoTriton. Der gesamte technische Weg von der Theorie zur Implementierung wird so umfassend dargestellt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/xpwkk
3. Online-Tutorial | SAM 3 erreicht konzeptbasierte Segmentierung mit doppelter Leistungssteigerung und verarbeitet 100 Erkennungsobjekte in 30 Millisekunden
Obwohl die Modelle SAM und SAM 2 bedeutende Fortschritte bei der Bildsegmentierung erzielt haben, konnten sie bisher nicht alle Instanzen eines Konzepts im Eingabeinhalt automatisch erkennen und segmentieren. Um diese Lücke zu schließen, veröffentlichte Meta die neueste Version, SAM 3. Diese neue Version übertrifft nicht nur die Leistung ihrer Vorgänger bei der cueable visuellen Segmentierung (PVS) deutlich, sondern setzt auch einen neuen Standard für die cueable Konzeptsegmentierung (PCS).
Den vollständigen Bericht ansehen:https://go.hyper.ai/YfmLc
4. Einem interdisziplinären Team der Carnegie Foundation gelang es, mithilfe eines Random-Forest-Modells auf Basis von 406 Proben Spuren von Leben aus der Zeit vor 3,3 Milliarden Jahren zu erfassen.
Die Carnegie Institution for Science in den Vereinigten Staaten hat in Zusammenarbeit mit zahlreichen Universitäten weltweit ein interdisziplinäres Team gebildet, um eine „Technologiefusionslösung“ aus Pyrolyse-Gaschromatographie-Massenspektrometrie und überwachtem maschinellem Lernen zu verfeinern, mit der sich uralte Spuren des Lebens in chaotischen Molekülfragmenten erfassen lassen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/CNPMQ
5. Veranstaltungszusammenfassung | Die Peking-Universität, die Tsinghua-Universität, Zilliz und MoonBit diskutieren über Open Source und behandeln dabei Videogenerierung, visuelles Verständnis, Vektordatenbanken und KI-native Programmiersprachen.
HyperAI, als Mitveranstalter der COSCon'25, veranstaltete am 7. Dezember das „Industry-Research Open Source Collaboration Forum“. Dieser Artikel fasst die wichtigsten Punkte der ausführlichen Präsentationen von vier Referenten zusammen. Die vollständigen Präsentationen werden wir später auch als Videos zur Verfügung stellen – bleiben Sie also gespannt!
Den vollständigen Bericht ansehen:https://go.hyper.ai/XrCEl
Beliebte Enzyklopädieartikel
1. Bidirektionales Long Short-Term Memory (Bi-LSTM)
2. Wahrheitsgehalt
3. Layoutsteuerung (Layout-zu-Bild)
4. Verkörperte Navigation
5. Bilder pro Sekunde (FPS)
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Januar-Frist für die Top-Konferenz

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1800 öffentliche Datensätze
* Enthält über 600 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 600 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








