Command Palette
Search for a command to run...
Enthüllung Von KI-Inferenz: OpenAIs Sparse-Modell Macht Neuronale Netze Erstmals Transparent; Vorhersage Des Kalorienverbrauchs: Präzise Energiedaten in Fitnessmodelle Einfließen Lassen

Originalartikel von Lin Jiamin HyperAI14. Januar 2026, 17:06 UhrPeking
In den letzten Jahren haben große Sprachmodelle rasante Fortschritte erzielt, doch ihre internen Entscheidungsprozesse bleiben eine tief verwurzelte „Black Box“, die schwer nachzuvollziehen und zu verstehen ist. Dieses grundlegende Problem behindert den zuverlässigen Einsatz von KI in risikoreichen Bereichen wie dem Gesundheitswesen und dem Finanzsektor erheblich.Wie der Denkprozess eines Modells transparent und nachvollziehbar gestaltet werden kann, bleibt eine zentrale, ungelöste Frage.
Auf dieser GrundlageOpenAI veröffentlichte im Dezember 2025 Circuit Sparsity, ein großes Sprachmodell mit 0,4 Milliarden Parametern. Es verwendet die Circuit-Sparsity-Technologie, um 99,9% Gewichte auf Null zurückzusetzen und so eine interpretierbare spärliche Berechnungsarchitektur zu konstruieren.Dieses Modell durchbricht die Grenzen der „Black-Box“-Entscheidungsfindung traditioneller Transformer und ermöglicht die schichtweise Analyse des KI-Inferenzprozesses. Im Kern transformiert es herkömmliche dichte neuronale Netze mithilfe einer einzigartigen Trainingsmethode in strukturierte, dünnbesetzte „Schaltkreise“.
*Dynamische erzwungene SparsitätAnders als bei herkömmlichen Methoden wird bei jedem Trainingsschritt ein "dynamisches Pruning" durchgeführt, wobei in jeder Runde nur eine sehr kleine Anzahl von Gewichten mit dem größten Absolutwert (z. B. 0,1%) beibehalten und der Rest auf Null gesetzt wird. Dadurch wird das Modell gezwungen, von Anfang an mit minimaler Konnektivität zu arbeiten.
*Sparsamkeit aktivierenDurch die Einführung von Aktivierungsfunktionen an Schlüsselstellen wie Aufmerksamkeitsmechanismen tendiert der Output von Neuronen zu einem diskreten Zustand von „entweder/oder“, wodurch klare Informationskanäle in spärlichen Netzwerken gebildet werden.
*Kundenspezifische KomponentenRMSnorm wird anstelle von LayerNorm verwendet, um die Zerstörung der Sparsity zu verhindern; außerdem wird eine Bigramm-Lookup-Tabelle eingeführt, um einfache Wortvorhersagen zu handhaben, sodass sich das Hauptnetzwerk stärker auf komplexe Logik konzentrieren kann.
Das mit der oben beschriebenen Methode trainierte Modell bildet spontan funktional definierte und auflösbare „Schaltkreise“. Jeder Schaltkreis ist für eine spezifische Teilaufgabe zuständig. Forscher können klar erkennen, dass einige Neuronen speziell zur Erkennung von einfachen Anführungszeichen verwendet werden, während andere als logische „Zähler“ fungieren. Im Vergleich zu herkömmlichen dichten Modellen ist die Anzahl der aktiven Knoten, die zur Erfüllung derselben Aufgabe benötigt werden, deutlich reduziert.Die dazugehörige „Brückennetzwerk“-Technologie versucht, die aus spärlichen Schaltkreisen gewonnenen Interpretationen auf leistungsstarke dichte Modelle wie GPT-4 zurückzubilden und bietet zudem ein potenzielles Werkzeug zur Analyse bestehender großer Modelle.
Auf der HyperAI-Website findet ihr jetzt „Circuit Sparsity: OpenAI's New Open Source Sparse Model“. Schaut doch mal vorbei und probiert es aus!
Online-Nutzung:https://go.hyper.ai/WgLQc
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 5. bis 9. Januar:
* Hochwertige öffentliche Datensätze: 8
* Eine Auswahl hochwertiger Tutorials: 4
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadlines im Januar: 9
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. MCIF Multimodal Cross-Language Instruction Following Dataset
MCIF ist ein mehrsprachiger, multimodaler, manuell annotierter Evaluierungsdatensatz, der auf wissenschaftlichen Vorträgen basiert und 2025 von der Fondazione Bruno Kessler in Zusammenarbeit mit dem Karlsruher Institut für Technologie und Translated veröffentlicht wurde. Ziel ist die Evaluierung der Fähigkeit multimodaler großer Sprachmodelle, Anweisungen in sprachübergreifenden Szenarien zu verstehen und auszuführen, sowie ihrer Fähigkeit, Sprach-, Bild- und Textinformationen für logische Schlussfolgerungen zu integrieren.
Direkte Verwendung:https://go.hyper.ai/SyUiL
2. TxT360-3efforts Multi-Task Inference Dataset
TxT360-3efforts ist ein massiv großer Trainingsdatensatz für Sprachmodelle zum überwachten Feinabstimmen (SFT), der 2025 von der Mohamed bin Zayed Universität für Künstliche Intelligenz veröffentlicht wurde. Er dient dazu, drei Inferenzstärken des Modells mithilfe von Chatvorlagen zu steuern.
Direkte Verwendung:https://go.hyper.ai/fMEbf
3. Datensatz zur Röntgen-Schmuggelware-Erkennung
Der Datensatz zur Erkennung von Schmuggelware mittels Röntgenaufnahmen wurde 2025 von der Pädagogischen Universität Südchina in Zusammenarbeit mit der Polytechnischen Universität Hongkong und der Universität Saskatchewan veröffentlicht. Er dient der Verbesserung der Erkennungsleistung von Modellen in komplexen und detailreichen Sicherheitsbildern und adressiert insbesondere reale Probleme wie Klassenungleichgewicht und Stichprobenknappheit.
Direkte Verwendung:https://go.hyper.ai/ppXub
4. MCD-rPPG Multi-Kamera-Fernphotoplethysmographie-Datensatz
MCD-rPPG ist ein Multi-Kamera-Videodatensatz, der 2025 vom Sber AI Lab veröffentlicht wurde. Der Datensatz besteht aus synchronisierten Videos und Biosignaldaten, die von 600 Probanden in verschiedenen Zuständen aufgenommen wurden, und ist für die Durchführung von Remote-Photoplethysmographie (rPPG) und die Schätzung von Gesundheitsbiomarkern konzipiert.
Direkte Verwendung:https://go.hyper.ai/6KY40
5. LongBench-Pro Long Context Comprehensive Evaluation Dataset
LongBench-Pro ist ein Datensatz zur Evaluierung von Sprachmodellen für lange Kontexte. Er wurde entwickelt, um die Fähigkeit eines Modells, lange Texte unter verschiedenen Kontextlängen, Aufgabentypen und Laufzeitbedingungen zu verstehen und zu verarbeiten, systematisch zu bewerten.
Direkte Verwendung:https://go.hyper.ai/7esQI
6. Datensatz „Menschliche Gesichter“
Human Faces ist ein Datensatz, der 2025 für Computer-Vision-Aufgaben im Bereich Gesichter veröffentlicht wurde. Er zielt darauf ab, qualitativ hochwertige, gut strukturierte Bilddaten für Anwendungen wie Gesichtserkennung, Detektion, Ausdrucksanalyse und generative Modellierung bereitzustellen.
Direkte Verwendung:https://go.hyper.ai/9WlDl

7. Datensatz zur Vorhersage des Kalorienverbrauchs
Die Kalorienverbrauchsprognose ist ein Datensatz für überwachtes Lernen zur Vorhersage des Energieverbrauchs beim Sport. Er nutzt die physiologischen Merkmale und den Trainingszustand einer Person, um die Anzahl der während eines Trainings verbrannten Kalorien vorherzusagen.
Direkte Verwendung:https://go.hyper.ai/o6X59
8. MapTrace Pfadverfolgungsdatensatz
MapTrace ist ein umfangreicher Datensatz zur Nachverfolgung synthetischer Karten, der 2025 von Google in Zusammenarbeit mit der University of Pennsylvania veröffentlicht wurde. Ziel des Datensatzes ist die Verbesserung der räumlichen Detailgenauigkeit und der Pfadplanungsfähigkeiten multimodaler großer Sprachmodelle (MLLMs) in Kartenszenen. Hauptziel ist es, Modelle so zu trainieren, dass sie pixelgenaue, durchgehende und begehbare Wege vom Start- zum Zielpunkt generieren.
Direkte Verwendung:https://go.hyper.ai/BGHUu
Ausgewählte öffentliche Tutorials
1. Schaltungssparsamkeit: Das neue Open-Source-Sparse-Modell von OpenAI
Circuit-Sparsity ist ein von OpenAI veröffentlichtes Sprachmodell mit 0,4 Milliarden Parametern. Es nutzt die Circuit-Sparsity-Technologie, indem es 99,9% Gewichte auf Null setzt, um eine interpretierbare, spärliche Rechenarchitektur zu erstellen. Dadurch werden die Einschränkungen der „Black-Box“-Entscheidungsfindung traditioneller Transformer überwunden und die KI-Inferenz Schicht für Schicht analysiert. Das mit dem Modell veröffentlichte Streamlit-Toolkit bietet die „Aktivierungsbrücken“-Technologie, mit der Forscher interne Signalwege verfolgen, die zugehörigen Schaltkreise analysieren und die Leistungsunterschiede zwischen spärlichen und dichten Modellen vergleichen können.
Online ausführen:https://go.hyper.ai/zui8w
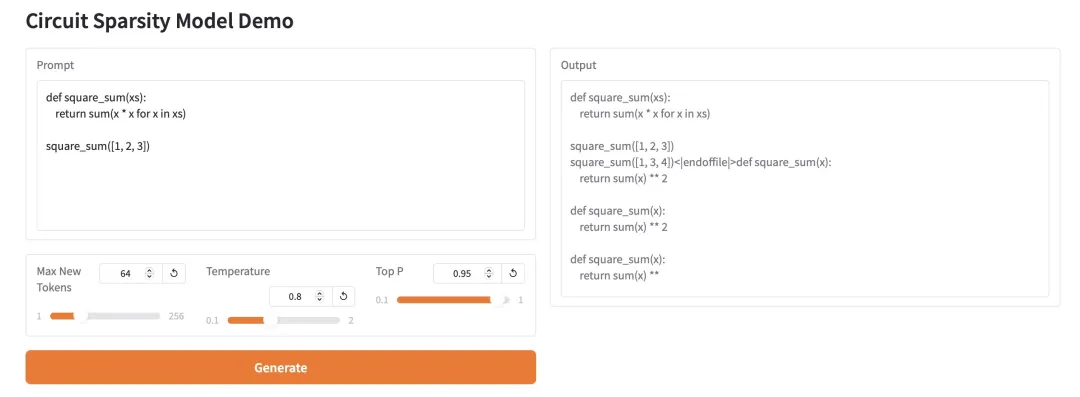
2. HY-MT1.5-1.8B: Mehrsprachiges neuronales maschinelles Übersetzungsmodell
HY-MT1.5-1.8B ist ein mehrsprachiges maschinelles Übersetzungsmodell mit 1,8 Milliarden Parametern, das vom Hunyuan-Team von Tencent entwickelt wurde. Basierend auf der einheitlichen Transformer-Architektur unterstützt es die Übersetzung zwischen 33 Sprachen und 5 ethnischen Sprachen/Dialekten und ist für reale Anwendungsszenarien wie gemischte Sprachen und Terminologiekontrolle optimiert. Bei einer Übersetzungsqualität, die nahezu der des 7B-Modells entspricht, verfügt dieses Modell nur über ein Drittel der Parameteranzahl, unterstützt den quantitativen Einsatz und die Integration in das HuggingFace-Ökosystem und eignet sich für effiziente und kostengünstige mehrsprachige Online-Übersetzungsdienste.
Online ausführen:https://go.hyper.ai/I0pdR
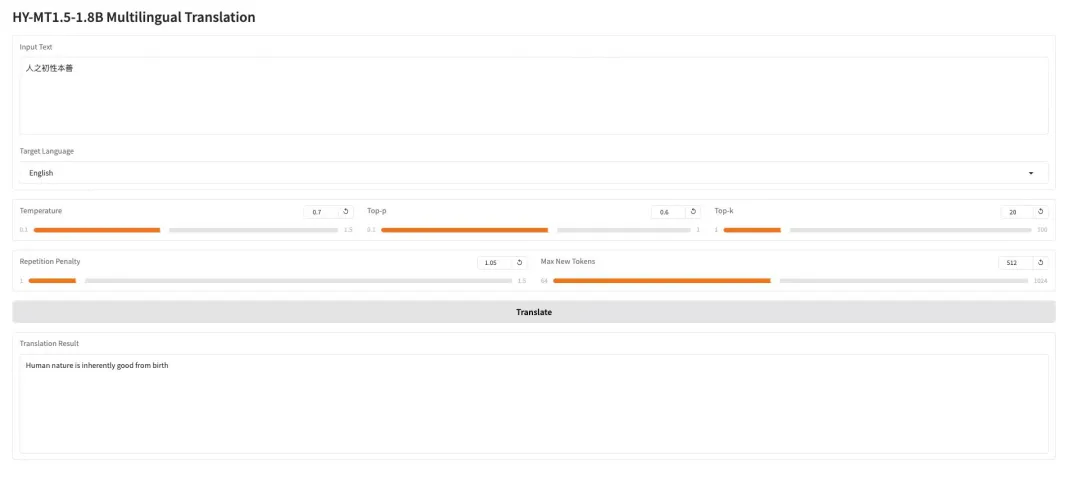
3. AWPortrait-Z Portrait Art LoRA
AWPortrait-Z ist ein auf LoRa-Technologie basierendes Modell zur Porträtoptimierung. Als Plugin integriert es sich in gängige textbasierte Bilddiffusionsmodelle und verbessert die Realitätsnähe und fotorealistische Qualität der generierten Porträts deutlich, ohne dass das Basismodell neu trainiert werden muss. Das Modell optimiert insbesondere die Darstellung von Gesichtsstruktur, Hauttextur und Beleuchtung und erzielt so natürlichere und feinere Effekte. Es eignet sich ideal für die Erstellung von Porträts und Bildkompositionen, die fotorealistischen Realismus erfordern.
Online ausführen:https://go.hyper.ai/wRjIp
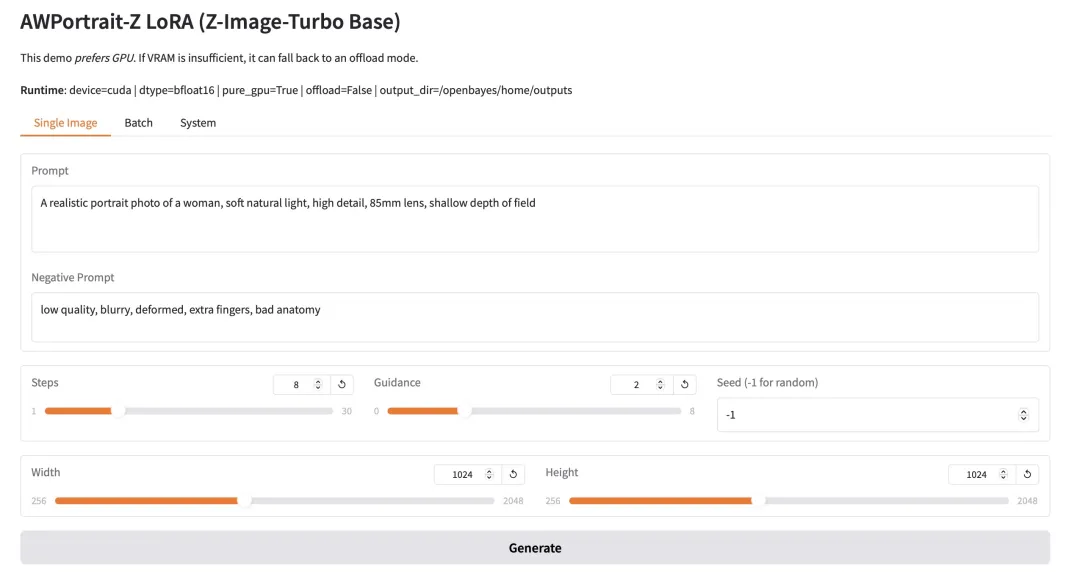
4. Granite-4.0-h-small: Eine Komplettlösung für mehrsprachige Dialog- und Codierungsaufgaben.
Granite-4.0-h-small ist ein von IBM entwickeltes Modell zur Feinabstimmung von Kontextinstruktionen mit 3,2 Milliarden Parametern. Es basiert auf einem Basismodell, integriert Open-Source- und synthetische Daten und verwendet überwachtes Feinabstimmungsverfahren, Reinforcement-Learning-Ausrichtung und Modellfusionstechniken. Dieses Modell zeichnet sich durch hervorragende Befehlskonformität und Werkzeugaufruffähigkeit aus, verwendet ein strukturiertes Dialogformat und ist für hocheffiziente Unternehmensanwendungen optimiert.
Online ausführen:https://go.hyper.ai/1HhB9
Die Zeitungsempfehlung dieser Woche
1. mHC: Mannigfaltigkeitsbeschränkte Hyperkonnektion
Diese Arbeit stellt Manifold-Constrained Hyper-Connections (mHC) vor, ein allgemeines Framework, das die Identitätsabbildungseigenschaft von HC wiederherstellt, indem es den Restverbindungsraum von HC auf eine spezifische Mannigfaltigkeit projiziert und gleichzeitig durch rigorose Infrastrukturoptimierung Recheneffizienz gewährleistet. Experimentelle Ergebnisse zeigen, dass mHC bei groß angelegten Trainingsdatensätzen hervorragend abschneidet und nicht nur spürbare Leistungsverbesserungen, sondern auch eine bemerkenswerte Skalierbarkeit aufweist. Wir gehen davon aus, dass mHC als flexible und praktische Erweiterung von HC zu einem tieferen Verständnis des Topologiedesigns beitragen und vielversprechende neue Wege für die Weiterentwicklung von Basismodellen eröffnen wird.
Link zum Artikel:https://go.hyper.ai/ZePnH
2. Youtu-LLM: Das Potenzial nativer intelligenter Agenten in leichtgewichtigen großen Sprachmodellen freisetzen
Die Autoren stellen Youtu-LLM vor, ein schlankes Sprachmodell mit 1,96 Milliarden Parametern, entwickelt vom Youtu-LLM-Team. Durch das Vortraining von Grund auf mit einem auf „Common Sense-STEM-Agent“ basierenden Curriculum erzielt es Bestleistungen unter den Modellen mit weniger als zwei Milliarden Parametern. Dieses Modell integriert eine kompakte Multi-Latency-Attention-Architektur, einen STEM-orientierten Tokenizer und eine skalierbare Pipeline zur Generierung hochwertiger Agenten-Trajektoriendaten in Bereichen wie Mathematik, Programmierung, Deep Learning und Werkzeugnutzung. Dadurch kann das Modell native Planungs-, Reflexions- und Handlungsfähigkeiten internalisieren und übertrifft größere Modelle in Agenten-Benchmarks deutlich, während es gleichzeitig starke allgemeine Argumentations- und Langzeitkontextualitätsfähigkeiten beibehält.
Link zum Artikel:https://go.hyper.ai/gitUc
3. Youtu-LLM: Das Potenzial nativer intelligenter Agenten in leichtgewichtigen großen Sprachmodellen freisetzen
Diese Arbeit erläutert zunächst Definition und Funktion des Gedächtnisses, indem sie dessen Entwicklung von der kognitiven Neurowissenschaft über große Sprachmodelle bis hin zu intelligenten Agenten nachzeichnet. Anschließend werden Klassifizierungssystem, Speichermechanismus und der gesamte Lebenszyklus des Gedächtnisses aus biologischer und künstlicher Perspektive verglichen und analysiert. Darauf aufbauend werden gängige Benchmarks zur Bewertung des Gedächtnisses intelligenter Agenten systematisch untersucht. Des Weiteren werden Sicherheitsaspekte von Gedächtnissystemen aus Angriffs- und Verteidigungsperspektive beleuchtet. Abschließend werden zukünftige Forschungsrichtungen aufgezeigt, die sich auf die Entwicklung multimodaler Gedächtnissysteme und Mechanismen zum Kompetenzerwerb konzentrieren.
Link zum Artikel:https://go.hyper.ai/01H6H
4. Dem Gedanken freien Lauf lassen: Intelligente Agenten im Kontext der Rockmusik entwickeln und das ROME-Modell innerhalb eines offenen Lernökosystems für intelligente Agenten schaffen.
Die Autoren stellen ROME vor, ein Open-Source-Agentenmodell, das auf dem Genetic Learning Ecosystem (ALE) basiert. Dieses Framework integriert die Sandbox-Orchestrierung von ROCK, die Optimierung nach dem Training von ROLL und die kontextsensitive Agentenausführung der iFlow CLI. Es erzielt Bestleistungen auf Terminal-Bench 2.0 und SWE-bench Verified, indem es semantischen Interaktionsblöcken mithilfe eines neuartigen Policy-Optimierungsalgorithmus (IPA) Punkte zuweist. ROME unterstützt den Einsatz in realen Umgebungen und ermöglicht so die Entwicklung skalierbarer, sicherer und produktionsreifer Agenten-Workflows.
Link zum Artikel:https://go.hyper.ai/UaAXZ
5. Technischer Bericht zu IQuest-Coder-V1
Diese Arbeit stellt eine neuartige Familie von großen Sprachmodellen (LLMs) vor: die IQuest-Coder-V1-Serie (7B/14B/40B/40B-Loop). Im Gegensatz zu herkömmlichen statischen Code-Repräsentationen schlagen die Autoren ein mehrstufiges, auf dem Codefluss basierendes Trainingsparadigma vor, das die Entwicklung der Softwarelogik in verschiedenen Phasen der Pipeline dynamisch erfasst. Das Modell wird mithilfe einer evolutionären Trainingspipeline erstellt. Die Veröffentlichung der IQuest-Coder-V1-Serie wird den Forschungsfortschritt im Bereich autonomer Codeintelligenz und realer intelligenter Agentensysteme maßgeblich voranbringen.
Link zum Artikel:https://go.hyper.ai/DBYN7
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
1. NVIDIA und andere haben Klimadaten für 18.000 Jahre generiert und die Methode der Langzeitdestillation vorgeschlagen, die eine langfristige Wettervorhersage mit nur einem einzigen Berechnungsschritt ermöglicht.
Ein Forschungsteam von NVIDIA Research hat in Zusammenarbeit mit der University of Washington eine neue Methode zur Langzeitprognose entwickelt. Der Kern besteht darin, ein autoregressives Modell, das realistische atmosphärische Variabilität erzeugen kann, als „Lehrer“ zu nutzen, um durch kostengünstige und schnelle Simulation große Mengen synthetischer Wetterdaten zu generieren. Diese Daten dienen anschließend zum Trainieren eines probabilistischen „Schülermodells“. Das Schülermodell erstellt Langzeitprognosen in einem einzigen Berechnungsschritt, wodurch die Akkumulation iterativer Fehler vermieden und die komplexen Herausforderungen der Datenkalibrierung umgangen werden. Erste Experimente zeigen, dass das so trainierte Schülermodell vergleichbare Ergebnisse wie das integrierte Prognosesystem des ECMWF in der S2S-Vorhersage liefert und seine Leistung mit zunehmendem Volumen synthetischer Daten weiter verbessert. Dies verspricht zuverlässigere und wirtschaftlichere Klimaprognosen in der Zukunft.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Ljebq
2. Jensen Huangs jüngster Vortrag: 5 Innovationen, erstmals veröffentlichte Leistungsdaten von Rubin; vielfältige Open-Source-Lösungen für Agenten, Roboter, autonomes Fahren und KI4S
Zu Beginn des neuen Jahres startete die CES 2026 (Consumer Electronics Show), oft auch als „Tech Spring Festival Gala“ bezeichnet, in Las Vegas, USA. Obwohl Jensen Huang nicht auf der offiziellen Keynote-Liste der CES stand, war er dennoch auf verschiedenen Veranstaltungen präsent. Besonders hervorzuheben ist seine persönliche Präsentation auf der NVIDIA LIVE. In seinem kürzlich beendeten Vortrag stellte Huang, in seiner charakteristischen schwarzen Lederjacke, die Rubin-Plattform vor, die fünf Innovationen vereint, und präsentierte mehrere Open-Source-Projekte. Konkret handelt es sich um die NVIDIA Nemotron-Serie für agentenbasierte KI, die NVIDIA Cosmos-Plattform für physikalische KI, die NVIDIA Alpamayo-Serie für die Forschung im Bereich des autonomen Fahrens, den NVIDIA Isaac GR00T für Robotik und NVIDIA Clara für den biomedizinischen Bereich.
Den vollständigen Bericht ansehen:https://go.hyper.ai/YMK1J
3. Bezos, Bill Gates, Nvidia, Intel und andere haben investiert; NASA-Ingenieure leiten ein Team, das ein universelles Robotergehirn entwickeln soll, und das Unternehmen wird mit 2 Milliarden Dollar bewertet.
Während große Modelle mithilfe des Internets, Bilddatenbanken und riesigen Textmengen „unendlich wachsen“ können, befinden sich Roboter in einer anderen Welt: Daten aus der realen Welt sind extrem knapp, teuer und nicht wiederverwendbar. Um den Einschränkungen unzureichender Datenmengen und begrenzter Struktur in der physischen Welt zu begegnen, hat FieldAI einen anderen Ansatz als die gängige, auf Wahrnehmung basierende Strategie gewählt. Das Unternehmen entwickelt ein universelles Roboterintelligenzsystem, das von Grund auf auf physikalischen Beschränkungen basiert und darauf abzielt, die Generalisierungsfähigkeit und Autonomie von Robotern in realen Umgebungen zu verbessern.
Den vollständigen Bericht ansehen:https://go.hyper.ai/9T1rE
4. Vollständige Aufzeichnung | Shanghai Chuangzhi/TileAI/Huawei/Advanced Compiler Lab/AI9Stars: Tiefgehender Einblick in die Praxis der KI-Compiler-Technologie
Angesichts der stetig wachsenden Bedeutung von KI-Compiler-Technologien finden zahlreiche Forschungsarbeiten statt, die wertvolle Erkenntnisse liefern und zusammengeführt werden. Vor diesem Hintergrund fand am 27. Dezember die achte Veranstaltung „Meet AI Compiler“ statt. Fünf Experten der Shanghai Innovation Academy, der TileAI Community, von Huawei HiSilicon, dem Advanced Compiler Lab und AI9Stars präsentierten ihre Erkenntnisse entlang der gesamten Technologiekette – vom Software-Stack-Design über die Operatorentwicklung bis hin zur Leistungsoptimierung. Die Referenten demonstrierten anhand der langjährigen Forschung ihrer Teams die Implementierungsmethoden und Vor- und Nachteile verschiedener technischer Ansätze in realen Anwendungsszenarien und verliehen abstrakten Konzepten so eine konkretere Grundlage.
Den vollständigen Bericht ansehen:https://go.hyper.ai/8ytqF
5. Erzielung eines hochselektiven Substratdesigns: MIT und Harvard entdecken neuartige Protease-Spaltungsmuster mithilfe generativer KI.
Das MIT und die Harvard University haben gemeinsam CleaveNet vorgeschlagen, einen KI-basierten End-to-End-Designprozess, der das bestehende Paradigma des Proteasesubstratdesigns revolutionieren soll, indem er Hand in Hand mit prädiktiven und generativen Modellen arbeitet und völlig neue Lösungen für die damit verbundene Grundlagenforschung und biomedizinische Entwicklung bietet.
Den vollständigen Bericht ansehen:https://go.hyper.ai/tcYYZ
Beliebte Enzyklopädieartikel
1. Mensch-Maschine-Schleife (HITL)
2. Super Reciprocal Sort Fusion RRF
3. Verkörperte Navigation
4. Mehrschichtiges Perzeptron
5. Feinabstimmung der Verstärkung
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
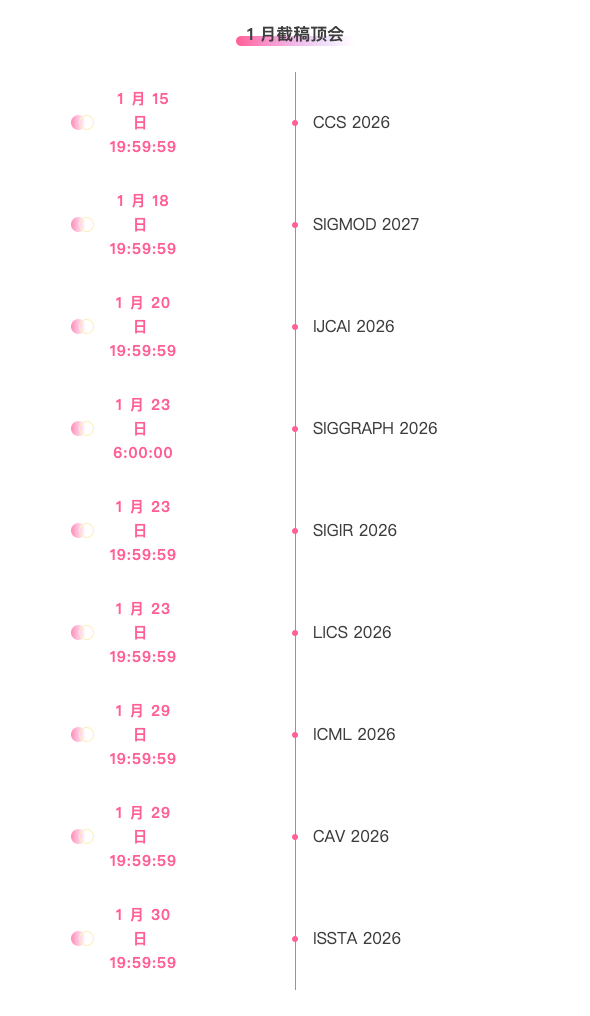
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








