Command Palette
Search for a command to run...
Bahnbrechende Technologie in Der 3D-Vision: ByteSeed Präsentiert DA3, Das Die Visuelle Raumrekonstruktion Aus Jedem Beliebigen Blickwinkel Ermöglicht; Über 70.000 Reale Industrielle Umgebungsdaten! CHIP Schließt Die Lücke in Den Industriedaten Für Die 6D-Pose-Schätzung.

Die Fähigkeit, dreidimensionale räumliche Informationen aus visuellen Reizen wahrzunehmen und zu verstehen, ist die Grundlage räumlicher Intelligenz und eine zentrale Voraussetzung für Anwendungen wie Robotik und Mixed Reality (ML). Diese grundlegende Fähigkeit hat eine Vielzahl von Aufgaben im Bereich der dreidimensionalen Bildverarbeitung hervorgebracht, darunter monokulare Tiefenschätzung, Strukturerkennung aus Bewegung, Stereosehen aus mehreren Blickwinkeln und simultane Lokalisierung und Kartierung.
Diese Aufgaben unterscheiden sich oft nur in wenigen Faktoren, wie beispielsweise der Anzahl der Eingabeansichten, und weisen daher eine hohe konzeptionelle Überschneidung auf. Dennoch besteht das derzeit vorherrschende Paradigma darin, für jede Aufgabe hochspezialisierte Modelle zu entwickeln. Die Konstruktion eines einheitlichen 3D-Verständnismodells, das mehrere Aufgaben bewältigen kann, hat sich zu einem wichtigen Forschungsschwerpunkt entwickelt.Die bestehenden Lösungen basieren jedoch typischerweise auf komplexen, individuell entworfenen Netzwerkarchitekturen und erfordern ein Training von Grund auf durch gemeinsame Optimierung mehrerer Aufgaben.Daher ist es schwierig, das Wissen und die Vorteile von groß angelegten vortrainierten Modellen vollständig zu erfassen und zu nutzen.
Auf dieser GrundlageDas Seed-Team von ByteDance hat Depth Anything 3 (DA3) veröffentlicht.Ein einzelnes, speziell trainiertes Transformer-Modell, das auf spezifischen Strahlendarstellungen basiert, kann Tiefe und Position aus jedem beliebigen Blickwinkel gemeinsam schätzen. Im Bestreben nach extremer Modellvereinfachung liefert DA3 zwei wichtige Erkenntnisse:
*Als Backbone-Netzwerk kann ein einzelner Standard-Transformator (wie zum Beispiel der Standard-DINO-Encoder) verwendet werden.Eine aufgabenspezifische Strukturanpassung ist nicht erforderlich;
*Zielvorhersage unter Verwendung nur eines einzigen Tiefenstrahls.Hervorragende Leistungen können auch ohne einen komplexen Multitasking-Lernmechanismus erzielt werden.
Das Forschungsteam entwickelte außerdem einen neuen Benchmark für visuelle Geometrie, der Kameraposenschätzung, Geometrie beliebiger Blickwinkel und visuelles Rendering umfasst. In diesem TestDA3 aktualisiert den Zustand in allen Missionen.Die Genauigkeit der Kamerapositionierung ist im Durchschnitt um 35,71 TP3T höher als bei VGGT, die geometrische Genauigkeit um 23,61 TP3T verbessert und die monokulare Tiefenschätzung dem Vorgängermodell DA2 überlegen. Experimente zeigen, dass diese minimalistische Methode ausreicht, um den visuellen Raum aus einer beliebigen Anzahl von Bildern zu rekonstruieren (unabhängig davon, ob die Kameraposition bekannt ist).
Auf der HyperAI-Website findet ihr jetzt „Depth-Anything-3: Recovering Visual Space from Any Viewpoint“, probiert es doch mal aus!
Online-Nutzung:https://go.hyper.ai/MXyML
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 15. bis 19. Dezember:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 3
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
Top-Konferenzen mit Anmeldefristen im Januar: 11
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. VideoRewardBench-Datensatz zur Evaluierung des Video-Belohnungsmodells
VideoRewardBench, eine gemeinsame Entwicklung der Universität für Wissenschaft und Technologie Chinas und des Huawei Noah's Ark Lab, ist der erste umfassende Evaluierungs-Benchmark, der die vier Kerndimensionen des Videoverständnisses abdeckt: Wahrnehmung, Wissen, Schlussfolgerung und Sicherheit. Ziel ist die systematische Bewertung der Fähigkeit von Modellen, Präferenzurteile zu fällen und die Qualität der generierten Ergebnisse in komplexen Videoverständnisszenarien zu beurteilen. Der Datensatz umfasst 1.563 annotierte Beispiele mit 1.482 verschiedenen Videos und 1.559 verschiedenen Fragen. Jedes Beispiel besteht aus einer Video-Text-Aufforderung, einer bevorzugten Antwort und einer Ablehnungsantwort.
Direkte Verwendung:https://go.hyper.ai/JIB1B
2. Arena-Write-Datensatz zur Evaluierung der Schreibgenerierung
Arena-Write ist ein Datensatz für Schreibaufgaben, der von der Singapore University of Technology and Design in Zusammenarbeit mit dem Knowledge Engineering Lab der Tsinghua-Universität veröffentlicht wurde. Er dient der Evaluierung von Modellen zur Generierung langer Texte und der systematischen Bewertung der umfassenden Fähigkeiten großer Sprachmodelle bei der Generierung langer Inhalte und komplexer Schreibaufgaben unter realistischen Anwendungsszenarien. Der Datensatz enthält 100 Benutzer-Schreibaufgaben, die jeweils aus einer realen Schreibanregung bestehen und dem entsprechenden Schreibszenario zugeordnet sind.
Direkte Verwendung:https://go.hyper.ai/4NQdD
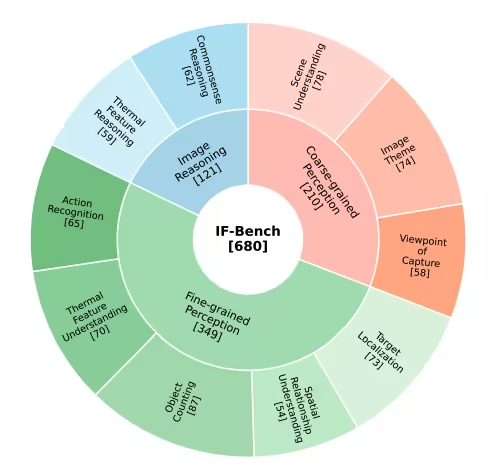
3. IF-Bench Infrarot-Bildverständnis-Benchmark-Datensatz
IF-Bench ist ein hochwertiger Benchmark für das multimodale Verständnis von Infrarotbildern, der gemeinsam vom Institut für Automatisierung der Chinesischen Akademie der Wissenschaften und der Fakultät für Künstliche Intelligenz der Universität der Chinesischen Akademie der Wissenschaften veröffentlicht wurde. Ziel ist die systematische Evaluierung der semantischen Fähigkeiten multimodaler großer Sprachmodelle (MLLMs) für Infrarotbilder. Der Datensatz umfasst 499 Infrarotbilder und 680 visuelle Frage-Antwort-Paare (VQA). Die Bilder stammen aus 23 verschiedenen Infrarotbilddatensätzen, wodurch eine relativ ausgewogene Gesamtverteilung gewährleistet ist.
Direkte Verwendung:https://go.hyper.ai/hty3u
4. CHIP Industriestuhl 6D-Pose-Schätzdatensatz
CHIP ist ein 6D-Pose-Estimation-Datensatz für die Robotermanipulation in realen industriellen Szenarien. Er wurde von FBK-TeV in Zusammenarbeit mit Ikerlan und Andreu World veröffentlicht. Ziel ist es, die Datenlücke bestehender Benchmarks zu schließen, die sich hauptsächlich auf Haushaltsgegenstände und Laboraufbauten konzentrieren und Daten zu realen industriellen Bedingungen vernachlässigen. Der Datensatz umfasst 77.811 RGB-D-Bilder von Stuhlmodellen mit sieben verschiedenen Strukturen und Materialien.
Direkte Verwendung:https://go.hyper.ai/AR5Xm
5. SSRB-Datensatz für semistrukturierte Daten und Abfragen in natürlicher Sprache
SSRB ist ein umfangreicher Benchmark-Datensatz für die Abfrage semistrukturierter Daten in natürlicher Sprache. Er wurde gemeinsam vom Harbin Institute of Technology (Shenzhen), der Hong Kong Polytechnic University, der Tsinghua University und weiteren Institutionen veröffentlicht. SSRB wurde für die NeurIPS 2025 Datasets and Benchmarks ausgewählt, um die Fähigkeit von Modellen zur Abfrage semistrukturierter Daten unter komplexen Bedingungen natürlicher Sprache zu evaluieren und zu fördern.
Direkte Verwendung:https://go.hyper.ai/szsqF
6. INFINITY-CHAT Datensatz für offene Frage-Antwort-Übungen aus der Praxis
INFINITY-CHAT, der erste umfangreiche Datensatz für offene Nutzerfragen aus der Praxis, der von der University of Washington in Zusammenarbeit mit der Carnegie Mellon University und dem Allen Institute for Artificial Intelligence veröffentlicht wurde, gewann den NeurIPS 2025 Best Paper Award (DB-Track). Ziel des Projekts ist die systematische Untersuchung zentraler Fragestellungen wie der Diversität von Sprachmodellen bei der Generierung offener Fragen, der Unterschiede in den menschlichen Präferenzen und des „künstlichen Schwarmeffekts“.
Direkte Verwendung:https://go.hyper.ai/KmH1N
7. MUVR Multimodal Uncropped Video Retrieval Benchmark
MUVR ist ein Benchmark-Datensatz für multimodale, ungeschnittene Video-Retrieval-Aufgaben. Er wurde gemeinsam von der Nanjing University of Aeronautics and Astronautics, der Nanjing University und der Hong Kong Polytechnic University veröffentlicht. MUVR wurde für die NeurIPS 2025 Datasets and Benchmarks ausgewählt und soll die Forschung im Bereich Video-Retrieval auf Langvideo-Plattformen fördern. Der Datensatz umfasst ca. 53.000 ungeschnittene Videos von Bilibili, 1.050 multimodale Suchanfragen und 84.000 Suchanfrage-Video-Zuordnungen und deckt verschiedene gängige Videotypen wie Nachrichten, Reise und Tanz ab.
Direkte Verwendung:https://go.hyper.ai/NRaSw

8. OpenGU Graph Forgetting – Umfassender Evaluierungsdatensatz
OpenGU ist ein umfassender Evaluierungsdatensatz für Graph Unlearning (GU), der vom Beijing Institute of Technology veröffentlicht wurde. Er wurde für die NeurIPS 2025 Datasets and Benchmarks ausgewählt und zielt darauf ab, ein einheitliches Evaluierungsframework, domänenübergreifende Datenressourcen und standardisierte experimentelle Einstellungen für Vergessensmethoden in Graph-Neuronalen Netzen bereitzustellen.
Direkte Verwendung:https://go.hyper.ai/qqHct
9. FrontierScience Inference Research Task Evaluation Dataset
FrontierScience, veröffentlicht von OpenAI, ist ein Datensatz zur Bewertung von Inferenz- und Forschungsaufgaben. Er dient der systematischen Beurteilung der Leistungsfähigkeit großer Modelle in wissenschaftlichen Argumentations- und Forschungsaufgaben auf Expertenniveau. Der Datensatz basiert auf einem Designmechanismus aus „Experten-Originalinhalten + zweischichtiger Aufgabenstruktur + automatischem Bewertungsmechanismus“ und ist in zwei Teilmengen unterteilt: Olympiade und Forschung.
Direkte Verwendung:https://go.hyper.ai/fUUzF
10. FirstAidQA Erste-Hilfe-Wissensfragen-Antwort-Datensatz
FirstAidQA ist ein domänenspezifischer Frage-Antwort-Datensatz für Erste-Hilfe- und Notfallsituationen, der von der Islamischen Universität für Wissenschaft und Technologie veröffentlicht wurde. Er dient der Unterstützung des Modelltrainings und der Anwendung in ressourcenarmen Notfallumgebungen. Der Datensatz umfasst 5.500 hochwertige Frage-Antwort-Paare und deckt eine Vielzahl typischer Erste-Hilfe- und Notfallsituationen ab.
Direkte Verwendung:https://go.hyper.ai/QQphC
Ausgewählte öffentliche Tutorials
1. Tiefen-Alles-3: Visuellen Raum aus jeder Perspektive wiederherstellen
Depth-Anything-3 (DA3) ist ein bahnbrechendes visuelles Geometriemodell, das vom ByteDance-Seed-Team entwickelt wurde. Es revolutioniert Aufgaben der visuellen Geometrie durch das Konzept des „minimalistischen Modellierens“: Es verwendet lediglich einen einzigen gewöhnlichen Transformer (wie den Standard-DINO-Encoder) als Basisnetzwerk und ersetzt komplexes Multitasking-Lernen durch eine „Tiefenstrahldarstellung“, um räumlich konsistente geometrische Strukturen aus beliebigen visuellen Eingaben (sowohl bekannten als auch unbekannten Kamerapositionen) vorherzusagen.
Online ausführen:https://go.hyper.ai/MXyML
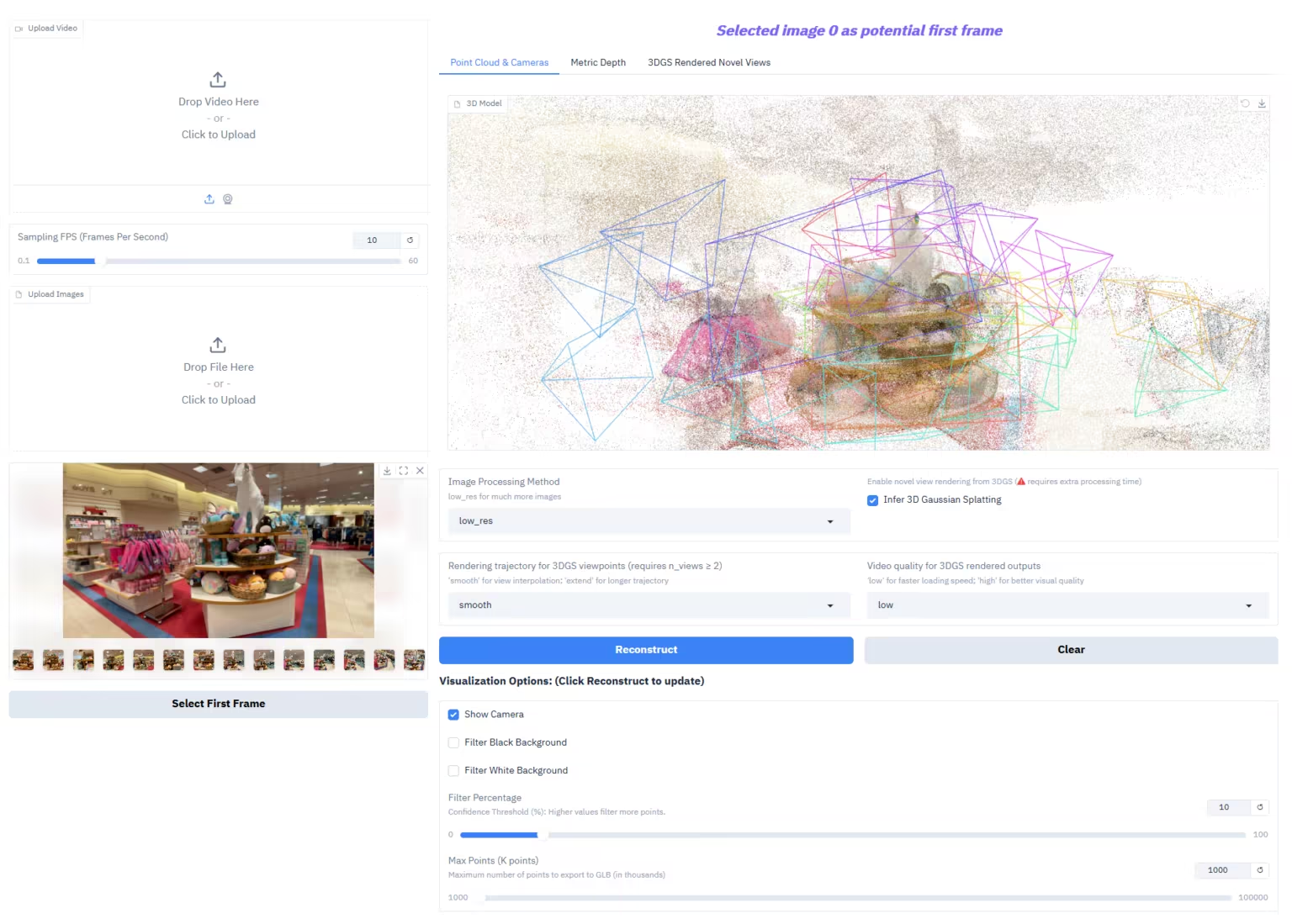
2. MarkItDown, Microsofts Open-Source-Dokumentkonvertierungstool
MarkItDown ist ein leichtgewichtiges, sofort einsatzbereites Python-Dokumentkonvertierungstool, das von Microsoft entwickelt wurde. Es zielt darauf ab, verschiedene gängige Dokument- und Rich-Media-Formate effizient und strukturiert in Markdown zu konvertieren und so ein optimiertes Eingabeformat speziell für Textverständnis- und Analyse-Pipelines in großen Sprachmodellen (LLMs) bereitzustellen.
Online ausführen:https://go.hyper.ai/7WIGP
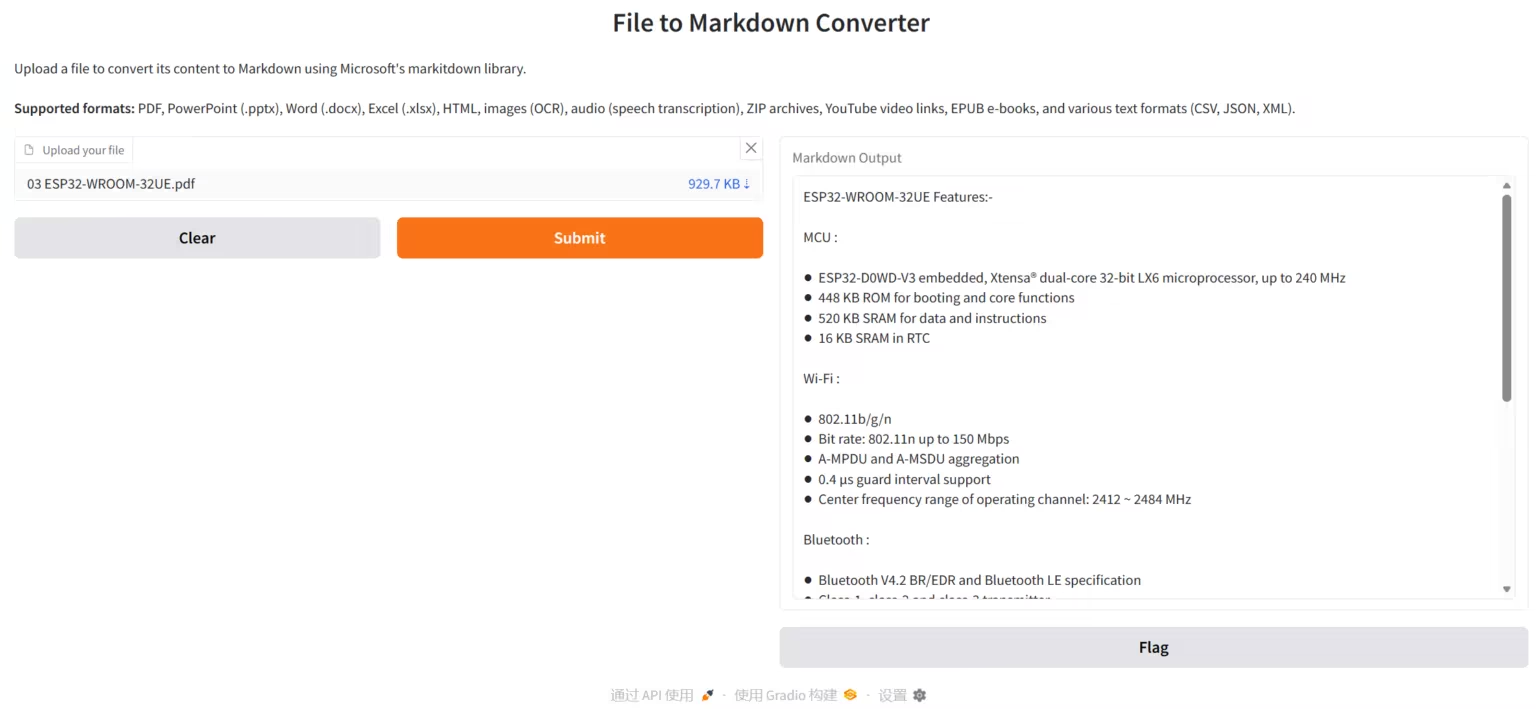
3. Chandra: Hochpräzise Dokumenten-OCR
Chandra ist ein hochpräzises Dokumenten-OCR-System (Optical Character Recognition), entwickelt vom Datalab-to-Team. Es konzentriert sich auf die Erkennung von Dokumentenlayouts und die Textextraktion. Chandra kann PDF- und Bilddateien direkt verarbeiten und strukturierten Text, Markdown und HTML-Ausgaben generieren. Zusätzlich werden visuelle Layoutdiagramme zur einfachen Überprüfung der OCR-Ergebnisse bereitgestellt.
Online ausführen:https://go.hyper.ai/nZhF5
Die Zeitungsempfehlung dieser Woche
1. LongVie 2: Multimodales, steuerbares Ultralang-Videoweltmodell
In diesem Beitrag wird LongVie 2 vorgestellt, ein durchgängiges autoregressives Framework, das in Bezug auf Langstreckensteuerbarkeit, zeitliche Kohärenz und visuelle Wiedergabetreue Bestleistungen erzielt und die Generierung von bis zu fünf Minuten langen, kontinuierlichen Videos unterstützt. Dies stellt einen wichtigen Schritt hin zur Modellierung einer einheitlichen Videowelt dar.
Link zum Artikel:https://go.hyper.ai/toK8K
2. MMGR: Multimodales generatives Schließen
Diese Arbeit stellt das Multimodal Generative Reasoning Evaluation and Benchmarking Framework (MMGR) vor, ein systematisches Bewertungssystem, das auf fünf zentralen Denkfähigkeiten basiert: physikalisches, logisches, räumliches 3D-Denken, räumliches 2D-Denken und zeitliches Denken. MMGR bewertet die Denkfähigkeiten generativer Modelle in drei Schlüsselbereichen: abstraktes Denken (ARC-AGI, Sudoku), verkörperte Navigation (reale 3D-Navigation und -Positionierung) und physikalisches Alltagsverständnis (Sportszenarien und komplexe interaktive Verhaltensweisen).
Link zum Artikel:https://go.hyper.ai/Gxwuz
3. QwenLong-L1.5: Rezept für die Zeit nach dem Training für kontextbezogenes Denken und Gedächtnismanagement
Diese Arbeit stellt QwenLong-L1.5 vor, ein Modell, das durch systematische Innovationen nach dem Training überlegene Fähigkeiten im Kontextschlussfolgern erzielt. Basierend auf der Architektur Qwen3-30B-A3B-Thinking erreicht QwenLong-L1.5 in Benchmarks zum Kontextschlussfolgern vergleichbare Ergebnisse wie GPT-5 und Gemini-2.5-Pro, mit einer durchschnittlichen Verbesserung von 9,90 Punkten gegenüber den Basismodellen. Bei extrem langen Aufgaben (1 bis 4 Millionen Token) erzielt das Memory-Agent-Framework eine signifikante Verbesserung von 9,48 Punkten gegenüber dem Basisagenten.
Link zum Artikel:https://go.hyper.ai/DxYGd
4. Gedächtnis im Zeitalter der KI-Agenten
Diese Arbeit zielt darauf ab, die neuesten Entwicklungen in der Forschung zum Agentengedächtnis systematisch zu untersuchen. Zunächst wird der Umfang des Agentengedächtnisses verdeutlicht und klar von verwandten Konzepten wie dem Speicher großer Sprachmodelle (LLM), der abrufgestützten Generierung (RAG) und dem Kontext-Engineering abgegrenzt. Anschließend wird das Agentengedächtnis aus drei einheitlichen Perspektiven analysiert: Form, Funktion und Dynamik.
Link zum Artikel:https://go.hyper.ai/zfHTr
5. ReFusion: Ein Diffusionsmodell für große Sprachen mit paralleler autoregressiver Dekodierung
Diese Arbeit stellt ReFusion vor, ein neuartiges Maskendiffusionsmodell, das durch die Anhebung der parallelen Dekodierung von der Token-Ebene auf eine höhere „Slot“-Ebene überlegene Leistung und Effizienz erzielt. Jeder Slot ist eine zusammenhängende Teilsequenz fester Länge. ReFusion erreicht nicht nur eine durchschnittliche Leistungsverbesserung von 341 TP3T gegenüber bisherigen MDMs und eine durchschnittliche Steigerung der Inferenzgeschwindigkeit um mehr als das 18-Fache, sondern verringert auch die Leistungslücke zu starken autoregressiven Modellen signifikant und erzielt dabei einen durchschnittlichen Geschwindigkeitsvorteil von 2,33.
Link zum Artikel:https://go.hyper.ai/YosaF
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
1. Die Eidgenössische Technische Hochschule Lausanne (EPFL) hat mit weniger als 100.000 strukturierten Datenpunkten für das Training PET-MAD entwickelt und damit eine atomare Simulationsgenauigkeit erreicht, die mit professionellen Modellen vergleichbar ist.
Das von der Eidgenössischen Technischen Hochschule Lausanne (EPFL) vorgeschlagene PET-MAD-Modell erreicht eine vergleichbare Genauigkeit wie spezialisierte Modelle mit einem Datensatz, der ein breites Spektrum atomarer Vielfalt abdeckt, und verwendet weit weniger Trainingsbeispiele als herkömmliche Modelle. Es liefert damit einen überzeugenden Beweis für die Entwicklung der Atomsimulation hin zu größerer Effizienz und Universalität.
Den vollständigen Bericht ansehen:https://go.hyper.ai/cpeR5
2. Online-Tutorial | Microsoft stellt VibeVoice als Open Source zur Verfügung und ermöglicht so 90 Minuten natürlichen Dialog zwischen 4 Rollen
Microsoft hat VibeVoice als Open Source veröffentlicht. Das System ermöglicht skalierbare Sprachsynthese für längere Dialoge mit mehreren Sprechern. Es kann bis zu 90 Minuten Sprache mit bis zu vier Sprechern in einem 64K-Kontextfenster synthetisieren und bietet dabei einen volleren Klang, eine natürlichere Intonation und eine realistische Gesprächsatmosphäre. VibeVoice zeichnet sich durch eine höhere Übertragbarkeit auf sprachübergreifende Anwendungen aus und übertrifft in seiner Gesamtleistung bestehende Open-Source- und proprietäre Dialogmodelle.
Den vollständigen Bericht ansehen:https://go.hyper.ai/YfDjq
3. Die ursprünglichen Teammitglieder von CUDA kritisieren cuTile scharf dafür, dass es "speziell" auf Triton abzielt; kann das Tile-Paradigma die Wettbewerbslandschaft des GPU-Programmierökosystems umgestalten?
Im Dezember 2025, fast zwei Jahrzehnte nach der Veröffentlichung von CUDA, brachte NVIDIA „cuTile“ auf den Markt, einen neuen Einstiegspunkt für die GPU-Programmierung. Dieses neue cuTile refaktoriert den GPU-Kernel mithilfe eines kachelbasierten Programmiermodells. Dadurch können Entwickler effizient Kernel schreiben, ohne tiefgreifende CUDA-C++-Kenntnisse zu benötigen, was in der Community zu intensiven Diskussionen führte. Obwohl sich cuTile noch in der Anfangsphase befindet, deuten die abstrakten Vorteile des kachelbasierten Ansatzes, die Erforschung von Migrationswerkzeugen durch die Community und praktische Versuche darauf hin, dass cuTile das Potenzial hat, ein neues Paradigma für die GPU-Programmierung zu werden. Seine Zukunft hängt von der Reife des Ökosystems, den Migrationskosten und der Leistung ab.
Den vollständigen Bericht ansehen:https://go.hyper.ai/H1b0n
4. Dario Amodei, der der proaktiven Überwachung Priorität einräumt, integrierte die Sicherheit von KI nach seinem Ausscheiden bei OpenAI in die Unternehmensmission.
Im Zuge des sich beschleunigenden globalen KI-Wettlaufs hat sich Dario Amodei mit seiner Minderheitenposition für eine frühzeitige Regulierung zu einer unbestreitbaren Kraft im Silicon Valley entwickelt. Von der Förderung einer verfassungsmäßigen KI bis hin zur Beeinflussung regulatorischer Rahmenbedingungen in Europa und den USA versucht er, ein „Governance-Protokoll“ ähnlich TCP/IP für das KI-Zeitalter zu etablieren. Dabei geht es nicht nur um Sicherheit, sondern auch darum, ob KI im nächsten Jahrzehnt den Sprung von rasantem technologischen Fortschritt zu stabilen Anwendungen schaffen kann. Amodeis Strategie verändert die grundlegende Logik der globalen KI-Industrie grundlegend.
Den vollständigen Bericht ansehen:https://go.hyper.ai/SwyNW
5. Ein Team unter der Leitung von Li Yong an der Tsinghua-Universität hat eine neuronale symbolische Regressionsmethode vorgeschlagen, die die Vorhersagegenauigkeit um 60% verbessern kann, indem sie automatisch hochpräzise Netzwerkdynamikformeln ableitet.
Professor Yong Li und sein Team vom Institut für Elektrotechnik der Tsinghua-Universität haben mit ND² eine neuronale symbolische Regressionsmethode entwickelt, die die Systemdynamik charakterisiert, indem sie automatisch mathematische Formeln aus den Daten ableitet. Diese Methode vereinfacht das Suchproblem in hochdimensionalen Netzwerken auf ein eindimensionales System und nutzt ein vortrainiertes neuronales Netzwerk, um hochpräzise Formeln zu ermitteln.
Den vollständigen Bericht ansehen:https://go.hyper.ai/wVktJ
Beliebte Enzyklopädieartikel
1. Nukleare Norm
2. Bidirektionales Long Short-Term Memory (Bi-LSTM)
3. Wahrheitsgehalt
4. Verkörperte Navigation
5. Bilder pro Sekunde (FPS)
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Januar-Frist für die Top-Konferenz

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung von inländischen beschleunigten Download-Knoten für über 1800 öffentliche Datensätze
* Enthält über 600 klassische und beliebte Online-Tutorials
* Interpretation von über 200 AI4Science-Papierfällen
* Unterstützt die Suche nach über 600 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








