HyperAI
Command Palette
Search for a command to run...
الأوراق البحثية
أوراق بحثية متطورة في مجال الذكاء الاصطناعي يتم تحديثها يوميًا لمساعدتك على مواكبة أحدث اتجاهات الذكاء الاصطناعي

ضغط السياق النشط: الإدارة الذاتية للذاكرة في LLM Agents

قلل خسائرك! تعلم تقليم المسارات مبكراً من أجل reasoning متوازٍ فعال



























ضغط السياق النشط: الإدارة الذاتية للذاكرة في LLM Agents
قلل خسائرك! تعلم تقليم المسارات مبكراً من أجل reasoning متوازٍ فعال
تقرير تقني حول Qwen3.5-Omni
تقطيع النصوص المدرك للاسترجاع من الويب (W-RAC) لأنظمة الـ Retrieval-Augmented Generation الفعالة ومنخفضة التكلفة
PersonaVLM: نماذج Multimodal LLMs المخصصة طويلة المدى
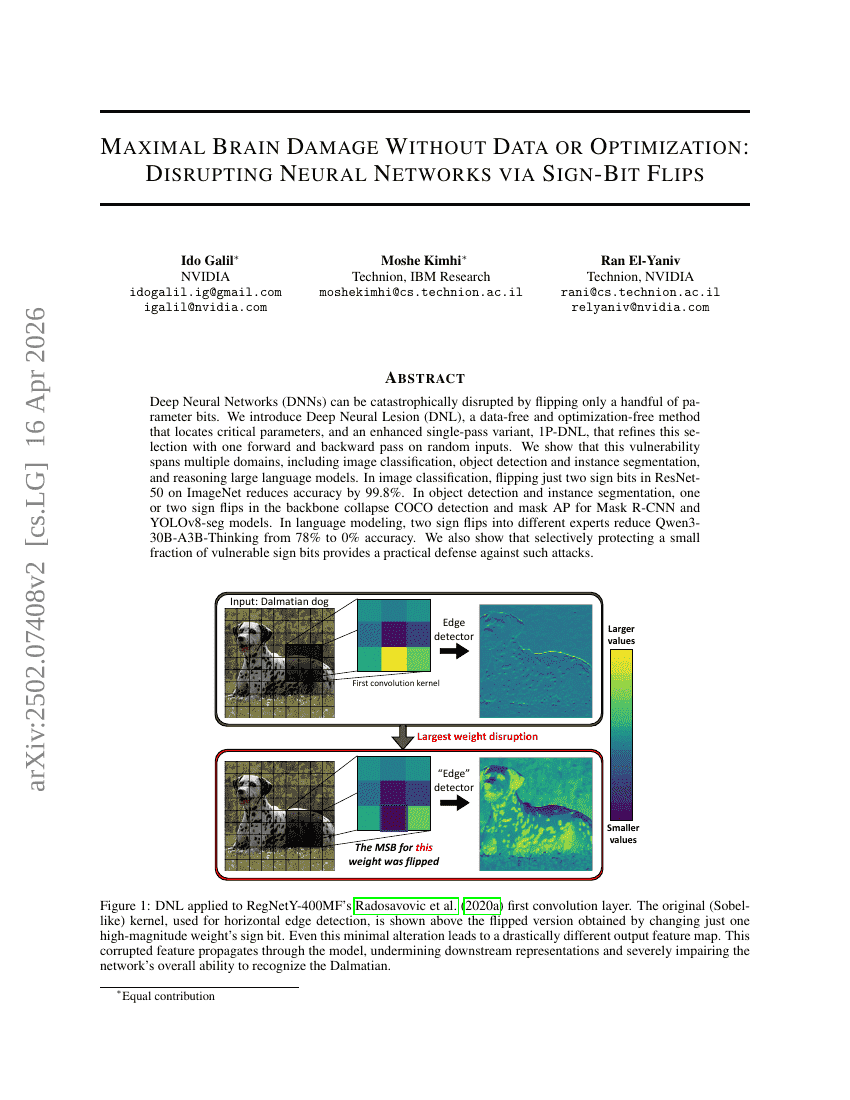
أقصى ضرر للدماغ دون بيانات أو تحسين: تعطيل Neural Networks عبر Sign-Bit Flips
توضيح انحياز SNR-t في نماذج Diffusion Probabilistic Models
التعرف الضوئي على الحروف متعدد الوسائط (Multimodal OCR): تحليل كل شيء من المستندات
Granite-speech: نماذج LLMs مفتوحة المصدر مدركة للكلام مع قدرات قوية في مجال ASR للغة الإنجليزية
Fish-Speech: الاستفادة من Large Language Models لتخليق الكلام متعدد اللغات المتقدم من النص إلى الصوت
حذف الكائنات والتفاعلات في الفيديو
VoxCPM: نظام TTS بدون Tokenizer لتوليد الكلام المدرك للسياق واستنساخ الصوت الواقعي للغاية
OmniVoice: نحو تحويل النص إلى كلام بأسلوب zero-shot متعدد اللغات باستخدام Diffusion Language Models
حيث تصبح الرؤية نصاً: تحديد موقع عنق الزجاجة في توجيه OCR ضمن Vision-Language Models
هل هو OCR أم لا؟ إعادة التفكير في استخراج معلومات المستندات في عصر MLLMs باستخدام مجموعات بيانات ضخمة من العالم الحقيقي
dnaHNet: نموذج تأسيسي هرمي وقابل للتوسع لتعلم المتواليات الجينومية
الحواسيب العصبية (Neural Computers)
ASGuard: Activation-Scaling Guard لتخفيف هجمات Targeted Jailbreaking
GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
كيف يتم إجراء Fine-Tune لنموذج استنتاج (Reasoning Model)؟ إطار عمل تعاوني بين Teacher و Student لتخليق بيانات SFT متسقة مع الـ Student.
RAD-2: توسيع نطاق Reinforcement Learning ضمن إطار عمل Generator-Discriminator
DR3-Eval: نحو تقييم بحثي عميق واقعي وقابل للتكرار
HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds HY-World 2.0: نموذج عالم متعدد الوسائط لإعادة بناء وتوليد ومحاكاة العوالم ثلاثية الأبعاد
pi0.7: نموذج روبوتي أساسي عام وقابل للتوجيه مع قدرات ناشئة
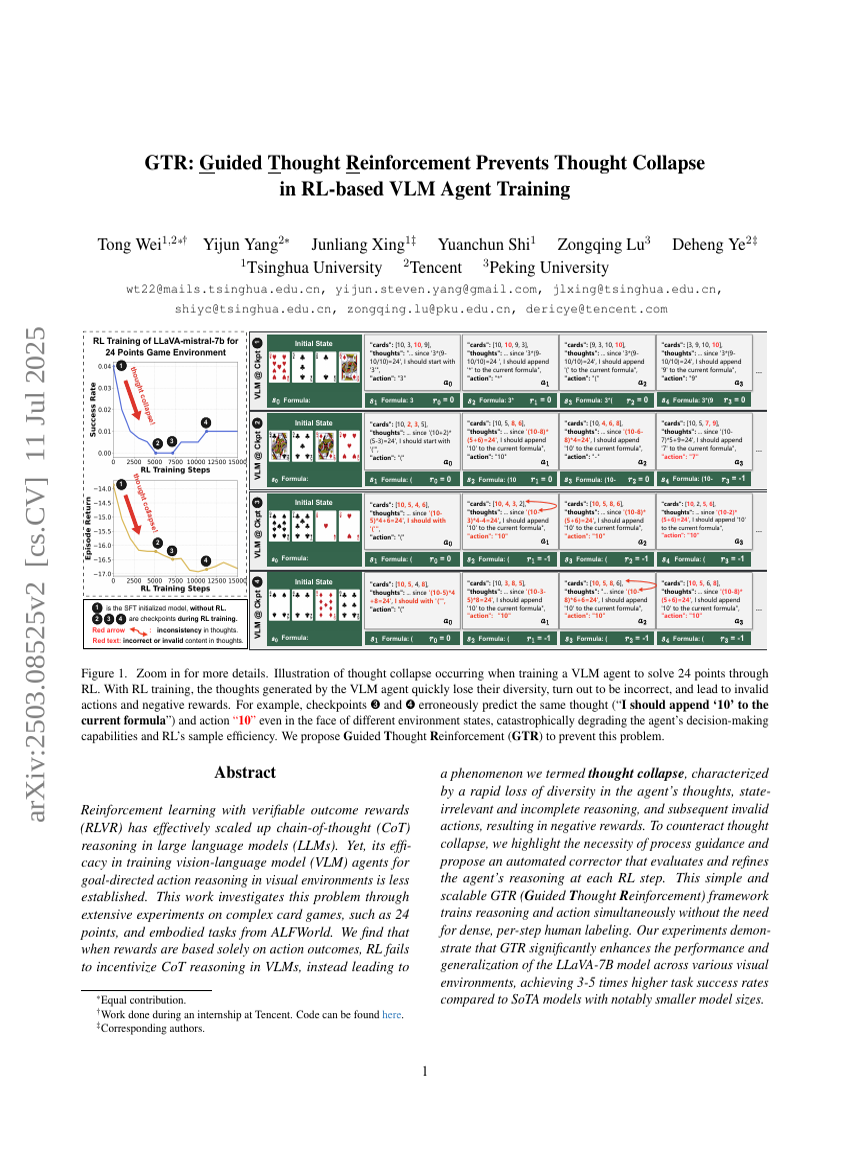
GTR: تعزيز التفكير الموجه يمنع انهيار التفكير أثناء تدريب VLM Agent القائم على RL
مهارات Agent لنماذج Large Language Models: البنية، والاكتساب، والأمن، والمسار المستقبلي
نظرية الفضاء: هل يمكن للنماذج الأساسية (Foundation Models) بناء معتقدات مكانية من خلال الاستكشاف النشط؟
تعلم نقل الذاكرة: كيف يتم نقل الذاكرة عبر النطاقات في Coding Agents
OccuBench: تقييم AI Agents في المهام المهنية الواقعية عبر Language World Models
SpatialEvo: ذكاء مكاني ذاتي التطور عبر بيئات هندسية حتمية
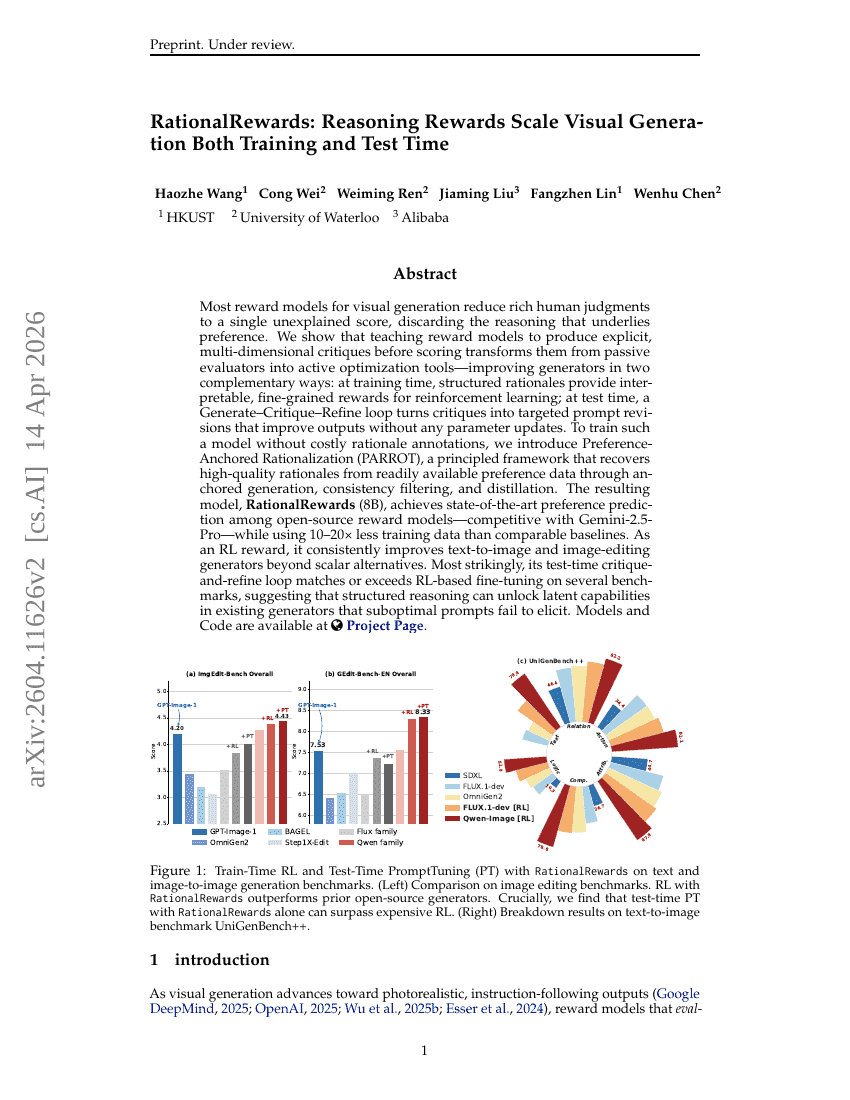
RationalRewards: مكافآت الاستدلال ترفع من كفاءة التوليد المرئي في مرحلتي Training و Test Time
Seedance 2.0: تعزيز توليد الفيديو لمواجهة تعقيد العالم
تقرير تقني حول Qwen3.5-Omni
تقطيع النصوص المدرك للاسترجاع من الويب (W-RAC) لأنظمة الـ Retrieval-Augmented Generation الفعالة ومنخفضة التكلفة
PersonaVLM: نماذج Multimodal LLMs المخصصة طويلة المدى
أقصى ضرر للدماغ دون بيانات أو تحسين: تعطيل Neural Networks عبر Sign-Bit Flips
توضيح انحياز SNR-t في نماذج Diffusion Probabilistic Models
التعرف الضوئي على الحروف متعدد الوسائط (Multimodal OCR): تحليل كل شيء من المستندات
Granite-speech: نماذج LLMs مفتوحة المصدر مدركة للكلام مع قدرات قوية في مجال ASR للغة الإنجليزية
Fish-Speech: الاستفادة من Large Language Models لتخليق الكلام متعدد اللغات المتقدم من النص إلى الصوت
حذف الكائنات والتفاعلات في الفيديو
VoxCPM: نظام TTS بدون Tokenizer لتوليد الكلام المدرك للسياق واستنساخ الصوت الواقعي للغاية
OmniVoice: نحو تحويل النص إلى كلام بأسلوب zero-shot متعدد اللغات باستخدام Diffusion Language Models
حيث تصبح الرؤية نصاً: تحديد موقع عنق الزجاجة في توجيه OCR ضمن Vision-Language Models
هل هو OCR أم لا؟ إعادة التفكير في استخراج معلومات المستندات في عصر MLLMs باستخدام مجموعات بيانات ضخمة من العالم الحقيقي
dnaHNet: نموذج تأسيسي هرمي وقابل للتوسع لتعلم المتواليات الجينومية
الحواسيب العصبية (Neural Computers)
ASGuard: Activation-Scaling Guard لتخفيف هجمات Targeted Jailbreaking
GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
كيف يتم إجراء Fine-Tune لنموذج استنتاج (Reasoning Model)؟ إطار عمل تعاوني بين Teacher و Student لتخليق بيانات SFT متسقة مع الـ Student.
RAD-2: توسيع نطاق Reinforcement Learning ضمن إطار عمل Generator-Discriminator
DR3-Eval: نحو تقييم بحثي عميق واقعي وقابل للتكرار
HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds HY-World 2.0: نموذج عالم متعدد الوسائط لإعادة بناء وتوليد ومحاكاة العوالم ثلاثية الأبعاد
pi0.7: نموذج روبوتي أساسي عام وقابل للتوجيه مع قدرات ناشئة
GTR: تعزيز التفكير الموجه يمنع انهيار التفكير أثناء تدريب VLM Agent القائم على RL
مهارات Agent لنماذج Large Language Models: البنية، والاكتساب، والأمن، والمسار المستقبلي
نظرية الفضاء: هل يمكن للنماذج الأساسية (Foundation Models) بناء معتقدات مكانية من خلال الاستكشاف النشط؟
تعلم نقل الذاكرة: كيف يتم نقل الذاكرة عبر النطاقات في Coding Agents
OccuBench: تقييم AI Agents في المهام المهنية الواقعية عبر Language World Models
SpatialEvo: ذكاء مكاني ذاتي التطور عبر بيئات هندسية حتمية
RationalRewards: مكافآت الاستدلال ترفع من كفاءة التوليد المرئي في مرحلتي Training و Test Time
Seedance 2.0: تعزيز توليد الفيديو لمواجهة تعقيد العالم