Command Palette
Search for a command to run...
PhysisForcing: محاكي العالم المدعَّم بالفيزياء للتلاعب الروبوتي
PhysisForcing: محاكي العالم المدعَّم بالفيزياء للتلاعب الروبوتي
الملخص
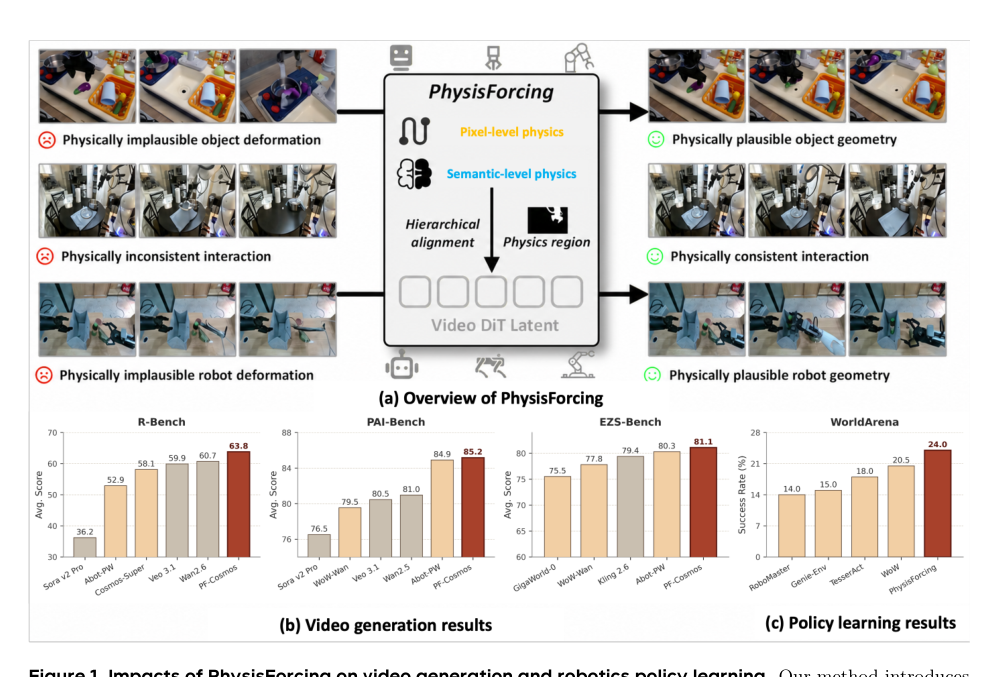
ظهرت نماذج توليد الفيديو كمنهج واعد لمحاكاة العالم المتجسد. ومع ذلك، لا تزال كل من مولدات الفيديو العامة والنماذج المضبوطة بدقة على بيانات الروبوت تنتج تلاعبات غير معقولة فيزيائياً، بما في ذلك مسارات حركة غير متصلة وتفاعلات غير متسقة بين الروبوت والأشياء، مما يحد من موثوقيتها كمحاكيات للعالم. من خلال تجارب موسعة، وجدنا أن عدم الاستقرار الفيزيائي ينشأ بشكل رئيسي من عاملين: تشوه الأجسام المتحركة والارتباطات الزمانية-المكانية غير المعقولة بين الكيانات المتفاعلة، خصوصاً أثناء التلامس. بناءً على هذه الملاحظة، نقترح PhysisForcing، وهو إطار تدريب قابل للتوسع يعزز الاتساق الفيزيائي عبر تركيز الإشراف على المناطق الغنية بالمعلومات الفيزيائية من خلال تحسين مشترك لميزات على مستوى البكسل والمستوى الدلالي. يتكون الإطار من دالة خسارة محاذاة المسار على مستوى البكسل، التي تشرف على ميزات DiT باستخدام مسارات النقاط المرجعية، ودالة خسارة محاذاة علائقية على المستوى الدلالي، التي توائم ميزات DiT مع علاقات بين المناطق المستخرجة من مشفر فهم فيديو مجمد. أظهرت التجارب الموسعة على R-Bench وPAI-Bench وEZS-Bench أن PhysisForcing يحسن بشكل مستمر توليد الفيديو المتجسد بالمقارنة مع خطوط الأساس القوية، حيث يحسن نموذجي Wan2.2-I2V-A14B وCosmos3-Nano الأساسيين على R-Bench بنسبة 22.3% و9.2% (7.1% و3.7% مقارنة بالضبط الدقيق العادي)، مع تحقيق متغير Cosmos3-Nano أعلى درجة إجمالية. بعيداً عن التوليد، كنموذج عالمي تحت بروتوكول WorldArena لمخطط الإجراءات، يرفع نسبة النجاح في الحلقة المغلقة من 16.0% إلى 24.0% ويحقق تحسناً إضافياً في نجاح السياسة النهائية، مما يشير إلى أن نماذج الفيديو المتوافقة فيزيائياً تقدم تمثيلات أقوى للتلاعب الروبوتي. الكود والمزيد من النتائج متاحة على https://dagroup-pku.github.io/PhysisForcing.github.io/.
One-sentence Summary
Researchers from Peking University and NVIDIA propose PhysisForcing, a training framework that reinforces physical consistency in video world simulators for robotic manipulation by jointly optimizing pixel-level trajectory alignment and semantic-level relational alignment losses, improving generation benchmarks including a +22.3% gain on R-Bench and raising the closed-loop manipulation success rate from 16.0% to 24.0%.
Key Contributions
- PhysisForcing is a training framework that enforces physical consistency in video generation by jointly optimizing a pixel-level trajectory alignment loss and a semantic-level relational alignment loss on interaction-critical regions.
- Experiments on R-Bench, PAI-Bench, and EZS-Bench show that PhysisForcing consistently improves embodied video generation, with relative gains of 22.3% on Wan2.2-I2V-A14B and 9.2% on Cosmos3-Nano over base models on R-Bench, and the Cosmos3Nano variant achieving the best overall score.
- When used as a world model in the WorldArena protocol, PhysisForcing raises closed-loop manipulation success rate from 16.0% to 24.0% and improves downstream policy success, demonstrating that physically aligned video generation yields stronger representations for robotic manipulation.
Introduction
Video generation models hold promise as world simulators for embodied intelligence, enabling scalable data generation and policy learning in robotic manipulation. However, they often produce physically implausible dynamics like object penetration or discontinuous motion, especially in contact-rich tasks. Prior approaches either lack sufficient exposure to manipulation data, treat all pixels uniformly during training, or apply single-level and post-hoc physical constraints that miss the hierarchical nature of physical plausibility. The authors introduce PhysisForcing, a region-focused, hierarchical alignment framework that, during training, identifies interaction-critical regions and applies two complementary losses: a pixel-level point-trajectory loss for local motion consistency, and a semantic-level token-similarity alignment loss for correct global object interactions.
Method
The authors propose PhysisForcing, a method that injects physics supervision into video generation through a region-focused hierarchical alignment framework. As shown in the figure below:
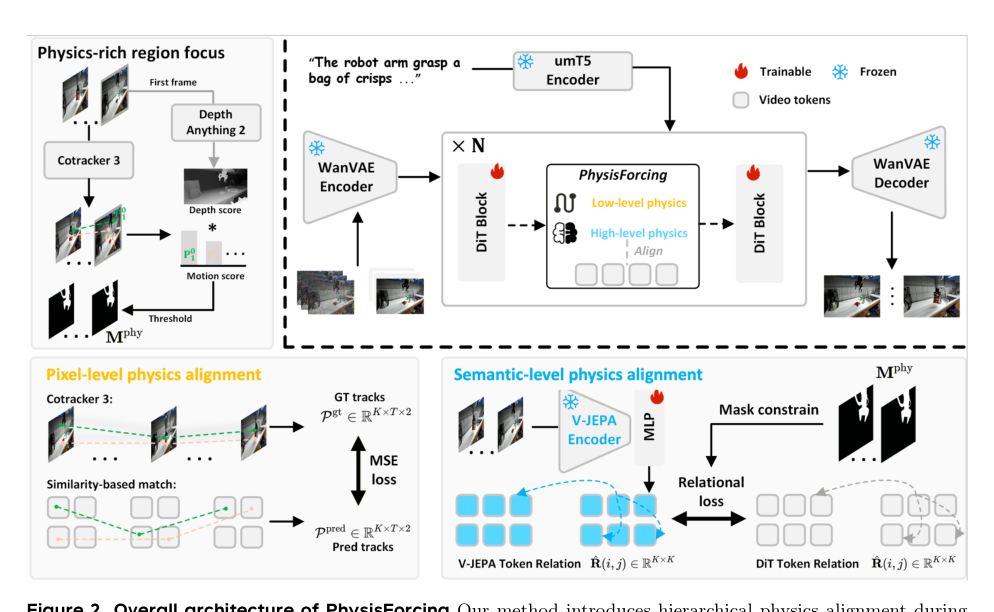
The pipeline begins by identifying physics-informative regions where robot-object interactions occur, followed by the application of two complementary training signals: pixel-level trajectory alignment for local motion consistency and semantic-level relational alignment for interaction outcome consistency.
To localize these interaction-rich regions, the authors first extract dense temporal trajectories from the input video V∈RT×C×H×W using an off-the-shelf point tracker. They compute the motion magnitude ai for each trajectory, noting that large local motion often indicates contact-rich areas. However, to filter out background jitter, they introduce a depth-aware foreground weight ri derived from the estimated depth map D0 of the first frame. By combining the motion magnitude with this foreground weight, they calculate a physics-informative score qi=ai⋅ri for each trajectory. An adaptive threshold based on the mean score is then applied to generate a trajectory-level motion mask, which is subsequently projected onto each frame to form a spatiotemporal physics mask Mphy. This mask provides spatial guidance for the subsequent physics supervision steps.
For pixel-level physics alignment, the authors enforce per-point trajectory continuity on the manipulator and the manipulated object. They extract the hidden feature Hl from an intermediate block of the Denoising Transformer (DiT) and refine it using a lightweight MLP ϕ(⋅). The refined feature is reshaped into frame-wise feature maps F^. Using the first-frame feature as the query Q=F^0 and the remaining frames as keys Kt=F^t, they compute a similarity map sit for each query point. By normalizing this map and computing the coordinate expectation, they obtain the predicted point location p^it at each frame. These predicted trajectories are then supervised by the reference trajectories extracted from the ground truth video using a masked mean squared error loss Lpixphy, restricted to the physics-informative regions identified earlier.
While pixel-level alignment constrains point-wise motion, manipulation plausibility also relies on the relational dynamics between different regions. To capture this, the authors introduce semantic-level physics alignment. They utilize a frozen self-supervised video understanding encoder to extract a target representation Fu from the input video. Simultaneously, they project the hidden features from the same intermediate DiT block into the encoder representation space using another lightweight MLP ψ(⋅) and resize them to match the encoder spatio-temporal token layout F^u. The physics-informative mask is resized to select corresponding spatio-temporal tokens from both representations. They then compute pairwise relational matrices R^ and R for both the DiT-side and encoder-side tokens, capturing the spatio-temporal relations among the selected physics-informative tokens. The semantic-level alignment loss is defined as the L1 distance between these two relational matrices:
Lsemphy=K21∑i=1K∑j=1KR^(i,j)−R(i,j)
This effectively transfers the relational structure of the encoder into the DiT.
PhysisForcing is applied during the fine-tuning of a pre-trained DiT-based video generation backbone. The overall training objective combines the standard flow matching loss with the pixel-level and semantic-level physics losses:
L=LFM+λpixLpixphy+λsemLsemphy
All auxiliary models, including the point tracker, depth estimator, and video understanding encoder, are utilized exclusively during training and are discarded at inference, ensuring that the method introduces no additional computational cost during video generation.
Experiment
Experiments across three embodied video generation benchmarks show PhysisForcing improves multiple backbones, yielding more physically plausible videos and outperforming strong baselines. The enhanced world model also boosts success rates in policy learning on contact-rich tasks. Ablations verify that the pixel and semantic losses are complementary, interaction-focused supervision drives gains, and a mid-block alignment layer is optimal.
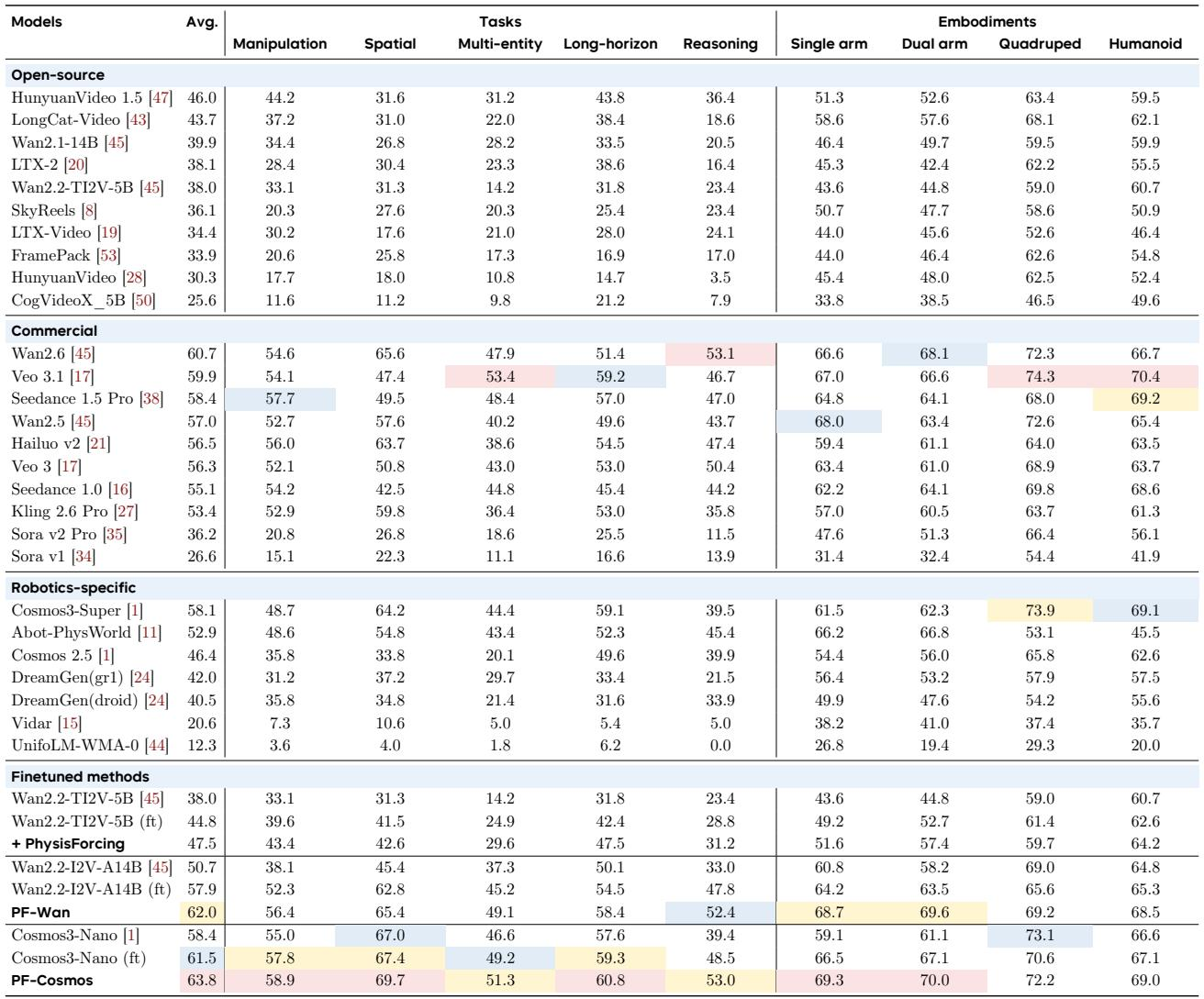
PhysisForcing substantially lifts video generation performance on R-Bench, with PF-Cosmos achieving the highest overall average (63.8) and PF-Wan following closely (62.0), both outperforming the best commercial and open-source baselines. Among backbone models without PhysisForcing, open-source counterparts reach only moderate scores, led by HunyuanVideo 1.5 at 46.0 average. PF-Cosmos attains the top overall average of 63.8, surpassing the strongest commercial model Wan2.6 (60.7) and all open-source models. PhysisForcing boosts the Wan backbone by 22.3% (to 62.0) while the highest-scoring open-source model without it, HunyuanVideo 1.5, reaches just 46.0.
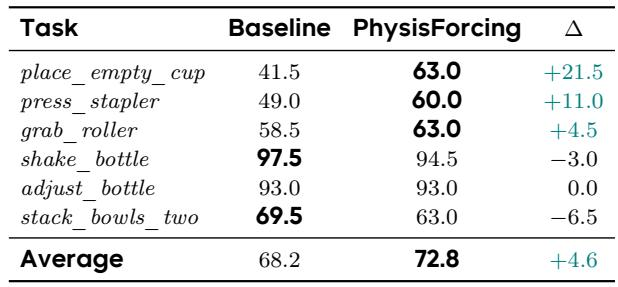
Replacing the video backbone with PhysisForcing in Fast-WAM raises the average success rate from 68.2% to 72.8% across six RoboTwin 2.0 tasks. Gains are concentrated on contact-rich placing and pressing, while tasks that already had high success show flat or slightly degraded performance. PhysisForcing improves place_empty_cup by 21.5 points and press_stapler by 11.0 points, the largest gains among all tasks. Tasks with high baseline success, such as shake_bottle and adjust_bottle, see no improvement or a small drop, and stack_bowls_two decreases by 6.5 points.
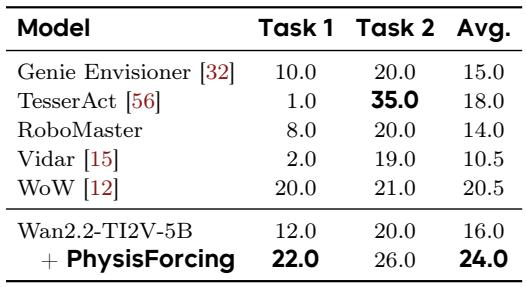
Incorporating PhysisForcing into the Wan2.2-TI2V-5B video backbone raises the average closed-loop action planning success rate from 16.0% to 24.0%, surpassing all prior world-model planners including the previous best WoW at 20.5%. Gains are observed on both evaluation tasks, indicating robust planning improvements. PhysisForcing provides an 8-point absolute improvement in average success rate over the base video model. It outperforms the strongest prior world-model planner, WoW, by a clear margin. The success rate on Task 1 nearly doubles, while Task 2 also sees a solid increase.
Ablating the two physical losses on R-Bench shows they are complementary: the pixel-level loss alone delivers a larger individual improvement, especially on the embodiment metric, while adding the semantic loss further lifts task-oriented performance. Their combination, PhysisForcing, achieves the highest overall average and task scores on the 5B model, and consistent gains on the larger 14B model confirm the benefit scales across backbones. The pixel-level physical loss alone raises the average R-Bench score by 2.4 points over the finetuned baseline, exceeding the semantic loss's 1.4-point gain. Combining both losses into PhysisForcing yields the highest task score (38.9 vs. 35.4) and highest overall average (47.5 vs. 44.8) on the 5B model, even though the embodiment score is slightly below the pixel-loss-only setting. On the larger 14B model, the pixel loss boosts average score from 57.9 to 60.7 and the semantic loss to 60.0, demonstrating the improvements are not limited to a single model scale.
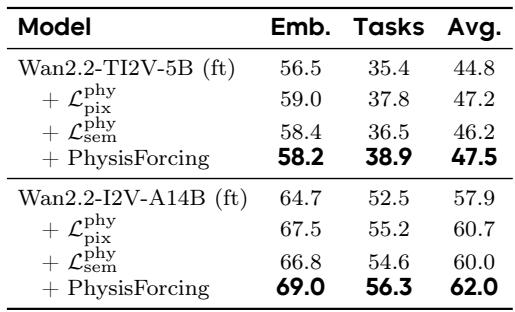
Applying physics losses uniformly over all video tokens improves average performance over the baseline, but restricting them to interaction-critical regions yields a further boost, especially on task-oriented metrics. This demonstrates that irrelevant background areas dilute the physical signal and focusing supervision on where robot-object interactions occur is what drives task-level correctness. Uniformly applying physics losses lifts the average score from 44.8 to 46.0, while focusing on physics-informative regions pushes it to 47.5. The largest gain is on task-oriented performance, which rises from 35.4 to 38.9 when supervision is concentrated on interaction-critical regions. The embedding metric also improves with region focus, from 56.5 to 58.2, showing better physical consistency. Background and near-static areas dilute the learning signal; restricting loss computation to robot-object interaction zones sharply improves task-level results.

PhysisForcing substantially improves performance across video generation, robotic manipulation, and world-model planning tasks. The method boosts video generation quality beyond both commercial and open-source baselines, enhances contact-rich manipulation policies, and raises closed-loop planning success rates. Complementary pixel-level and semantic physics losses, combined with supervision focused on robot-object interaction regions, drive these gains, and the benefits scale to larger video backbones.