Command Palette
Search for a command to run...
ما وراء البيانات المستقلة والمتطابقة التوزيع: إلى أي مدى تصل عمومية النماذج الأساسية الجدولية حقاً؟
ما وراء البيانات المستقلة والمتطابقة التوزيع: إلى أي مدى تصل عمومية النماذج الأساسية الجدولية حقاً؟
Lennart Purucker Andrej Tschalzev Nick Erickson Gioia Blayer David Holzmüller Alan Arazi Alexander Pfefferle Mustafa Tajjar Gaël Varoquaux Frank Hutter
الملخص
اكتسبت النماذج الأساسية للتعلم الآلي التنبؤي على البيانات الجدولية زخماً كبيراً مؤخراً في الأوساط الأكاديمية والصناعية. تقوم مجتمعات البحث عبر التخصصات المختلفة بشكل متزايد بتقييم النماذج الأساسية الجدولية على مجموعات بيانات ومهام متنوعة. ومع ذلك، تظل هذه التقييمات الخاصة بالمهام والتخصصات غير متاحة إلى حد كبير للباحثين في مجال النماذج بسبب تجزؤ برمجيات المقارنة المعيارية وبروتوكولات التقييم. نتيجة لذلك، يعتمد باحثو النماذج على معايير قياسية، تُعرّف في الغالب لمهام تتفوق فيها النماذج الأساسية الجدولية أصلاً. يتم استبعاد السيناريوهات الأكثر تحدياً، مما يحد من التقدم المجدي في المجال عبر التركيز على تحسينات هامشية على البيانات المستقلة والمتطابقة التوزيع بدلاً من التحديات الأوسع والأكثر تطلباً. للتغلب على هذا، نقدم BeyondArena، أول معيار موحد وشامل للبيانات الجدولية يدعم أنواع مهام متنوعة (مستقلة ومتطابقة التوزيع، زمانية، مجمعة)، عبر مقاييس حجم العينة وأبعاد السمات، مع أنواع سمات متنوعة (مع نصوص، مع علاقات أساسية عالية) من مجموعة واسعة من التخصصات. لتمكين المقارنة المعيارية الموحدة خارج نطاق المعايير القياسية، نقدم DataFoundry، إطار عمل بلغة بايثون ومخطط بيانات وصفية لتنظيم مجموعات البيانات الجدولية للتعلم الآلي التنبؤي. تُظهر نتائجنا عبر 11 نموذجاً و142 مجموعة بيانات منظمة أن النماذج الأساسية الجدولية الحالية تتفوق على البيانات المستقلة والمتطابقة التوزيع صغيرة إلى متوسطة الحجم، بينما لا تزال النماذج التقليدية القائمة على الأشجار ونماذج التعلم العميق تهيمن على البيانات غير المستقلة والمتطابقة التوزيع، والكبيرة، وعالية الأبعاد. يوجه BeyondArena أبحاث النماذج نحو التحديات الأكثر تطلباً في البيانات الجدولية، مما يتيح التقدم نحو نماذج جدولية أساسية حقاً.
One-sentence Summary
Researchers from Prior Labs, University of Freiburg, INRIA Saclay, et al. introduce BeyondArena, the first unified benchmark for tabular data supporting IID, temporal, and grouped tasks, along with DataFoundry, a curation framework, and their evaluation across 11 models and 142 datasets shows that existing tabular foundation models excel only on small IID data while tree-based and deep learning models dominate on non-IID, large, and high-dimensional tasks, highlighting the need for truly general tabular AI.
Key Contributions
- BeyondArena is a unified benchmark consolidating IID, temporal, and grouped tabular tasks across dataset scales, feature dimensionalities, and modalities (text, high cardinality), providing standardized evaluation on 142 curated datasets from multiple disciplines.
- DataFoundry is a Python framework and metadata schema for reproducible dataset curation, enabling consistent preprocessing, validation, and benchmarking across task paradigms.
- Evaluating 11 models shows that tabular foundation models excel on small- to medium-sized IID data but are outperformed by tree-based and deep learning methods on non-IID, large, and high-dimensional data, revealing critical gaps for future models.
Introduction
Tabular foundation models (TFMs) have been evaluated extensively, but the tabular research community has mostly restricted benchmarks to independent and identically distributed (IID) tasks, ignoring the grouped and temporal splits common in real-world predictive applications. Prior efforts also suffer from fragmentation, with separate infrastructures and standards for tiny, temporal, or text-rich tables, which confuses practitioners and slows progress. The authors introduce BeyondArena, a unified benchmark that spans IID, temporal, and grouped tasks across a wide range of sample sizes, dimensionality, and feature types (including high-cardinality categorical and text data). By curating 142 high-quality datasets and integrating 11 models into the open-source TabArena ecosystem, they provide a rigorous, standardized evaluation that reveals where current TFMs excel (small- to medium-scale IID data) and where traditional models still dominate (non-IID, large-scale, high-dimensional settings).
Dataset
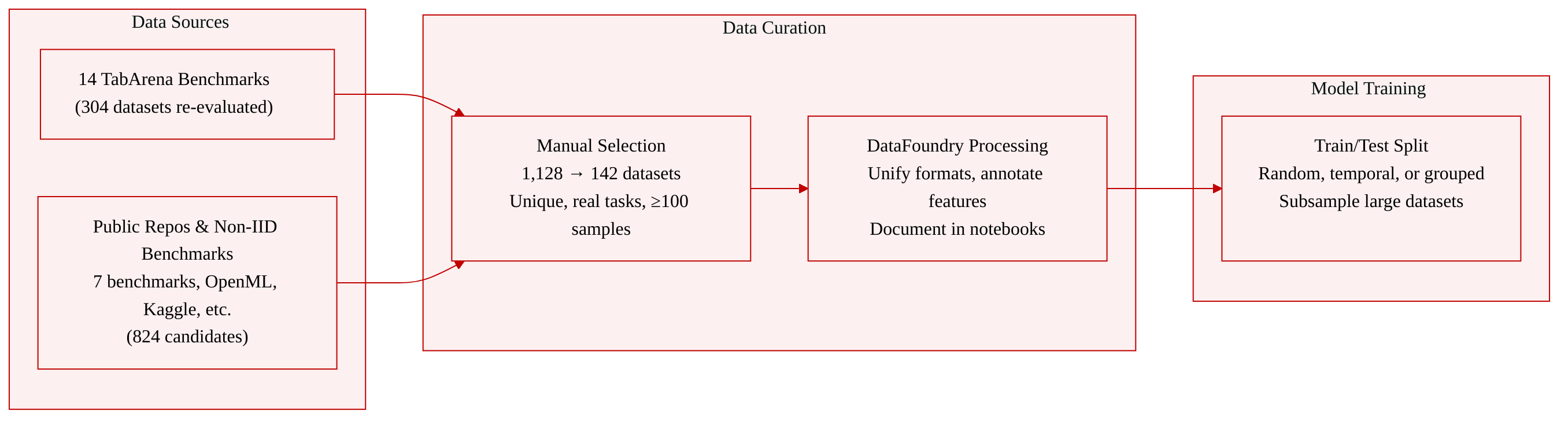
The authors curate BeyondArena, a manually verified collection of 142 tabular datasets designed to reflect challenging real-world prediction tasks. The collection extends earlier benchmarks by including non-IID scenarios (temporal and grouped splits), datasets with fewer than 500 or more than 100,000 training samples, and tables containing text and date features.
Dataset composition and sources
- The initial pool of 1,128 candidates was drawn from 21 prior tabular benchmark studies, public repositories (UCI, OpenML, Hugging Face, Kaggle, Zindi, ASlib), and government websites.
- 304 datasets from 14 earlier TabArena benchmarks (both accepted and previously rejected) were re-evaluated.
- 7 non-IID or multimodal benchmarks (TabReD, TableShift, CARTE, TextTabBench, TabSTAR, AutoGluon Multimodal, and a string vectorizing benchmark) contributed additional candidates.
Key details for each dataset
- Selection rules: A dataset must be unique within the benchmark, contain at least 100 training samples, support a random, temporal, or grouped validation split, be explicitly published for classification or regression, represent a real application (not purely synthetic or vectorized images), and raise no obvious ethical concerns.
- Filtering outcome: After manual review, 142 datasets satisfied all criteria; the majority of rejected candidates were duplicates, lacked a real-world task, or were not originally designed for supervised prediction.
- Characteristics: The final collection spans tiny to large-scale datasets, includes diverse feature types (numerical, categorical, date, text), covers both classification and regression, and comes from varied application domains. The 142 data artifacts are hosted on Hugging Face.
How the paper uses the data
- Each dataset is processed through the DataFoundry framework, which unifies file formats (CSV, Parquet, Excel) and annotates feature types, target column, and metadata for group or time indices.
- The authors define a train-test split for every dataset – random, temporal, or grouped – according to the original task description. For very large datasets, subsampling is applied to keep training manageable while preserving the task’s predictive challenge.
- No explicit mixture ratios or cropping are used; instead, the curated datasets serve as an independent benchmark suite where each dataset is evaluated individually with its designated split and preprocessing.
- Feature engineering is applied only when necessary to align with the original task (e.g., as described in a paper or winning competition solution), and all processing steps are documented in reproducible Python notebooks.
Method
The authors aim to extend tabular benchmarking to better represent challenging real-world predictive machine learning applications. To achieve this, they overhaul selection criteria to support non-IID data (temporal and grouped), datasets with fewer than 500 or more than 100,000 training samples, and tabular data containing text and date features. To ensure high quality and representativeness, the authors opt for a labor-intensive manual curation process where all results are verified by humans, which is crucial for scientific rigor.
To enable extensive and reproducible dataset curation, the authors introduce DataFoundry, a Python framework and metadata schema for tabular datasets and predictive machine learning. DataFoundry provides a mature Python package for dataset checks, train-test splits, and an extensible metadata schema, alongside reproducible Python notebooks for processing each dataset.
The authors gather datasets from 21 tabular benchmark studies and public data repositories, including UCI Machine Learning Repository, OpenML, Hugging Face, Kaggle, and others. They re-evaluate datasets from prior benchmarks and collect from non-IID or multimodal tabular benchmarks.
A dataset must fulfill specific criteria to be included in BeyondArena: it must represent a unique predictive machine learning task, have at least 100 training samples to avoid few-shot tasks, support appropriate validation protocols such as random, temporal, or grouped splits, be published for predictive classification or regression, represent a real-world application problem, and raise no obvious ethical concerns.
The selection workflow is illustrated in the figure below:
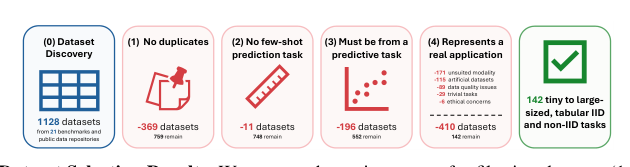
Starting with 1128 datasets from various sources, the authors filter out duplicates, few-shot prediction tasks, non-predictive tasks, and datasets that do not represent real applications. This rigorous filtering results in 142 selected datasets ranging from tiny to large-scale, covering tabular IID and non-IID tasks.
Each selected dataset is thoroughly investigated and integrated into DataFoundry. The authors unify data formats and feature type annotations, including numbers, categorical, dates, and strings. They store necessary metadata for tasks and curation annotations in a machine-readable schema. Feature engineering is applied when necessary to create appropriate tasks.
The characteristics of the curated datasets are detailed in the following figure:
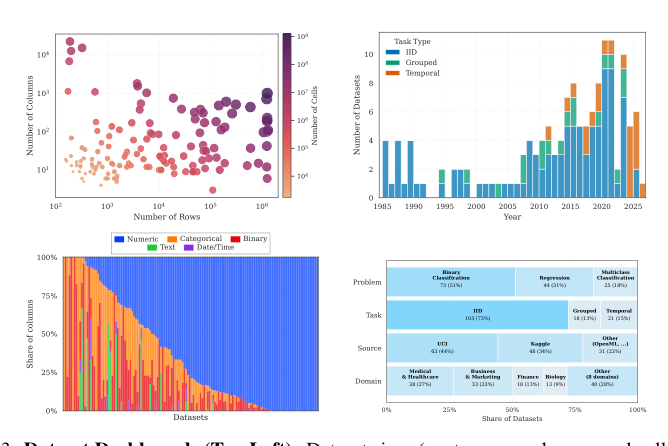
The datasets vary widely in size regarding rows, columns, and cells, as well as age and feature types such as numeric, categorical, binary, text, and date/time. They cover diverse problem types including binary classification, regression, and multiclass classification, along with various task types like IID, grouped, and temporal. The collection spans multiple sources and application domains, including medical and healthcare, business and marketing, finance, and biology.
Experiment
The BeyondArena benchmark evaluates 11 tabular models, including several tabular foundation models (TFMs), across diverse dataset characteristics like scale, dimensionality, task type, and feature types. While TFMs perform strongly on small, tiny, and IID datasets, they are consistently outperformed by well-tuned traditional models—especially deep networks such as RealMLP—on temporal, grouped, large-scale, high-dimensional, and high-cardinality tasks. Overall, TFMs can match or beat the best traditional model on 70% of datasets, but their pretrained generality falls short in many real-world non-IID regimes, illustrating the need for further development. Ablations confirm the importance of using appropriate non-IID splits and preprocessing, and show that post-hoc calibration generally improves log-loss performance.
Ablations confirm that BeyondArena's inner split choices (repeated 5-fold CV and non-IID splits) are robust, consistently improving average performance while maintaining ranking stability. Preprocessing decisions for grouped and text data have mixed effects: handling group indices for label-per-sample data heavily alters rankings, and using TF-IDF over Qwen3 embeddings for long text features yields large performance gains without disrupting model ordering. Post-hoc probability calibration nearly always beats the uncalibrated default, except for a few specific models. Replacing 8-fold CV with 5×5-fold CV improves performance across models while keeping rankings nearly unchanged (τ=0.93). Using non-IID inner splits instead of IID splits for temporal and grouped data achieves better average performance and leaves model ranks identical (τ=1.00). For label-per-sample grouped datasets, dropping index preprocessing substantially scrambles model rankings (τ=0.43), though BeyondArena's preprocessing still wins 71% of the time. On long text datasets, switching from Qwen3 embeddings to TF-IDF drastically improves predictive performance, with BeyondArena's Qwen3 setting winning only 6% of comparisons yet rankings remaining highly correlated (τ=0.89). Applying post-hoc probability calibration outperforms the no-calibration default in 82% of cases, but can negatively impact TabPFN-2.6 and RealMLP.

Ablation experiments confirm that BeyondArena's inner split strategies—repeated 5-fold cross-validation and non-IID splits—consistently boost average performance while keeping model rankings stable. Preprocessing decisions for grouped and text data have mixed effects: handling group indices is essential for label-per-sample datasets, and using TF-IDF instead of Qwen3 embeddings on long text features yields large predictive gains without disrupting model ordering. Post-hoc probability calibration nearly always outperforms the uncalibrated default, though it can negatively affect TabPFN-2.6 and RealMLP. Overall, the core design choices are robust, with calibration and careful preprocessing being key to performance without harming rank consistency.