Command Palette
Search for a command to run...
SingGuard: حاجز حماية متعدد الوسائط لنماذج اللغة الكبيرة متكيف مع السياسات مع استدلال ديناميكي
SingGuard: حاجز حماية متعدد الوسائط لنماذج اللغة الكبيرة متكيف مع السياسات مع استدلال ديناميكي
الملخص
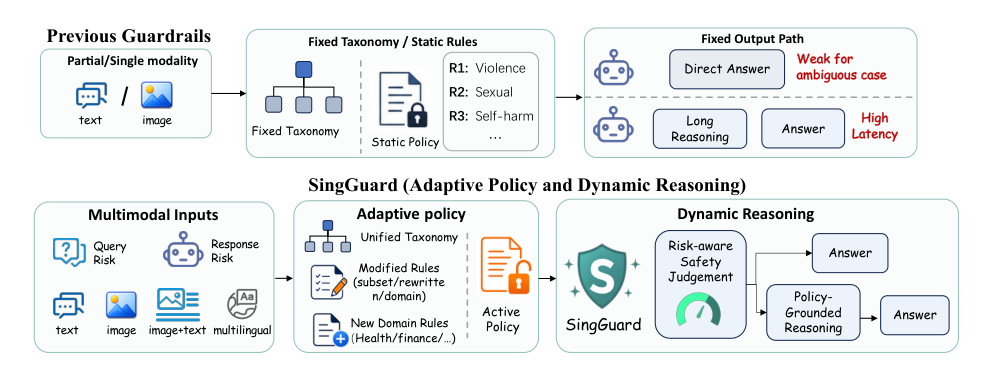
تُنشر نماذج الرؤية واللغة (VLMs) بشكل متزايد في التطبيقات الاستهلاكية والطبية والمالية والمؤسسية. يوسّع هذا الانتشار الواسع سطح الأمان: قد تنشأ المخاطر من الإجابة على الأسئلة متعددة الوسائط، واستجابات المساعد، والتركيب عبر الوسائط، بينما قد تختلف سياسات الإشراف عبر المنتجات والمناطق ومراحل النشر. تعتمد معظم حواجز الحماية الحالية إما على تصنيفات ثابتة أو تستهدف مجموعة ضيقة من إعدادات التفاعل، مما يحد من قدرتها على التكيف عندما تتغير قواعد الأمان في وقت النشر. نقدم SingGuard، عائلة نماذج حواجز حماية متعددة الوسائط متكيفة مع السياسات لتقييم الأمان في المحادثات متعددة الوسائط. يتعامل SingGuard مع السياسة النشطة كمدخل في وقت التشغيل: بناءً على القواعد المقدمة باللغة الطبيعية، يتحقق من المحتوى المستهدف مقابل كل قاعدة من قواعد السياسة النشطة ويتنبأ بكل من تسمية الأمان والقاعدة التي تم تفعيلها. لتحقيق التوازن بين الكفاءة والقابلية للتفسير، يدعم SingGuard أنظمة استدلال سريعة وهجينة وبطيئة على طول طيف من الاستدلال السريع إلى البطيء، يتراوح بين أحكام الأمان المباشرة والمداولات المستندة إلى السياسة. نقوم بتحسين هذا السلوك بشكل أكبر باستخدام التعلم المعزز المنفصل بين السريع والبطيء. نقدم أيضًا SingGuard-Bench، معيارًا لحواجز الحماية متعددة الوسائط يحتوي على 56,340 مثالًا تغطي أكثر من 80 نوعًا دقيقًا من المخاطر عبر إعدادات الأسئلة والأجوبة متعددة الوسائط والهجمات العدائية وتقييم القواعد الديناميكية، بما في ذلك حالات المخاطر المشتركة عبر الوسائط حيث تكون كل وسيطة غير ضارة بمعزل عن الأخرى ولكن تركيبهما يشير إلى نية غير آمنة. عبر ست عائلات من المعايير (35 مجموعة بيانات)، يحقق SingGuard متوسط F1 متطور في كل عائلة. يُظهر تقييم القواعد الديناميكية أيضًا تحسنًا في دقة اتباع السياسة من 0.6465 إلى 0.7415 في ظل تغييرات السياسة في وقت التشغيل. الكود الخاص بنا متاح على https://github.com/inclusionAI/Sing-Guard.
One-sentence Summary
Ant Group's AI Security Lab presents SingGuard, a policy-adaptive multimodal guardrail model family that treats active safety rules as a runtime input, supports fast-to-slow reasoning via fast, hybrid, and slow inference regimes optimized with fast-slow decoupled reinforcement learning, and achieves state-of-the-art average F1 across six benchmark families (35 datasets) on SingGuard-Bench, a 56,340-example benchmark covering over 80 fine-grained risk types including cross-modal joint-risk cases, while raising dynamic policy-following accuracy from 0.6465 to 0.7415 under runtime policy shifts.
Key Contributions
- The paper introduces SingGuard, a policy-adaptive multimodal guardrail model that takes natural-language safety policies as runtime input, performs rule-by-rule matching, and supports fast, hybrid, and slow inference regimes with fast-slow decoupled reinforcement learning for efficient, interpretable moderation.
- It constructs SingGuard-Bench, a comprehensive multimodal guardrail benchmark with 56,340 examples covering over 80 fine-grained risk types, cross-modal joint-risk cases, and dynamic-rule evaluation settings to test policy-adaptive safety assessment.
- Extensive experiments across 35 datasets demonstrate that SingGuard achieves state-of-the-art average F1 in every benchmark family, and dynamic-rule evaluation shows policy-following accuracy rising from 0.6465 to 0.7415 under runtime policy shifts.
Introduction
Vision-language models are now widely deployed across consumer assistants, creative tools, and high-stakes domains like medicine and finance, greatly expanding the safety surface. Moderation demands change with product, region, and deployment stage, so a practical guardrail must condition its decisions on an active policy supplied at runtime, not merely classify against a static taxonomy. Prior text guardrails achieve strong moderation but rely on fixed label sets with little runtime flexibility. Multimodal guardrails extend to visual inputs yet still assume static policy boundaries and classify risk directly rather than matching content against an open set of rules. Policy-adaptive efforts show that fixed-policy training degrades under unseen rules, but they remain focused on narrow settings rather than general multimodal QA and response moderation. Reasoning-based systems improve auditability but force a single always-on heavy inference mode that adds latency on routine cases. To address these gaps, the authors introduce SingGuard, a policy-adaptive multimodal guardrail family that accepts open runtime policies and performs rule-by-rule matching. It supports fast, hybrid, and slow inference regimes along a spectrum, combined with a fast–slow decoupled reinforcement learning objective that preserves low-latency judgments while reducing their anchoring effect on policy-grounded reasoning. The work also contributes SingGuard-Bench, a comprehensive multimodal guardrail benchmark covering dynamic rules, attack transformations, and cross-modal joint-risk scenarios.
Dataset
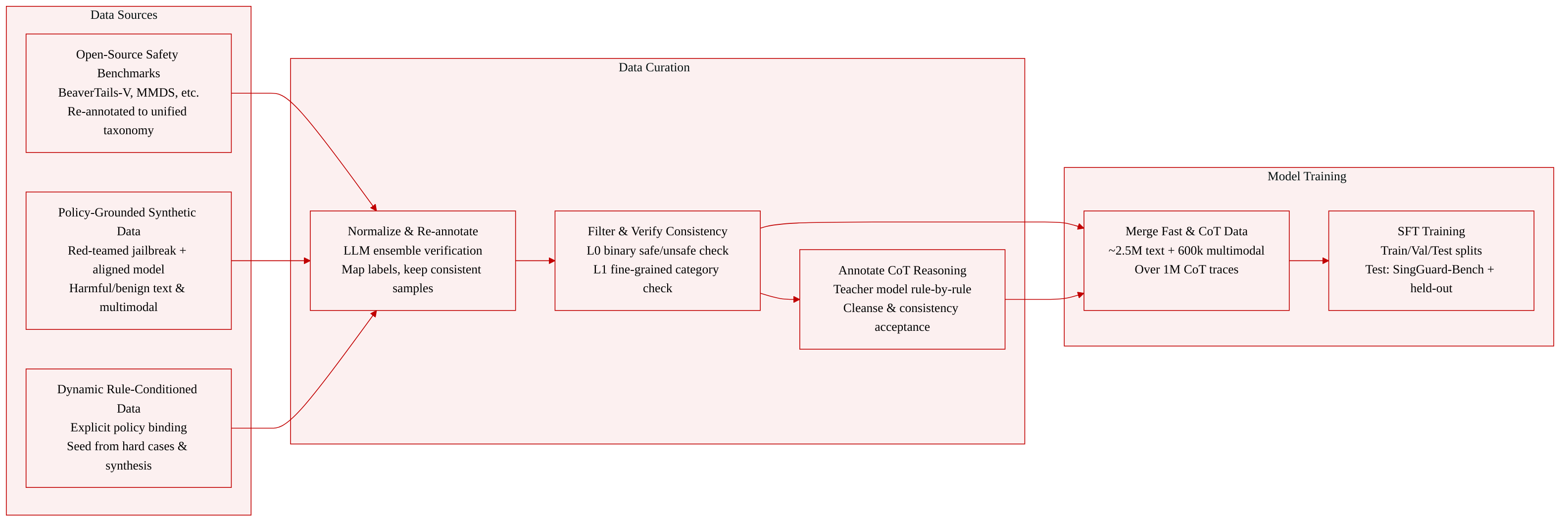
The authors construct a large-scale training corpus for the SingGuard guardrail model and a separate policy-conditioned evaluation benchmark, SingGuard-Bench.
Training corpus
- Size: ~2.5 million text samples, ~600k multimodal samples; over 1 million samples carry chain-of-thought (CoT) reasoning traces.
- Sources and composition:
- Re-annotated open-source data: Public safety datasets (e.g., BeaverTails-V, MMDS, UnsafeBench) are normalized into a unified risk taxonomy through an LLM-driven pipeline. An ensemble of models (Qwen3.5-397B, KIMI-K2.6, GLM4.5V) verifies label mappings; only samples with consistent binary safety and fine-grained category decisions are kept. Ambiguous or hard cases are recycled as seeds for later synthesis.
- Policy-grounded synthetic data: Safety policies are decomposed into fine-grained categories. A red-teamed jailbreak model generates harmful prompts and responses, while an aligned model produces harmless contrastive examples, refusals, and safe completions. Multimodal data is synthesized by pairing harmful/benign images and texts, including cross-modal attacks where a harmful intent is split across modalities so each appears safe alone. All samples are re-verified to match the intended labels.
- Dynamic rule-conditioned data: (Referenced in Section 2.3.3) Samples are paired with explicit policies, binding the safety decision to the active rule rather than a fixed taxonomy.
- CoT reasoning data: Built on top of fast-judgment samples by annotating rule-by-rule. A teacher model checks each policy rule for hit/not-hit/not-applicable, aggregates per-rule evidence, and outputs the final unsafe (with rule title) or safe. Traces pass a structural cleansing step and a two-stage consistency check (CoT coherence and answer-label match).
- Format: Uniform schema with user query, optional images, optional assistant response, and dialogue context. Query-side and response-side labels are kept separate to support prompt screening, response checking, and joint moderation.
- Usage: All data is merged and used during cold-start supervised fine-tuning (SFT). CoT examples are combined with fast-judgment examples to train the hybrid reasoning interface.
SingGuard-Bench benchmark
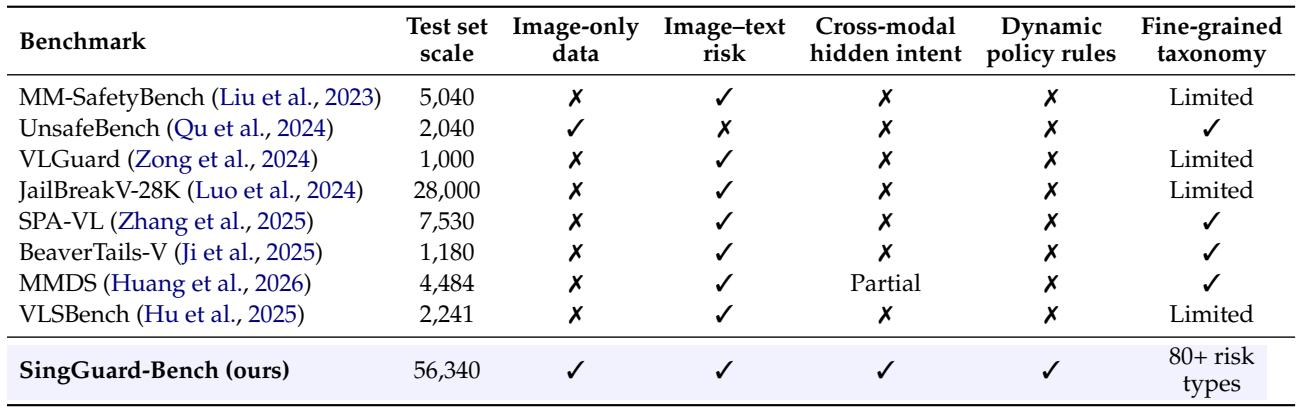
- Size: 56,340 test examples: 40,663 image-only, 13,677 multimodal, 2,000 dynamic-rule.
- Subset composition:
- Image subset: 10,697 unsafe images and 29,966 benign-sensitive images covering bottom-line visual risks and precision challenges.
- Multimodal subset: 6,487 unsafe and 7,190 benign-sensitive image-text pairs, annotated with safety subtypes (e.g., Image-Unsafe/Text-Safe, hidden-intent where both modalities appear safe alone).
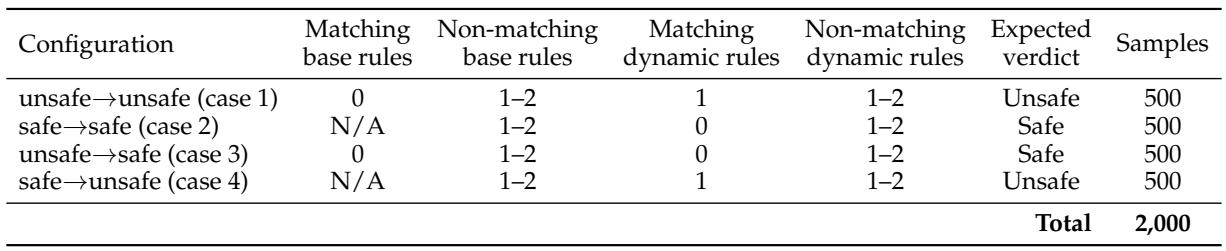
- Dynamic-rule subset: 2,000 examples paired with active policies containing matching and distracting rules, evenly distributed across four policy-shift configurations (unsafe→unsafe, unsafe→safe, safe→unsafe, safe→safe).
- Key features: Over 80 fine-grained risk types, extensive benign-sensitive content (~68.4% of image+multimodal samples), cross-modal hidden-intent attacks, and dynamic policy adaptation. Construction uses keyword generation, knowledge-graph association, data supplementation, and multi-model quality filtering.
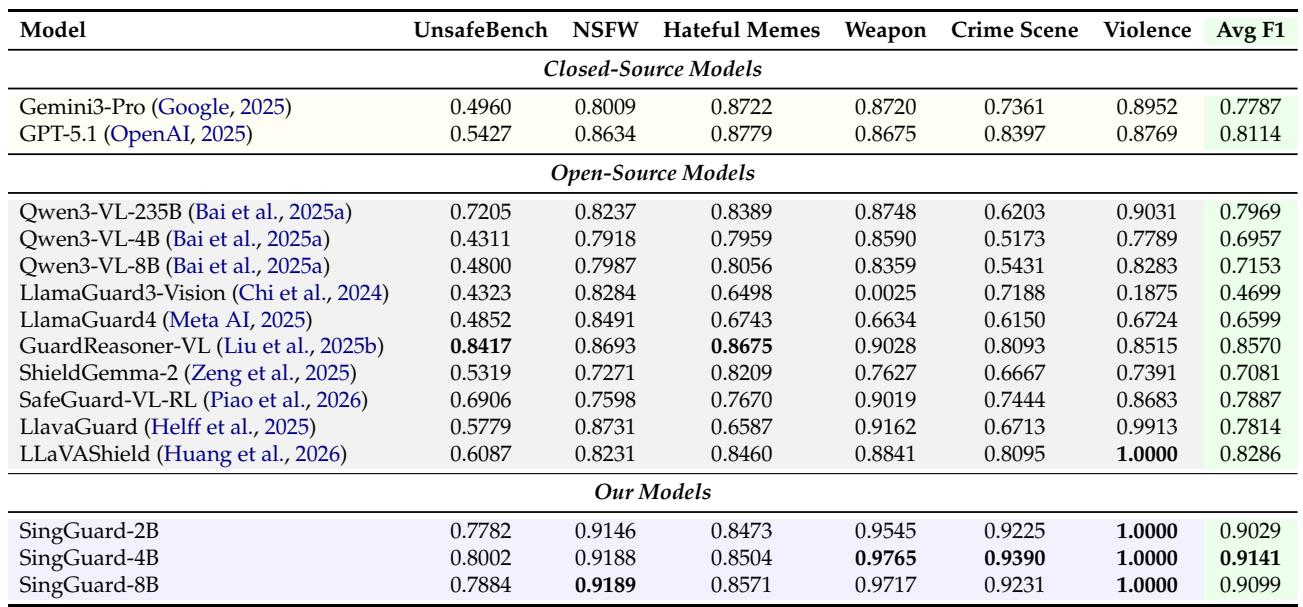
- Keyword coverage: 78 leaf nodes, 2,124 keywords per language (English and Chinese), with intentional cross-node overlap to capture real-world concept ambiguity.
Method
The authors introduce SingGuard, a policy-conditioned multimodal guardrail model that addresses three key limitations of static safety classifiers. First, rather than relying on a fixed taxonomy, SingGuard accepts an active safety policy at runtime and grounds its decision in the supplied rules. Second, to prevent the initial quick judgment from anchoring subsequent reasoning, training combines cold-start supervised fine-tuning (SFT) with a fast–slow decoupled reinforcement learning stage. Third, the model supports three inference modes—fast direct judgment, slow rule-by-rule reasoning, and a hybrid early-exit regime—enabling a tunable trade-off between latency and depth of verification.
The task is formulated as instruction-following. Given an input x=(q,I,a) consisting of a user query, optional images, and an optional assistant response, together with an active policy P={r1,…,rn}, the model learns a mapping
fθ(x,P)→(y,z,c),where y∈{safe,unsafe} is the overall label, z is an optional rule-by-rule reasoning trace, and c∈T(P)∪{Safe} is the final triggered category or rule title. This formulation covers query-only, response-only, and query–response moderation, and the decision is always bound to the currently active policy.
The method is built on a unified hierarchical safety taxonomy containing 8 primary dimensions, 27 secondary categories, and over 80 fine-grained risk types. This taxonomy serves as the built-in default policy, but at inference time the active policy can be instantiated as the full taxonomy, a subset, a narrowed or expanded version, or newly introduced domain-specific rules. The design forces the model to re-derive its judgment from the provided rule set rather than memorizing static category names.
To train policy-adaptive behavior, the authors construct a large-scale corpus through four complementary processes: re-annotation of open-source safety data, policy-grounded synthetic data generation, dynamic rule-conditioned data construction, and chain-of-thought (CoT) reasoning annotation. Open-source data are normalized into the unified taxonomy via an LLM-driven re-annotation pipeline with two-level consistency checks (binary safe/unsafe and fine-grained category). Synthetic pipelines compose harmful and benign text-image pairs, cross-modal attacks where intent is split between modalities, and multilingual variants, each verified for policy consistency. Dynamic rule data create multiple policy views for the same content—full rules, subsets, single rules, and merged or rephrased rules—and introduce counterfactual supervision where the label is recomputed under edited or newly generated audit rules, producing label transitions such as unsafe→safe or safe→unsafe. Finally, over 1 million CoT examples are generated in a rule-grounded manner: a teacher model walks through each active rule step by step, records hit/not-hit/not-applicable judgments with evidence, and aggregates them into the final answer. These examples undergo structural cleansing and a two-stage consistency check (CoT coherence and answer-rule matching) before being merged with direct-judgment data.
The training pipeline consists of two stages. Stage 1 is a policy-conditioned cold-start SFT that establishes a shared output grammar. All samples follow a unified schema: a fast form emits a plain safe or unsafe token followed by the <answer> rule title; a slow form inserts a <reasoning> span where the model summarizes the content, checks each active rule, and produces a reviewed answer. The reasoning span is structured as z=(zsummary,m1,…,mn,zfinal) with per-rule judgments mi∈{hit,not-hit,not-applicable}. The objective is a field-weighted autoregressive loss:
where Lreason is masked for fast-only samples. This stage mixes a large pool of fast-judgment examples with a smaller set of verified CoT traces, teaching the model both direct classification and rule-by-rule reasoning under varying policy presentations.
Stage 2 applies fast–slow decoupled DAPO (decoupled alignment via policy optimization) to address the anchoring effect of the initial judgment. The model starts from the SFT checkpoint and samples a group of G candidate outputs, each following the same <fast> → <reasoning> → <answer> format. A two-level reward function
scores the final answer’s safety polarity and exact rule selection. Rewards are group-normalized to compute advantages
Ai=std({Rj})+ϵRi−mean({Rj}).To decouple fast and slow thinking, the first generated response token is masked during the RL update, so it receives neither advantage nor policy-gradient loss. The subsequent reasoning and answer tokens are still optimized with the group-relative reward, allowing the slow path to correct an unreliable initial judgment. This stage preserves the fast path for easy cases while giving the reasoning span room to revise decisions, particularly on policy-shifted examples where the taxonomy prior is uncertain.
After training, SingGuard supports three inference modes. Fast mode directly emits the opening safety label and the <answer> field, suitable for low-latency moderation. Slow mode treats the initial decision as provisional, performs full rule-by-rule verification in <reasoning>, and outputs a reviewed answer. Hybrid mode implements adaptive early exit: the model decodes only the initial binary label and accepts it when the normalized confidence
satisfies s(y0)≥τ. Otherwise, generation continues to produce the slow-mode reasoning trace and reviewed answer. This allows deployment to balance speed and auditability without a separate routing model.
Finally, a model distillation stage transfers the 8B model’s policy-grounded reasoning to a 2B student. Using on-policy generalized knowledge distillation (GKD), the student samples its own responses, and the frozen teacher provides token-level target distributions. The bidirectional distillation objective
LGKD=Ex,y^∼πθ[αDKL(πϕteacher∥πθ)+(1−α)DKL(πθ∥πϕteacher)]aligns the student with the teacher on its own generation trajectories, exposing the teacher to the student’s typical errors on dynamic rules and edge cases. This improves the compact model’s policy-following and reasoning quality while preserving low-latency deployment.
Experiment
SingGuard is evaluated across six safety axes covering multimodal, image, text query and response, multilingual, and dynamic policy adaptation, with SingGuard models consistently achieving leading results over open-source baselines and often surpassing closed-source alternatives. The experiments highlight robust transfer from intent detection to assistance detection, consistent cross-lingual performance, and reliable policy-following even when active rules change. Ablations confirm that reinforcement learning and hybrid routing improve safety while controlling latency, and on-policy distillation effectively transfers broad safety behavior to smaller models.
Existing multimodal safety benchmarks focus primarily on image-text risk but largely omit image-only content, cross-modal hidden intent, dynamic policy rules, and fine-grained taxonomies. Only one benchmark includes image-only data, only one partially addresses hidden intent, and none combine all evaluation axes. SingGuard-Bench fills these gaps with a unified 56,340-example suite that spans all dimensions. Only UnsafeBench provides image-only data, while all other compared benchmarks lack this modality and none cover cross-modal hidden intent aside from a partial instance in MMDS. No prior benchmark supports dynamic policy rules or combines them with fine-grained risk categories; most offer only limited or absent per-category detail.
The dynamic-rule subset contains 2,000 samples evenly divided across four policy-shift configurations, each pairing a sample with an active policy that includes matching and distracting rules. Evaluations show that models often fail when the policy requires a verdict opposite to their training-time default, especially in the safe-to-unsafe case, but SingGuard's slow reasoning mode improves accuracy on this challenging shift from 0.38 to 0.57. The four configurations cover all combinations of verdict change: unsafe remains unsafe, safe remains safe, unsafe becomes safe, and safe becomes unsafe, each with 500 samples. Qwen baselines perform well when the active policy matches the default label but drop sharply on policy-shift splits, with safe-to-unsafe accuracy reaching only 0.38. SingGuard-slow achieves the highest average dynamic-policy accuracy (0.7415) and lifts safe-to-unsafe accuracy to 0.57, demonstrating better enforcement of newly introduced restrictions. The hybrid SingGuard variant maintains the strongest unsafe-to-unsafe score while balancing safety and latency, keeping performance close to slow-mode reasoning.
The safety taxonomy covers seven primary unsafe risk categories, defined by 78 fine-grained leaf nodes and 2,124 aligned English–Chinese keyword pairs. Keyword breadth is uneven: Crimes and Public Safety, Unethical/Moral, and Cybersecurity hold the most keywords, while Agent Safety and Animal Abuse are comparatively narrow. Every English keyword has an exact one-to-one Chinese counterpart, ensuring consistent bilingual coverage for policy evaluation. The taxonomy spans seven unsafe primary categories (A–G), excluding the benign-sensitive class. Crimes and Public Safety, Unethical/Moral, and Cybersecurity together account for the majority of the 2,124 keyword pairs. Agent Safety is the smallest risk category, with only two leaf nodes and 47 English–Chinese keyword pairs. Leaf node counts generally correlate with keyword volume, but categories like Cybersecurity have fewer leaf nodes yet a similar keyword count to Unethical/Moral. English and Chinese keywords are consistently matched one-to-one, with no gaps in bilingual alignment.
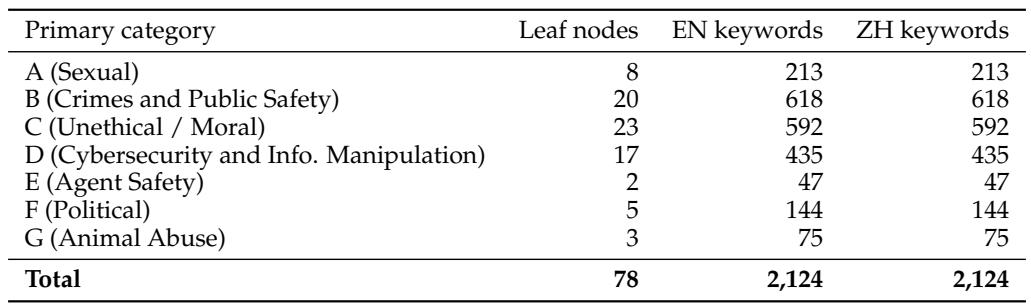
SingGuard-8B sets a new state-of-the-art macro-average F1 of 0.9092 on the multimodal safety suite, surpassing the previous best open-source model LLaVAShield and GPT-5.1. The smaller SingGuard-2B and SingGuard-4B variants also outperform all existing open-source models, demonstrating a Pareto improvement across model sizes. On individual benchmarks, SingGuard-8B excels on VLGuard and SPA-VL, while LLaVAShield retains top scores on several jailbreak and MMDS splits, and ShieldGemma-2 leads on BeaverTails-V. SingGuard-8B achieves the highest macro-average F1, outperforming both the best open-source baseline and the closed-source GPT-5.1. Every SingGuard size pushes the Pareto frontier, with the 2B and 4B variants already exceeding all prior open-source models. LLaVAShield keeps the lead on JailBreakV, VLSBench, MM-Safety, and both MMDS query and response splits, while ShieldGemma-2 remains strongest on BeaverTails-V. Jailbreak-oriented benchmarks are saturated by guards that train on jailbreak templates, leaving little room for further improvement on those datasets.
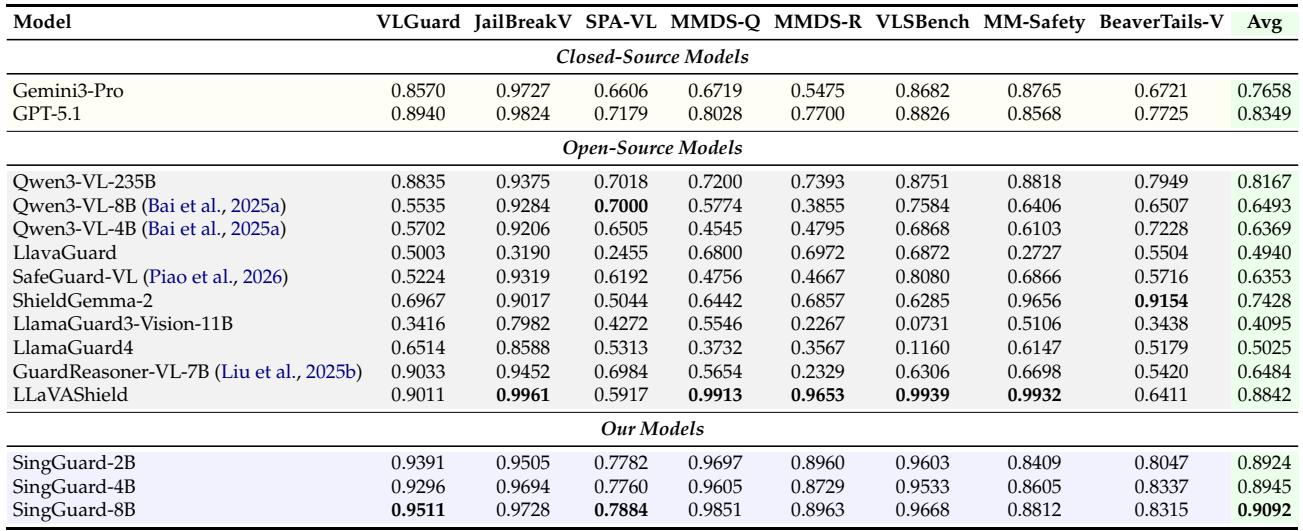
SingGuard models achieve the highest macro-average image safety F1, outperforming the best open-source baseline GuardReasoner-VL and closed-source frontier models. SingGuard leads on NSFW, weapon, and crime-scene detection, while GuardReasoner-VL retains the lead on UnsafeBench and Hateful Memes. Several text-trained guards collapse on purely visual slices like weapon and violence, underscoring the need for genuine multimodal training. SingGuard-4B attains the strongest macro-average F1 (0.9141), with the 2B and 8B variants close behind. SingGuard leads on NSFW, weapon, and crime-scene detection and matches the saturated violence benchmark at F1=1.0. GuardReasoner-VL is the best open-source baseline on UnsafeBench (0.8417) and Hateful Memes (0.8675). LlamaGuard3-Vision collapses to near-zero F1 (0.0025) on weapon detection, revealing a failure of purely text-trained guards on visual threats. All SingGuard variants surpass both closed-source models (Gemini3-Pro and GPT-5.1) on average image safety F1.
SingGuard-Bench fills missing evaluation dimensions in multimodal safety, including image-only content, hidden intent, and dynamic policies, with a 56K-example suite and a fine-grained bilingual taxonomy of 2,124 keyword pairs. SingGuard models achieve state-of-the-art safety F1 on the multimodal suite and on image-only threats, surpassing all prior open-source and closed-source models, and demonstrate improved enforcement under policy shifts through slow reasoning. Text-only guards collapse on visual dangers, confirming the necessity of genuine multimodal training.