Command Palette
Search for a command to run...
ReFreeKV: نحو ضغط ذاكرة التخزين المؤقت KV بدون عتبة
ReFreeKV: نحو ضغط ذاكرة التخزين المؤقت KV بدون عتبة
Xuanfan Ni Liyan Xu Chenyang Lyu Longyue Wang Mo Yu Lemao Liu Fandong Meng Jie Zhou Piji Li
الملخص
لتقليل استهلاك الذاكرة أثناء استدلال نماذج اللغة الكبيرة، تم اقتراح عدد من الطرق لتقليم ذاكرة التخزين المؤقت KV. بينما يمكن لهذه التقنيات تحقيق تقليل غير مفقود للذاكرة على العديد من مجموعات البيانات، فإنها غالبًا ما تعتمد على شرط غير مُشدد عليه: يجب تحديد عتبة خاصة بالمدخلات/المجال لميزانية ذاكرة التخزين المؤقت KV مسبقًا لتحقيق الأداء الأمثل. ومع ذلك، قد يكون هذا التصميم الحساس للمدخلات محدودًا بشكل كبير في السيناريوهات الواقعية، حيث تمتد المدخلات مفتوحة المجال عبر مجالات وأطوال ومستويات صعوبة متنوعة، دون حدود واضحة لاختيار العتبة. نتيجة لذلك، يمكن أن يكون الاعتماد على هذه العتبة الحساسة للمدخلات قيدًا أساسيًا يسبب تدهورًا كبيرًا على المدخلات العشوائية. في هذا العمل، نقترح هدفًا جديدًا يرفع قيود العتبة لضغط KV قوي، داعين إلى طرق "خالية من العتبة" تضبط تخصيص الميزانية بشكل تكيفي مع الحفاظ على أداء الذاكرة المؤقتة الكاملة. ثم نقترح طريقة جديدة، ReFreeKV، تمثل أول تجسيد لهذا الهدف. تُظهر التجارب الموسعة عبر 13 مجموعة بيانات ذات أطوال سياق وأنواع مهام وأحجام نماذج متنوعة فعاليتها وكفاءتها. تم إصدار الكود الخاص بنا علنًا على https://github.com/Patrick-Ni/ReFreeKV.
One-sentence Summary
A team from Nanjing University of Aeronautics and Astronautics, WeChat AI, Tencent, and Fudan University proposes ReFreeKV, a threshold-free KV cache compression method that adaptively allocates budget to eliminate input-sensitive threshold tuning and preserve full-cache performance, achieving robust lossless memory reduction across diverse open-domain inputs as demonstrated on 13 datasets with varying context lengths, task types, and model sizes.
Key Contributions
- The paper introduces a threshold‑free objective for KV cache compression that adaptively allocates cache without input‑specific budget thresholds, preserving full‑cache performance across diverse open‑domain inputs.
- ReFreeKV realizes this objective using a universal stopping metric (Uni‑Metric) insensitive to input domain and sequence length, enabling compression ratios to self‑adjust to task complexity without manual calibration.
- Experiments on 13 datasets spanning reasoning, reading comprehension, and coding with multiple LLM sizes show ReFreeKV slightly surpasses full‑cache performance on average, automatically using a 63.7% KV budget ratio on Llama3‑8B, and is the only method that sustains robust compression while preserving full‑cache performance across datasets without per‑input threshold tuning.
Introduction
Transformer-based large language models (LLMs) perform autoregressive generation with a KV cache that stores intermediate key-value states for all previous tokens. This cache consumes substantial GPU memory and drives up inference latency, especially as model size and sequence length grow—for example, Llama3-70B can require 50 GB of memory for 20K tokens. Prior work reduces the cache footprint by pruning or compressing less critical entries, but nearly all existing methods rely on a data-dependent budget threshold (e.g., a fixed ratio or token count) that is tuned on a specific benchmark. Such thresholds fail to generalize across mixed real-world inputs with different domains, difficulties, and lengths, causing large performance drops when the fixed budget is inadequate or wasteful. The authors address this fragility by proposing ReFreeKV, a threshold-free KV cache pruning method that eliminates the need for per-dataset threshold calibration. It ranks KV positions by importance and applies a universal stopping criterion that is insensitive to input variations, dynamically adjusting the cache budget to maintain full-cache-level performance across diverse tasks without manual tuning.
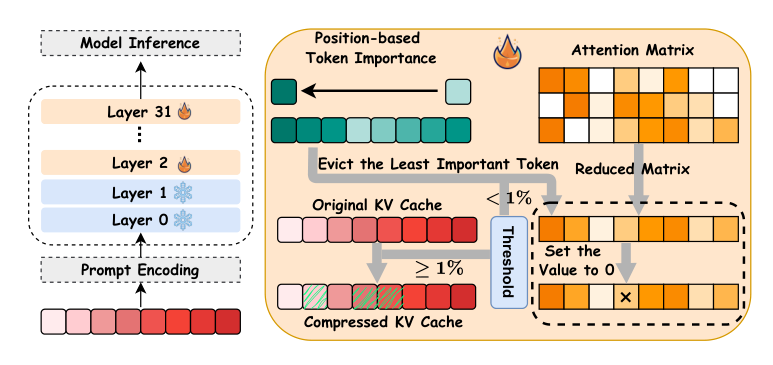
Method
The authors proposeReFreeKV, a threshold-free KV cache compression method designed to maintain consistent performance comparable to full-cache regardless of the input, without requiring input-specific threshold tuning. The method consists of two stages implemented with efficient parallel operators: an initial ranking stage and an eviction stage based on an input-insensitive threshold metric called Uni-Metric.
Initial Ranking The first stage ranks all KV cache positions per layer and per attention head. Building on the observation that positions at the beginning of the input and the latest positions generally play a more critical role, the authors rank the KV cache by token positions. For an input sequence X={x1,x2,...,xn}, the initial ranking takes the first m positions and reversely takes the remaining n−m positions, denoted by X={x1,x2,...,xm,xn,xn−1,...,xm+1}. This position-based ranking serves as an inductive bias, making the subsequent subset selection tractable.
Eviction by Uni-Metric Following the initial ranking, ReFreeKV sequentially retains KV vectors until a stopping condition is met. The authors utilize the Frobenius norm of the attention matrix A∈Rn×n as the Uni-Metric, denoted as ∥A∥F=∑i=1n∑j=1n∣Ai,j∣2. For each position i in the ranked sequence, they compare the Frobenius norm of the original attention matrix with that of a curated attention matrix ∥Ai∥F, where scores to all positions beyond i are masked out. The pruning position iprune is determined when the norm difference reaches a threshold T: iprune=argminj=1n(1−∥A∥F∥Aj∥F<T)
The Universal Threshold To fulfill the threshold-free objective, the threshold T must ensure near lossless pruning invariant to inputs. Empirical search identifies T=1% as a robust choice that balances minimal degradation with maximal cache eviction. As shown in the figure below:
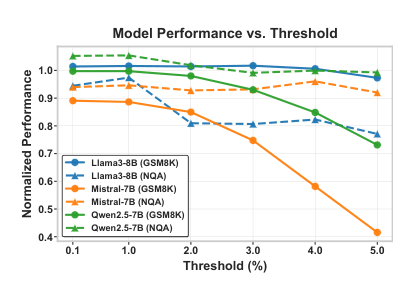
Performance remains comparable to the full-cache version robustly when T≤1%.
Reducing Overhead and Implementation Since calculating the norm on the full attention matrix grows by O(n2), the authors approximate the norm calculation by O(n). They reduce A by taking the average of its last k rows to a single attention vector A′∈R1×n. The score for a position i is: A′[i]=∑j=kn1{Ai,j=0}∑j=knAi,j This allows the pruning position to be determined directly using PyTorch cumulative-sum and where operators in parallel, avoiding explicit looping. Furthermore, aligned with prior works, the authors always retain the full KV cache of the first two layers, as early layers are crucial for semantic understanding. For batch processing, shorter cache segments are padded, and attention masks are updated accordingly. The performance versus efficiency trade-off is shown in the figure below:
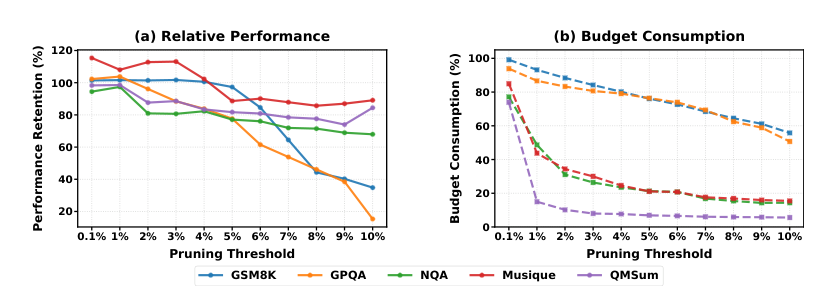
Setting the universal threshold to 1% maintains robust full-cache performance while substantially reducing the KV cache budget.
Experiment
The experiments assess Re-FreeKV across multiple LLM families (Llama3, Mistral, Qwen2.5) and diverse short- and long-context reasoning, QA, and summarization tasks, comparing it against fixed-budget baselines (H2O, StreamingLLM, SnapKV, PyramidKV, CAKE) and the adaptive method Twilight. Re-FreeKV automatically adjusts compression to preserve near-lossless performance, often surpassing full-cache scores while using less memory, and it avoids the input-specific budget tuning that degrades fixed-budget methods at lower ratios. Efficiency analysis shows minimal pruning overhead and improved end-to-end generation speed, with ablation studies confirming that relying on the last token’s attention, position-based ranking, and a 1% universal threshold yields robust generalization even to larger models without hyperparameter changes.
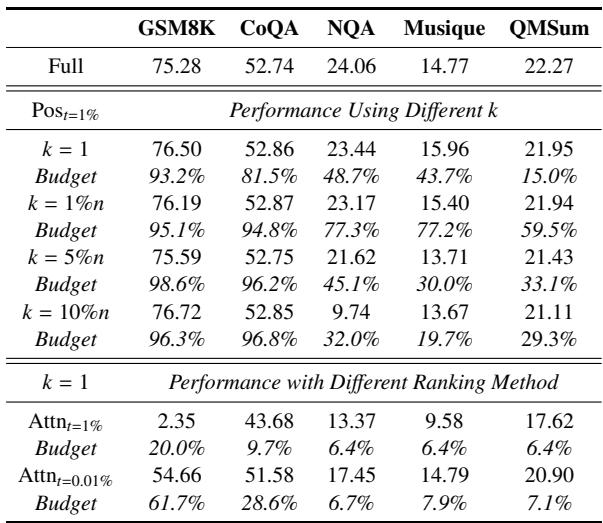
KV pruning methods with a preset budget threshold show highly inconsistent performance across domains. Tasks like CoQA remain robust even under aggressive pruning, while GSM8K and GPQA suffer catastrophic drops, making per‑task budget tuning unavoidable for achieving acceptable accuracy. At a 50% budget, SnapKV retains virtually full CoQA performance but plummets to 17% of full‑cache score on GSM8K. SLM’s relative CoQA score declines from 85% to 76% when the budget is tightened from 50% to 20%. GSM8K is acutely sensitive to KV pruning: H2O achieves only 3% of full‑cache performance at a 20% budget.
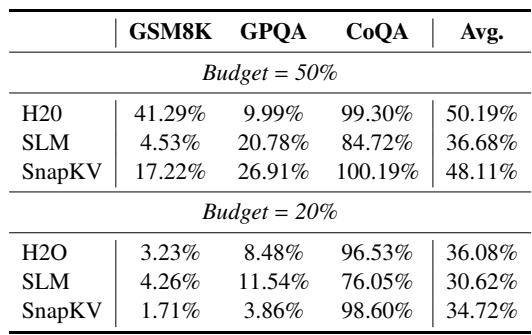
ReFreeKV dynamically adapts KV cache retention to each input, achieving full-cache-level performance across diverse tasks while using only 63.7% of the cache on average. In contrast, fixed-budget methods like H2O, SLM, and SnapKV require a high budget of 90% and still underperform. The method's budget allocation naturally reflects task difficulty, reserving more cache for math and science problems and far less for summarization. ReFreeKV surpasses full-cache performance by 0.12% on average with a 63.68% cache budget, while H2O, SLM, and SnapKV at 90% budget all degrade performance. The cache budget automatically ranges from only 15% on summarization datasets to over 90% on math and science datasets, mirroring problem complexity.
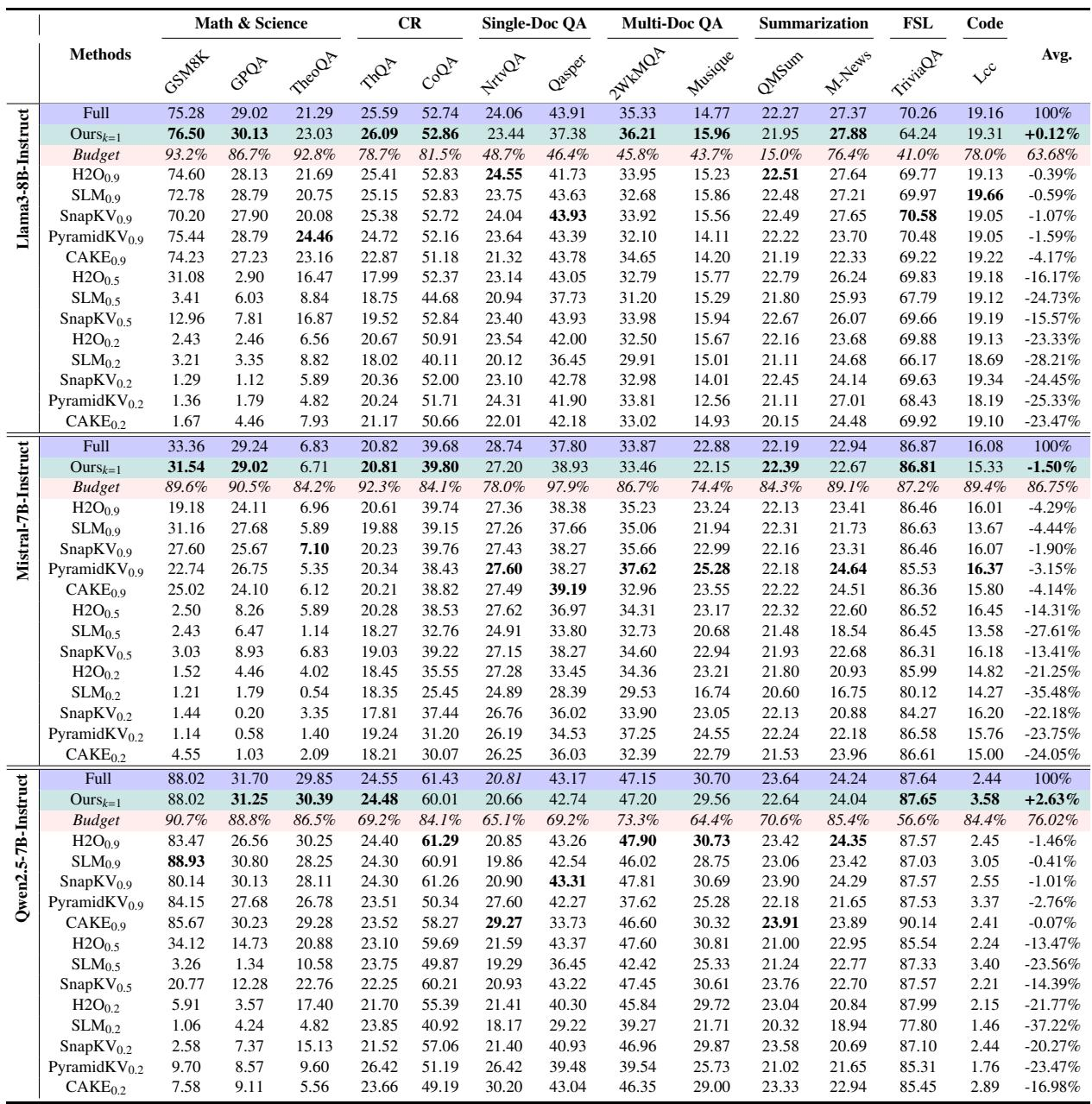
ReFreeKV generally achieves higher task performance than Twilight across both models and datasets, often surpassing the full-cache baseline. On Llama3-8B, ReFreeKV outperforms full-cache on GSM8K, 2WQA, and Musique, while Twilight lags behind on most tasks except Qasper. For Mistral-7B, ReFreeKV exceeds the uncompressed model on Qasper and consistently beats Twilight on all datasets except Musique. ReFreeKV achieves the best performance aside from full-cache on 4 of 5 datasets for Llama3-8B and Mistral-7B, compared to Twilight. With Llama3-8B, ReFreeKV surpasses the full-cache baseline on GSM8K (76.50 vs 75.28), 2WQA (36.21 vs 35.33), and Musique (15.96 vs 14.77). On Mistral-7B, ReFreeKV slightly exceeds full-cache performance on Qasper (38.93 vs 37.80), while Twilight demonstrates a marginal improvement over full-cache only on Musique (22.92 vs 22.88). Twilight retains a clear advantage only on Qasper for Llama3-8B (43.08 vs 37.38 for ReFreeKV) and on Musique for Mistral-7B (22.92 vs 22.15).
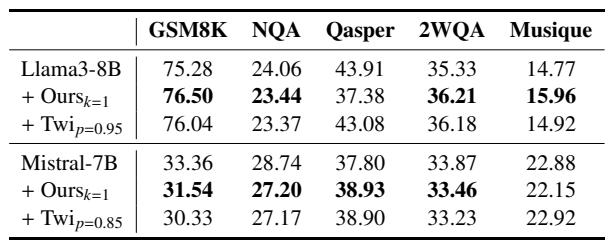
On Llama3-8B across six diverse datasets, ReFreeKV attained the lowest average overall generation time compared to full-cache inference and other token-eviction methods under a 50% budget. Its pruning latency remained comparable to baselines, and it achieved the best end-to-end generation speed in most evaluated settings, confirming that the method reduces inference latency without meaningful overhead. ReFreeKV's average overall generation time was faster than the full-cache baseline and all other pruning methods. Pruning latency for ReFreeKV was minimal and similar to H2O, SnapKV, and SLM, so the lightweight pruning step does not negate speed gains. Across model scales, ReFreeKV had the best overall generation time in 8 out of 12 comparisons, consistently outperforming prior methods in end-to-end latency.
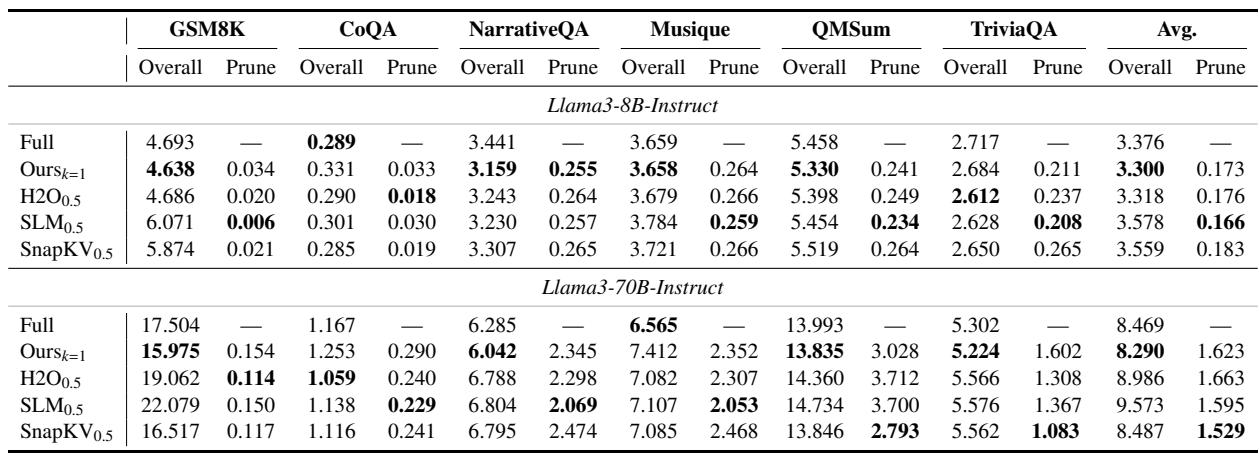
Ablation experiments on attention matrix reduction demonstrate that using only the last row (k=1) achieves a much lower KV-cache budget with nearly the same performance as larger windows, while aggregating over more rows harms accuracy. Replacing the position-based initial ranking with an attention-score-based strategy fails to yield robust trade-offs across tasks, confirming that raw attention scores are unreliable for importance estimation. With k=1, the model retains near-full performance (e.g., 23.44 on NarrativeQA at 48.7% budget and 21.95 on QMSum at 15.0% budget) while drastically reducing memory compared to k=1%n or k=5%n, whereas k=10%n causes severe drops (such as falling to 9.74 on NarrativeQA). Initial ranking by attention scores produced unstable results; on NarrativeQA, one threshold gave only 9.74 using 32% of the budget and another gave 21.44 using 48.7%, both inferior to the position-based ranking's performance of 23.44 at 48.7%.
This study evaluates KV cache pruning methods across diverse tasks and models, comparing fixed-budget baselines like H2O, SnapKV, and SLM to the proposed ReFreeKV, which dynamically adapts its cache budget per input. Fixed-budget pruning causes highly inconsistent accuracy, requiring task-specific tuning, whereas ReFreeKV matches full-cache performance using only 63.7% of the cache on average and automatically reserves more memory for harder problems like math and science. ReFreeKV also surpasses the competitive Twilight method, often exceeding the uncompressed baseline, and achieves the lowest end-to-end generation latency across model scales without meaningful overhead. Ablation studies show that relying on only the last attention row and a position-based initial ranking is crucial, as aggregating more rows or using raw attention scores harms both efficiency and accuracy.