Command Palette
Search for a command to run...
BlockPilot: تعلّم السياسات المكيّفة حسب العينة للتوليد التكهني القائم على الانتشار
BlockPilot: تعلّم السياسات المكيّفة حسب العينة للتوليد التكهني القائم على الانتشار
Hao Zhang Yiming Hu Yong Wang Mingqiao Mo Xin Xiao Xiangxiang Chu
الملخص
يُسرّع التوليد التكهني الاستدلال باستخدام نموذج مسودة خفيف لتوليد رموز مرشحة بالتوازي، ثم يتم التحقق منها لاحقاً بواسطة النموذج الهدف، مما يحقق تسريعاً غير منقوص الدقة. مؤخراً، حسّن التوليد التكهني القائم على الانتشار التوازي بدرجة أكبر عبر توليد رموز متعددة في كل مرور أمامي من خلال الانتشار على مستوى الكتل، محققاً أداءً متطوراً (SOTA). مع ذلك، تعتمد الأساليب الحالية حجماً ثابتاً لكتلة الاستدلال وتفترض استراتيجية توليد مثلى موحدة لجميع المدخلات. في هذه الورقة، نُظهر أن هذا الافتراض دون الأمثل، إذ يتباين الحجم الأمثل للكتلة عبر العينات ويلعب دوراً حاسماً في أداء التوليد التكهني. علاوة على ذلك، تُظهر هذه القيم بنية محلية واضحة تتمركز حول حجم كتلة التدريب، مما يُقلّص المسألة إلى فضاء قرار منخفض البعد ومنظم. بناءً على هذه الرؤى، نقترح BlockPilot، وهي سياسة تتكيف مع كل عينة وتتنبأ بالحجم الأمثل للكتلة من تمثيل مرحلة ما قبل التعبئة. على وجه التحديد، نصوغ اختيار حجم الكتلة كمسألة تعلّم سياسة خفيفة الوزن ونقترح آلية قرار مكيّفة حسب العينة تتنبأ بالحجم الأمثل للكتلة بناءً على تمثيل مرحلة ما قبل التعبئة. يُجرى التنبؤ مرة واحدة فقط بعد مرحلة ما قبل التعبئة، مما يتيح تكاملاً سلساً. تُظهر التجارب المكثفة أن طريقتنا قابلة للتوصيل والعمل بأقل عبء إضافي، وتُحسّن الكفاءة باستمرار، محققةً طول قبول قدره 5.92 وتسارعاً بمعامل 4.20× على نموذج Qwen3-4B عند درجة حرارة T = 1.
One-sentence Summary
Researchers at AMAP, Alibaba Group propose BlockPilot, a sample-adaptive policy that predicts the optimal block size for diffusion-based speculative decoding from a lightweight policy learned on prefilling representations, exploiting the local structure of optimal block sizes to reduce the decision space and achieving an acceptance length of 5.92 and a 4.20× speedup on Qwen3-4B at temperature T=1.
Key Contributions
- The optimal block size in diffusion-based speculative decoding varies across samples and concentrates locally around the training block size, forming a structured, low-dimensional decision space that can be learned from the prefilling state.
- A lightweight instance-adaptive policy, BlockPilot, predicts the optimal block size from a discrete candidate set using only the prefilling representation, with minimal overhead and seamless integration into existing frameworks.
- Experiments on Qwen3-4B show that BlockPilot attains an acceptance length of 5.92 and a 4.20× speedup at temperature 1, consistently improving efficiency over fixed block-size strategies.
Introduction
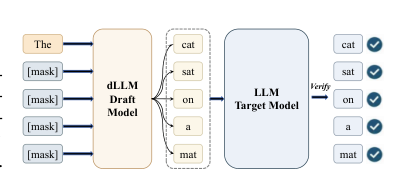
Large language models achieve impressive results, but their autoregressive decoding creates a sequential bottleneck that leads to high latency. Diffusion-based speculative decoding tackles this by having a draft model propose multiple tokens in parallel through block-wise generation, which the target model then verifies. Recent practical systems, such as DFlash, inject hidden states from the target model into the diffusion drafter to boost draft quality, yet they lock the draft block size to a fixed value inherited from training. The authors identify that the optimal block size actually depends on the predictability of each input sample, and a static choice leaves efficiency gains untapped. They propose BlockPilot, which is a lightweight, sample-adaptive method that uses the target model’s prefilling distribution for the final token to predict a suitable block size from a small local set. This policy-learning approach integrates without altering the target or draft models, and it raises acceptance lengths and inference speedups across diverse settings.
Dataset
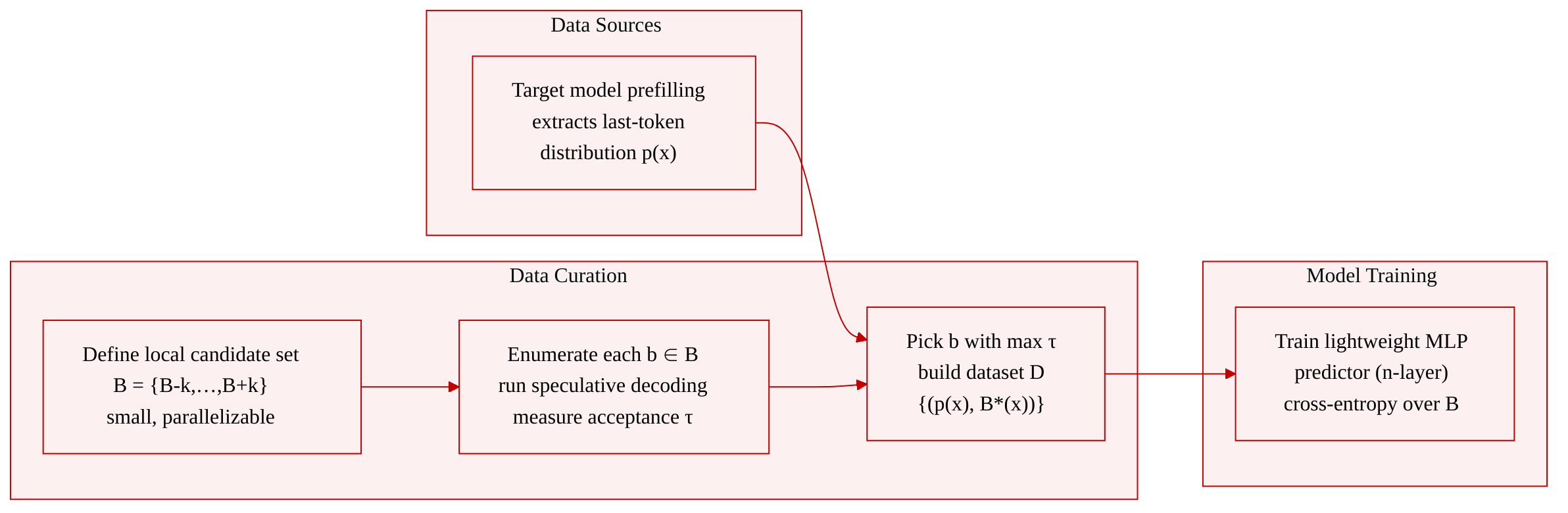
The authors construct a supervised training dataset to teach a lightweight block size predictor how to choose the optimal speculative decoding block size from the final prefilling hidden state.
Dataset composition and sources
- Each sample is a pair: a predictive probability distribution over the vocabulary at the last prefilling position, and a ground-truth optimal block size category.
- No external labeled data is used; all samples are generated offline from the target language model itself by enumerating candidate block sizes and measuring their effectiveness.
Key details and construction process
- Input feature extraction: For an input prompt x, the target model runs its prefilling stage, and the output distribution at the last token p(x) is captured as the input feature.
- Candidate set: Based on an earlier finding (Finding II), a small local candidate set B = {B−k, …, B+k} is defined around a base block size B.
- Label generation: For each candidate block size b in B, a full speculative decoding pass is executed to measure the acceptance length τ(b; x). The block size that yields the maximum acceptance length is labeled as the optimal block size B*(x).
- Dataset: The resulting collection D = {(p(x_i), B*(x_i))} contains N such pairs. The process is parallelizable because evaluations across candidates are independent.
How the data is used
- The dataset is used exclusively to train a shallow multilayer perceptron (n-layer MLP) that serves as the block size predictor.
- The model takes p(x) as input and outputs logits over the candidate block sizes, trained with a standard cross-entropy loss that maximizes the probability of the recorded optimal block size.
- No explicit train/validation split or mixture ratio is mentioned; the dataset is constructed per target model configuration and used directly for training the predictor.
Other processing details
- There is no cropping, augmentation, or metadata beyond the feature-label pairs.
- The candidate set size (2k+1) is deliberately small to keep the offline enumeration tractable while still covering the relevant dynamic range of block sizes.
- The feature p(x) is a high-level representation already compressed by the target model's prefilling, so the predictor can remain compact and add minimal latency.
Method
The authors propose a sample-adaptiveblock size selection method for speculative decoding based on diffusion language models. In this framework, a lightweight diffusion model acts as the draft model to generate a block of tokens in parallel, which are then verified by the target autoregressive model. The efficiency of this process is primarily governed by the expected number of accepted tokens per verification step, τ(B). The average per-token generation latency is defined as L(B)=τ(B)Tdraft(B)+Tverify(B), where Tdraft(B) and Tverify(B) represent the computational costs of draft generation and verification. Since these costs increase sublinearly with block size B, maximizing τ(B) is key to improving the end-to-end speedup η(B)=L(B)LAR. To achieve this, the authors aim to determine a sample-specific optimal inference block size B∗ rather than relying on a fixed training-time block size.
To understand the behavior of optimal block sizes, the authors conduct an exhaustive sweep over candidate block sizes. They observe significant instance-wise variability, where the optimal block size for a given sample often deviates from the fixed block size used during training. Furthermore, they identify a strong local interval property: the optimal block size consistently falls within a narrow range around the training block size B, specifically B∗(x)∈{B−k,…,B+k}.
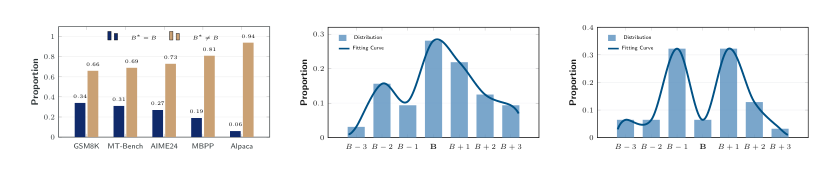
These findings motivate formulating the block size selection as a structured classification task over a finite discrete space. The authors leverage the predictive probability distribution of the last token after the prefilling stage as the input representation. This distribution serves as a compact summary of the input sequence, capturing contextual constraints and uncertainty, which makes it highly informative for predicting the optimal block size.
The training process consists of two main components: supervised data construction and learning a lightweight block size predictor. Since optimal block sizes are not explicitly annotated, the authors construct a training dataset via offline enumeration. For each input sample x, they extract the predictive distribution at the last position p(x) and evaluate the acceptance length for each candidate block size in the local neighborhood. The block size yielding the maximum acceptance length serves as the ground-truth label, forming the dataset D={(p(xi),B∗(xi))}i=1N. The block size predictor is implemented as a lightweight multi-layer perceptron. It takes the predictive distribution as input and outputs logits over the candidate block size set, which are converted to probabilities via a softmax function: P(b∣x)=∑b′∈Bexp(ob′)exp(ob). The model is trained by minimizing the standard cross-entropy loss L=−N1∑i=1NlogP(B∗(xi)∣xi), learning a direct mapping f:p(x)→B∗(x) from decoding states to optimal block size decisions.
During inference, the learned predictor is seamlessly integrated into the speculative decoding pipeline.
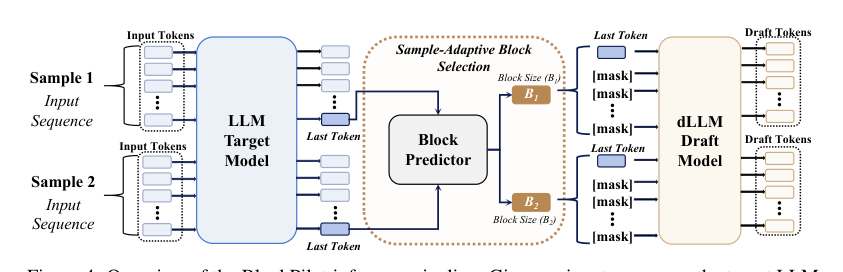
Given an input sequence, the target model first performs the prefilling stage and produces the predictive distribution of the last token. This distribution is fed into the block size predictor, which outputs logits for the candidate block sizes. The block size with the highest predicted score is selected as B^(x)=argmaxb∈Bf(p(x))b and fixed for the entire subsequent speculative decoding process, guiding both the draft generation and target model verification. Because the prediction is performed only once after prefilling and the predictor is a lightweight network, the additional computational overhead is minimal, while the adaptive selection significantly improves decoding efficiency compared to fixed block size strategies.
Experiment
The experiments assess BlockPilot's sample-adaptive block size selection across four LLMs of varying scales and domains on math, code, and chat benchmarks, comparing against autoregressive decoding, EAGLE-3, and fixed-block DFlash baselines. BlockPilot consistently achieves the highest speedups under both deterministic and stochastic decoding, outperforming even the best fixed-block variants and demonstrating that adapting block size per sample better balances parallelism and verification acceptance, with gains holding across all task categories. Ablation studies confirm that a two-layer MLP with hidden size 2048, a candidate interval radius of 2, and the raw last-token prefilling distribution as predictor input yield the optimal configuration, as the raw distribution already carries sufficient confidence information without preprocessing.
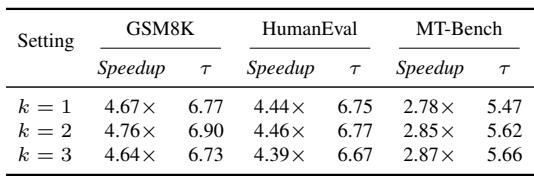
The block size predictor introduces minimal overhead compared to the backbone models, with latency in the single-digit milliseconds and memory usage far below that of the full models. This makes adaptive block size selection nearly cost-free during inference. The predictor runs in 7.34 ms, while backbone models require between 183 and 278 ms. Its activation memory is only 0.62 GB, an order of magnitude lower than the 8–16 GB needed by the backbone models.
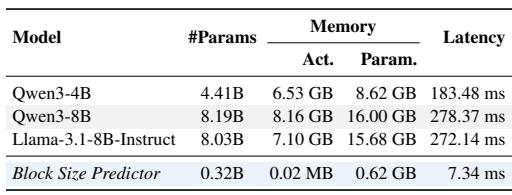
BlockPilot achieves the highest speedup ratios on Qwen3-4B and Qwen3-8B models, outperforming fixed-block DFlash variants and EAGLE-3 under both deterministic and stochastic decoding. Its sample-adaptive block size selection delivers consistent improvements in speedup and average acceptance length, while overly large fixed blocks suffer diminishing returns due to drafting errors. These gains add negligible latency and require no modifications to draft or target models. On Qwen3-4B at temperature 0, BlockPilot reaches an average speedup of 4.17×, exceeding the best fixed-block DFlash(16) speedup of 3.99× and increasing average acceptance length from 6.31 to 6.59. On Qwen3-8B at temperature 0, BlockPilot attains 4.66× speedup versus 4.42× for DFlash(16), and at temperature 1 it reaches 3.94× compared to 3.55× for the fixed-block baseline. DFlash(32) consistently underperforms DFlash(16), as larger block sizes reduce token acceptance due to accumulated drafting errors, despite greater parallelism. BlockPilot's adaptive strategy yields higher speedups across math, code, and chat benchmarks, and the gains are preserved under stochastic sampling where draft acceptance is more challenging. The method generalizes across model scales without modifying draft or target models, and the raw prefilling distribution of the last token serves as a reliable signal for block size prediction.
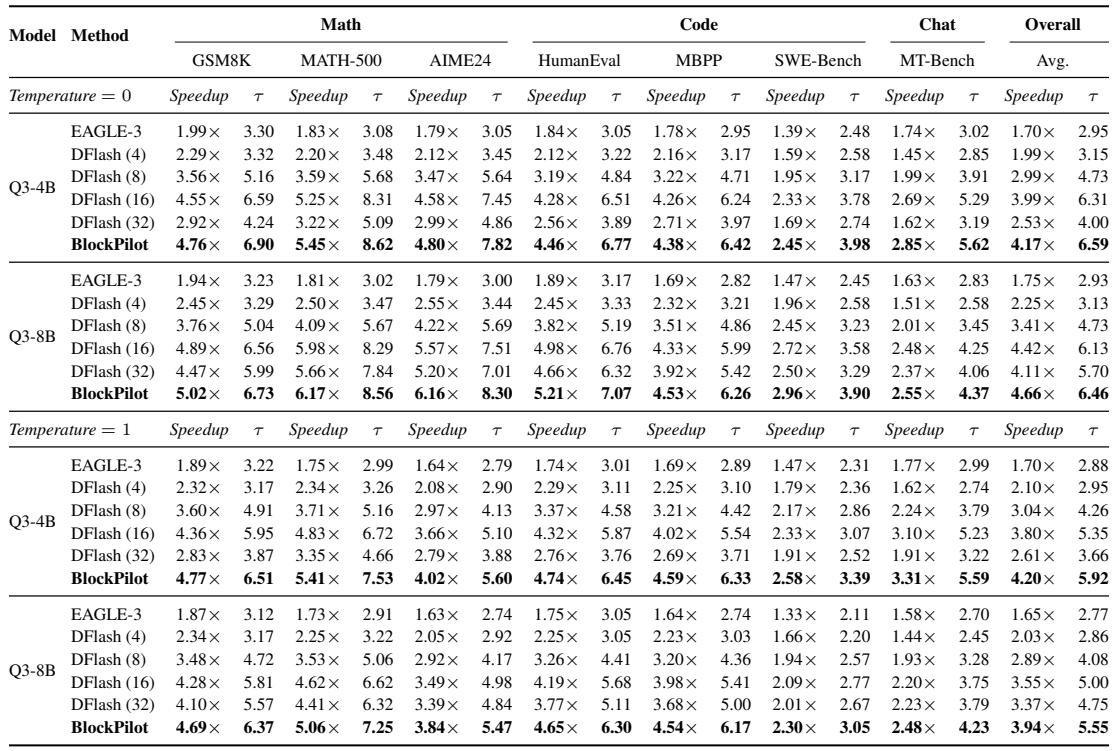
Increasing the predictor's hidden size from 1024 to 2048 yields modest improvements in speedup and acceptance length, but further scaling to 4096 offers no additional benefit. A two-layer predictor consistently outperforms a single-layer one, while a third layer gives mixed results—better on HumanEval but slightly worse on GSM8K—providing no clear overall advantage. Scaling the hidden width beyond 2048 leaves speedup and acceptance length unchanged across all three benchmarks, indicating saturation. A single-layer predictor underperforms a two-layer model, with lower speedup and acceptance length observed on every task.
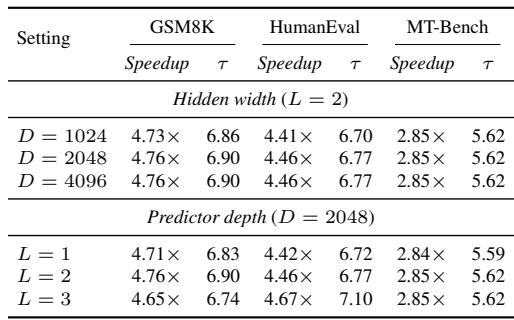
Increasing the candidate interval radius from 1 to 2 consistently improves speedup and acceptance length across all evaluated tasks. Expanding the radius further to 3 reduces performance on GSM8K and HumanEval and yields only marginal gains on MT-Bench, suggesting that a moderately wider interval best balances candidate coverage and prediction difficulty. A radius of 2 provides higher speedup and longer acceptance length than the restrictive radius of 1 on every benchmark. Moving from radius 2 to radius 3 degrades speedup and acceptance length on GSM8K and HumanEval while delivering a small improvement on MT-Bench, indicating diminishing returns.
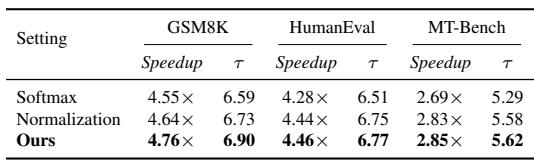
Using the raw predictive distribution of the last token after prefilling as predictor input yields the highest speedup and acceptance length across all benchmarks. Applying softmax or normalization preprocessing consistently degrades performance, suggesting that the original distribution already encodes the necessary confidence signal and that preprocessing may suppress useful information. The raw prefilling distribution outperforms softmax and normalization preprocessing on GSM8K, HumanEval, and MT-Bench in both speedup and acceptance length. Softmax preprocessing leads to the lowest speedup and shortest acceptance lengths, while normalization falls between softmax and the raw input, indicating any preprocessing hurts prediction quality.
The evaluation first confirms that the block size predictor adds negligible overhead (single-digit millisecond latency and an order of magnitude less memory than backbone models). Across models and decoding modes, BlockPilot outperforms fixed-block DFlash and EAGLE-3 by adaptively selecting block sizes, achieving higher speedups and longer acceptance lengths without modifying draft or target models. Ablation studies show that the optimal predictor uses two layers, a hidden size of 2048, a candidate interval radius of 2, and raw prefill token distributions as input; increasing model capacity or applying softmax and normalization preprocessing either saturates gains or hurts performance.